Sist oppdatert 14. desember 2010.
Vis innholdsfortegnelse
Skjul innholdsfortegnelse
kap-1: Introduksjon
kap-1.1: Innledning
kap-1.2: Om tekstkoding og retningslinjer
kap-1.2.1: Hvordan ser koding ut?
kap-1.2.2: Grunnleggende retningslinjer
kap-1.2.3: Dokumentanalyse
kap-1.2.3.1: Teksttypeanalyse
kap-1.2.3.2: Tekstkildeanalyse
kap-1.3: Typografi
kap-1.3.1: Typografisk forståelse
kap-1.3.2: Vår behandling av blanke i XML-filene
kap-1.3.3: Typografisk «variasjon» mellom tekstkilder
kap-1.3.5: Avvikende markering av tegn i trykte tekster
kap-1.3.6: Kapitler
kap-2.1: Filbeskrivelse – <fileDesc>
kap-2.1.1.1: Eksempler på <titleStmt>:
kap-2.1.2: Tekstens utgave – <editionStmt>
kap-2.1.3: Publiseringsinfo – <publicationStmt>
kap-2.1.5.1: Opplysninger om kildefil
kap-2.1.5.2: Trykte tekstkilder – enkeltverk (med liste over tekstkilder brukt i ekstern variantapparat)
kap-2.1.5.3: Trykte tekstkilder – samlede verker
kap-2.1.5.4: Trykte tekster – føljetonger
kap-2.1.5.5: Håndskrifter
kap-2.2.1: Prosjektbeskrivelse – <projectDesc>
kap-2.2.2: Filologisk praksis – <editorialDecl>
kap-2.2.2.1: Typografibeskrivelse – <typography>
kap-2.2.2.2: <stdVals> – standardized values
kap-2.2.2.3: Lenke til tekstkritiske retningslinjer
kap-2.2.3: Kodedokumentasjon – <tagsDecl>
kap-2.2.3.1: <tagUsage gi="id-who">
kap-2.2.3.2: <tagUsage gi="pb-ed-HU">/<tagUsage gi="pb-ed-HU-n">
kap-2.2.3.3: <tagUsage gi="tei.2">
kap-2.2.4: Om verskoding og notasjonssystem – <metDecl>
kap-2.3.1: Språkbruk – <langUsage>
kap-2.3.2: Håndskriftets hender – <handlist>
kap-2.4: Loggføring – <revisionDesc>
kap-3: Strukturkoding
kap-3.1: Om strukturkoding
kap-3.1.1: XML-struktur
kap-3.1.2: Tekststruktur
kap-3.1.2.1: Oversikt over generelle strukturelementer
kap-3.2: <text> og <group>
kap-3.2.1: Dobbel femakter
kap-3.2.2: Rollehefter
kap-3.2.3: Føljetonger
kap-3.3: <teiCorpus.2>
kap-3.4: <front>
kap-3.4.1: Tittelsider
kap-3.4.2: Innholdsfortegnelser
kap-3.4.3: Forord
kap-3.5: <body>
kap-3.6: <back>
kap-3.6.1: Etterord
kap-3.6.2: Notebilag
kap-3.7: <div>
kap-3.8: <lg>
kap-3.9: Overskrifter
kap-3.9.1: <opener> og <closer>
kap-3.9.2: Musikkinformasjon
kap-3.10: Lister
kap-3.10.1: Trykkfeillister
kap-3.10.2: «Huskelister»
kap-3.11: Tabeller
kap-3.11.1: Tabell med fylltegn
kap-3.11.2: Tabell uten fylltegn
kap-3.11.3: Tabeller med avvikende oppsett
kap-4: Brevkoding
kap-4.1: Innledning
kap-4.2: Tekstelementer i brev
kap-4.2.1: Eksempel på kodet enkeltbrev
kap-4.3: <teiHeader>
kap-4.3.2: Enkeltbrevenes <teiHeader>
kap-4.3.3: <msDescription> og <bibl>
kap-4.3.3.1: <msDescription>
kap-4.3.3.1.1: <msIdentifier>
kap-4.3.3.1.2: <letterinfo>
kap-4.3.3.1.2.1: typeattributt i <letterinfo>
kap-4.3.3.1.2.2: <sender>, <recipient>, <origDate>, <origPlace>
kap-4.3.3.1.2.3: <matDesc>
kap-4.3.3.1.2.4: Eksempel på <letterinfo>
kap-4.3.3.2: <bibl>
kap-4.3.4: <projectDesc>
kap-4.3.5: <handList> i brevfiler
kap-4.4.1: Etterskrift – <div type="postscript">
kap-4.4.1.1: Tilføyet etterskrift
kap-4.4.2: Vedlegg – <back>
kap-4.6: Åpningshilsen – <salute>
kap-4.7: Avsnitt – <p>
kap-4.8: Avslutningshilsen – <salute>
kap-4.9: Signatur – <signed>
kap-4.9.1: Signerte fellesbrev
kap-4.10: Konvolutter
kap-4.11: Avskrifter/kopier
kap-4.12: Trykt tekst i håndskrifter
kap-4.12.1: Visittkort
kap-4.12.2: Prefrankerte postkort
kap-4.13: Rimbrev og dikt
kap-4.14: Åpne Brev
kap-4.15: Telegrammer
kap-4.16.1: Retningslinjer for transkripsjon av brev
kap-4.16.2: Retningslinjer for håndskriftskoding i brev
kap-4.17: Koding av brevhovedtekster
kap-5: Diktkoding
kap-5.1: <teiHeader> i dikt
kap-5.1.2: Om verskoding og notasjonssystem – <metDecl>
kap-5.2: Innholdsfortegnelser
kap-5.3: Tekstelementer i dikt
kap-5.4: Tekststrukturer
kap-5.4.1: Strukturen i diktsamlinger
kap-5.4.2: Strukturen innenfor enkeltdikt
kap-5.4.2.1: Større avdelinger – <div type="section">
kap-5.4.2.2: Verslinjegrupper – <lg>
kap-5.4.2.3: Verslinjer – <l>
kap-5.4.2.3.1: Metrikk vs. typografi
kap-5.4.2.3.3: Inkomplette verslinjer
kap-5.4.2.3.4: Linjer med tankestreker
kap-5.5: Oppsplittede dikt
kap-5.5.1: Lenking mellom diktdeler
kap-5.6: Dikthenvisninger
kap-5.6.1: Dikthenvisninger med titler
kap-5.6.2: Enklere henvisninger
kap-5.7: Ufullstendige dikt
kap-5.8: Musikkinformasjon
kap-5.9: Bibliografiske opplysninger
kap-5.10: Verksfiler
kap-5.10.1: Oppsplittede filer for versjonsvisninger
kap-6: Dramakoding
kap-6.1: Tekstelementer i drama
kap-6.2: Rollelister – <castList>
kap-6.2.1: Elementer og prinsipper
kap-6.2.2: id="" og det tilhørende who=""
kap-6.2.2.1: Hvilke roller skal ha id=""?
kap-6.2.2.2: Hva skal brukes som id=""?
kap-6.2.2.2.1: Rollenavnvarians mellom ulike tekstkilder
kap-6.2.2.3: Hvor plasseres id=""?
kap-6.2.2.4: who="" i <sp> og <stageRole>
kap-6.2.3: Eksempel på kodet rolleliste
kap-6.2.4: Setting – <set>
kap-6.3: Akt- og sceneinndeling
kap-6.3.1: Akter
kap-6.3.2: Scener
kap-6.3.3: Akt- og sceneoverskrifter
kap-6.4: Replikk – <sp>
kap-6.4.1: «Avvikende» replikker
kap-6.4.1.1: Replikker uten replikkåpner
kap-6.4.1.2: Replikker med doble rollenavn
kap-6.4.1.3: Replikker med forkortede rollenavn
kap-6.4.1.4: Replikker med feil rollenavn
kap-6.4.1.5: Tomme replikker
kap-6.4.1.6: Avvikende oppsett
kap-6.6: Avsnitt i prosa – <p>
kap-6.7: Verslinjer – <l>
kap-6.7.1: Oppdelte verslinjer
kap-6.7.2: Inkomplette verslinjer
kap-6.7.4: Grupper av verslinjer
kap-6.7.5: Metrikk vs. typografi
kap-6.8: Sceneanvisninger – <stage>
kap-6.8.1: Ulike utforminger av sceneanvisninger
kap-7.1: Innledning
kap-7.2: TEI-header
kap-7.2.2: Sakprosa-TEI-header
kap-7.2.2.1: <sourceDesc>
kap-7.2.2.2: <analytic>
kap-7.2.2.3: <monogr>
kap-7.2.2.4: <proseinfo>
kap-7.2.2.4.1: Typeattributt i <proseinfo>
kap-7.2.2.4.2: <occasion>
kap-7.2.2.4.3: <matDesc>
kap-7.2.2.5: <projectDesc>
kap-7.2.2.6: <profileDesc>
kap-7.2.3: Eksempler
kap-7.2.3.1: Artikkel (trykk)
kap-7.2.3.2: Artikkel (manuskript)
kap-7.2.3.3: Tale (trykk)
kap-7.2.3.4: Tale (manuskript)
kap-7.2.4: Varia-TEI-header
kap-7.3.1: Overskrifter
kap-7.3.2: Nummerering av sider og spalter/kolonner
kap-7.3.2.1: Koding av omkringliggende tekst
kap-7.3.3: Illustrasjoner
kap-7.3.4: Transkripsjon
kap-7.3.5: Skillingstegn
kap-7.3.6: Trykt tekst i håndskrifter
kap-7.3.7: Signatur
kap-7.3.8: Noter
kap-7.3.8.1: i trykk
kap-7.3.8.2: i manuskript
kap-7.3.9: Tabellkoding
kap-7.3.10: Koding av personnavn, stedsnavn og verkstitler
kap-8: Verskoding
kap-8.1: Hvilke tekster har verskoding?
kap-8.1.2: Sjangeravgrensninger
kap-8.1.2.1: Sondring mellom prosa og vers
kap-8.2: <teiHeader>
kap-8.3: Verslinjer
kap-8.3.1: Metrikk vs. typografi
kap-8.3.2: Linjer med tankestreker
kap-8.3.3: Førstelinjekoding
kap-8.4: Grupper av verslinjer
kap-8.4.1: Typifisering
kap-8.4.1.1: Formdannelse
kap-8.4.1.1.1: Strofisk
kap-8.4.1.1.2: Stikisk
kap-8.4.1.1.3: Rapsodisk
kap-8.4.2: Oppdelte verslinjegrupper
kap-8.4.2.1: Ufullstendige strofer
kap-8.4.2.2: Refreng
kap-8.5: Metrikk-noter
kap-8.6: Notasjonssystem
kap-8.6.1: Spesialtegn
kap-8.6.2: Rimkoding
kap-8.6.2.1: Rimnotasjon
kap-8.6.2.1.1: Forkortelse
kap-8.6.2.2: Rimsekvens
kap-8.6.2.2.1: Versdramaer
kap-8.6.2.2.2: Dikt
kap-8.6.2.3: Urene rim
kap-8.6.2.4: Variasjon og avvik
kap-8.6.2.4.1: Gjennomgående variasjon
kap-8.6.2.4.2: Avvik
kap-8.6.2.5: Nullrim
kap-8.6.3: Metrisk mønster
kap-8.6.3.1: Versgang
kap-8.6.3.1.1: Ren og blandet versgang
kap-8.6.3.2: Versenes stavelsesantall
kap-8.6.3.2.1: Strofiske tekster
kap-8.6.3.2.2: Stikiske tekster
kap-8.6.3.2.3: Rapsodiske tekster
kap-8.6.3.2.4: Forkortelse
kap-8.6.3.3: Fordeling av trykksvake og trykksterke stavelser
kap-8.6.3.3.1: Typografisk trykkmarkering
kap-8.6.3.4: Normalisering, avvik, variasjon
kap-8.6.3.4.1: Normalisering
kap-8.6.3.4.2: Avvik
kap-8.6.3.4.3: Variasjon
kap-8.6.4: Opptaktsforhold
kap-8.6.4.1: Variasjon og avvik
kap-8.6.4.2: Visning av faktisk opptakt
kap-8.6.5: Spesialtilfeller
kap-8.6.5.1: Trisyllabiske rim i bisyllabisk versgang
kap-8.6.5.2: Tekster som inneholder flere metre
kap-8.6.5.3: Tekster som ligger midt mellom to metre
kap-8.6.5.4: Metrisk koding av strøkne verslinjer i manuskripter
kap-8.7: Produksjonskoding – <lg rend="poem">
kap-8.7.1: Diktoppsett
kap-8.7.2: Innrykkede verslinjer
kap-8.8: Vasking av filer med metrikk-koding
kap-8.9: Litteraturliste
kap-9: Detaljkoding
kap-9.1: Paginering – <pb/>
kap-9.2: Kolonnenummerering – <cb/>
kap-9.3.1: Bruken av <fw> i manuskripter
kap-9.3.1.1: Typologisering av <fw>
kap-9.3.1.2: Vanskelige <fw>-tilfeller
kap-9.3.2: Bruken av <fw> i trykte tekstvitner
kap-9.3.2.1: Uthevet tekst i arksignaturer
kap-9.3.2.2: Doble arksignaturer
kap-9.4: Linjeskift – <lb/>
kap-9.4.1: Plassering av linjeskiftselementene
kap-9.5: Utheving
kap-9.5.1: Retorisk utheving – <emph>
kap-9.5.2: Tilfeldig utheving – <hi>
kap-9.5.5.1: Hevet tekst – <hi rend="raised">
kap-9.5.5.2: Initialer – <hi rend="initial">
kap-9.5.5: Trykt tekst i håndskrift – <print>
kap-9.5.6: Husregler for plassering av interpunksjon
kap-9.6: Noter – <note>
kap-9.6.2: Noter om feil i teksten – <note type="typo">
kap-9.6.3: Forfatternoter – <note resp="">
kap-9.6.3.1: Noter uten referanse i teksten
kap-9.6.3.2: Noter med referanse i teksten
kap-9.6.4: Fortellernoter og redaksjonelle noter
kap-9.6.5: Metrikknoter – <note type="met">
kap-9.7: «Tekstfeil» – <sic>
kap-9.7.1: Koding av tekstfeil
kap-9.7.2: Husregler for behandling av tekstfeil
kap-9.7.3: Koding av snudde typer
kap-9.8: Transkripsjonsnormalisering
kap-9.8.1: ...i trykt tekst
kap-9.8.2: ...i manuskripter
kap-9.9: Faksimiler, logoer og illustrasjoner
kap-9.9.1: Utelatt tekst/illustrasjoner – <gap/>
kap-9.10: Skillestreker
kap-9.10.1: Pynte- og skillestreker
kap-9.10.2: Strofeskiller
kap-9.11: Tegnsetting
kap-9.11.1: Anførselstegn
kap-9.11.2: Tankestrek
kap-9.11.2.1: Tankestrek etterfulgt av interpunksjon
kap-9.11.2.2: Tankestrek mellom tall i tidsspenn
kap-9.11.2.3: Linjer med tankestreker
kap-9.11.2.4: Tankestreker i manuskripter
kap-9.11.3: Bindestreker
kap-9.11.3.1: Typografiske/myke bindestreker ved linjeskift – &typHyp;
kap-9.11.3.2: Meningsbærende/harde bindestreker ved linjeskift
kap-9.11.3.3: Manglende bindestreker
kap-9.11.3.4: To bindestreker på rad
kap-9.12.1: I teiHeader/letterinfo
kap-9.12.2: I løpende tekst
kap-9.13: Koding av datoer
kap-9.13.1: I teiHeader
kap-9.13.2: I innledende og avsluttende elementer
kap-10: Lenkekoding
kap-10.1: Innledning
kap-10.2.1: «Forts»/«Slutning» i føljetonger
kap-10.2.2: Notereferanse
kap-10.2.3: <div type="ref">
kap-10.3: Sammenlenking – <join/>
kap-10.3.1: Føljetonger
kap-10.3.2: Delte replikker
kap-10.3.3: Lemma som krysser strukturgrenser
kap-10.3.4: Flertabellkodede innholdsfortegnelser
kap-10.4: Innhenting av xml-filer – <xptr/>
kap-10.7: Pekere til andre tekstvitner
kap-10.8: Lenking innenfor diktkoding
kap-10.8.2: Oppsplittede dikt
kap-10.8.2.1: Lenking mellom diktdeler
kap-10.8.3: Dikthenvisninger
kap-10.8.3.1: Dikthenvisninger med titler
kap-10.8.3.2: Enklere henvisninger
kap-10.9: Koding for synoptiske versjonsvisninger
kap-10.9.1: Grunnlagskoding – <pb ed="hu"/>
kap-10.9.2: Generelt om synoptiske visninger
kap-10.9.3: Synoptisk visning av hovedversjoner
kap-10.9.3.1: Koding
kap-10.9.3.2: Eksempel: OL
kap-9.3.3: Når tekst ikke finnes i en av versjonene
kap-10.9.4.1: Koding
kap-10.9.4.2: Når tekst ikke finnes i en av filene
kap-11: Manuskriptkoding
kap-11.1: Retningslinjer
kap-11.1.1: Koding av struktur: «normalisering»
kap-11.1.1.1: Paratekst
kap-11.1.1.2: Tekstelementer
kap-11.1.2: Tyding av skrift: skjønn
kap-11.1.4: Retningslinjene sett under ett
kap-11.2.1: Overordnede prinsipper
kap-11.2.1.2: Ordning vha. type="" i <text>
kap-11.2.1.3: Videre ordning, <text> eller <div>?
kap-11.2.1.4: Ordning vha. av type="" og n="" i <div>
kap-11.2.1.4.1: Ordning vha. av type=""
kap-11.2.1.4.2: Ordning vha. n=""
kap-11.2.2: Notater
kap-11.2.2.1: Generelt
kap-11.2.2.2: «Huskelister»
kap-11.2.2.3: Trykkfeillister
kap-11.2.3: Arbeidsmanuskripter
kap-11.2.3.1: Generelt
kap-11.2.3.2.1: Rolleliste (<castList>) eller vanlig <list>?
kap-11.2.3.2.2: Replikker (<sp> eller <q type="speech">)
kap-11.2.3.2.3: who-attributtet i <sp> og <q type="speech">
kap-11.2.3.2.4: Sceneanvisning
kap-11.2.3.3: Trykte tekster med håndskrevne rettelser
kap-11.2.3.3.1: Retningslinjer for kodingen
kap-11.2.3.3.2: Koding
kap-11.2.4: Endelige manuskripter
kap-11.2.4.1: Generelt
kap-11.2.4.2: Rollehefter
kap-11.2.4.2.1: Overordnet struktur
kap-11.2.4.2.2: Tittelblader
kap-11.2.4.2.3: Gjennomgående «avvik» i typografiske oppsett
kap-11.2.4.2.4: id=""- og who=""-attributter
kap-11.2.4.2.5: Tomme <speaker>-elementer
kap-11.2.5: Materiale til flere verk i samme manuskript
kap-11.2.5.1: Generelt
kap-11.2.5.2: UF81937a/KG81937a
kap-11.2.5.3: UF41109a+b
kap-11.2.6: Dokumentasjon av kodeløsninger
kap-11.2.6.1: Huskelister – KG41111
kap-11.2.6.2: Konvolutter – Ro41291
kap-11.2.6.3: Materiale som ellers kodes i <front> eller <back>
kap-11.2.6.3.1: Kladd til vedlegg i tapt brev – NBO Ms. 8° 1937a
kap-11.2.6.3.2: Notater til forord – KG81937a
kap-11.2.6.3.3: Trykkmanuskript til forord – KK8955a
kap-11.2.6.4: Manuskripter med flere rollelister
kap-11.3.1: Latinsk og gotisk håndskrift
kap-11.3.2: Skriblerier, spesialtilfeller og Ibsens særheter
kap-11.3.2.1: Julius Elias' klammeparenteser
kap-11.3.4: Sider og paginering
kap-11.3.4.1: Mange blanke sider etter hverandre
kap-11.3.4.2: Plassering av <pb/> for blanke sider
kap-11.3.5: Nummerering – <fw>
kap-11.3.6: Egenhendige og ikke-egenhendige noter
kap-11.3.7: Brutt sammenheng
kap-11.3.8: Feil rekkefølge
kap-11.3.10: Illustrasjoner
kap-11.3.11: Håndskriftsendring av pretrykt tekst
kap-11.3.12: Ufullførte tegn
kap-11.3.13: Tilfeldig utheving av overskrifter, rollenavn o. l.
kap-11.4: Skriverhender
kap-11.4.1: Skriveomganger
kap-11.4.2: Markering av hender – hand=""
kap-11.4.3: Skifte av skriverhender – <handShift/>
kap-11.5: Uleselig/manglende tekst – <gap/>
kap-11.6: Uklar tekst – <unclear>
kap-11.7: Tydeliggjøring
kap-11.7.1: Overskriving av tegn/bokstav/ord med samme tegn/bokstav/ord – <clarification place="inline">
kap-11.7.3: Tydeliggjøring i tilknytning til andre endringer
kap-11.7.4: Tydeliggjøringer i trykt tekst
kap-11.8: Hull i teksten – <space/>
kap-11.9: Forkortede ord – <expan abbr="">
kap-11.10: Generelt om retningslinjer...
kap-11.10.1: ...for elementbruk
kap-11.10.2: ...for hvordan man begrenser størrelsen på apparatet
kap-11.10.3: ...for behandling av blanke
kap-11.11: Tilføyelser – <add>
kap-11.11.2: Plassering av tilføyelsene
kap-11.11.4: Strøket tilføyelse
kap-11.11.5: Sideskift i lengre tilføyelser
kap-11.11.6: Linjeskift
kap-11.11.6.1: ... i tilføyelser generelt
kap-11.11.6.2: ... i lengre offline-tilføyelser
kap-11.11.6.3: ... i lengre inline-tilføyelser
kap-11.11.7: Tilføyelser som skal inneholde strukturelementer
kap-11.11.8.1: Når ett referansetegn mangler
kap-11.11.8.2: Når ett referansetegn viser til flere referansetegn
kap-11.11.8.3: Referansetegn uten tilføyelse
kap-11.12: Slettet tekst – <del>
kap-11.12.1: Retningslinjer
kap-11.12.2: Overstrykninger
kap-11.12.2.1: «Vanlige» strykninger
kap-11.12.2.3: «Dobbel» strykning
kap-11.12.2.4: «Tomme» strykninger
kap-11.12.2.5: Strykninger som skal inneholde strukturelementer
kap-11.12.3: Overskrevet tekst
kap-11.12.3.1: Hovedhåndens overskrivninger
kap-11.12.3.2: Overskrivning og tilføyelse
kap-11.12.3.3: Usikker rekkefølge ved overskriving
kap-11.12.3.4: Når bokstav overskriver tegnsetting
kap-11.12.3.5: «Dobbel» overskrivning
kap-11.13: Substitusjon – <add> og <del> sammen
kap-11.13.1: Inline-substitusjoner
kap-11.13.3: Større substitusjoner
kap-11.14.1: Generelle retningslinjer
kap-11.14.2: Eksempler på substitusjoner
kap-11.14.4: Substitusjon hvor opprinnelig lesemåte gjenopprettes
kap-11.15: Ufullførte endringer
kap-11.15.2: Alternativ eller parallell tekst
kap-11.16: Endringer på tvers av strukturgrenser
kap-11.17: Splitting av replikk
kap-11.18: Sammenslåing av replikker
kap-11.19: Omrokkering
kap-11.19.1: Endring av rekkefølge på ord
kap-11.19.2: Endring av rekkefølge på fraser
kap-11.19.3: Endring av rekkefølge på ord og frase
kap-11.19.4: Behandling av ord som kommer mellom
kap-11.19.5: Endring av rekkefølge på enkeltlinjer
kap-11.19.6: Endring av rekkefølge på grupper av linjer
kap-11.20: Flytting av tekst vha. piler e.l.
kap-11.21: Gjenoppretting av tidligere lesemåte
kap-11.21.1: Gjenoppretting av strykning
kap-11.21.2: Oppheving av utheving
kap-11.21.3: Noter som opphever endringer
kap-11.21.4: Kansellert nummerert omrokkering
kap-11.21.5: Kansellerte erstatninger
kap-12: Internvariasjon
kap-12.1: Grunnkoding
kap-12.2: Ved kryssende strukturer
kap-13: Det eksterne variantapparatet
kap-13.1: Begrepsavklaring
kap-13.2: Behandling av eksternvariasjon i HIS
kap-13.2.1: Variantvisninger
kap-13.2.2: Diplomatarisk gjengivelse
kap-13.2.3: Rollehefter
kap-13.3: Arbeidsprosedyrer
kap-13.4: Avgrensning av variantapparatet
kap-13.4.1: Variasjon som ekskluderes
kap-13.4.1.2: Gjennomgående variasjon
kap-13.4.2: Variasjon som inkluderes
kap-13.4.3: Øvrige retningslinjer
kap-13.5: <teiHeader>
kap-13.5.1: Bibliografiske opplysninger – <listBibl>
kap-13.5.1.1: Antall varianter – <notesStmt>
kap-13.5.2: Variantapparatdeklarasjon – <variantEncoding/>
kap-13.6: Variantkoding
kap-13.6.1: Tekstkilder som ikke er grunntekster
kap-13.6.1.1: Id-verdier
kap-13.6.2: Grunntekster
kap-13.6.2.1: Rekkefølge av tekstkilder
kap-13.6.2.2: Forenkling av koding i andre tekstkilder
kap-13.6.3: Varianttyper
kap-13.6.4: Variasjon i forhold til grunntekst
kap-13.6.5: Kontekst
kap-13.6.6: Internvariasjon
kap-13.6.7: Forskjeller i linjeskift
kap-13.6.7.1: Feilaktig verslinjeoppsett
kap-13.6.7.2: Haplo- og dittografier ved linjeskift
kap-13.6.8: Store avvikende tekststeder, fragmenter
kap-13.6.8.1: Manglende dikt i diktsamlinger
kap-13.7: Noter
kap-13.7.1.1: Noter til variantlisten vs. noter til løpende tekst
kap-13.7.1.2: Generering av tekstkildebetegnelser
kap-13.7.2: Sluttnote – <note type="varThrough">
kap-13.8: Kontroll av variantene
kap-14: Edering og hovedtekstkoding
kap-14.1: Innledning
kap-14.2: <teiHeader> og dokument-topp
kap-14.2.1: Dokument-topp
kap-14.2.2: Filbeskrivelse – <fileDesc>
kap-14.2.2.1: Den elektroniske tekstens tittel – <titleStmt>
kap-14.2.2.2: Tekstens utgave – <editionStmt>
kap-14.2.2.3: Publiseringsinfo – <publicationStmt>
kap-14.2.2.4: Bibliografiske opplysninger om kildene – <sourceDesc>
kap-14.2.2.4.1: Dramafiler
kap-14.2.2.4.2: Brevfiler
kap-14.2.2.4.3: Diktfiler
kap-14.2.2.4.4: Sakprosafiler
kap-14.2.3: Beskrivelse av kodingen – <encodingDesc>
kap-14.2.3.1: Prosjektbeskrivelse – <projectDesc>
kap-14.2.3.2: Filologisk praksis – <editorialDecl>
kap-14.2.3.2.1: Typografibeskrivelse – <typography>
kap-14.2.3.2.1.1: Dramafiler
kap-14.2.3.2.1.2: Brev- og sakprosafiler
kap-14.2.3.2.1.3: Diktfiler
kap-14.2.3.2.2: <stdVals> – standardized values
kap-14.2.3.2.3: Referanse til tekstkritiske retningslinjer
kap-14.2.3.3: <tagsDecl>
kap-14.2.3.4: <metDecl>
kap-14.2.3.5: <variantEncoding>
kap-14.2.4.1: <langUsage>
kap-14.2.4.2: <handList>
kap-14.2.5: <revisionDesc>
kap-14.3: Tekstkritisk noteapparat
kap-14.3.1: Koding av lemma i hovedteksten
kap-14.3.2: Koding av notelisten
kap-14.3.2.1: <teiHeader> og dokumenttopp
kap-14.3.2.2: Øvrig filstruktur
kap-14.3.2.3: Koding av notene
kap-14.3.3: Utforming av noter
kap-14.3.3.1: Rollenavn som lemma
kap-14.3.4: Manuskriptendringer
kap-14.3.4.2: Håndskriftsfenomener som ikke noteres i noteapparatet
kap-14.3.4.2.1: Uklar tekst – <unclear>
kap-14.3.5: Manglende tekst
kap-14.3.5.1: Uteglemt tekst
kap-14.3.5.2: Utfylling av tapt tekst – <supplied>
kap-14.3.6: Noter i grunnteksten
kap-14.3.6.1: Originale noter
kap-14.3.6.2: Arbeidsnoter
kap-14.4: Typografisk koding (bokproduksjon)
kap-14.4.1: Grunntekstkoding som fjernes
kap-14.4.1.1: Typografikoding
kap-14.4.1.2: Koding som ellers skal undertrykkes
kap-14.4.2: Linjeskift
kap-14.4.2.1: Fjerning av linjeskift
kap-14.4.4: Transkriberte tittelsider
kap-14.4.4.1: Tittelsider til føljetonger
kap-14.4.5: Overskrifter
kap-14.4.6: Rollenavn og replikkinnehavere
kap-14.4.7: Underskrift og datering av forord/etterord
kap-14.4.8: Innholdsfortegnelser
kap-14.4.9: Kolumnetitler
kap-14.4.10: Side-/spaltereferanser i margene
kap-14.4.11: Tegn og entiteter
kap-14.4.11.1: Generelt
kap-14.4.11.2: Mellomromsentiteten &tu20;
kap-14.4.11.3: Mellomromsentiteten
kap-14.4.12: Diktoppsett
kap-14.4.12.1: Frittstående dikt og sanger i drama
kap-14.4.12.2: Innrykkede verslinjer
kap-14.4.12.3: Fire- og femdelte verslinjer
kap-14.4.12.4: Optisk justering
kap-14.4.13: Prosaavsnitt
kap-14.4.14: Plassering av sceneanvisninger ved ombrekking
kap-14.4.15: Sceneanvisninger først i akt
kap-14.4.16: Typologisering av <text>
kap-14.5: Sjangerspesifikk koding
kap-14.5.1.1: Generelt
kap-14.5.1.2: Typografisk tilleggskoding
kap-14.5.1.2.1: <role>
kap-14.5.1.2.2: <head>
kap-14.5.1.2.3: <emph>
kap-14.5.1.2.4: <stageRole>
kap-14.5.1.2.5: <stage>
kap-14.5.1.2.6: <spOpener> og <speaker>
kap-14.5.1.2.7: <figure type="bar/num"/>
kap-14.5.1.2.8: Innrykkskoding
kap-14.5.1.2.9: Farging av tekst
kap-14.5.1.3: Omkoding
kap-14.5.1.4: Tilleggskoding
kap-14.5.1.4.1: OL3ht – kryssende strukturer
kap-14.5.1.4.2: OL3ht – flyttemarkering
kap-14.5.1.4.3: Fjht – <stage> med klammer
kap-14.5.1.4.4: Fjht – «Dekorationsforandring»
kap-14.5.2: Brev
kap-14.5.2.1: Rettelser i brevmaterialet
kap-14.5.2.2: Noter om manuskriptskader
kap-14.5.2.3: «Tilføyelser» i margen
kap-14.5.2.4: Typografisk utheving
kap-14.5.2.5: Koding av personer, steder, verk og institusjoner
kap-14.5.2.6: Kodeendringer: <dateline rend="">/<salute rend="">
kap-14.5.3: Dikt
kap-14.5.3.1: Generelt
kap-14.5.3.1.1: Standardisering
kap-14.5.3.2: <text>
kap-14.5.3.3: Hovedstruktur
kap-14.5.3.4: Id-verdier
kap-14.5.3.5: Diktkoding, samt typografisk tilleggskoding
kap-14.5.3.6: Metrikk-koding
kap-14.5.4: Sakprosa
kap-14.5.4.1: Hovedstruktur
kap-14.5.4.2: Standardisering
kap-14.5.4.3: Koding av personer, steder, verk og institusjoner
kap-14.6: Appendiks
kap-15: KOMMENTARKODING
kap-15.1: INNLEDNING
kap-15.1.1: STRUKTUR
kap-15.1.1.1: STRUKTUR FOR DRAMAKOMMENTARBIND
kap-15.1.1.1.1: Om ulike div-elementer i dramakommentarbind
kap-15.1.1.2: STRUKTUR FOR BREVKOMMENTARBIND
kap-15.1.1.3: OM EKSTERNE PRODUKSJONSFILER
kap-15.1.2: ORD- OG SAKKOMMENTARER
kap-15.1.3: OVERSKRIFTSKODING
kap-15.1.3.1: Overskriftsnivåene
kap-15.1.4: DETALJKODING
kap-15.1.4.1: Text-elementet
kap-15.1.4.2: p-elementet – <p> eller <p rend="noIndent">?
kap-15.1.4.3: Kolumnetitler i dramakommentarbind
kap-15.1.4.4: Typografisk koding
kap-15.1.4.4.1: Titler
kap-15.1.4.4.2: Formatering
kap-15.1.4.5: Bilder
kap-15.1.4.6: Sitater
kap-15.1.4.7: Entiteter som særlig brukes i kommentarfilene
kap-15.1.4.7.1: Entitet for 20-enheters mellomrom
kap-15.1.4.8: Fotnoter
kap-15.1.4.9: Romertall
kap-15.1.5: Referanser og koblinger
kap-15.1.5.1: Bibliografiske referanser – <bibl>
kap-15.1.5.3: Referanseentiteter
kap-15.1.5.3.1: Lemmaentiteter (&koK1_nr;)
kap-15.1.5.3.2: Internentiteter (&koK1_nr_intern;)
kap-15.1.5.3.3: HT-entiteter (= ht-referanser) (&koK1_ht_nr;)
kap-15.1.5.3.4: Om skripting av lemma-, intern- og HT-entiteter til elementer
kap-15.1.6: Metrisk koding i kommentarfiler
kap-15.1.7: Listekoding i kommentarfiler
kap-15.1.7.1: Generelt
kap-15.1.7.2: Lister som forekommer ofte
kap-15.1.7.2.1: Eksemplarliste i Tekstkritisk redegjørelse
kap-15.1.7.2.2: Oversettelser i Ibsens levetid
kap-15.1.7.2.3: Lister i manuskriptbeskrivelser
kap-15.1.7.2.4: Bidragsyterlisten
kap-15.1.8: Tabellkoding i kommentarfiler
kap-15.1.8.1: Tabell for sammenlikning av to eller flere tekstvitner
kap-15.1.9: MER OM INNHOLD I OG KODING AV BREVKOMMENTARBIND
kap-15.1.9.1: Kolumnetitler
kap-15.1.9.2: BREVKOMMENTARER
kap-15.1.9.2.1: Brevhoder
kap-15.1.9.3: TOTALREGISTER
kap-15.1.9.3.1: Navnekoding i totalregisteret
kap-15.1.9.3.2: Koding av fødsels- og dødsår
kap-15.1.9.3.3: OMTALTE PERSONER
kap-15.1.9.3.4: BREVMOTTAGERE (personer)
kap-15.1.9.3.6: BREVMOTTAGERE (institusjoner, organisasjoner, bedrifter)
kap-15.1.9.4: TIDSTAVLE
kap-15.1.9.4.1: Koding av overskrifter i tidstavlen
kap-15.1.9.5: PERSONREGISTER
kap-15.1.9.5.1: Forarbeid for personkoding og oppretting av personregisteret
kap-15.1.9.5.2: Personkoding i innledning, kommentarer og tidstavlen
kap-15.1.9.5.4: Hvordan generere personregisteret
kap-15.1.9.6.1: Brevenes tekstkritiske redegjørelse
kap-15.1.9.6.2: Innledningen til brevenes manuskriptbeskrivelser
kap-15.1.9.6.3: Brevenes manuskriptbeskrivelser og opplysninger om tekstgrunnlag
kap-15.2: DIKT- og SAKPROSAKOMMENTARBIND
kap-16: Koding for bokproduksjon
kap-16.1: Lemma- og hovedtekstreferanser
kap-16.2: Bilderessurser
kap-16.2.1: Grunnleggende koding
kap-16.2.3: Bildetekst
kap-16.2.4: Krediteringstekst
kap-16.2.5: Sidetallsreferanser til illustrasjoner
kap-16.3: Innhenting av XML-filer
kap-16.4: Litteraturliste
kap-16.4.1: Manuskriptinnførsler
kap-16.4.2: Trykte kilder
kap-16.4.2.1: Monografier
kap-16.4.2.2: Samlede verk
kap-16.4.2.3: Artikler
kap-16.4.3: Annen koding i litteraturlisten
kap-16.4.3.1: Markering av bindtilhørighet
kap-16.4.3.2: Markering av korrekturlesning
kap-17.1: Innledning
kap-17.2: Hovedtekster
kap-17.2.1: <teiHeader>
kap-17.2.1.1: Den elektroniske tekstens tittel – <titleStmt>
kap-17.2.1.2: Tekstens utgave – <editionStmt>
kap-17.2.1.3: Publiseringsinfo – <publicationStmt>
kap-17.2.1.4: Bibliografiske opplysninger om kildene – <sourceDesc>
kap-17.2.1.5: Kodedokumentasjon – <tagsDecl>
kap-17.2.2: Fjerning av typografisk koding (bokproduksjon)
kap-17.2.3: Innlegging av sidereferanser til HISb
kap-17.3: Hovedtekstens notefil
kap-17.3.1: <teiHeader>
kap-17.4: Tekstarkiv
kap-17.5: Lenking til faksimiler
kap-17.6: Kommentarmateriale
kap-17.6.1: Innledning
kap-17.6.1.1: <teiHeader>
kap-17.6.1.2: Overordnet struktur
kap-17.6.1.3: Omgjøring av bokutgavens typografi
kap-17.6.1.4: Liste med oversettelser
kap-17.6.2: Tekstkritisk redegjørelse
kap-17.6.3: Manuskriptbeskrivelse
kap-17.6.4: Ord- og sakkommentarer
kap-17.6.4.1: <teiHeader>
kap-17.6.4.2: Overordnet struktur
kap-17.6.4.3: Omgjøring av bokutgavens typografi
kap-17.6.4.4: Omkoding av kommentarene
kap-18: Tekniske tema
kap-18.1.1: Kodesettet TEI
kap-18.1.2: En oversikt over de viktigste DTD-fragmentene
kap-18.1.3: Forskjellige element-typer
kap-18.1.4: Elementdefinisjon
kap-18.1.5: Videre om elementdefinisjoner
kap-18.2: Guide til DTD-endringer
kap-18.2.1: Grunnleggende
kap-18.2.2: Legge til nye elementer
kap-18.2.3: Endre eksisterende elementer
kap-18.2.4.1: IDREF & IDREFS
kap-18.2.4.2: Attributter med forhåndsdefinerte verdier
kap-18.3: DTD-baking
kap-18.3.1: The Pizza Chef
kap-18.3.2: Testing og feilretting
kap-18.4: Dokument-headere
kap-18.4.1: XML
kap-18.4.2: SGML
kap-18.4.3: catalog-filen
kap-18.5.1: Elementer med attributt-tillegg
kap-18.5.2: Endringer i elementklasser
kap-18.5.3: Reviderte elementer
kap-18.5.4: Fjernede elementer
kap-18.6.1: Nye elementer
kap-18.6.2: Nye elementklasser
kap-18.7: Entiteter definert i Ibsen-DTD-en
kap-18.8: Endringer fra MASTER
kap-18.8.1: Elementer i MASTER tatt inn i HIS
kap-18.8.2: Elementer lagt til av HIS i MASTER
kap-18.8.3: Elementer endret i MASTER
kap-18.8.4: Entitetsklasser som er endret i MASTER
kap-18.9: DTD for dokumentasjon av kodepraksis
kap-19: Attributtverdier
kap-19.1: Innledende bemerkninger
kap-19.1.1: Utarbeidelse av nye verdier
kap-19.1.2: Prinsipper for rekkefølge
kap-19.2: Attributter og attributtverdier i bruk
kap-19.2.1: Generell koding
kap-19.2.2: Globale attributter
kap-19.2.2.1: Verdier i bruk i det globale attributtet rend
kap-19.2.3: Metrisk koding
kap-20: Entiteter
Skjul innholdsfortegnelse

kap-1: Introduksjon
kap-1.1: Innledning
Dokumentet inneholder Henrik Ibsens skrifters (HIS) retningslinjer og praksis vedrørende tekstkoding.
For utviklingen av retningslinjer og dtder er det tatt utgangspunkt i retningslinjene og dtdene som er utviklet av Text Encoding Initiative (TEI). Vi bruker TEI P4. Vi følger i hovedsak TEI både hva gjelder retningslinjer og dtder. Arbeidet med våre dtder er dokumentert i kapitlet «Tekniske tema». Ny bruk av elementer hos oss i forhold til i TEI Guidelines (TEI P4) dokumenteres i forklaringene i kodepraksisdokumentene. Våre retningslinjer går mer i detalj rundt bruken av elementene enn det TEI gjør, og retningslinjene definerer den spesifikke bruken på vårt materiale.
Gode kilder til kunnskap om tekstkoding og xml:
- I TEI Guidelines kan det være en fordel å begynne med kapittel 2 A Gentle Introduction to XML.
- Datahåndbok for humanister redigert av Espen Aarseth, særlig Claus Huitfeldts artikkel «Tekstkoding og tekststrukturer», s. 123-146. Ad Notam Gyldendal AS 1998.
kap-1.2: Om tekstkoding og retningslinjer
Tekstkoding innebærer å kode «informasjon om visse aspekter ved tekster, for eksempel deres typografiske utseende eller innholdsmessige struktur, på en eksplisitt, systematisk og formalisert måte» (Huitfeldt 1998, 123). Standardisert koding som den vi gjør, forenkler datamaskinell behandling av tekstene og gir dem lenger liv uavhengig av data og programvare.
kap-1.2.1: Hvordan ser koding ut?
En kode eller tagg kalles i XML (SGML, HTML osv.) for element. Et element består av enten én start- og én sluttagg eller én «tom» tagg, jfr. nedenfor. Tomme elementer markerer vanligvis ikke-tekstlige fenomener i teksten, sånn som f.eks. sideskift. De kan også erstatte tekst. Vanlige elementer inneholder (omslutter) derimot tekst.
<starttagg></sluttagg> <element attributt="attributtverdi">TEKST</element> <tomtElement attributt="attributtverdi"/
I XML er det lov å gjøre om vanlige elementer til tomme elementer der det er mer hensiktsmessig.
<element attributt="attributtverdi">TEKST</element> <element attributt="attributtverdi"/>
Hos oss brukes dette f.eks. i forbindelse med elementet <figure> som bla. brukes til innkoding av skillestreker og illustrasjoner.
<figure type="bar"></figure> <figure type="bar"/>
Elementets navn svarer gjerne til den viktigste egenskapen ved teksten som blir omsluttet av elementet. Attributter gir mer detaljerte opplysninger om den kodede teksten. <div type="act" n="3"> forteller sett under ett at teksten i elementet er 3. akt i et eller annet skuespill. Litt mer detaljert kan man si at elementnavnet <div> forteller at teksten er på et hierarkisk nivå over avsnittsnivå, attributtet type="" oppgir at teksten det dreier seg om er en akt, mens attributtet n="" oppgir hvilket nummer i rekken av større tekstdeler av typen «act» det her er snakk om, nemlig den tredje.
Det er ikke obligatorisk å bruke noen attributter. Noen få attributter er globale, dvs. at de er tillatt brukt i alle TEI-elementer. De aller fleste attributtene er imidlertid elementspesifikke eller tillatt i en gruppe liknende elementer/elementer med liknende behov.
Attributtverdiene er i noen tilfeller definert på forhånd slik at man er nødt til å bruke faste verdier. Stort sett kan man imidlertid definere sine egne verdier etter de behov man har.
XML-strukturer er strengt hierarkiske. Elementer kan ikke overlappe hverandre, de nestes (ordnes) hierarkisk i strukturer som gjerne kalles «trær». Her er en typisk struktur hos oss:
<text>
<front>
<titlePage>
<docTitle>
<titlePart type="main"></titlePart>
<titlePart type="desc"></titlePart>
</docTitle>
<byline>
<docAuthor></docAuthor>
</byline>
<docImprint>
<date></date>
</docImprint>
</titlePage>
<performance>
<castList>
<castItem>
<role></role>
<roleDesc></roleDesc>
</castItem>
</castList>
</performance>
</front>
<body>
<div type="act">
<head></head>
<stage></stage>
<div type="scene">
<head></head>
<stage></stage>
<sp who="ROLLENAVN">
<spOpener>
<speaker></speaker>
<stage></stage>
</spOpener>
<p>
<stage></stage>
</p>
</sp>
</div>
</div>
</body>
<back>
<div type="epilogue">
<head></head>
<p></p>
<closer></closer>
</div>
</back>
</text>
Strukturer som overlapper hverandre, som den nedenfor, er umulige og ulovlige i XML:
<emph><hi></emph></hi>
Se også kapitlet om strukturkoding.
kap-1.2.2: Grunnleggende retningslinjer
Konsekvens og presisjon er to viktige begreper i tekstkoding. For at kodingen skal bli så konsekvent som mulig er det viktig at kodene brukes på en og samme måte hele tiden. For at kodingen skal bli presis må den holde samme presisjonsnivå gjennom det hele.
Hovedretningslinjen for grunnkodingen vår er tekstens typografiske/grafiske utforming. Vi oppfatter tekstens struktur som gitt av det typografiske/grafiske oppsettet. Oppsettet bestemmer derfor i hovedsak hvilken struktur vi koder, dvs. hva vi oppfatter som avsnitt, overskrifter, replikker etc.. De typografiske virkemidlene (dvs. de typografiske trekkene som markerer et tekstelement) skal beskrives i <teiHeader>. Videre om vår forståelse av typografi i «Typografi».
Den kodede strukturen modifiseres deretter gjerne i arbeidet med innholdsstrukturer som ikke er uttrykt typografisk, som f.eks. deler av den metriske strukturen i versdrama og dikt.
Ved siden av strukturer uttrykt gjennom typografisk/grafisk presentasjon og metrikk støtter vi oss på konvensjonelle oppfatninger av hva slags innhold de teksttypene vi behandler vanligvis inneholder samt innholds-/kontekstanalyse. Vi må også støtte oss til skjønnsmessige vurderinger. For å unngå vilkårlighet, dokumenterer vi alle løsninger. Vi dokumenterer også argumentasjonen bak avgjørelser om hvordan problematiske tilfeller kodes slik at både vi selv og våre brukere kan etterprøve arbeidet vårt.
Hvordan man konkret går fram i kodingen beskrives i kapitlene til de forskjellige delene av kodingen og i retningslinjene for de enkelte elementene.
kap-1.2.3: Dokumentanalyse
Vi bruker begrepet dokumentanalyse om to aktiviteter: 1) Dokumentanalyse som en grunnleggende gjennomgang av en teksttype/sjanger, og 2) dokumentanalyse foran arbeidet med en spesifikk tekstkilde.
kap-1.2.3.1: Teksttypeanalyse
Når vi skal sette i gang arbeidet med en ny type tekst eller sjanger, starter vi arbeidet med i fellesskap å bli enige om hvilke elementer som skal kodes. Dels dreier det seg om å definere hva slags elementer som fins i en teksttype/sjanger, og dels om å avgjøre hvilke av disse som vi ønsker å kode/dokumentere.
Resultatet av disse arbeidsmøtene legges inn her som lister over elementer som kodes i den aktuelle teksttypen/sjangeren, jfr. f.eks. «Tekstelementer i drama».
kap-1.2.3.2: Tekstkildeanalyse
Analyse av tekstkilden gjøres av den som skal kode det. Her varierer arbeidsmengden svært. Skal du opprette fil for transkripsjon av 12. utgave av et verk, baserer du transkripsjonen på 11. utgave, og er dermed vanligvis spart for alt arbeid med (om-)koding.
Skal du derimot i gang med koding av en 1. utgave eller en transkripsjon av arbeidsmanuskripter til et verk, må du sannsynligvis bruke en del mer tid på dokumentanalyse. Nedenfor er en skisse til arbeidsgang med tips.
- den fysiske tekstkilden
- hva slags tilstand er kilden i?
- er kilden komplett?
- er den skadet?
- er den et enkeltverk eller del av et samlet verk? får dette konsekvenser f.eks. for strukturkodingen?
- paratekst
- kontrollér arksignaturer
- gjennomgå paginering og foliering, fins det feil?
- ved manglende/ombyttede sidetall, sjekk om teksten er brutt (feil i trykkingen eller innbindingen) eller ikke (feil i sidenummereringen)
- struktur
- hvordan ser strukturen/hierarkiet ut?
- hva er øverste nivå?
- hvor mange <div>-nivå er det?
- har vi attributtverdier til type="" som dekker det du finner?
- hvis tekstkilden inneholder vers, konsultér metrikerne, forskningsassistentene Ingrid Falkenberg og Stine Brenna Taugbøl.
kap-1.3: Typografi
kap-1.3.1: Typografisk forståelse
Blanke, dvs. mellomrom mellom ord, er skilletegn. Skilletegn forekommer mellom ord i løpende tekst, som blanke på linjen, og som linjeskift mellom linjer i et avsnitt. Det fins ikke skilletegn i form av blanke/mellomrom på slutten eller starten av ei linje/et avsnitt. Det skal aldri være mer enn ett skilletegn mellom to ord, linjer, avsnitt etc.
Avstanden mellom avsnitt er derfor ikke linjer, men typografisk luft. Denne avstanden kodes ikke med linjeskiftskoder, men genereres i visningene våre. Det samme gjelder innrykk/hengende innrykk og større rom/avstand mellom setninger i avsnitt. Innrykkene er en del av avsnittets typografiske markering, mens mellomrommet mellom setninger i avsnitt er å regne som en blank (selv om det er større enn avstanden mellom ordene forøvrig).
kap-1.3.2: Vår behandling av blanke i XML-filene
Vi har vedtatt at typografisk utforming av tekstene først og fremst er et presentasjonsproblem som angår stilark/framvisningsprogram. Konsekvensen for kodingen er at vi ikke legger inn blanke alle steder hvor det skal være mellomrom mellom tekstelementer. I en del tilfeller legger vi likevel inn blanke, se nedenfor (<stage> i ren tekst i <l>/<p>).
<lb/><p>bla bla <stage>tekst</stage> bla bla</p> <lb/><p>bla bla bla bla <stage>tekst</stage></p> <lb/><l>bla bla <stage>tekst</stage> bla bla</l>
Men ikke i slike tilfeller (<stage> i <sp>, men utenfor <l>/<p>):
<lb/><sp><spOpener><speaker>rollenavn</speaker></spOpener>
<l>bla bla bla</l>
<stage>tekst</stage><l>bla bla bla bla</l></sp>
<lb/><sp><spOpener><speaker>rollenavn</speaker></spOpener>
<p>bla bla bla bla</p><stage>tekst</stage></sp>
Kriteriet for når man skal legge inne blanke og når man ikke skal gjøre det, ligger i DTD-definisjonen av elementene. Elementer som inneholder tekst (dvs. hvor deler av innholdet er definert som PCDATA) skal ha blanke før og/eller etter innskutte elementer (jf. eksemplene med <stage> i <p> ovenfor). Dette gjelder også innenfor <spOpener>; det skal være en blank mellom <speaker> og <stage> når de er plassert på samme linje. Elementer som er definert slik at tekst ikke kan skrives direkte i dem, skal ikke ha blanke ved påfølgende/etterfølgende element (jf. eksemplene med <l> og <stage> i <sp> ovenfor). Dette gjelder også alle elementer som er tillatt brukt direkte i <sp>.
Linjeskiftselementer (<lb/>) representerer også skilletegn i teksten; en <lb/> satt inn i løpende tekst, erstatter mellomrommet mellom ordene den settes inn mellom (merk at vi «rydder» teksten slik at <lb/>-elementene alltid ligger først på linjene).
kap-1.3.3: Typografisk «variasjon» mellom tekstkilder
Forskjellig typografi regnes ikke som variasjon. Med forskjellig typografi mener vi at forskjellige typografiske signaler markerer samme funksjonselement; f.eks. er en overskrift en overskrift selv om den ene tekstkilden understreker den, mens det andre sperrer overskriften.
Forskjell i funksjon regnes derimot som faktisk variasjon og kodes derfor, f.eks. når samme ord er uthevet i grunnteksten, men ikke i den påfølgende tekstkilden, det uthevede ordet blir da kodet med <emph> i grunnteksten, men ikke i tekstkilden.
Avvik fra det etablerte typografiske systemet i en tekst skal når det gjelder enkeltord som ikke er kodet på annen måte, kodes med <hi>; når hele innholdet i et element har avvikende typografi (for eksempel en overskrift) koder vi ikke med <hi>, men legger til rend="deviation" direkte i elementet. Avvik betyr vanligvis at ett eller flere av de typografiske trekkene mangler og ikke at deler av f.eks. understrekingen av en sceneanvisning mangler (slike unøyaktigheter dokumenteres ikke, men normaliseres i transkripsjonen). Avvik på enkelttegn-nivå (mindre/større/fete enkelttegn) kodes heller ikke med <hi>, se Avvikende markering av tegn i trykte tekster nedenfor.
Den faktiske typografiske utformingen av teksten som er kodet med <hi> eller rend="deviation", skal redegjøres for i typografibeskrivelsen i <teiHeader>.
rend=""-attributt kan brukes unntaksvis i <hi> når man har behov for å kode med <hi> for forskjellige formål innenfor samme element (f.eks. både enkel og dobbel understreking av ord i et avsnitt).
Attributtet hand="" kan brukes når det (i håndskrifter) forekommer understrekinger e.l. med annen hånd enn hovedhånden. Bemerk imidlertid at det ikke alltid tas hensyn til alle hender i håndskrifter.
kap-1.3.5: Avvikende markering av tegn i trykte tekster
I trykte tekster hender det at man kommer over slurvete satt tekst med feil. F.eks. forekommer det at det er brukt større, mindre eller fete enkelttegn der teksten rundt er satt med jevn størrelse og uten utheving. Vi har sett tilfeller hvor det er brukt mindre punktum og fete punktum, og større/mindre/fete bokstaver midt inne i ord. Det forekomemr også tilfeldig/feilaktig sperring av ord/deler av ord. Disse feilene i satsen blir ikke kodet. I spesielle tilfeller blir satsfeil kommentert i <note resp="editor">; dette gjelder f.eks. for snudde typer (der vi transkriberer tegnet riktig vei).
Store uregelmessigheter i plasseringen av interpunksjonstegn (stor variasjon i avstanden mellom interpunksjonstegnet og foregående tekst), bemerkes i typografibeskrivelsen. Det skal sterke argumenter til for å legge inn mellomrom mellom interpunksjonstegn og tekst. Vi gjør dette f.eks. når punktum mangler før parentes i slutten av en sceneanvisning i et trykk hvor sceneanvisningssystemet er slik at det vanligvis er punktum før parentes (eller hvor mellomrommet åpenbart indikerer at punktum har falt ut av satsen). I slike tilfeller setter man inn en note samt et mellomrom mellom siste ord og sluttparentes.
<stage>(vaklende )
<note resp="editor">Punktum mangler.</note>
</stage>
kap-1.3.6: Kapitler
I en del trykte tekstkilder er markeringer i teksten gjort ved kapitler. Kapitler skal transkriberes med minuskler, unntatt fra denne regelen er første bokstav i ord som innleder setninger samt navn.
En <teiHeader> består av fire hoveddeler; <fileDesc>, <encodingDesc>, <profileDesc> og <revisionDesc>. Disse fire delene er igjen delt opp i underpunkter. Nedenfor følger en gjennomgang av de elementene vi bruker i våre teiHeadere.
En rekke elementer har standardisert innhold. Noen av standardtekstene ligger i fulltekst i kodepraksis og kan hentes herfra; andre hentes inn vha. entiteter.
kap-2.1: Filbeskrivelse – <fileDesc>
Filbeskrivelsen inneholder opplysninger om den elektroniske teksten og om det kildematerialet den er basert på. Her fins dessuten opplysninger om hvilken utgave av den elektroniske teksten filen inneholder samt hvem som har arbeidet med den.
<titleStmt> skal inneholde opplysninger om filen, ikke verket. Opplysninger som må være med:
- <title level="s" type="main"> – hovedtittel for HIS
- <title level="s" type="sub"> – undertittel for HIS
- <title level="a" type="main"> – hovedtittel for verket
- <title level="a" type="sub"> – tekstens status i HIS
- <title level="a" type="origYear"> – tekstens utgivelsesår/datering
level="s" betyr at det er snakk om «series» (omfatter flere bind); level="a" står for «analytic» (del av et bind)
Hoved- og undertittel for HIS er i grunntekst- og tekstkildefilene alltid de samme:
<title level="s" type="main">Henrik Ibsens skrifter</title> <title level="s" type="sub">Diplomatarisk tekstarkiv</title>
Hovedtittel for verket anføres med HIS's valgte stavemåte. Skarpe klammer rundt HIS-tittelen brukes bare i de sjeldne tilfeller hvor verket ikke har tittel fra før, inntil nå bare ved Episk Brand:
- KE: <title level="a" type="main">Kongs-Emnerne<title>
- BE: <title level="a" type="main">[Episk Brand]<title>
Tekstens status i HIS kan inneholde opplysninger om hvilken hovedversjon teksten tilhører (hvis det er flere versjoner av verket), om det er en grunntekst, utgavenummer (innenfor HIS), manuskriptsignatur, om det er en FU-tekst. Filologene utarbeider lister over tekstenes tilhørighet innenfor hvert verk. Eksempler:
- C150: <title level="a" type="sub">første hovedversjon, grunntekst, 1. utg.<title>
- C275: <title level="a" type="sub">annen hovedversjon, grunntekst, 1. utg.<title>
- C291: <title level="a" type="sub">annen hovedversjon, 2. utg.<title>
- C21395: <title level="a" type="sub">annen hovedversjon, NBO Ms. 4° 1395<title>
- DuFU: <title level="a" type="sub">FU<title>
- og ved spesielle teksttyper kan det legges til en kort for beskrivelse i parentes. Eksempler:
- Sapr: <title level="a" type="sub">grunntekst, 1. utg. (prolog)<title>
- K254: <title level="a" type="sub">annen hovedversjon, grunntekst, 1. utg. (føljetong)<title>
- K2238: <title level="a" type="sub">annen hovedversjon, TarkUiB NT238r (rollehefter)<title>
- K204: <title level="a" type="sub">annen hovedversjon, 2. utg. (utgave med Olaf Liljekrans)<title>
- F1S: <title level="a" type="sub">første hovedversjon, 2. utg. (særtrykk)<title>
- Sa872s: <title level="a" type="sub">grunntekst, TarkUiB NT872 (sufflørbok)<title>
- KE81923: <title level="a" type="sub">NBO Ms.8° 1923 (trykt eksemplar med rettelser)<title>
- Du39: <title level="a" type="sub">NBO Brevs. 39 (i brev)<title>
Tekstens utgivelsesår eller datering oppgives hvis den står i tekstkilden. Hvis ikke kan elementet stå tomt, for disse opplysninger skal gåes igjennom av filologene mot Tones manuskriptbeskrivelser før ferdigstillelse.
Videre i <titleStmt> følger:
- <author> – forfatter. Innenfor denne koden skal det stå 'Henrik Ibsen', medmindre teksten har psudonymet Brynjolf Bjarme som forfatter. Da anfører vi det slik: 'Brynjolf Bjarme (pseudonym for Henrik Ibsen)'. Det vil kanskje bli noen eksempler på tekster med usikker forfatter (imellom dikt og varia), og da kan man sette 'Henrik Ibsen' i skarpe klammer.
- <funder> – inneholder entiteten &funder; som henter frem en tekst som dokumenterer prosjektets finansiering
- <editor> – inneholder entiteten &editor; som henter frem en liste over de som er eller har vært vitenskapelig ansvarlige
- <respStmt> – her opplyses det om hvem som har arbeidet med en tekst, hva vedkommende medarbeider har gjort: konvertering, kollasjonering, koding og/eller korrektur/kodekontroll (kodeoppdateringer regnes som koding). Hver medarbeider føres kun en gang. Samkjør med statusrapportene under oppdatering. Dato er unødvendig (listen kan føres slik at de som er ansvarlige for/har gjort mest med ei fil føres øverst, jf. eks. nedenfor).
kap-2.1.1.1: Eksempler på <titleStmt>:
C275:
<titleStmt> <title level="s" type="main">Henrik Ibsens skrifter</title> <title level="s" type="sub">Diplomatarisk tekstarkiv</title> <title level="a" type="main">Catilina</title> <title level="a" type="sub">annen hovedversjon, grunntekst, 1. utg.</title> <title level="a" type="origYear">1875</title> <author>Henrik Ibsen</author> <funder>&funder;</funder> <editor>&editor;</editor> <respStmt> <resp>Konvertering fra Bergensmaterialet (cati50.txt) til prosjektspesifikk TEI SGML, juni 1998</resp> <name>Espen S. Ore</name> <resp>Konvertering til prosjektspesifikk TEI XML desember 2000</resp> <name id="HIS-IF">Ingrid Falkenberg</name> <resp>Koding, kollasjonering, korrekturlesing og oppdatering</resp> <name id="HIS-HL">Hanne Lauvstad</name> <name id="HIS-HY">Hallvard Ystad</name> <name id="HIS-MW">Mette Witting</name> <resp>Korrekturlesing og oppdatering</resp> <name id="HIS-HB">Hilde Bøe</name> <name id="HIS-MS">Margit Sauar</name> <resp>Kontrollkollasjon og kodekorrektur</resp> <name id="HIS-HMS">Henninge Margrethe Solberg</name> <name id="HIS-HG">Helene Grønlien</name> </respStmt> </titleStmt>
HGFU:
<titleStmt> <title level="s" type="main">Henrik Ibsens skrifter</title> <title level="s" type="sub">Diplomatarisk tekstarkiv</title> <title level="a" type="main">Hedda Gabler</title> <title level="a" type="sub">FU</title> <title level="a" type="origYear">1900</title> <author>Henrik Ibsen</author> <funder>&funder;</funder> <editor>&editor;</editor> <resp>Konvertering og koding</resp> <name id="HIS-JMH">Jens-Morten Hanssen</name> <resp>Kollasjonering</resp> <name id="HIS-III">Ingunn Indrebø Ims</name> <name id="HIS-HMS">Henninge Margrethe Solberg</name> <name id="HIS-AAH">Åshild Haugsland</name> <resp>Kodekontroll</resp> <name id="HIS-MW">Mette Witting</name> </respStmt> </titleStmt>
Fj4504:
<titleStmt> <title level="s" type="main">Henrik Ibsens skrifter</title> <title level="s" type="sub">Diplomatarisk tekstarkiv</title> <title level="a" type="main">Fjeldfuglen</title> <title level="a" type="sub">UBiT Ms. 504, 4°</title> <title level="a" type="origYear">1859</title> <author>Henrik Ibsen</author> <funder>&funder;</funder> <editor>&editor;</editor> <respStmt> <resp>Kollasjonering, koding og korrektur</resp> <name id="HIS-EN">Ellen Nessheim</name> <name id="HIS-SBT">Stine Brenna Taugbøl</name> </respStmt> </titleStmt>
Fil basert på ekstern transkripsjon, K2238:
<titleStmt> <title level="s" type="main">Henrik Ibsens skrifter</title> <title level="s" type="sub">Diplomatarisk tekstarkiv</title> <title level="a" type="main">Kjæmpehøien</title> <title level="a" type="sub">annen hovedversjon, TarkUiB NT238r (rollehefter)</title> <title level="a" type="origYear">1853</title> <author>Henrik Ibsen</author> <funder>&funder;</funder> <editor>&editor;</editor> <respStmt> <resp>Transkripsjon</resp> <name>Bjørg Harvey</name> <resp>Koding, korrektur og konvertering</resp> <name id="HIS-EN">Ellen Nessheim</name> <resp>Koding og korrektur</resp> <name id="HIS-IF">Ingrid Falkenberg</name> </respStmt> </titleStmt>
Br66a:
<titleStmt> <title level="s" type="main">Henrik Ibsens skrifter</title> <title level="s" type="sub">Diplomatarisk tekstarkiv</title> <title level="a" type="main">Brand</title> <title level="a" type="sub">2. utg.</title> <title level="a" type="origYear">1866</title> <author>Henrik Ibsen</author> <funder>&funder;</funder> <editor>&editor;</editor> <respStmt> <resp>Kollasjonering, koding og korrektur</resp> <name id="HIS-EN">Ellen Nessheim</name> <resp>Koding og korrektur</resp> <name id="HIS-HB">Hilde Bøe</name> <resp>Kollasjonering</resp> <name id="HIS-IAA">Ingvald Aarstein</name> </respStmt> </titleStmt>
kap-2.1.2: Tekstens utgave – <editionStmt>
I <editionStmt> føres opplysninger om de utgavene som opprettes underveis i arbeidet; dvs. versjonsspesifikke opplysninger.
Elementet <edition> skal inneholde attributtet id="" med en unik attributtverdi som er lik tekstkildeforkortelsen + måned og år for siste validering.
<editionStmt> <edition id="HH85-1000"/> </editionStmt>
Når det opprettes nye utgaver, skal informasjonen i <editionStmt> endres.
kap-2.1.3: Publiseringsinfo – <publicationStmt>
<publicationStmt> inneholder standardopplysninger om publisering. Siden dette dreier seg om grunntekster og tekstkilder skal bare opplysninger om HIS-e med. I hovedtekstfilene kommer i tillegg et punkt om HIS-b. (NB! Det kan være innholdet her må justeres senere
når forholdene rundt e-utgaven blir endelig avklart).
<publicationStmt> <publisher>Universitetet i Oslo ved Henrik Ibsens skrifter</publisher> <distributor id="HISe">Universitetet i Oslo</distributor> <date value="2007" id="HISe-date">2007</date> <pubPlace>Oslo</pubPlace> </publicationStmt>
Brukes til å gi informasjon om hvor mye hver enkel tekstkilde varierer i forhold til grunnteksten innenfor et verk. Se avsnittet Antall varianter - <notesStmt> i Ekstern variasjons-kapitlet.
<bibl id="">/<msDescription type="" id=""> i <sourceDesc> skal inneholde bibliografiske opplysninger om tekstkilden som er transkribert, jf. eksemplene under. Ordlyden for tittel- og utgaveopplysninger hentes fra tittelbladet/i ms-et. Hvis opplysninger om henholdsvis forfatternavn, datering og/eller tittel mangler skrives: "Uten forfatternavn", "Uten datering" eller "Uten tittel". Følgende utgavetyper uten eksplisitte utgaveopplysninger på tittelbladet er standardisert til: "Førsteutgave" og "Folkeutgave". Hvis det dukker opp opplysninger som ikke dekkes av eksemplene nedenfor og som man mener bør med, skal man konsultere et kodemøte eller spørre på kodelisten.
id=""-attributtet i <bibl>/<msDescription> skal inneholde tekstkildens verks- eller vitnenummer. I grunnteksten plasseres id="" for verket i <bibl>, mens id="" for enkelteksemplarene plasseres i <idno>. For tekstkilder som ikke er grunntekster holder det med id="" i <bibl>/<msDescription>. Hvilke opplysninger som er tatt med for håndskrifter er delvis avgjort i samarbeid med manuskriptansvarlig Tone Modalsli. For trykte tekstkilder er malen laget i forhold til de vanligste opplysningene på tekstkildens tittelside.
Forøvrig skal alle eksemplarer som er benyttet som grunnlag for oppretting av tekstkilder, identifiseres vha. <idno>. For trykte tekstkilder benyttes dokid-nummeret fra BIBSYS som identifikasjonsnummer (f.eks. 74ga01305). Hvis eksemplaret ikke er registrert i BIBSYS, benyttes bibliotekets oppstillingssignatur (f.eks. Na/a b 65/si). For håndskrifter benyttes manuskriptsignaturen (f.eks. Ms 8° 2586).
Rekkefølgen på elementene er bindende slik eksemplene er satt opp nedenfor.
Hvis filen er grunntekstfilen for et verk inneholder den ev. variantene fra flere av verkets tekstkilder. Alle de aktuelle tekstkilder må da listes opp i <listBibl> etter <bibl>/<msDescription> (se eks. i kap. 1.4.2).
kap-2.1.5.1: Opplysninger om kildefil
Hvilket kildemateriale XML-filen bygger på plasseres aller først i <sourceDesc>. Her er de vanlige kildene:
- Bergensmaterialet
- XML/(SGML)-fil (vanligvis filen med foregående utgave). NB! Viktig å opplyse om hvilken versjon av filen man har brukt som basis!
- Eksternt transkribert materiale
- Internt transkribert materiale
- Materiale fra Museumsprosjektet (tidl. Dokumentasjonsprosjektet)
Eks.:
<sourceDesc> <p>Denne filen bygger på Br89.xml (Br89-0102).</p> <bibl>...</bibl> </sourceDesc>
kap-2.1.5.2: Trykte tekstkilder – enkeltverk (med liste over tekstkilder brukt i ekstern variantapparat)
Enkeltverk kodes i <monogr>.
<bibl id="C275"> <orgName type="owner">Deichmanske bibliotek</orgName> <idno id="C275f1"></idno> <orgName type="owner">Nasjonalbiblioteket</orgName> <idno id="C275f2">74ga05815</idno> <orgName type="owner">Vigdis Ystads eksemplar</orgName> <idno id="C275f3"></idno> <monogr> <author>Henrik Ibsen</author> <title type="main">Catilina</title> <title type="sub">Drama i tre Akter</title> <edition>Anden og gennemarbejdet Udgave</edition> <imprint> <pubPlace>København</pubPlace> <publisher>Gyldendalske Boghandels Forlag (F. Hegel)</publisher> <printer>Thieles Bogtrykkeri</printer> <date>1875</date> </imprint> </monogr> </bibl> <listBibl> <head>Tekstkilder inkludert i det eksterne variantapparatet</head> <msDescription type="workingManuscript" id="C21938-1"> <msIdentifier> <settlement>Oslo</settlement> <repository>Nasjonalbiblioteket</repository> <idno>NBO Ms.8° 1938:1</idno> </msIdentifier> <msHeading> <author>Uten forfatternavn</author> <title type="main">Uten tittel</title> <origDate>Uten datering</origDate> <matDesc>Ms.8° 1938:1. «Forord til anden udgave». Egenhendig utkast med rettelser.</matDesc> </msHeading> </msDescription> <msDescription type="workingManuscript" id="C21938-2"> <msIdentifier> <settlement>Oslo</settlement> <repository>Nasjonalbiblioteket</repository> <idno>NBO Ms.8° 1938:2</idno> </msIdentifier> <msHeading> <author>Uten forfatternavn</author> <title type="main">Uten tittel</title> <origDate>Uten datering</origDate> <matDesc>Ms.8° 1938:2. «Første akt». Påbegynt egenhendig renskrift med rettelser.</matDesc> </msHeading> </msDescription> <msDescription type="printersCopy" id="C21395"> <msIdentifier> <settlement>Oslo</settlement> <repository>Nasjonalbiblioteket</repository> <idno>NBO Ms.4° 1395</idno> </msIdentifier> <msHeading> <author>Henrik Ibsen</author> <title type="main">Catilina</title> <origDate>1875</origDate> <matDesc>Egenhendig renskrift med rettelser.</matDesc> </msHeading> </msDescription> <bibl id="C291"> <orgName type="owner">Ibsensenteret</orgName> <idno>74ga01151</idno> <monogr> <author>Henrik Ibsen</author> <title type="main">Catilina</title> <title type="sub">Drama i tre akter</title> <edition>Tredje udgave</edition> <imprint> <pubPlace>København</pubPlace> <publisher>Gyldendalske Boghandels Forlag (F. Hegel & Søn)</publisher> <printer>Græbes Bogtrykkeri</printer> <date>1891</date> </imprint> </monogr> </bibl> <bibl id="C2FU"> <orgName type="owner">Ibsensenteret</orgName> <idno>74ga05933</idno> <author>Henrik Ibsen</author> <title type="main">Catilina</title> <edition>Folkeutgave</edition> <series> <editor>J. B. Halvorsen</editor> <title>Samlede værker</title> </series> <imprint> <pubPlace>København</pubPlace> <publisher>Gyldendalske Boghandels Forlag (F. Hegel & søn)</publisher> <printer>Græbes Bogtrykkeri</printer> <date>1898-1902</date> </imprint> <monogr> <title>Samlede værker. Første bind. Catilina. Gildet på Solhoug. Fru Inger.</title> <imprint> <biblScope type="volume">Bd. 1</biblScope> <date>1898</date> </imprint> </monogr> </bibl> </listBibl>
kap-2.1.5.3: Trykte tekstkilder – samlede verker
Samleoppførelsen for samlede verker kodes i <series>, mens enkeltbind kodes i <monogr>. Legg merke til at <imprint> er tillatt innenfor <monogr>, men ikke innenfor <series>. For samleoppførelsen til de samlede verkene må altså <imprint> stå etter <series>.
<bibl id="K2FU"> <orgName type="owner">HIS</orgName> <idno>Ekspl. 1</idno> <author>Henrik Ibsen</author> <title type="main">Kæmpehøjen</title> <title type="sub">Dramatisk digtning i en akt</title> <edition>Folkeutgave</edition> <series> <editor>J. B. Halvorsen</editor> <title>Samlede værker</title> </series> <imprint> <pubPlace>København</pubPlace> <publisher>Gyldendalske Boghandels Forlag (F. Hegel & søn)</publisher> <printer>Græbes Bogtrykkeri</printer> <date>1898-1902</date> </imprint> <monogr> <title>Samlede værker. Tiende bind (supplementsbind)</title> <imprint> <biblScope type="volume">Bd. 10</biblScope> <date>1902</date> </imprint> </monogr> </bibl>
<bibl id="C2HU"> <orgName type="owner">HIS</orgName> <idno>Ekspl. 1</idno> <author>Henrik Ibsen</author> <title type="main">Catilina</title> <edition>Hundreårsutgave</edition> <series> <editor>Francis Bull, Halvdan Koht og Didrik Arup Seip</editor> <title>Hundreårsutgave. Henrik Ibsens samlede verker</title> </series> <imprint> <pubPlace>Oslo</pubPlace> <publisher>Gyldendal</publisher> <printer>Dreyer, Stavanger</printer> <date>1928-57</date> </imprint> <monogr> <title>Samlede verker. Første bind. Catilina. Kjæmpehøien. Norma.</title> <imprint> <biblScope type="volume">Bd.1</biblScope> <date>1928</date> </imprint> </monogr> </bibl>
kap-2.1.5.4: Trykte tekster – føljetonger
For føljetonger kodes Ibsens tekst først, i <analytic>, dernest avisen/tidsskriftet som helhet, i <series> og til slutt de aktuelle avis-/tidsskriftnumrene i hver sin <monogr>. <edition> er ikke tillatt i <analytic> og må derfor legges mellom <analytic> og <series>, men den hører altså til <analytic>.
<bibl id="No51"> <orgName type="owner">Universitetsbiblioteket i Oslo</orgName> <idno id="No51f1">NA/A b 65/si</idno> <orgName type="owner">Universitetsbiblioteket i Oslo</orgName> <idno id="No51f2">Schw 19</idno> <orgName type="owner">Bergen offentlige bibliotek</orgName> <idno id="No51f3">h 050 A552</idno> <analytic> <author>Henrik Ibsen</author> <title type="main">Norma</title> <title type="sub">eller en Politikers Kjærlighed, Musik-Tragedie i tre Akter</title> </analytic> <edition>Førsteutgave</edition> <series> <editor>Henrik Ibsen, Paul Botten-Hansen, Aasmund Olavsson Vinje</editor> <title level="s">Andhrimner</title> </series> <imprint> <pubPlace>Kristiania</pubPlace> <publisher>N. F. Axelsen</publisher> <printer>A. Th. Nissens Bogtrykkeri</printer> </imprint> <monogr> <title level="s">Andhrimner</title> <title level="a">Norma, [fortale og 1. akt]</title> <imprint> <biblScope type="issue">2. kvartal, nr. 9</biblScope> <date value="1851-06-01">1. juni 1851</date> </imprint> </monogr> <monogr> <title level="s">Andhrimner</title> <title level="a">Norma, [2. og 3. akt]</title> <imprint> <biblScope type="issue">2. kvartal, nr. 10</biblScope> <date value="1851-06-08">8. juni 1851</date> </imprint> </monogr> </bibl>
kap-2.1.5.5: Håndskrifter
- <matDesc> – opplysninger om vitnets innhold (bruk manuskripttypologi), oppl. om egenhendig/ikke egenhendig, utelatt materiale (f.eks. i tilfeller hvor et fysisk ms inneholder vitner fra forskjellige verk, jf. «Materiale til flere verk i samme manuskript»). I brev (som ikke har noen typografibeskrivelse) kan opplysninger om skriblerier og hender som ikke transkriberes, gjennomgående vanskelig lesbare bokstaver eller bokstaver som kan forveksles etc. legges i <matDesc>. Jf. brevkapitlet.
- <title> – tittel funnet i manuskriptet, hvis tittel mangler skal man sette «Uten tittel». Titler suppleres altså bare i <titleStmt>, ikke i <sourceDesc>.
- <author> – hvis forfatternavnet står i manuskriptet noteres det her. Hvis forfatternavnet mangler skal vi skrive «Uten forfatternavn».
- <origDate> – som <title>; datering i manuskriptet brukes.
- Stammer datering fra brev med ms-fragmenter, kan dette kommenteres i <note>.
- I manuskripter uten datering, skriv 'Uten datering'.
NB! Opplysningene i <msDescription> må sammenholdes og synkroniseres med Tone Modalslis manuskriptbeskrivelser.
<msDescription type="finalFairCopy" id="F28950"> <msIdentifier> <settlement>Oslo</settlement> <repository>Nasjonalbiblioteket</repository> <idno>NBO Ms 8° 950</idno> </msIdentifier> <msHeading> <author>Henrik Ibsen</author> <title type="main">Fru Inger til Østråt</title> <title type="sub">Skuespil i fem handlinger</title> <origDate>1874</origDate> <matDesc>Renskrift, egenhendig</matDesc> </msHeading> </msDescription>
En fullstendig oversikt over hvilke rollehefter/manuskripter (hvis flere) som inngår i fila skal plasseres i <msContents> i <msDescription>. Man kan også legge inn ekstra opplysninger om f.eks. feil i organiseringen/innbindingen av materialet.
<msDescription type="workingManuscript" id="BE428691"> <msIdentifier> <settlement>København</settlement> <repository>Kbl.Bibl.Kbh.</repository> <idno>KBK NKS 2869, 4°, 1</idno> </msIdentifier> <msHeading> <author>Uten forfatternavn</author> <title type="main">Uten tittel</title> <origDate>Uten datering</origDate> <matDesc>Egenhendig arbeidsmanuskript, dels kladd, dels renskrift. Se forøvrig Tone Modalslis manuskriptbeskrivelse.</matDesc> </msHeading> <msContents> <msItem><locus>poem 1a (I, bl. 1-2):</locus><title>«Till de medskyldige»</title><note>Opplysningene (i locus) "poem" og "3a" er fra henholdsvis type og n i div, tallene i parentes er fra ordningen av materialet samt henvisning til blyantfoliering i manuskriptmaterialet, rekkefølgen på locus-elementene er identisk med HIS' ordning av materialet.</note></msItem> <msItem><locus>poem 2a (I, 3):</locus><title>«Fra Modningstiden»</title></msItem> <msItem><locus>poem 3a (II, 4-16):</locus><title>«Over Storfjellet»</title></msItem> <msItem><locus>poem 4a (II, 17-26):</locus><title>«To paa Kirkevejen»</title></msItem> <msItem><locus>poem 5 (II, 27-30):</locus><title>«Ved Kirken»</title></msItem> <msItem><locus>poem 2b (III, 31-32):</locus><title>«Fra Modningstiden»</title></msItem> <msItem><locus>(IV, 33):</locus><title>replikkutkast</title></msItem> <msItem><locus>poem 1b (V, 34-35):</locus><title>«Till de medskyldige!»</title></msItem> <msItem><locus>poem 2c (V, 36-41):</locus><title>«Fra Modningstiden»</title></msItem> <msItem><locus>poem 3b (VI, 42-51):</locus><title>«Over Storfjellet»</title></msItem> <msItem><locus>poem 4b (VI, 52-61):</locus><title>«Kirkevejene»</title></msItem> </msContents>
<msDescription type="parts" id="Sa872r">
<msIdentifier>
<settlement>Bergen</settlement>
<repository>Teaterarkivet, Universitetet i Bergen</repository>
<idno>N. T. 872</idno>
</msIdentifier>
<msHeading>
<author>Henrik Ibsen</author>
<title type="main">Sancthansnatten</title>
<origDate>Uten datering</origDate>
<matDesc>Rollehefter, ikke egenhendig</matDesc>
</msHeading>
<msContents>
<msItem n="Sa872r-Anne"><locus>58 sider</locus><title>
«Annes Rolle i Sancthansnatten af Henr. Ibsen»</title></msItem>
<msItem n="Sa872r-Paulsen"><locus>68 sider</locus><title>
«Paulsens Rolle i Sancthansnatten af Henr: Ibsen»</title></msItem>
<msItem n="Sa872r-JohannesBirk"><locus>68 sider</locus><title>
«Birks Rolle i Sancthansnatten, af Henr: Ibsen.»</title></msItem>
<msItem n="Sa872r-Juliane"><locus>42 sider</locus><title>
«Julianes Rolle i Sancthansnatten af Henr. Ibsen»</title></msItem>
<msItem n="Sa872r-Nissen"><locus>10 sider</locus><title>
«Nissens Rolle i Sancthansnatten af Henr: Ibsen»</title></msItem>
<msItem n="Sa872r-Jørgen"><locus>29 sider</locus><title>
«Jørgens Rolle i Sancthansnatten af Henr. Ibsen»</title></msItem>
<msItem n="Sa872r-FruBerg"><locus>28 sider</locus><title>
«Fru Bergs Rolle i Sancthansnatten af Henr: Ibsen»</title></msItem>
<msItem n="Sa872r-Berg"><locus>21 sider</locus><title>
«Bergs Rolle i Sancthansnatten af Henr: Ibsen»</title></msItem>
<msItem n="Sa872r-UngErik"><locus>2 sider</locus><title>
«Ung Erik i Pantomimen i 2den Act af Sancthansnatten. Eventyrcomedie i
3 Acter af Henr: Ibsen.»</title></msItem>
<msItem n="Sa872r-Svanhvide"><locus>2 sider</locus><title>
«Svanhvide i Pantomimen i 2den Act af Sancthansnatten. Eventyrcomedie i
3 Acter ved Henr. Ibsen.»</title></msItem>
<msItem n="Sa872r-Bjergkongen"><locus>4 sider</locus><title>
«Bjergkongen i Pantomimen i 2den Act af Sancthansnatten. Eventyrcomedie i
3 Acter ved Henr. Ibsen.»</title></msItem>
<msItem n="Sa872r-LidenKarin"><locus>3 sider</locus><title>
«Liden Karin i Pantomimen i 2den Act af Sancthansnatten. Eventyrcomedie i
3 Acter ved Henr. Ibsen.»</title></msItem>
</msContents>
</msDescription>
Elementet skal inneholde beskrivelser av prosjektet (<projectDesc>), den filologiske praksis (<editorialDecl>), kodingen av tekstene (<tagsDecl>) og hvilken type variantapparater prosjektet bruker (<variantEncoding/>).
kap-2.2.1: Prosjektbeskrivelse – <projectDesc>
OBS: Sjekk at entiteten svarer til den aktuelle teksttype.
For prosjektbeskrivelsen er det utarbeidet tre standardtekster: en for trykte grunntekster (&projectDesc-grt-trykk;), en for håndskrevne grunntekster (&projectDesc-grt-ms;) og en for øvrige tekstkilder (&projectDesc-tekstkilde;). Entiteten bestemmes altså etter teksttype; eksemplet nedenfor gjelder for trykte grunntekster:
<projectDesc>
<p>&projectDesc-grt-trykk;</p>
</projectDesc>
kap-2.2.2: Filologisk praksis – <editorialDecl>
Elementet <editorialDecl> inneholder beskrivelser av typografien til de tekstkildene som XML-filen inneholder. Dessuten inneholder <editorialDecl> elementer som deklarerer hva slags filologisk praksis som er fulgt i arbeidet med å kode teksten. Eksempler følger nedenfor.
kap-2.2.2.1: Typografibeskrivelse – <typography>
Typografien til hver enkel tekstkilde skal beskrives i elementet <typography>. Brevene unntas typografibeskrivelse, så pr. i dag (mars 2006) er det drama og dikt som skal ha typografibeskrivelse.
Beskrivelsen av grunntekstene blir brukt av filologene i den filologiske redegjørelse, mens typografibeskrivelsen av resten av tekstkildene utelukkende er til internt bruk i kollasjoneringsarbeidet. Beskrivelsene vil ikke bli publisert i sin nåværende form i HIS-e. Beskrivelsen bør gjøres tidlig i arbeidet, før eller i starten av kollasjoneringen av tekstkildene, slik at man slipper å bruke tid på typografien i kollasjoneringen.
Pr. mars 2006 er typografibeskrivelsen blitt forenklet. Fremover vil <typography> bli brukt som et sted å dokumentere vår transkripsjon og kodingens forhold til tekstkilden. Vi legger vekt på tre ting:
- typografiske fenomener som ikke kodes (f.eks. understreking, sperring)
- tekst vi normaliserer i transkripsjonen (f.eks. FU's omfattende bruk av kapitler som vi transkriberer med majuskler og minuskler)
- avvik fra systemet (f.eks. utheving av 'og' mellom rollenavn)
En del punkter og aspekter i de tidligere typografibeskrivelser er nå tatt bort, siden det enten kommer frem i kodingen (majuskler/minuskler) eller det blir ikke brukt og er ikke viktig i kodearbeidet. Det gjelder:
- majuskler/minuskler
- i parentes
- situasjonsbeskrivelsen (<set>)
- skillestreker, pyntestreker, bindestreker, tankestreker
- anførselstegn
- tall (renessanse- eller tabelltall)
- innrykk
- verselinjers justering
- replikk-justering
- typologisering av sceneanvisninger
Nedenfor følger en mal for alle tekstkilder (grunntekster, trykte tekstkilder og manuskripter), samt en egen utfylt mal for Folkeutgave-tekstene. I beskrivelsene av de enkelte markerte elementer bruker vi termene: sperret, kursiv, forstørret/formindsket (når det er tydelig forstørret/formindsket), fet, understreking og kapitler.
Generell mal:
<typography>
<list>
<item>Skriftgruppe: (antikva/gotisk)</item>
<item>Tittelblad (og ev. deltittelblad): (beskriv de deler (hovedtittel, undertittel, «byline», forfatternavn, utgave, sted, forlag, trykkeri, trykkeår...) som er markert)</item>
<item>Overskrifter:
<list>
<item>ved rollelisten: </item>
<item>ved akt: </item>
<item>andre (f.eks. ved forord): </item>
</list>
</item>
<item>Rollenavn:
<list>
<item>i rollelisten (også rollebeskrivelsen hvis den er markert): </item>
<item>over replikk (husk ev. 'og' mellom rollenavn): </item>
</list>
</item>
<item>Utheving:
<list>
<item>i replikk ('emph', 'foreign'): </item>
<item>i sceneanvisninger ('stageRole' - husk ev. 'og' mellom navnene): </item>
</list>
</item>
<item>Topp- og bunntekst:
<list>
<item>arksignaturer: </item>
<item>sidetall: </item>
</list>
</item>
<item>Transkripsjonsnormaliseringer (f.eks. FU's bruk av kapitler, ø med tødler i svenske og tyske navn...): </item>
<item>Annet:
<list>
<item>ved trykk (f.eks. svakheter i trykket): </item>
<item>ved manuskripter (f.eks. bruk av enkel og dobbel understreking i ubeskrevne elementer ('set', 'roleDesc', 'stage'...), diakritiske tegn (manglende prikk over i, manglende tødler over ø...)): </item>
</list>
</item>
</list>
</typography>
Mal for FU-tekstene:
<typography>
<list>
<item>Skriftgruppe: antikva</item>
<item>Deltittelblad: hovedtittelen er forstørret</item>
<item>Overskrifter:
<list>
<item>ved rollelisten: forstørret, sperret</item>
<item>ved akt: forstørret, sperret</item>
</list>
</item>
<item>Rollenavn:
<list>
<item>i rollelisten: kapitler (alle tegn er like store)</item>
<item>over replikk (husk ev. 'og' mellom rollenavn): kapitler (alle tegn er like store), 'og' mellom rollenavn er satt med minuskler</item>
</list>
</item>
<item>Utheving:
<list>
<item>i replikk ('emph', 'foreign'?): sperret</item>
<item>i sceneanvisninger ('stageRole' - husk ev. 'og' mellom navnene?): kapitler</item>
</list>
</item>
<item>Topp- og bunntekst:
<list>
<item>arksignaturer: formindsket, tittel i kapitler (alle tegn er like store)</item>
<item>sidetall: (ingen spesiell markering)</item>
</list>
</item>
<item>Transkripsjonsnormaliseringer: FU's bruk av kapitler uten større forbokstav i rollenavn og arksignaturer er transkribert med majuskel og minuskler</item>
<item>Annet:
<list>
<item>ved trykk (f.eks. svakheter i trykket): </item>
</list>
</item>
</list>
</typography>
kap-2.2.2.2: <stdVals> – standardized values
<stdVals> inneholder en standardtekst om standardiserte verdier som brukes i koding av navn og datoer.
<stdVals>
<p>&stdVals;</p>
</stdVals>
kap-2.2.2.3: Lenke til tekstkritiske retningslinjer
Til slutt i <editorialDecl> opplyses det om prosjektets generelle filologiske praksis og det lenkes til tekstkritiske retningslinjer. Dette gjøres vha. en entitet. Strukturen ser slik ut:
<editorialDecl>
...
<stdVals><p>&stdVals;</p></stdVals>
<p>&editorialDecl;</p>
</editorialDecl>
kap-2.2.3: Kodedokumentasjon – <tagsDecl>
Vi bruker <tagUsage gi="">-elementer til å dokumentere spesiell kodepraksis i filene våre. Vår bruk av <tagsDecl> følger ikke TEIs retningslinjer, men vi har valgt å utvide bruken av koden for å ha et sted i <teiHeader> til å angi en referanse til de fullstendige koderetningslinjene for HIS, til å dokumentere spesiell kodepraksis i filene våre samt til å validere attributtverdier i who-attributtet, når det ikke finnes (komplett) rolleliste i filen for øvrig.
Hvis vi ønsker å registrere annen koding i <tagsDecl> må det tas opp til diskusjon enten på diskusjonslista eller på et kodemøte. Etterpå kan det legges inn et nytt <tagUsage gi="">-element i kodepraksis og i de aktuelle filer.
Innførslene i <tagsDecl> ordnes alfabetisk.
kap-2.2.3.1: <tagUsage gi="id-who">
I forbindelse med rollelistene har vi vedtatt at man alltid skal lage en oversikt i <tagUsage> som viser hvilke attributtverdier i id=""/who="" som korresponderer med hvilke rollenavn. Behovet for dette skyldes at det en del ganger er avvik mellom navnene i rollelisten og i selve stykket. Vi har også hatt tilfeller hvor en rolle har skiftet navn i løpet av stykket. (Se avsnittet id="" og det tilhørende who="" i Drama-kapitlet for nærmere beskrivelse).
Nedenfor er en skisse til koding av denne oversikten (som man kan se er det benyttet listekoding for å organisere opplysningene). Det skal spesifiseres hvilke navn som er brukt i de respektive elementene (<castItem>, <speaker> og <stageRole>).
<tagsDecl>
<tagUsage gi="id-who">
<list>
<headLabel>id=""</headLabel>
<headItem>castItem/speaker/stageRole</headItem>
<label>HAAKON</label>
<item>Haakon Haakonssøn/Haakon/Haakon Haakonssøn, Haakon,
Kong Haakon</item>
</list>
</tagUsage>
</tagsDecl>
Hvis det bare er brukt én navneform er det ikke nødvendig å føre opp navnet flere ganger. Manglende kategori markeres med - (strek).
Minuskel/majuskelvariasjon og tegnsetting tas ikke med. Feilstavede navneformer tas vanligvis heller ikke med, men grove trykkfeil (eks. i HH hvor Hjørdis er skrevet bakvendt – sidrøjH) kan tas med.
I tekstkilder hvor det ikke finnes rollelister (f.eks. rollehefter og arbeidsmanuskripter), plasserer man id=""-attributtene i <label>-elementene i <tagUsage>. Legg merke til at man da ikke tar med innførslen for castItem (og i eksemplet nedenfor fra Du39 heller ikke stageRole), da den er tom. Dessuten har vi forenklet kodingen i <label> siden innholdet i elementet og id=""-verdien ellers ville være identiske:
<tagUsage gi="id-who"> <list> <headLabel>id=""</headLabel><headItem>speaker</headItem> <label id="NORA"/><item>Nora</item> <label id="HELMER"/><item>Helmer</item> </list> </tagUsage>
I tekstkilder med ufullstendige rollelister legges id=""-attributtene så langt det rekker i rollelisten, de resterende legges i <label>-elementene i <tagUsage>.
I arbeidsmanuskripter hvor det er mer enn n rolleliste plasseres id=""-attributtene i den mest endelige rollelisten. Rollenavnene i de øvrige rollelistene skal ha et corresp=""-attributt med tilsvarende attributtverdi som i id=""-attributtene i hovedrollelisten. Variansen i rollenavn i rollelistene dokumenteres i <tagUsage gi="id-who">. I FH41116 er det tre rollelister, og her følger eksempler på koding av rollen Fru Wangel i <tagUsage gi="id-who">, i den mest endelige rollelisten og i en av de sekundære rollelister:
Fra teiHeader:
<headLabel>id=""</headLabel><headItem>castItem/speaker/stageRole</headItem> <label>ELLIDA</label><item>Fru Ellida Wangel, Fru Wangel/Ellida, Thora, Tora, Fru Wangel, E./-</item>
Fra hovedrollelisten:
<lb/><castList><head>Personerne:</head> <lb/><castItem id="ELLIDA">Fru Ellida Wangel, hans anden hustru.</castItem>
Fra den sekundære rolleliste:
<lb/><castList><head>Personerne.</head> <lb/><castItem corresp="ELLIDA">Fru Wangel, hans anden hustru.</castItem>
I arbeidsmanuskripter hvor replikkene ikke har dramaoppsett, men er formet som prosa og derfor er kodet med <q who=""> kan <item> i <tagUsage gi="id-who"> stå tom:
<tagUsage gi="id-who"> <list> <headLabel>id=""</headLabel> <label id="BOLETTE"/><item></item> <label id="HILDE"/><item></item> <label id="ARNHOLM"/><item></item> </list> </tagUsage>
NB! Dette siste kodeeksempel er helt skrabet siden <tagUsage gi="id-who"> da bare brukes til å få validert who=""-verdiene som er brukt i filens <q>-elementer.
kap-2.2.3.2: <tagUsage gi="pb-ed-HU">/<tagUsage gi="pb-ed-HU-n">
Alle tekstkilder (unntatt rolleheftene og tekstkilder som ikke inneholder sammenlignbar tekst med HU) skal inneholde sideskiftsmarkering fra Hundreårsutgaven. Dette noteres også i <teiHeader>, jfr. oppskrift nedenfor:
<tagUsage gi="pb-ed-HU">For synkroniseringsformål er sideskiftene fra Hundreårsutgaven (bd V) kodet
med pb ed="HU". Dette tekstvitnet dekker sidene 175-362. Det første
sidetallet er oppgitt i et n-attributt.</tagUsage>
I filer som inneholder tekstkilder som ikke er kronologisk organisert eller som mangler enkeltsider, legger vi også inn n=""-attributtet. I <tagUsage> markeres det slik:
<tagUsage gi="pb-ed-HU-n">For synkroniseringsformål er sideskiftene fra Hundreårsutgaven
(bd X) kodet med pb ed="HU" n="". Dette tekstvitnet dekker
sidene 175-362. Alle sidetall er oppgitt i n-attributter.</tagUsage>
Se også «Lenkekoding».
kap-2.2.3.3: <tagUsage gi="tei.2">
Elementet <tagUsage gi="tei.2"> inneholder en entitet som henter frem en standardtekst med lenker til Kodepraksis og TEI P4.
<tagUsage gi="tei.2">
&tagUsage-tei2;</tagUsage>
kap-2.2.4: Om verskoding og notasjonssystem – <metDecl>
Metrisk koding er forbeholdt hovedtekstene, men i grunntekster der det er avvikende metrisk struktur skal det gjøres rede for verskoding og notasjonssystem. Dette gjøres innenfor <metDecl>, mellom <tagsDecl> og <variantEncoding/>. Følgende standardtekst skal inn:
<metDecl>
<p>&metDecl;</p>
</metDecl>
Det finnes tre typer variantapparater i våre filer med hver sin deklarasjon her i <teiHeader>. For hver fil må man undersøke hvilke typer apparater som finnes, og de tilhørende deklarasjoner må føres opp.
De tre apparattyper og deres deklarasjon er:
- <variantEncoding type="alteration" method="parallel-segmentation" location="internal"/> - Manuskriptendringer kodet i apparat
- <variantEncoding type="external" method="parallel-segmentation" location="internal" n=""/> - Ekstern variantapparat
- <variantEncoding type="internal" method="parallel-segmentation" location="internal" n=""/> - Intern variantapparat
Opplysningene i de første to attributtene til <variantEncoding/> forteller at vi benytter metoden «parallel segmentation» og at vi koder variantapparatene internt i tekstene (se beskrivelsen av <variantEncoding/> under <encodingDesc> på hjemmesiden til TEI P4).
Type-attributtet har HIS selv lagt til for å skille de tre apparattyper fra hverandre. Attributtverdiene "external", "internal" og "alteration" er de samme som brukes i <app> i <text>. N-attributtet skal inneholde antallet av henholdsvis interne og eksterne varianter i filen, og opplysningen skal brukes til lage statistikk.
I <profileDesc> skal opplysninger om tekstkilden/verket dokumenteres. Vi tar vare på opplysninger om hvilke språk som brukes i tekstene, samt for håndskriftsmaterialet, hvilke hender som fins.
kap-2.3.1: Språkbruk – <langUsage>
I dette elementet skal alle språk i fila, både i <teiHeader> og i <text>, defineres. Eksemplet nedenfor viser hvordan vi gjør dette:
<langUsage>
<language id="nob"/>
<language id="Dano-Norwegian"/>
<language id="lat"/>
<language id="ger"/>
</langUsage>
Eksemplet er fra No (Norma).
Attributtverdiene er hentet fra ISO-standarden for språkkoder, 639-2 (med tre bokstaver). Attributtverdiene i eksemplene ovenfor er forkortelser for følgende språk:
- nob – norsk bokmål
- lat – latin
- ger – tysk
- eng – engelsk
Dansk-norsk er naturlig nok ikke inkludert i ISO-standarden. Derfor benytter vi vårt opprinnelige "Dano-Norwegian"; den avvikende formen gjør det også tydelig at denne språkkoden er egendefinert.
Dersom det dukker opp flere språk i Ibsens tekster, må det gis beskjed om dette til teiHeader-redaktøren, slik at dette punktet kan inneholde en komplett oversikt over språkene og de tilhørende språkverdiene som er i bruk.
Attributtverdiene i id="" benyttes i attributtet lang="" i <foreign> eller andre elementer når (typografisk markerte) tekststeder har annet språk enn hovedspråket. Språket i <teiHeader> og i tekstene legges i lang=""-attributter i de respektive taggene: <teiHeader lang="nob">, <text lang="Dano-Norwegian">.
kap-2.3.2: Håndskriftets hender – <handlist>
NB! Håndattribueringen i xml-filene må samkjøres med Tone Modalslis manuskriptbeskrivelser.
I håndskriftsmateriale er det nødvendig å sette opp ei liste over hvilke hender som har hatt befatning med håndskriftet. Vi gjør dette selv om det bare fins ei hånd. Hovedkriteriene for håndattribuering er redskap og farge. Kvalitet kan brukes som tilleggskriterium der det er nødvendig/hensiktsmessig.
<handList>
<hand hand="HI-1" id="HI-1" ink="pen-black" first="yes"><p>Sort penn.
Henrik Ibsen. Hovedhånd</p></hand>
<hand hand="HI-2" id="HI-2" ink="pencil"><p>Blyant. Henrik Ibsen. Enkelte rettelser.</p></hand>
<hand hand="h1" id="h1" ink="pen-red"><p>Rød penn,
steilskrift. Ukjent hånd. Enkelte rettelser</p></hand>
<hand hand="h2" id="h2" ink="pencil"><p>En eller flere blyanter. Bibliotekar(er)? Bladfoliering.</p></hand>
</handList>
Elementet <hand> skal inneholde attributtene hand="", id="" og ink="" og evt. character="".
I hand="" skiller vi mellom identifiserte og uidentifiserte skrivere vha. attributtverdiene. Identifiserte skrivere får initialene som verdi (evt. med nummerering). For Ibsens vedkommende ALLTID med nummerering etter også selvom det bare er en hånd, HI-1. Uidentifiserte får kun h + nummer. Identifiserte skriveres attributtverdier rapporteres til redaktøren for attributtverdilisten.
id="" skal inneholde samme verdi som hand="" og er obligatorisk.
Verdiene som skal brukes i ink="" er definert i attributtverdilista, men en oversikt over manuskriptansvarlig Tone Modalslis fargebetegnelser (brukt i K1) fins nedenfor.
- brunsort
- bare en sjelden gang noterer TM at noe av skriften er «i brunere blekk» for å skjelne dette fra resten av skriftbildet. Også vi bør være forsiktige med å skjelne mellom fargenyanser når vi deler inn i hender
- mørkt brunt
- blåsort
- rødt
- fiolett
Trenger man nye verdier lages de over samme mal som eksisterende verdier og postes på kodelista.
Hovedhånden (eller den første hånden i et manuskript med flere «hovedhender») skal dessuten ha attributtet first="" med verdien «yes». Vi tolker TEIs formulering «first indicates the first scribe in the document» som at attributtet indikerer hvilken hånd som skriver fra begynnelsen av manuskriptet og/eller skriver hoveddelen av manuskriptet.
Attributtverdier til character="" fins i attributtverdilista.
<p>-elementet skal inneholde en kort beskrivelse av håndens særtrekk: skriveredskap, farge, skriftsærtrekk (jf. begreper om skriftstil og skrifthelling i typografibeskrivelsen). I <p> skal det også presiseres hvor de ulike hendene skriver og hva de bidrar med etc. (f. eks. foliering, rettelser). Det skal ikke brukes mye tid på å skjelne mellom fargenyanser og hvis man er usikker på hvorvidt man bør dele inn i eller slå sammen hender, bør man notere dette i håndlista og konferere med TMs manuskriptbeskrivelser ved samkjøring med hennes inndeling i hender.
Merk at våre hand=""-attributter ikke indikerer antall faktiske skrivere, men hvor mange skriveredskaper som med rimelighet kan skilles fra hverandre i et manuskript. Dette innebærer for eksempel både at Ibsen har «flere hender» og at flere tilfeldige blyanthender kan slås sammen til en «hånd» når det ikke er mulig å skille mellom dem. Vi skiller imidlertid alltid ut hånden som har paginert eller foliert manuskriptet som en egen hånd når denne utgjør f.eks. en av flere uidentifiserte blyanthender og når den ikke er Ibsens hovedhånd.
kap-2.4: Loggføring – <revisionDesc>
Loggbøker skal føres i <teiHeader> i elementet <revisionDesc>. Loggen skal føres «nedenfra og opp», slik at nyeste innførsel ligger øverst/først og eldste innførsel nederst/sist. Hver innførsel må inneholde disse elementene for å bli validert:
<change> <date>03.12.04</date> <respStmt> <name>SBT</name> <resp>Kodekontroll</resp> </respStmt> <item>Utførte kodekontroll og gjennomgikk typografibeskrivelsen. Validert</item> </change> <change> <date>10.10.04</date> <respStmt> <name>MW</name> <resp>Koding</resp> </respStmt> <item>Førte inn resultatene etter annenkollasjonen</item> </change>
<change> inneholder en innførsel av endringer som er gjort. <date> inneholder datoen for når endringen(e) er foretatt. <respStmt> identifiserer hvem som har gjort hva: <resp> skal inneholde en fellesnevner for det som er gjort, en slags overskrift. <name> inneholder initialene til den som har arbeidet i filen. <item> inneholder en oversikt over hva som er gjort. Vi pleier også å legge inn oppsummerende loggføringer over hva som gjenstår når vi anser oss for å være ferdige med et stadium i tekstkodingen.
At kodekorrektur er foretatt skal føres inn i loggen av den som har lest korrektur.
Ferdige filer får utgavebetegnelse i <editionStmt> og blir brent på cd samt ført inn i statusrapporten. Etter kodeoppdateringer skal dessuten ny utgavebetegnelse føres i <editionStmt>, en cd brennes, og dette noteres i statusrapporten.
Loggbøker kan med fordel også føres i forkortet versjon (i form av en oversikt over hvilke oppgaver som gjenstår og hvilke som er utført) som html-dokumenter, men det er veldig viktig at informasjonen om hva som er gjort med XML-filen ligger i <teiHeader> i den aktuelle XML-filen, slik at man senere kan finne ut hva som er gjort uten å måtte spore opp et annet dokument. Det som ikke er dokumentert i loggen, anses for ikke å være gjort.
NB:
Man må ikke bruke kodeklammer rundt koder man omtaler i teiHeader-loggen, siden disse forstås som faktiske koder i valideringsprosessen og dermed forårsaker feilmeldinger om manglende sluttkoder etc. Mao. skriv elementnavnene uten klammer. Man bør også unngå å bruke klammeparenteser – [...] – siden de forstyrrer syntaksmarkeringen i TextPad.
Man må ikke bruke kodeklammer rundt koder man omtaler i teiHeader-loggen, siden disse forstås som faktiske koder i valideringsprosessen og dermed forårsaker feilmeldinger om manglende sluttkoder etc. Mao. skriv elementnavnene uten klammer. Man bør også unngå å bruke klammeparenteser – [...] – siden de forstyrrer syntaksmarkeringen i TextPad.
kap-3: Strukturkoding
kap-3.1: Om strukturkoding
Vår koding går ut på å markere/avgrense og gi informasjon om strukturenheter i tekstene. Dette gjelder både generelle tekststrukturer, som overskrifter og prosaavsnitt, og mer sjangerspesifikke strukturer, som rollelister og strofer. Før vi begynner å kode de ulike teksttypene, er det nødvendig å foreta en dokumentanalyse for å finne ut hvilke strukturenheter som (vanligvis) finnes i den aktuelle teksttypen, og hvilke av disse vi er interessert i å dokumentere informasjon om.
Dette kapitlet omhandler koding av generelle strukturelementer, som kan gjenfinnes i alle teksttyper.
Koding av mer sjangerspesifikke strukturelementer beskrives i kapitlet om sjangerspesifikk koding. Foreløpig omhandler kapitlet koding av brev, dramaer og dikt. Først i sjangerkapitlene står en oversikt over hvilke elementer som er i bruk. Slike oversikter har vi kommet fram til gjennom dokumentanalyser av de aktuelle teksttypene.
kap-3.1.1: XML-struktur
XML-filene har en hierarkisk struktur, der elementer med start- og sluttagger nestes innenfor hverandre. I tillegg finnes tomme elementer (milesteinselementer), med eller uten sluttmarkør, <anchor/>. (Der de tomme elementene avløser hverandre suksessivt, er det unødvendig med sluttmarkører.) Tomme elementer benyttes for å kunne kode strukturer som krysser den hierarkiske hovedstrukturen. Slike strukturer er bl.a. side-, linje- og kolonneskift (kodes uten sluttmarkører).
De enkelte XML-filene innledes med en dokumentprolog, inneholdende bl.a. referanse til dtd-en vår. Resten av fila omsluttes av elementet <TEI.2> som inneholder en <teiHeader> med utfyllende informasjon om tekstkilden fila inneholder, og en <text> som inneholder den kodete transkripsjonen av tekstkilden. I dette kapitlet gis informasjon om den overordnete strukturen innenfor <text>.
kap-3.1.2: Tekststruktur
kap-3.1.2.1: Oversikt over generelle strukturelementer
<text> omslutter hele den transkriberte teksten i dokumentet. Følgende strukturelementer finnes i <text>:
- <group> – brukes for å gruppere tekster, f.eks. sett av rollehefter og føljetongnumre
- <text> – de enkelte tekstene, f.eks. rollehefter og føljetongnumre, innenfor en tekstgruppe
- <front> – inneholder innledende tekst før teksten i <body>, f.eks. tittelsider, forord og rollelister
- <body> – selve teksten i en tekstkilde, f.eks. aktene i et drama og diktene i en diktsamling
- <back> – inneholder avsluttende tekst etter teksten i <body>, f.eks. etterord og appendikser
Innenfor elementene <front>, <body> og <back> kan disse strukturelementene stå:
- <div> – ulike typer tekstdivisjoner, f.eks. akter i et drama
- <head> – overskrifter
- <p> – prosaavsnitt
- <list> – ulike typer lister
- <head> – til ev. overskrift
- <item> – for de enkelte innførslene
- <list> – for ev. underlister
- <div> – tekstdivisjon på lavere nivå, f.eks. scene i en akt
- <lg> – metrisk definerte grupper av vers, f.eks. strofer i et dikt
- <head> – overskrift
- <l> – verslinje
- <div> – tekstdivisjon innenfor verslinjegruppa
I tillegg til de generelle strukturelementene som er listet ovenfor kan mer sjangerspesifikke elementer være tillatt på de ulike nivåene (f.eks. er elementet <sp> (for replikk) tillatt innenfor <div>). Dette omtales i kapitlene om brev, dikt, drama og sakprosa/varia.
Fullstendig oversikt over hvilke elementer som er i bruk, og tillatt plassering av disse, finnes i prosjektets dtd.
kap-3.2: <text> og <group>
Hele tekstkilden kodes innenfor <text>. Dersom tekstkilden består av flere mindre tekster, kodes disse som separate <text> innenfor <group>. Foreløpig er slik koding brukt til doble femaktere, rollehefter, føljetonger og samlede utgaver av dikt. Her beskrives kodinga av gruppestrukturen til slike teksttyper. Mer spesifikk koding av teksttypene beskrives i kapitlene om drama-, dikt- og manuskriptkoding.
kap-3.2.1: Dobbel femakter
Kejser og Galilæer består av to femaktere («Cæsars frafald» og «Kejser Julian») med hver sin tittelside og hver sin rolleliste. Strukturen kodes slik:
<text>
<group>
<text id="KG1">…</text>
<text id="KG2">…</text>
</group>
</text>
Fellessidene (tittelsider og innholdsfortegnelse) er plassert i <front> i det ytterste <text>-elementet.
kap-3.2.2: Rollehefter
Rollehefter kodes i hver sine <text>-elementer innenfor <group>, på samme måte som doble femaktere. Rollenavnene benyttes som id-attributtverdier til de enkelte heftene. NB: Husk å bruke minuskler og majuskler (bare majuskler brukes i id-attributtverdiene til rollenavnene)!
<text> <group> <text id="Blanka">…</text> <text id="Gandalf">…</text> (osv.) </group> </text>
Detaljert informasjon om koding av rollehefter finnes i kapitlet om koding av håndskriftsmateriale.
kap-3.2.3: Føljetonger
Føljetongnumre kodes som enkeltstående <text> i <group>.
Informasjon om hvilket nummer den enkelte teksten kommer fra legges i id=""-attributtet i <text>-elementet (Attributtverdien bygges opp av verksnummer + utgivelsesår + føljetongnummer.). n=""-attributtet inneholder fortløpende nummerering av de numrene grunnteksten består av.
De enkelte føljetongnumrene lenkes sammen med <join>. Attributtet targOrder=""="" (med attributtverdien "Y" ("yes"), "N" ("no") eller "U" ("unspecified")) forteller om rekkefølgen av føljetongnumrene er den samme som den som er spesifisert i attributtet i targets="".
<text>
<group>
<join targets="No1851-9 No1851-10" targOrder="Y"/>
<text id="No1851-9" n="1">
<front>…</front>
<body>…</body>
<back>
<div type="ref">
<lb ed="No"/><p><ref target="No1851-10">(Forts.)</ref></p>
</div>
</back>
</text>
<text id="No1851-10" n="2">
<front>
…
<div type="ref">
<lb ed="No"/><p><ref target="No1851-9">(Slutning fra forrige
<sic>Numer</sic>.)</ref></p>
</div>
</front>
<body>…</body>
<back>…</back>
</text>
</group>
</text>
Kodeutdraget er hentet fra No, (Norma).
Koding av referansene (tekstelementene «Forts»/«Slutning») avhenger av hvor i strukturen disse står. Her er et eksempel med referanser i tittelstrukturen:
<front> <lb/><titlePage><docTitle><titlePart type="main">Kjæmpehøien.</titlePart> <lb/><titlePart type="Desc">Dramatisk Digtning i een Act </titlePart></docTitle><byline>af <docAuthor><hi>Henrik Ibsen</hi>.</docAuthor></byline> <lb/><docImprint><ref target="K21854-11">(Slutning fra forr. No.).</ref></docImprint> <lb/><figure type="bar"></figure> </titlePage> </front>
Kodeutdraget er hentet fra K2, (Kjæmpehøien).
For ytterligere informasjon om koding av referansene (tekstelementene «Forts»/«Slutning»), se lenkekoding.
I de verkene som er trykt første gang i føljetong, skal tittelbladene fra alle numrene med som del av teksten (manglende tekst i de elektroniske tekstene fra Bergen skal mao. transkriberes og kodes). Tittelbladet for det enkelte nummeret av føljetongen kodes som vanlig i <titlePage type="serial"> i <front>.
Når teksten i føljetongen avbrytes av tekst eller illustrasjoner som ikke skal være en del av vår tekst, markerer vi den utelatte teksten/illustrasjonen med <gap reason="irrelevant"/>, se «Utelatt tekst/illustrasjoner – <gap/>».
kap-3.3: <teiCorpus.2>
<teiCorpus.2>-elementet brukes i samlefiler for brev (og etterhvert også dikt). Hvert brev/dikt kodes (som vanlig) i et <TEI.2>-element med <teiHeader> og <text>. <TEI.2>-elementene omsluttes av et <teiCorpus.2>-element:
<teiCorpus.2> <teiHeader type="corpus" lang="nob"></teiheader> <TEI.2> <teiHeader>...</teiHeader> <text> <body>...</body> </text> </TEI.2> <TEI.2> <teiHeader>...</teiHeader> <text> <body>...</body> </text> </TEI.2> osv </teiCorpus.2>
Metadata som gjelder samlefilen plasseres i samlefilens TEI-header, <teiHeader type="corpus">, som plasseres øverst i filen før <TEI.2>-elementene.
kap-3.4: <front>
I <front> plasseres all innledende tekst før teksten i <body>. Foreløpig koder vi tittelsider, innholdsfortegnelser, forord, prologer, rollelister og situasjonsbeskrivelser (setting) her. Koding av rollelister og situasjonsbeskrivelser (setting) omtales i dramakapitlet.
kap-3.4.1: Tittelsider
Tittelblad kodes med taggen <titlePage type=""> innenfor elementet <front>. Med type=""-attributtet skiller vi mellom flere typer tittelsider; hovedtittelsider («main»), smusstittelsider («flyleaf»), kolofonsider («colophon»), mellom- og deltittelsider («part»), tittelsider i føljetonger («serial») og hovedtittelside/kolofonside («appendix-main»/«appendix-colophon») i tillegg (notebilag). type=""-attributtet skal brukes selv om tekstkilden bare inneholder ei enkelt tittelside.
Innenfor <titlepage type=""> koder vi disse tekstelementene:
- tittelen – <docTitle>
- tittelens deler – <titlePart type="">
- «byline» – <byline>
- forfatterens navn – <docAuthor>
- utgaveopplysninger – <docEdition>
- publiseringsopplysninger – <docImprint>
- publiseringssted – <pubPlace>
- utgiver/forlag – <publisher>
- til tekstelementer med ekstra utheving – <hi rend="">
- trykkeri – <printer>
- til tekstelementer med ekstra utheving – <hi rend="">
- utgivelsesår – <date>
- rettigheter – ren tekst
- tilblivelsesår for manuskripter – <docDate>. For manuskripter som inneholder både årstall og sted på tittelsiden, kodes det med <pubPlace> og <date> innenfor <docImprint>, jf. strukturen ovenfor.
Eksempel på koding av trykt tittelside:
<titlePage type="main"><docTitle> <lb/><titlePart type="main">PEER GYNT.</titlePart> <lb/><titlePart type="sub">ET DRAMATISK DIGT</titlePart></docTitle> <lb/><byline>AF <lb/><docAuthor>HENRIK IBSEN</docAuthor>.</byline> <lb/><docEdition>ANDET OPLAG.</docEdition> <lb/><figure type="logo"><figDesc>Den Gyldendalske Boghandels forlagslogo.</figDesc></figure> <lb/><docImprint><pubPlace>KJØBENHAVN.</pubPlace> <lb/><publisher>FORLAGT AF DEN GYLDENDALSKE BOGHANDEL (F. HEGEL).</publisher> <lb/><printer>TRYKT HOS <hi rend="spaced">J. H. SCHULTZ</hi>.</printer> <lb/><date>1867.</date></docImprint> </titlePage>
Eksemplet er hentet fra Peer Gynt, 2. utg. 1867.
Eksempel på koding av trykt tittelside med ekstra publiseringsopplysninger på baksiden, kodet i en egen <titlePage> med attributtverien colophon="":
<titlePage type="main"><docTitle> <lb/><titlePart type="main">FRUEN FRA HAVET.</titlePart> <lb/><titlePart type="sub">SKUESPIL I FEM AKTER.</titlePart></docTitle> <lb/><byline>AF <lb/><docAuthor>HENRIK IBSEN</docAuthor>.</byline> <lb/><figure type="logo"><figDesc>Den Gyldendalske Boghandels forlagslogo.</figDesc></figure> <lb/><docImprint><pubPlace>KØBENHAVN.</pubPlace> <lb/><publisher>GYLDENDALSKE BOGHANDELS FORLAG (F. HEGEL & SØN).</publisher> <lb/><printer>GRÆBES BOGTRYKKERI.</printer> <lb/><date>1888.</date></docImprint> </titlePage> <pb/> <titlePage type="colophon"> <lb/><docImprint>En af forfatteren autoriseret tysk oversættelse udkommer <lb/>samtidig med originalen.</docImprint> </titlePage> <pb/> <titlePage type="part"> <docTitle> <lb/><titlePart type="main">FRUEN FRA HAVET.</titlePart></docTitle> <lb/><figure type="bar"/></titlePage>
Eksemplet er hentet fra Fruen fra havet, 1. utg. 1888.
Eksempel på koding av trykt tittelside med rettighetserklæring:
titlePage type="main">
<docTitle>
<lb/><titlePart type="main">LILLE EYOLF</titlePart>
<lb/><titlePart type="sub">SKUESPIL I TRE AKTER</titlePart>
</docTitle>
<lb/><byline>AF
<lb/><docAuthor>HENRIK IBSEN</docAuthor></byline>
<lb/><figure type="logo"><figDesc>Den Gyldendalske Boghandels
forlagslogo.</figDesc></figure>
<lb/><docImprint><pubPlace>LONDON</pubPlace>
<lb/><publisher>WILLIAM HEINEMANN</publisher>
<lb/><date>1895</date>
<lb/>All rights reserved
</docImprint>
</titlePage>
Eksemplet er hentet fra London-utgaven av Lille Eyolf (1895).
Eksempel på koding av tittelside i manuskript:
<titlePage type="main"> <docTitle> <lb/><titlePart type="main">Et dukkehjem.</titlePart> <lb/><titlePart type="sub">Skuespil i tre akter</titlePart> </docTitle> <byline> <lb/>af <lb/><docAuthor>Henrik Ibsen</docAuthor>. </byline> <lb/><docDate>1879.</docDate> <lb/><figure type="bar"></figure> </titlePage>
Eksemplet er hentet fra Et Dukkehjem, ms 8° 952.
Eksempel på koding av tittelside med stedsangivelse i manuskript:
<lb/><titlePage type="main"><docTitle><titlePart type="main">Catilina.</titlePart> <lb/><titlePart type="sub">Drama i tre akter</titlePart></docTitle> <lb/><byline>af <lb/><docAuthor>Henrik Ibsen</docAuthor>.</byline> <lb/><figure type="bar"/> <lb/><docEdition>Anden og gennemarbejdet udgave.</docEdition> <lb/><docImprint><pubPlace>København.</pubPlace> <lb/><date>1875.</date></docImprint></titlePage>
Eksemplet er hentet fra Catilina (1875), ms 4° 1395.
Mellomtittelsider (tittelside etter hovedtittelside) og deltittelsider (for ulike deler av et verk, f.eks. «I. Cæsars frafald, skuespil i fem handlinger» og «II. Kejser Julian, skuespil i fem handlinger» i Kejser og Galilæer) kodes likt, i <titlePage type="part">. Tittelsidene i FU regnes som mellomtittelsider.
Tittelsider i håndskrifter som ikke inneholder opplysningene til <docEdition> og <docImprint> skal kodes uten disse elementene. Årstall for tilblivelse skal kodes som <docDate> direkte i <titlePage>.
På tittelsider i småtrykk av dikt (spesielt av sanger og leilighetsdikt) knyttes sted og dato gjerne til faktiske begivenheter snarere enn til sted og tid for trykking. Det lille heftet med følgende tekst på tittelsiden: «Sang ved Festen paa Klingenberg 17de Mai 1861», kan tjene som eksempel. Sted og dato plasseres i slike tilfeller ikke i <docImprint>, men innenfor tittelen, ev. som en undertittel kodet <titlePart type="sub">. (Datoen kodes ikke med <date> siden den oppfattes som en del av tittelen og ikke som en egentlig datering av tekstkilden).
I elementet <titlePart> skiller vi mellom hovedtittel («main») og undertittel («sub»). type=""-attributtet skal brukes selv om tittelen ikke skal deles opp i flere deler (enn en).
Hvis utgiver/forlag og trykkeri faller sammen, kodes de bare med <publisher>. Tekstdeler som er uthevet for seg innenfor <publisher> og <printer> kodes med <hi rend="">. I rend="" brukes en attributtverdi som beskriver uthevingen, f.eks. «spaced» for sperret tekst.
Logoer og skille-/pyntestreker kodes som <figure>.
kap-3.4.2: Innholdsfortegnelser
Innholdsfortegnelser kodes som tabeller eller lister (avhengig av om innholdsfortegnelsen er flerspaltet eller enspaltet) i <div type="contents"> i <front>. Fylltegn (prikker, streker etc.) i tabeller kodes med et tomt <cell role="filler">-element. (Hvilke fylltegn som er benyttet beskrives i typografibeskrivelsen.) Dersom det forekommer sideskift inne i innholdsfortegnelser kodet som tabeller, må tabellen deles i to (ellers vises ikke sideskiftet i visningstekstene). De to tabelldelene lenkes sammen med id=""-atributter.
Her er et eksempel på tabellkoding med fylltegn og sideskift:
<div type="contents"> <join targets="t1 t2" targOrder="Y"/> <table id="t1"> (…) <lb/><row><cell role="data">Folkesorg</cell><cell role="filler"></cell><cell role="data">41.</cell></row> <lb/><row><cell role="data">Til thingmændene</cell><cell role="filler"></cell><cell role="data">44.</cell></row> <lb/><row><cell role="data">Hilsen til Svenskerne</cell><cell role="filler"></cell><cell role="data">47.</cell></row> <lb/><row><cell role="data">Til de genlevende</cell><cell role="filler"></cell><cell role="data">49.</cell></row> </table> <pb/> <table id="t2"> <lb/><row><cell></cell><cell></cell><cell role="label">Side</cell></row> <lb/><row><cell role="data">Til professor Schweigård</cell><cell role="filler"></cell><cell role="data">50.</cell></row> <lb/><row><cell role="data">Vuggevise</cell><cell role="filler"></cell><cell role="data">52.</cell></row> <lb/><row><cell role="data">Borte!</cell><cell role="filler"></cell><cell role="data">53.</cell></row> (…) </table> </div>
Eksempel fra Digte.
Her er et eksempel på innholdsfortegnelse kodet som liste:
<div type="contents"> <head>INDHOLD:</head> <list> <item> <lb/>I. <lb/>CÆSARS FRAFALD, <lb/>SKUESPIL I FEM HANDLINGER. </item> <item> <lb/>II. <lb/>KEJSER JULIAN, <lb/>SKUESPIL I FEM HANDLINGER. </item> </list> </div>
Eksempel fra KGHU.
kap-3.4.3: Forord
Forord kodes som <div type="preface"> innenfor <front>. Teksten kodes som prosa med overskrifter og avsnitt (evt. delt inn i undernivåer med nye overskrifter). Evt. andre elementer, f.eks. noter og pynte-/skillestreker kodes med dertil egnede elementer.
<front> <div type="preface"> <lb/><head>FORTALE <lb/>til anden udgave.</head> <lb/><figure type="bar"></figure> <lb/><p>«<hi>G</hi>ildet på Solhaug» skrev jeg i Bergen i <lb/>sommeren 1855, altså for omtrent 28 år siden.</p> <lb/><p>Stykket opførtes samme steds for første gang <lb/>den 2. Januar 1856 som festforestilling til erindring <lb/>om den norske scenes stiftelsesdag.</p> <lb/><p>Jeg var dengang ansat som instruktør ved <lb/>det bergenske teater og ledede altså selv <sic>instu­ <lb/>deringen</sic> af mit stykke. Det fik en fortrinlig, <lb/>en sjelden stemningsfuld udførelse. Med lyst og <lb/>hengivelse blev det givet, og således blev det <lb/>også modtaget. «Den bergenske lyrik», der <lb/>efter sigende skal have afgjort de seneste politiske <lb/>valg deroppe, svulmede på hin teateraften højt i <lb/>det fuldt besatte hus. Forestillingen endte med <lb/>talrige fremkaldelser af forfatteren og af de spil­ <lb/>lende. Senere på aftenen gav orkestret, ledsaget <lb/>af en stor del af publikum, mig en serenade uden­ <lb/>for mine vinduer. Jeg tror næsten, jeg lod mig <lb/>henrive til at holde et slags tale til de forsamlede; <lb/>jeg ved i al fald, at jeg følte mig såre lykkelig.</p> <lb/><p>(…)</p> <lb/><closer><dateline><name type="place">Rom</name>, i <date>April 1883</date>.</dateline> <lb/><signed>Henrik Ibsen.</signed></closer> </div> </front>
Eksemplet er hentet fra G2 (apparater og sideskift er fjernet).
kap-3.5: <body>
Koding av strukturenheter innenfor <body> inngår i den sjangerspesifikke kodinga og beskrives i kapitlene om drama og dikt.
kap-3.6: <back>
I <back> plasseres etterord og ulike appendikser etter teksten i <body>.
kap-3.6.1: Etterord
Etterord kodes som <div type="epilogue"> innenfor <back>. Teksten kodes, på samme måte som forord, som prosa med overskrifter og avsnitt (evt. delt inn i undernivåer med nye overskrifter). Evt. andre elementer, f.eks. noter og pynte-/skillestreker kodes med dertil egnede elementer.
<back> <div n="1" type="epilogue"> <lb/><head>Anmærkninger.</head> <lb/><figure type="bar"></figure> <lb/><p><hi>H</hi>vad de Facta, der ligge til Grund for nærværende Styk­ <lb/>ke, angaae, da ere disse altfor bekjendte, til at det ikke strax <lb/>skulde sees, hvilke Afvigelser der ere gjorte fra det historisk <lb/>Sande, og at det Historiske blot deelviis er benyttet, saale­ <lb/>des at dette nærmest maa betragtes kun som en Iklædning <lb/>for den gjennem Stykket gaaende Idee.</p> <lb/><p>At Forfatteren har betjent sig af historiske Navne for <lb/>Personer, der saavel med Hensyn til Characteer, som andre <lb/>Omstændigheder optræde anderledes, end man fra Historien <lb/>lærer dem at kjende, vil forhaabentlig undskyldes, saameget <lb/>mere, da disse Navne neppe ere fremragende nok, til at for­ <lb/>styrrende Indtryk skulde fremkaldes ved deres Optræden un­ <lb/>der Forholde, hvorunder de i Historien ikke antræffes.</p> <lb/><figure type="bar"></figure> </div> </back>
Eksemplet er hentet fra C1. Sideskift og flertekstkoder (deriblant C1HUs lesemåter) er fjernet.
kap-3.6.2: Notebilag
I tekstkilden KE64 forekommer det et innskutt notebilag til slutt i trykket. Dette kodes innenfor <back>. Notebilaget er trykt for seg selv og bundet inn sammen med trykket. Det inneholder en tittelside og en kolofonside, som begge er kodet med <titlePage> (og med type-attributtverdier som innledes med "appendix-" for å skille dem fra verkets ordinære tittel- og kolofonside), i tillegg til tekst og noter til en sang. Denne er kodet som verslinjer innenfor et <div type="song">-element. Musikkopplysninger er kodet innenfor <tune>.
<back> <pb/> <titlePage type="appendix-main"> <docTitle> <lb/><titlePart type="main">Margretes Vuggesang.</titlePart> </docTitle> </titlePage> <div type="song"> <pb/> <lb/><head>Margretes Vuggesang.</head> <lb/><figure type="bar"></figure> <lb/><tune><cb/><foreign lang="Italian">Andante tranquillo.</foreign> <cb/>Comp. af <lb/><composer>Emma Dahl</composer>.</tune> <lb/><l>Nu løf - tes Laft og <lb/>Lof - - te</l><l>Til Stjer - ne - hvæl - ven blaa,</l><l>Nu <lb/>fly - ver lil - le Haa - kon</l><l>Med Drøm - me - vin - ger <lb/>paa.</l><l>Med Drøm - me - vin - ger paa . . . . <lb/>. . . . . . . . . . . . . . . . .</l> <lb/><l>Der er en Sti - ge <lb/>stil - - let</l><l>Fra Jord til Him - mel opp,</l><l>Nu <lb/>sti - ger lil - le Haa - kon</l><l>Med Eng - le - ne til <lb/>topp.</l><l>Med Eng - le - ne til topp . . . . <lb/>. . . . . . . . . . . . . . . . .</l> <lb/><l>Guds Eng - le smaa de <lb/>vaa - - ge</l><l>For Vug - ge - bar - nets Fred,</l><l>Gud <lb/>sign Dig lil - le Haa - kon</l><l>Din Mo - der vaa - ger <lb/>med.</l><l>Din Mo - der vaa - ger med . . . . <lb/>. . . . . . . . . . . . . . . . .</l> </div> <pb/> <titlePage type="appendix-colophon"> <lb/><figure type="bar"></figure> <lb/><docImprint><printer>Trykt hos Werner & Comp.</printer></docImprint> </titlePage> </back>
Kodeutdrag fra KE.
Notebilagets typografiske utforming er annerledes enn det oppsettet som er valgt her. I trykket er teksten strukturert i forhold til notene, som vi har valgt å utelate fra transkripsjonen. Vi har likeledes valgt å transkribere teksten i henhold til strofene. Et sideskift er av denne grunn utelatt siden det forekommer i alle tre strofene i trykket, og dermed her feilaktig ville forekomme tre steder istedenfor ett. Notebilagets typografi og kodingen av det er beskrevet i detalj i typografibeskrivelsen i <teiHeader>, og skal sammen med kodingen ovenfor fungere som mal for evt. flere notebilag.



kap-3.7: <div>
<div> brukes for å kode tekstdivisjoner innenfor <front>, <body> og <back>. <div>-elementene brukes unummererte, men med typeattributter. Eksempler på typeattributter som er i bruk er "act", "scene", "poem", "workingManuscript" og "preface". En fullstendig oversikt over typeattributtene finnes i attributtverdioversikten.
Ved koding av akt- og scenedivisjoner bruker vi attributtet n="" til faktisk nummerering.
Ved koding av enkeltdikt i diktsamlinger benyttes id=""-attributter (med attributtverdien 'po' (for 'poem') + løpende nummerering).
Dersom tekstdivisjoner er delt i flere biter pga. innskutt materiale (i C14936 er f.eks. akt to delt i to av innskutte utkast til scenegang), benyttes part=""-attributt med verdien "I" (initial), "M" (medial) og "F" (final).
kap-3.8: <lg>
Elementet <lg> brukes om metrisk definerte verslinjegrupper, dvs. grupper av vers som inngår i samme versemål. Elementet kan stå både i <front>, <body> og <back>. Det brukes unummerert, men med type=""-attributt. Mer informasjon om koding av verslinjegrupper finnes i kapitlet om verskoding.
kap-3.9: Overskrifter
Titler og nummeroverskrifter kodes innenfor <head>.
kap-3.9.1: <opener> og <closer>
Dateringer, stedfestinger, dedikasjoner etc. kan forekomme på linja under en overskrift eller etter teksten, som typografisk markerte enheter. Særlig ser vi slike opplysninger i for- og etterord, i brev og i dikt.
Her er en liste over elementer som kan benyttes innenfor <opener> (før teksten) og <closer> (etter teksten):
- <dateline> – steds- og tidsangivelse
- <date> – dato. Brukes ev. innenfor <dateline>
- <rs type="place"> – stedsnavn
- <rs type="person"> – personnavn (gjelder brev)
- <salute> – dedikasjon
- <signed> – forfatterens navnetrekk i <closer>
- <byline> – inneholder oftest småordet "af" samt forfatternavn i <opener>
- <docAuthor> – forfatternavn i <byline>. Ev. andre medvirkende oppgis med type=""-attributt.
- <title> – tittel
I diktene kan det være vanskelig å skille mellom <head> og <opener> (det kan f.eks. være vanskelig å avgjøre om stedsnavn og datoer er knyttet til innholdet i teksten eller til tidspunktet for nedskrivning/trykking). Vi har derfor vedtatt å unngå <opener>-koding i dikt og innlemme alle opplysningene i <head>. Innenfor <head> kodes datoer fortsatt som <date>. Stedsnavn kodes ikke. <closer>-kodinga beholdes, fordi den er tydeligere markert i forhold til den øvrige teksten.
Her er et eksempel på <opener>-koding, hentet fra forordet til KKHU. Løsningen er valgt på bakgrunn av en analyse av innhold og det typografiske oppsettet («Henrik Ibsens fortale til annen utgave.» er satt med store, fete typer midtstilt på siden. «Till anden Udgave.» er satt med samme typer som brødteksten).
<lb/><head>Henrik Ibsens fortale til annen utgave.</head> <lb/><opener><title type="main">Till anden Udgave.</title></opener>
Her er et eksempel på <closer>-koding, hentet fra forordet til C2 (apparat og linjeskift er utelatt):
<closer> <dateline><rs type="place" corresp="plDre">Dresden</rs> i <date value="1875-02-xx">Februar 1875.</date></dateline> <signed>Henrik Ibsen.</signed> </closer>
I brev skal ikke navn og dato detaljkodes i <dateline>, siden disse opplysningene allerede finnes i <letterInfo>.
kap-3.9.2: Musikkinformasjon
Ofte står det en melodiangivelse eller annen musikkinformasjon etter tittelen til en sang. Slik informasjon kodes innenfor <tune>:
<head>1. <lb/>REISEBILLEDER.</head> <lb/><tune>(Mel.: Sinclairsvisen.)</tune>
Eksempel fra DHU.
kap-3.10: Lister
Lister av ulike typer kodes med <list> inneholdende:
- <head> – til ev. overskrift
- <item> – for de enkelte innførslene
- <list> – for ev. underlister
Listekoding er foreløpig blitt benyttet til innholdsfortegnelser, trykkfeillister og «huskelister».
kap-3.10.1: Trykkfeillister
Trykkfeillisten til Fru Inger til Østråt, F281939, er kodet som en liste med overskrift, direkte i <body>.
<text type="notes" lang="Dano-Norwegian"> <body> <pb n="1r"/> <list> <lb/><head>Trykfejl <lb/>i <lb/>«Fru Inger til Østråt.»</head> <lb/><item><xptr type="synch" id="ref1" doc="F2.xml" from="refB1"/>Side 7, næstnederste linje står: <lb/><list><item>«sidset riddersmand.»</item> <lb/><item rend="deviation">rettes til</item> <lb/><item>«sidste» o.s.v</item></list></item> <lb/><item><xptr type="synch" type="synch" id="ref2" doc="F2.xml" from="refB2"/>Side 29, 11<hi rend="raised">te</hi> linje står: <lb/><list><item>«– lede og rædde de rådvil<del type="overstrike">l</del>de» –</item> <lb/><item rend="deviation">rettes til:</item> <lb/><item>«– lede og redde» o.s.v.</item></list></item> … </list> <pb n="2r"/> <pb n="2v"/> </body> </text>
Kodet eksempel fra F281939.
Det er lagt inn pekere som lenker sammen rettelsene i trykkfeillisten med trykkfeilene i førstetrykket. For koding, se lenkekoding.

kap-3.10.2: «Huskelister»
I arbeidet med NBO Ms. 4° 1111 har Ibsen skrevet en slags «huskeliste»:
Punktene som er strøket kodes med <del type="checkList" rend="overstrike">. Siden «listen» er flerspaltet brukes tabellkoding:
<table> <lb/><row><cell role="data"><del type="checkList" rend="overstrike">Længsel efter visdomsvennerne</del></cell> <cell role="filler"></cell> <cell role="data"><hi rend="underlined">Brogl</hi>:</cell> <cell role="data">699.</cell></row> <lb/><row><cell role="data"><del type="checkList" rend="overstrike">Julian hengiver sig til kynismen</del></cell> <cell role="filler"></cell> <cell role="data">"</cell> <cell role="data">704.</cell></row> <lb/><row><cell role="data">Overdrevne ofringer</cell> <cell role="filler"></cell> <cell role="data"><hi rend="underlined">Amm</hi>:</cell> <cell role="data">459.</cell></row> <lb/><row><cell role="data"><delIntended><del type="checkList" rend="overstrike">Herakleos latterliggør gudern</del>e</delIntended></cell> <cell role="filler"></cell> <cell role="data"><hi rend="underlined">Brogl:</hi></cell> <cell role="data">708.</cell></row> <lb/><row><cell role="data">Julians mythe om sig selv</cell> <cell role="filler"></cell> <cell role="data">"</cell> <cell role="data">711.</cell></row> <lb/><row><cell role="data">Den ældste dødsdømte vil dø selv først</cell> <cell role="filler"></cell> <cell role="data">"</cell> <cell role="data">717.</cell></row> <lb/><row><cell role="data">Jovian forvises</cell> <cell role="filler"></cell> <cell role="data">"</cell> <cell role="data">717.</cell></row> <lb/><row><cell role="data"><del type="checkList" rend="overstrike">Markos af Arethusa</del></cell> <cell role="filler"></cell> <cell role="data">"</cell> <cell role="data">719.</cell></row> </table>
Eksempel fra KG41111.
kap-3.11: Tabeller
Tabeller av ulike typer kodes med <table> inneholdende:
- <row> – tabellrad
- <cell role="data"> – tabellcelle
- <cell role="filler"> – tabellcelle som skal erstattes med fylltegn
- <cell role="label"> – celleoverskrift
Tabellkoding er foreløpig blitt benyttet til flerspaltede innholdsfortegnelser, lister og brev. <table> kan stå direkte i <div>.
kap-3.11.1: Tabell med fylltegn
<table> <lb/><row><cell></cell><cell></cell><cell role="label">Side</cell></row> <lb/><row><cell role="data">Spillemænd</cell><cell role="filler"></cell><cell role="data">1.</cell></row> <lb/><row><cell role="data">Kong Håkons gildehal</cell><cell role="filler"></cell><cell role="data">2.</cell></row> <lb/><row><cell role="data">Byggeplaner</cell><cell role="filler"></cell><cell role="data">4.</cell></row> <lb/><row><cell role="data">Markblomster og potteplanter</cell><cell role="filler"></cell><cell role="data">5.</cell></row> <lb/><row><cell role="data">En fuglevise</cell><cell role="filler"></cell><cell role="data">7.</cell></row> </table>
Eksempel fra Digte.
kap-3.11.2: Tabell uten fylltegn
<table> <lb/><row><cell role="data">Constantius,</cell><cell role="data">Constantin den stores søn, kejser over <lb/>det samlede romerske rige.</cell></row> <lb/><row><cell role="data" rend="braced">Gallus <lb/>Julian</cell><cell role="data">halvbrødre og Constantius's fættere.</cell></row> <lb/><row><cell role="data">Nikokles,</cell><cell role="data">nyplatoniker, Julians lærer.</cell></row> <lb/><row><cell role="data"><add place="offline">Mardonius</add></cell> <cell role="data">NB: <app><lem><add place="inline">26</add></lem><rdg><del rend="overwritten">16</del></rdg></app> år gammel kaldes Julian <app><lem>f<add place="inline">ra</add></lem><rdg>f<del rend="overwritten"><gap/></del></rdg></app> Macellum, <lb/>landgodset i Kappadokien, til Konstan­ <lb/>tinopel, for at fortsætte sine studeringer.</cell></row> <lb/><row><cell role="data">Libanius,</cell><cell role="data">hedensk filosof, turde ikke omgåes <lb/>med Julian.</cell></row> <lb/><row><cell role="data">Ekebolios,</cell><cell role="data">hykler, rettende sig efter hofluften, <lb/>blev hans lærer.</cell></row> </table>
Eksempel fra KG41111.

kap-3.11.3: Tabeller med avvikende oppsett
Tabellene er definert med et standardoppsett i stilarket. F.eks. har trespaltede tabeller standardbredden 60-20-20. Dersom visningen blir helt feil, er det mulig å endre cellebreddene i kodinga, slik: <table rend="40-20">. Bare første og siste cellebredde oppgis; den midterste gir seg da selv (her er den altså 40, siden total bredde alltid er 100). Stilarkansvarlig (Vemund) kan konsulteres for hjelp.
kap-4: Brevkoding
kap-4.1: Innledning
Brevene er samlet i større samlefiler, en fil pr. år. Se strukturkoding, <tagCorpus.2> for detaljer om strukturen i samlefilene.
kap-4.2: Tekstelementer i brev
Nedenfor er en oversikt over hvilke brevelementer vi koder. Merk at rekkefølgen på elementene kan variere, for eksempel kan dateringen stå sist i brevet (og er derfor transkribert og kodes sist i brevet).
- i <front> kodes konvolutter
- <envelope type=""> – konvolutt
- <postmark> – "franco", "betalt" osv.
- <minAddress> – mottagers navn og adresse
- <addrLine> – adresselinjer
- <hi rend="underlined"> – understreket tekst
- <envelope type=""> – konvolutt
- i <body> kodes disse tekstelementene:
- <div type=""> – brevteksten, brevtype spesifiseres i type-attributtet: type="letter"/"letter poem"/"letter telegram"/"letter visitingCard" type="postcard")
- (<opener> – samler åpningselementene, kan sløyfes hvis strukturen tilsier det)
- <dateline> – sted- og tidsangivelse
- <date> – datering
- <salute> – åpningshilsen
- <dateline> – sted- og tidsangivelse
- <head type="autograph">
- <print> – trykket signatur på visittkort
- <p> – avsnitt i brevteksten
- <print> – pretrykket tekst
- <emph> – retorisk utheving (understreket)
- <hi> – typografisk utheving (understreket eller større, fetere skrift)
- (<closer> – samler avslutningselementene, kan sløyfes hvis strukturen i brevet tilsier det)
- <salute> – avslutningshilsen
- <signed> – underskrift
- (<opener> – samler åpningselementene, kan sløyfes hvis strukturen tilsier det)
- <div type="postscript"> – etterskrift til brevet
- <div type=""> – brevteksten, brevtype spesifiseres i type-attributtet: type="letter"/"letter poem"/"letter telegram"/"letter visitingCard" type="postcard")
- i <back> kodes vedlegg
kap-4.2.1: Eksempel på kodet enkeltbrev
<TEI.2 corresp="B18651025FH"> <teiHeader lang="nob">[...]</teiHeader> <text corresp="B18651025FH" lang="Dano-Norwegian"> <body> <pb/> <div type="letter"> <lb/><dateline>Rom den <date>25<hi rend="raised">de</hi> October 1865</date>.</dateline> <lb/><salute>Hr: <sic>Cacelliraad</sic> F. Hegel. <lb/>Kjøbenhavn.</salute> <lb/><p>Idet jeg aflægger min forbindt- <lb/>ligste Takk for den gjennem B. Bjørnson mod- <lb/>tagne Vexel, har jeg herved den Fornøjelse at <lb/>fremsende Manuscriptet till de første hundrede <lb/>Sider af mit nye Arbejde. Resten skal følge <lb/>enten samlet eller i to Forsendinger i Løbet <lb/>af 14 Dage. Det hele udgjør omtrent 280 Sider. <lb/>Jeg skulde meget ønske at Bogen, hvad For- <lb/>mat, Typer o.s.v, angaar, maatte udstyres som <lb/>Bjørnsons dramatiske Arbejder. – I Afskrif- <lb/>ten findes ingen Skrivfejl af noget Slags, og <lb/>da <sic>Haanskriften</sic> formentlig er tydelig vover <lb/>jeg at haabe at ingen Trykfejl<del rend="overstrike">,</del> indløber i Bo- <lb/>gen. Postforsendelsen af Manuskriptet er kost- <lb/>bar, men jeg finder mig naturligvis i at dette <lb/>medtages i Beregningen ved det endelige Oppgjør. <lb/>Idet jeg endnu engang aflægger min Takk for den <lb/>af Hr. Cancelliraaden udviste Tillid og Vel- <lb/>vilje tegner jeg mig</p> <lb/><salute>Deres ærbødige</salute> <lb/><signed>Henr: Ibsen</signed> </div> <div type="postscript"> <lb/><p>P. S.</p> <lb/><p>Tør jeg udbede mig at indlagte Billet maa <lb/>blive nedlagt i en Postkasse, samt at jeg <lb/>med et Par Ord underrettes om Modtagelsen <lb/>af Manuscriptet; Postgangen gjennem Italien er ikke sikker.</p> </div> </body> </text> </TEI.2>
Eksempel hentet fra B18651025FH.

kap-4.3: <teiHeader>
Hver samlefil skal ha en overordnet TEI-header øverst i filen. I <sourceDesc> skal det finnes en liste over hvilke brev filen inneholder.Unike id-verdier samles <teiHeader type="corpus">. Tilsvarende opplysninger fjernes i brevenes interne <teiHeader>-elementer. I <langUsage> legges for eksempel språkattributtenes id-verdier kun i samlefilens overordnede <teiHeader>, mens et tomt <language>-element legges i brevets interne <teiHeader>.
<teiHeader type="corpus" lang="nob"> <fileDesc> <titleStmt> <title level="s" type="main">Henrik Ibsens skrifter</title> <title level="s" type="sub">Diplomatarisk tekstarkiv</title> <title level="a" type="main">Brev 1871</title> <title level="a" type="sub">Grunntekster</title> <funder>&funder;</funder> <editor>&editor;</editor> <respStmt> <resp>Oppretting av corpus-fil:</resp> <name>Ellen Nessheim Wiger</name> <name>Tone Merete Bruvik</name> </respStmt> </titleStmt> <editionStmt><edition id="B1871gt-0905"/></editionStmt> <publicationStmt> <publisher>Universitetet i Oslo ved Henrik Ibsens skrifter</publisher> <distributor id="HISb">H. Aschehoug & co</distributor> <date value="" id="HISb-date"/> <distributor id="HISe">Universitetet i Oslo</distributor> <date value="2007" id="HISe-date"/> <pubPlace>Oslo</pubPlace> </publicationStmt> <sourceDesc><p> <list> <head>Grunntekstfiler</head> <item>B18710626JHT.xml</item> <item>B18710712FH.xml</item> <item>B18710803JHT.xml</item> <item>B18710830KongK4.xml</item> <item>B18710917HJJ.xml</item> <item>B18710924GB.xml</item> <item>B18710926FH.xml</item> <item>B18710928DaBog.xml</item> <item>B18710929FH.xml</item> <item>B18711010MB.xml</item> <item>B18711015NN_Til_Oplysning.xml</item> <item>B18711028MB.xml</item> <item>Budat18711028OAB.xml</item> <item>B18711123NN_Eine_Rechtfertigung_u.xml</item> <item>B18711123NN_Eine_Rechtfertigung.xml</item> <item>B18711227FH.xml</item> <item>Budat1871NN_Om_slige.xml</item> </list></p> </sourceDesc> </fileDesc> <encodingDesc> <projectDesc><p>&projectDesc-grt-ms;</p></projectDesc> <editorialDecl> <stdVals><p>&stdVals;</p></stdVals> <p>&editorialDecl;</p> </editorialDecl> <tagsDecl> <tagUsage gi="tei.2">&tagUsage-tei2;</tagUsage> <tagUsage gi="id-base">&Ibsen-keys;</tagUsage> </tagsDecl> <variantEncoding method="parallel-segmentation" location="internal"/> </encodingDesc> <profileDesc> <langUsage> <language id="nob"/> <language id="Dano-Norwegian"/> <language id="ger"/> </langUsage> </profileDesc> <revisionDesc>...</revisionDesc> </teiHeader>
Eksempel hentet fra samlefilen B1871jun-desgt.xml.
kap-4.3.2: Enkeltbrevenes <teiHeader>
Hvert enkelt brev i samlefilen har sin egen <teiHeader>. Enkeltbrevenes <teiHeader> er noe forkortet, konsentrert om de spesifikke opplysningene om selve brevet.
<TEI.2 corresp="B18720108FH"> <teiHeader lang="nob"> <fileDesc> <titleStmt> <title level="s" type="main">Henrik Ibsens skrifter</title> <title level="s" type="sub">Diplomatarisk tekstarkiv</title> <title level="a" type="main">B18720108FH</title> <title level="a" type="sub">Grunntekst</title> <author>Henrik Ibsen</author> <funder>&funder;</funder> <editor>&editor;</editor> <respStmt> <resp>Oppretting og kollasjonering</resp> <name>Ingvald Aarstein</name> <name></name> </respStmt> </titleStmt> <editionStmt><edition id="B18720108FH-0905"/></editionStmt> <publicationStmt><p>Se samlefilens teiHeader.</p></publicationStmt> <sourceDesc> <p>Denne filen bygger på B18720108FH_HU</p> <msDescription type="letter" id="B18720108FH"> <msIdentifier> <settlement>København</settlement> <repository>Det Kongelige Bibliotek</repository> <idno>NKS 3742, 4vo, 1. rk.</idno> </msIdentifier> <letterinfo type="letter"> <sender><rs type="person" corresp="peHI">Henrik Ibsen</rs></sender> <recipient><rs type="person" corresp="peFH">Frederik Hegel</rs></recipient> <origDate value="1872-01-08">08.01.1872</origDate> <origPlace><rs type="place" corresp="plDre">Dresden</rs></origPlace> <matDesc>Løs konvolutt sammen med brevet.</matDesc> </letterinfo> </msDescription> </sourceDesc> </fileDesc> <encodingDesc> <projectDesc><p>&projectDesc-grt-ms;</p></projectDesc> <editorialDecl> <stdVals><p>&stdVals;</p></stdVals> <p>&editorialDecl;</p> </editorialDecl> <tagsDecl> <tagUsage gi="tei.2">&tagUsage-tei2;</tagUsage> </tagsDecl> </encodingDesc> <profileDesc><langUsage><language/></langUsage> <handList> <hand hand="B18720108FH-HI" id="B18720108FH-HI" ink="pen" first="yes"><p>Henrik Ibsen. Hovedhånd. Blekk.</p></hand> </handList> </profileDesc> <revisionDesc>...</revisionDesc> </teiHeader>
Eksempel hentet fra B18720108FH.
kap-4.3.3: <msDescription> og <bibl>
Alle brev som tar utgangspunkt i det originale Ibsenbrevet (også kopi/faksimile) kodes med <msDescription type="letter" id="BREVID">. Merk at alle brev typifiseres som "letter" i <msDescription>.
Hvis brevgrunnteksten bygger på en trykt tekst kodes bibliografiske opplysninger i <bibl>, og <msDescription> utgår (se kap. 3.4 under).
kap-4.3.3.1: <msDescription>
<msDescription> inneholder <msIdentifier> og <letterinfo>.
kap-4.3.3.1.1: <msIdentifier>
I <msIdentifier> legger vi inn informasjon om brevets tekstgrunnlag; i <settlement> oppgir vi hvor tekstgrunnlaget befinner seg, i <repository> noterer vi navn på eierinstitusjon, mens brevets signatur registreres i <idno>. Hvis et brev eies av en privatperson, skal det stå «PE» i <repository>. Eierens navn føres kun opp i statusrapporten.
<msIdentifier> <settlement>Oslo</settlement> <repository>NBO</repository> <idno>Brevs. 39</idno> </msIdentifier>
<msIdentifier> <settlement>Oslo</settlement> <repository>NBO</repository> <idno>Øyvind Ankers arkiv (kopi av original i privat eie)</idno> </msIdentifier>
<msIdentifier> <settlement>Oslo</settlement> <repository>HIS</repository> <idno>(digital faksimile av original i British Library)</idno> </msIdentifier>
kap-4.3.3.1.2: <letterinfo>
kap-4.3.3.1.2.1: typeattributt i <letterinfo>
Klassifikasjon av brevet legges inn i et type-attributt i <letterInfo> med attributtverdi "telegram" for telegrammer, "visitingCard" for visittkort, "poem" for dikt og "letter" for brev, "postcard" for prefrankerte postkort.
- <letterinfo type="telegram">
- <letterinfo type="visitingCard">
- <letterinfo type="poem">
- <letterinfo type="letter">
- <letterinfo type="postcard">
Siden vi redegjør for hva slags brevtype det dreier seg om her, er det ikke nødvendig å ta med slike opplysninger i <matDesc>.
kap-4.3.3.1.2.2: <sender>, <recipient>, <origDate>, <origPlace>
Standardisert informasjon om avsender, mottaker, tid og sted legges i det prosjektspesifikke elementet <letterinfo> i <msDescription>/<bibl>. <letterinfo> skal inneholde elementene <sender>, <recipient>, <origDate> og <origPlace>.
Personnavn, stedsnavn og navn på institusjoner/organisasjoner staves i henhold til standardisert skrivemåte, selv om denne kan avvike fra Ibsens egen skrivemåte. Eksempelvis skriver vi Roma for Rom, Kristiania for Christiania og Trondheim for Trondhjem.
Person-, institusjons- og stedsnavn kodes i <rs>-elementer med corresp- og type-attributt (se detaljkoding). Uidentifiserte brevmottakere og opprinnelsessteder kodes som henholdsvis «peNN» og «plNN».
Datoer kodes i <origDate> med brevets datering som attributt-verdi i value="" etter standarden yyyy-mm-dd. Eventuelle usikre elementer i dateringen fylles ut med xx. Hvis brevet er skrevet over flere dager, brukes attributtene notBefore="" og notAfter i stedet for value-attributtet). Ved usikker datering settes datering innenfor kodede klammeparenteser uten etterfølgende spørsmålstegn.
Eksempler på koding:
<lb/><origDate value="1867-10-15">15.10.1867</origDate>
<lb/><origDate value="1867-12-30">[30.12.1867]</origDate>
<lb/><origDate notBefore="1853-06-03" notAfter="1853-06-06">03.–06.06.1853</origDate>
kap-4.3.3.1.2.3: <matDesc>
<letterinfo> kan også inneholde <matDesc>. I <matDesc> legges opplysninger vi mener bør inkluderes i filen, men som faller utenfor kodingen. Det kan f. eks. være opplysninger om konvolutter, frimerker, poststempler, forseglinger, monogram, påskrifter av andre hender, vedlegg, bibliotekstempler, journalinnførsler o.l. All originaltekst som gjengis i <matDesc> settes i kodede anførselstegn.
I <matDesc> fører man også inn opplysninger om vedlegg som ikke er kodes inn i fila fordi det faller inn under dikt-, drama-, eller artikkelmaterialet (se koding av vedlegg).
kap-4.3.3.1.2.4: Eksempel på <letterinfo>
<letterinfo type="letter"> <sender><rs type="person" corresp="peHI">Henrik Ibsen</rs></sender> <recipient><rs type="person" corresp="peMB">Michael Birkeland</rs></recipient> <origDate value="1866-05-04">04.05.1866</origDate> <origPlace><rs type="place" corresp="plRom">Roma</rs></origPlace> <matDesc>Adressetekst på brevark</matDesc> </letterinfo>
Eksempel hentet fra B18660504MB.
kap-4.3.3.2: <bibl>
Hvis brevgrunnteksten bygger på en trykt tekst kodes bibliografiske opplysninger i <bibl> (og <msDescription> utgår). Dette gjelder først og fremst offentlige, åpne brev og brevgrunntekster som bygger på tidligere brevutgaver (i de fleste tilfeller HU eller Anker).
Under følger forskjellige eksempler på <bibl>. <letterinfo> kodes på samme måte som for brev som bygger på et håndskrift (se kap. 3.3.1.2 over).
ÅPENT BREV I AVIS (mal):
<bibl id="B18510928NN_Til_Abonnenterne"> <orgName type="owner">NBO</orgName> <idno>NA/A b 65/si</idno> <analytic> <author>Henrik Ibsen</author> <title>Til Abonnenterne</title> </analytic> <monogr> <title>Andhrimner</title> <imprint> <pubPlace>Kristiania</pubPlace> <publisher>Henrik Ibsen, Paul Botten-Hansen, Aasmund Olavsson Vinje</publisher> <printer>A. Th. Nissens Bogtrykkeri</printer> <date value="1851-09-28">28.09.1851</date> </imprint> </monogr> <msIdentifier> <settlement>Original trolig tapt (avistrykk er tekstgrunnlag)</settlement> <repository>Åpent brev abonnentene, trykket i Andhrimner No. 13, 3. kvartal, 28.09.1851</repository> <idno/> </msIdentifier> <letterinfo> <sender><rs type="person" corresp="peHI">Henrik Ibsen</rs></sender> <sender><rs type="person" corresp="pePBH">Paul Botten-Hansen</rs></sender> <sender><rs type="person" corresp="peAOV">Aasmund Olavsson Vinje</rs></sender> <recipient><rs type="person" corresp="peNN">abonnentene av andhrimner</rs></recipient> <origDate value="1851-09-28">28.09.1851</origDate> <origPlace><rs type="place" corresp="plKri">kristiania</rs></origPlace> </letterinfo> </bibl>
Eksempel hentet fra B18601205Aftb.
BREV BASERT PÅ HU ELLER ANKER (mal):
<bibl id="B18600418OKL"> <orgName type="owner">HIS</orgName> <idno>Ekspl. 1</idno> <author>Henrik Ibsen</author> <title>Brev 1844-1871</title> <edition>Hundreårsutgave</edition> <series> <editor>Francis Bull, Halvdan Koht og Didrik Arup Seip</editor> <title>Hundreårsutgave, Henrik Ibsens Samlede verker</title> </series> <monogr> <title>Samlede verker. Sekstende bind. Brev 1844-1871.</title> <imprint> <pubPlace>Oslo</pubPlace> <publisher>Gyldendal</publisher> <date>1940</date> <printer>Dreyer, Stavanger</printer> </imprint> </monogr> <msIdentifier> <settlement>Original trolig tapt</settlement> <repository></repository> <idno></idno> </msIdentifier> <letterinfo type="letter"> <sender><rs type="person" corresp="peHI">Henrik Ibsen</rs></sender> <recipient><rs type="person" corresp="peOKL">O. K. Lysholm</rs></recipient> <origDate value="1860-04-18">18.04.1860</origDate> <origPlace><rs type="place" corresp="plKri">Kristiania</rs></origPlace> </letterinfo> </bibl>
Eksempel hentet fra B18600418OKL.
BREV I ENKELTVERK (mal):
<bibl id="BREVID"> <orgName type="owner"></orgName> <idno></idno> <analytic> <author>Henrik Ibsen</author> <title>BREVETS FØRSTE LINJE</title> </analytic> <monogr> <author></author> <title></title> <imprint> <pubPlace></pubPlace> <publisher></publisher> <printer></printer> <date></date> </imprint> </monogr> <msIdentifier> <settlement>Original trolig tapt</settlement> <repository>Brev til XXX</repository> <idno/> </msIdentifier> <letterinfo> <sender></sender> <recipient></recipient> <origDate value="xxxx-xx-xx"></origDate> <origPlace></origPlace> </letterinfo> </bibl>
BREV I TIDSSKIFT e.l. (mal):
<bibl id="BREVID"> <orgName type="owner"></orgName> <idno></idno> <analytic> <author>Henrik Ibsen</author> <title>BREVETS FØRSTE LINJE</title> </analytic> <series> <editor></editor> <title>TIDSSKRIFTET</title> </series> <imprint> <pubPlace></pubPlace> <publisher></publisher> <printer></printer> <date></date> </imprint> <monogr> <title>TITTEL PÅ DET AKTUELLE NUMMERET/BINDET</title> <imprint> <biblScope type="volume"></biblScope> <date></date> </imprint> </monogr> <msIdentifier> <settlement>Original trolig tapt</settlement> <repository>Brev til XXX</repository> <idno/> </msIdentifier> <letterinfo> <sender></sender> <recipient></recipient> <origDate value="xxxx-xx-xx"></origDate> <origPlace></origPlace> </letterinfo> </bibl>
kap-4.3.4: <projectDesc>
Grunntekster som bygger på manuskripter skal ha entiteten projectDesc-grt-ms i <projectDesc>. Ved grunntekster som bygger på trykk skal entiteten i <projectDesc> være projectDesc-grt-trykk (dette gjelder også for telegrammer med trykt tekst).
kap-4.3.5: <handList> i brevfiler
Brevfiler som bygger på håndskrevne brev skal inneholde en liste over hvilke hender/skrivere som har hatt befatning med brevet. Dette kodes i <handList> i <teiHeader>. Både Ibsens hånd og andre, kodede hender føres opp her. Se også <teiHeader>, <handList>. Merk at id-verdien skal inneholde brevets id-verdi.
<handList> <hand hand="B18800808Dagbl-HI" id="B18800808Dagb-HI" ink="pen" first="yes"><p>Henrik Ibsen. Hovedhånd. Blekk.</p></hand> </handList>
<handList> <hand hand="B18710928DaBog-HI" id="B18710928DaBog-HI" ink="pen1" first="yes"><p>Henrik Ibsen. Hovedhånd. Blekk.</p></hand> <hand hand="B18710928DaBog-h2" id="B18710928DaBog-h2" ink="pencil"><p>Blyant.</p></hand> <hand hand="B18710928DaBog-h3" id="B18710928DaBog-h3" ink="pen2"><p>Blekk.</p></hand> </handList>
Merk at vi for brevene kun skiller mellom blekk og blyant. Fargeangivelser overlates til manuskriptansvarlig.
<handList> inkluderes også når brevet er basert på en kopi av originalbrevet, men alle opplysninger om skriveredskap fjernes:
<handList> <hand hand="B18801024FrkM-HI" id="B18801024FrkM-HI" first="yes"><p>Henrik Ibsen. Hovedhånd</p></hand> </handList>
Hver enkelt brevtekst kodes i et overordnet <text>-element med attributtene corresp="BREVID" og lang="SPRÅKVERDI". Verdien i språkattributtet angir brevets språk, dette må i tillegg ligge i <langUsage> i samlefilas overordnede <teiHeader> for at fila skal være valid. En oversikt over de ulike språkenes id-verdier finnes i attributtverdilisten.
Som hovedregel kodes brevteksten i ett <div type="letter">-element i <body>. I tillegg legger vi en tekstspesifikasjon inn i type-attributtet ved telegram (type="letter telegram"), dikt (type="letter poem"), visittkort (type="letter visitingCard"), prefrankert postkort (type="letter postcard").
<text corresp="BREVID" lang="SPRÅKID"> <body> <div type="letter"> [brevtekst] </div> </body> </text>
Hvis brevet består av flere deler (enten fordi det er skrevet i flere omganger eller fordi det avbrytes av at en annen tekst(type) er skutt inn) kodes brevet i flere <div type="letterpart" part="[I/M/F]">-elementer i et omsluttende <div type="letter">-element. Gyldige verdier i part="" er "I" (initial), "M" (medial) og "F" (final).
<div type="letter"> <div type="letterpart" part="I"> [brevtekst] </div> <div type="letterpart" part="F"> [brevtekst] </div> </div>
kap-4.4.1: Etterskrift – <div type="postscript">
Etterskrift kodes i et eget <div>-element med type="postscript".
<text> <body> <div type="letter"> [...] <lb/>Takk for den skete Henvendelse till Dem <lb/>allene og till Dem personligt.</p> <lb/><salute>Med Højagtelse <lb/>Deres ærbødige</salute> <lb/><signed>Henrik Ibsen.</signed> </div> <div type="postscript"> <lb/><p>P. S. Skulde De senerehen ønske nogle Smaating <lb/>fra <rs corresp="plIt" type="place">Italien</rs>, Karaktertræk, Rejseopplevelser – alt i Knapphed <lb/>meddelt og uden al Fordring paa Kunstværd, – saa har <lb/>jeg Stoff nok, og skulde vel ogsaa vide at finde en <lb/>Form. Men herom kan der jo først paa et senere <lb/>Tidspunkt blive Tale.</p> <lb/><signed>H. I.</signed> </div> </body> </text>
Eksempel på etterskrift hentet fra B18681031RS.

kap-4.4.1.1: Tilføyet etterskrift
Etterskrift som er tilføyet i margen kodes i <add place="margin">:
[...] <lb/><salute>Deres stedse hengivne</salute> <lb/><signed>Henrik Ibsen.</signed> </div> <add place="margin"> <div type="postscript"> <lb/><p>P. S. Tak for Götheborgs-posten og hvad jeg ellers <lb/>fra tid til anden har modtaget fra Dem!</p> <lb/><signed>H. I.</signed> </div> </add> </body> </text>
Eksempel på tilføyet etterskrift hentet fra B18710225FH.

kap-4.4.2: Vedlegg – <back>
Vedlegg til brev kodes i <back>. Det øverste <div>-elementet kodes med type="attachment". Ytterligere sjangerspesifisering av vedlegget legges i en underliggende <div>-tag med type-attributt etter samme mønster som ved telegram og visittkort. Kun vedlegg som innholdsmessig hører sammen med brevteksten kodes inn i brevfila.
<body> <div type="letter"> [brevtekst] </div> </body> <back> <div type="attachment"> [vedlegg] </div> </back>
I <dateline> koder vi stedsangivelse og datering. <dateline> plasseres direkte i <div>. Datering kodes i <date>, avsluttende tegnsetting kodes utenfor <date> men innenfor <dateline>.
<lb/><dateline>Dresden, <date>22<hi rend="raised">de</hi> Januar 1871</date>. –</dateline>
Eksempel på dateline hentet fra B18710122KB.
Merk at <dateline> i enkelte tilfeller står uten stedsangivelse og datering:
<dateline>tirsdag formiddag</dateline>
kap-4.6: Åpningshilsen – <salute>
Åpningshilsen kodes i <salute>, plassert direkte i <div>.
<lb/><salute>Kære herr Bomhoff!</salute>
<lb/><p>Efterat jeg nu i lang tid
<lb/>forgæves i «Morgenbladet» har spejdet efter
[...]
Eksempel på åpningshilsen hentet fra B18710122KB.

I enkelte brev er åpningshilsenen skrevet etter brevteksten, teksten kodes der den står.
Merk at ikke alle brev har åpningshilsen, hvis brevet istedet har overskrift, kodes denne <head>:
<head>Fuldmagt.</head> <p>Herved bemyndiges Herr kgl: Fuldmægtig Johan Herman Thoresen till paa mine Vegne at hæve og kvittere for det mig ved kgl: Resolution af 28<hi rend="raised">de</hi> Juli d. A. tillstaaede Rejsestipendium, stort 350 Sp<hi rend="raised">dlr</hi>.</p> <dateline>Frascati den <date>20<hi rend="raised">de</hi> September 1866</date>.</dateline> <signed>Henrik Ibsen.</signed>
kap-4.7: Avsnitt – <p>
Avsnitt i brevteksten kodes med <p>.
Uthevet tekst, bindestreker, tankestreker etc. kodes på vanlig måte, se detaljkoding.
Substitusjoner, strykninger, tilføyelser, uklare lesemåter etc. kodes på vanlig måte, se koding av håndskriftsmateriale.
kap-4.8: Avslutningshilsen – <salute>
Avslutningshilsner kodes i <salute>, også når hilsenen inngår i den løpende brevteksten. <salute> plasseres direkte i <div>.
<div>
...
<lb/><p>Tag nu ikke min anmodning ilde
<lb/>op; og vær fra os alle hjerteligst hilset
<lb/>gennem</p>
<lb/><salute>Deres venskabeligst forbundne</salute>
<lb/><signed>Henrik Ibsen.</signed>
</div>
Eksempel på avslutningshilsen hentet fra B18710122KB.
kap-4.9: Signatur – <signed>
Signaturer kodes i <signed> direkte i <div>. Det gjelder både for signaturer som står på egen linje og for signaturer som inngår i den løpende brevteksten. Hvis en annen en hovedhånden har undertegnet brevet legger vi inn et hand-attributt i <signed>.
<signed>Henrik Ibsen.</signed> <signed hand="B18661210SF-JCo">J. la Cour.</signed>
kap-4.9.1: Signerte fellesbrev
Dersom brevet er signert av flere personer, kodes hver enkel signatur med eget hånd-attributt som legges inn i håndlista. I tillegg føres hver signatur opp som avsender i <letterinfo> og kodes med hvert sitt <rs>-element.
kap-4.10: Konvolutter
Konvolutter kodes med elementet <envelope> i <front>. I type-attributtet i <envelope> legges informasjon om hvor adresseteksten står:
- type="envelope": adressetekst skrevet på løs konvolutt
- type="sheet": adressetekst skrevet på baksiden av brevarket
Adressatopplysninger kodes i <addrLine> i <minAddress>. Hvis Ibsen oppgir egen adresse på baksiden av konvolutten, legges det inn en <pb/> mellom adressat- og avsendertekst. Avsenderopplysninger kodes på samme måte som adressatopplysninger i <addrLine> og <minAddress>.
Dersom Ibsen har skrevet en melding til adressaten på konvolutten, kodes denne i en egen <div type="envelope_note"> innenfor <envelope>:
<envelope type="envelope"> <minAddress> <lb/><addrLine>Til</addrLine> <lb/><addrLine>Redaktionen for tidsskriftet</addrLine> <lb/><addrLine>&lquo;Det 19<hi rend="raised">de</hi> århundrede.&rquo;</addrLine> </minAddress> <pb/> <div type="envelope_note"> <lb/><salute rend="opener">Til <lb/>G: Brandes!</salute> <lb/><p>Tak for brevet og det tilsendte. <lb/>Næste bidrag snart og ialfald inden <lb/>20<hi rend="raised">de</hi> Juli.</p><salute>venskabeligst</salute><signed>H. I.</signed> </div> </envelope>
Opplysninger om eventuelle frimerker og poststempler kodes ikke i <envelope>, men beskrives i <matDesc>. Påskrevet "fr:", "franco", "Betalt" e.l. transkriberes og kodes i <postmarkDesc>.
<front>
<envelope type="envelope">
<minAddress>
<lb/><addrLine>Til</addrLine>
<lb/><addrLine>hs: højvelbårenhed</addrLine>
<lb/><addrLine>første hofmarskalken hos H. M. Kongen,</addrLine>
<lb/><addrLine>herr Erik af Edholm,</addrLine>
<lb/><addrLine>chef for de kgl: theatre.</addrLine>
<lb/><addrLine><hi rend="underlined2">Stockholm</hi>.</addrLine>
<lb/><addrLine>(<hi rend="underlined2">Schweden</hi>.)</addrLine>
</minAddress>
<postmark><postmarkDesc>f<hi rend="underlined">r</hi>:</postmarkDesc></postmark>
</envelope>
</front>
Eksempel på konvolutt hentet fra B18800103EaE.

Påskrifter som 'Rekommanderet' kodes i <note resp="author" place=""> såfremt de er Ibsens.
<front>
<envelope type="envelope">
<note resp="author" place="top-left"><hi rend="underlined">Rekommanderet</hi>.</note>
<minAddress>
<lb/><addrLine>Hr: excellence</addrLine>
<lb/><addrLine>herr statsminister Sverdrup</addrLine>
<lb/><addrLine>storkors av St: Olafs orden etc. etc.</addrLine>
<lb/><addrLine><hi rend="underlined">Kristiania</hi>.</addrLine>
</minAddress>
</envelope>
</front>
Eksempel på konvolutt hentet fra B18871003JS.

NB! I grunntekstene for første brevbind er konvoluttene kodet litt anderledes, blant annet er:
- opplysninger om frimerker og poststempler kodet i <postmarkDesc> (i <envelope>)
- påskrevet "fr:", "franco", "Betalt" e.l. ikke transkribert, men omtalt i <matDesc>
- addresattekst på konvolutter ikke kodet med <addrLine>
kap-4.11: Avskrifter/kopier
Avskrifter av Ibsens brev kodes som manuskripter med opplysninger om hånd og skriveredskap i <handList>. Avskriverens ID legges inn i håndattributtverdien, etter brevets ID. Endringer (rettelser/tilføyelser) i avskriften som skyldes slurv fra avskriverens side kodes ikke. Hvis det fremgår at rettelsene/tilføyelsene speiler originalteksten kodes disse som vanlige manuskriptendringer.
Kopier av brev kodes også som manuskript. <handList> legges inn, men uten informasjon om skriveredskap.
kap-4.12: Trykt tekst i håndskrifter
For pretrykte tekst har HIS laget et nytt element <print> som kan brukes tilsvarende <emph> og <hi>. Elementet brukes ved innslag av trykt tekst som inngår i brødteksten i håndskriftmateriale, som pretrykte kontrakter, signerte opprop ol.
Håndskrevet datering som inkluderer trykt tekst kodes slik:
<date hand="B18591027NN_Vi_tillade-h5">27 Oktober <print>18</print>59</date>
kap-4.12.1: Visittkort
Pretrykt tekst på visittkort kodes ikke med mindre Ibsen har foretatt endringer i den trykte teksten eller den trykte teksten inngår i brødteksten. Hvis den trykte teksten ikke har noen tilknytning til brevteksten, er det tilstrekkelig å opplyse om pretrykt tekst i <matDesc> i <letterinfo>.
<p><print>Dr. <hi rend="italics">Henrik Ibsen</hi>.</print> takker herr løjnant Lundh forbindtligst for den godhedsfulle tilsendelse af de to gamle breve.</p> <salute>Ærbødigst</salute> <signed>H. I.</signed>
Eksemplet er hentet fra B18990108ABL (linjeskiftkoding er fjernet)

<div type="letter visitingCard"> <dateline>den <date>16. April 1893</date>.</dateline> <p><print rend="italics"><del rend="overstrike">D</del><hi rend="raised">r:</hi> Henrik Ibsen<del rend="overwritten">.</del></print>takker venskabeligst og forbindligst for de i går modtagne 320 kroner.</p> </div>
Eksempelet er hentet fra B18930416NL (linjeskiftskoding er fjernet)

I enkelte tilfeller har Ibsen gjort rettelser i den trykte teksten for hånd. Dette kodes som en kombinasjon av tydeliggjøring og overskriving, se «Håndskriftsendring av trykt tekst»
kap-4.12.2: Prefrankerte postkort
Ved ferdig frankerte postkort skal type-attributtet ha verdien "postcard" i <letterinfo> og "letter postcard" i <div>. Adressatteksten kodes i <envelope> og opplysninger om logo o.l. legges i <matDesc>
<envelope type="sheet"> <minAddress> <addrLine>l Cavaliere Myhlenphort,</addrLine> <addrLine>Console di Danimarca, di Svezia & Norvegia.</addrLine> <addrLine>Via Sistina, 118.</addrLine> <addrLine><hi rend="underlined">Roma</hi>.</addrLine> </minAddress> </envelope>
Eksempelet er hentet fra B18810806CAM (linjeskiftskoding er fjernet)

kap-4.13: Rimbrev og dikt
Rimbrev regnes i HIS både som dikt og brev. Bare diktet skal metrikk-kodes, brevfilene skal altså ikke inneholde metrikk-koding.
I rimbrev omsluttes <dateline> og <signed> av et <closer>-element.
kap-4.14: Åpne Brev
Åpne brev som ble trykket i aviser eller tidsskrifter kodes som vanlige brev med bibliografiske opplysninger i <bibl>.
kap-4.15: Telegrammer
Ved koding av telegrammer legges telegramteksten i <text>. Mottakerens navn legges inn i <salute> – selv om dette bare står i telegramhodet. Opplysninger om sted og dato legges inn i <letterinfo>. Hvis det er andre ting i telegrammet man mener bør med, noteres dette i <matDesc>.
<msDescription type="letter" id="B18820809BB"> ... <letterinfo type="telegram"> <sender><rs type="person" corresp="peHI">Henrik Ibsen</rs></sender> <recipient><rs type="person" corresp="peBB">Bjørnstjerne Bjørnson</rs></recipient> <origDate value="1882-08-09">09.08.1882</origDate> <origPlace><rs type="place" corresp="plGoss">Gossensass</rs></origPlace> </letterinfo> </msDescription> ... <text corresp="B18820809BB" lang="ger"> <body> <pb/> <div type="letter telegram"> <lb/><salute>Herrn Bjørnson <lb/>Gausdal</salute> <lb/><p>Dank fr gemeinschaftliche arbeit <lb/>der freimachung in verflossenen 25 jahren <lb/>glck und sieg in den kommenden</p> <lb/><signed>Ibsen</signed> </div> </body> </text>
Eksemplet er hentet fra B18820809BB.

kap-4.16.1: Retningslinjer for transkripsjon av brev
- Fremmede påskrifter kodes ikke i brevteksten, men omtales i <matDesc> i <letterinfo>.
- Tødler (ö/ä/ü) transkriberes i fremmedspråklige (svenske og tyske) ord og der de hører hjemme og i egennavn. I norsk tekst normaliseres tøddelvariantene til ø og æ. Det opplyses om forekomst av tøddel-æ i <matDesc>, mens tøddel-ø normaliseres stilltiende. I trykte tekster transkriberes derimot tødlene - de regnes da som trykkfeil.
- Ordenstall ordenstallenes hevede endelser kodes i hi rend="raised". Evnt understrekinger i endelsene kodes ikke. Der Ibsen bare har skrevet en liten krusedull etter den første bokstaven i endelsen, transkriberer vi den fullstendige endelsen.
- Ulike skriftvarianter kodes ikke. Hvis det forekommer både gotisk og latinsk håndskrift i et og samme brev noterer vi dette i <matDesc>.
- Pyntesløyfen i Ibsens signatur eller på slutten av ord kodes ikke. Pyntesløyfer må ikke forveksles med komma.
- Uthevet tekst: Retorisk uthevet tekst kodes med <emph>, mens typografisk uthevet tekst kodes med <hi rend="">. Ved tekst som er typografisk uthevet via understreking markers antall streker etter underlined (<hi rend="underlined2">). Typografisk utheving gjennom større og fetere skrift kodes med <hi rend="bold">.
- verte!: Hvis Ibsen har skrevet 'verte' (snu, vend), 'vend!' e.l. på brevarkets eller visittkortets nedre hjørne, kodes dette med <note resp="author"> samt place-attributt som angir hvor på siden noten befinner seg.
- Tegnsetting i forkortelser transkriberes alltid med mellomrom etter tegnsetting, slik: H. I., o. s. v., P. S.)
- Se også detaljkoding, transkripsjonsnormalisering.
kap-4.16.2: Retningslinjer for håndskriftskoding i brev
For brev gjelder de generelle regler for koding av manuskripter, se «Retningslinjer for koding av håndskriftsmateriale». Her følger en kort oversikt over de vanligste håndskriftfenomenene i brev:
- Slurvete/utydelig skrift når slutten av et ord er skrevet slurvete, men det likevel er opplagt hva det skal stå, legger vi godviljen til og transkriberer ordet slik det skulle stått.
- Tilføyelser på linja kodes <add place="inline">, mens tilføyelser over/utenfor linja kodes <add place="offline/margin">. Se Tilføyelser
- Slettet tekst: Tekst som er overstrøket kodes <del rend="overstrike">, mens tekst som er overskrevet kodes <del rend="overwritten"> . Se Slettet tekst
- Substitusjon overstrykning med tilføyelse utenfor linja kodes i apparat på denne måten: <app type="alteration"><lem><add place="offline">TILFØYD TEKST</add></lem><rdg><del rend="overstrike">SLETTET TEKST</rdg></app>. Se Substitusjon
- Rettelser av andre hender eventuelle manuskriptrettelser i brevtekster som ikke er ført i pennen av Ibsen selv kodes ikke, men nevnes i <matDesc>. Ved avskrifter og telegrammer markeres ikke rettelser/tilføyelser i kodingen med mindre det eksplisitt fremgår at rettelsene avspeiler rettelser i originalen.
kap-4.17: Koding av brevhovedtekster
NB! Gjelder bare hovedtekster.
I brev kodes personnavn, stedsnavn, verk og enkelte institusjonsnavn, se detaljkoding. Merk at fiktive tekster som f.eks. rimbrevene ikke skal navnekodes.
kap-5: Diktkoding
kap-5.1: <teiHeader> i dikt
Det kan være nyttig med en oversikt over hvilke dikt en fil inneholder, spesielt for arbeidsmanuskripter som inneholder oppsplittede dikt. En slik liste kan legges i <msContents> i <sourceDesc>:
<msDescription type="printersCopy" id="Di42622"> <msIdentifier> <settlement>København</settlement> <repository>Det Kongelige Bibliotek</repository> <idno>KBK Collin 262, 4°, II.2</idno> </msIdentifier> <msHeading> <author>Henrik Ibsen</author> <title>Uten tittel</title> <origDate>Uten datering</origDate> <matDesc>Delvis egenhendig trykkmanuskript...</matDesc> </msHeading> <msContents> <msItem corresp="DiAbrLincMord"><title>Abraham Lincolns mord</title></msItem> <msItem corresp="DiAgnes"><title>Agnes</title></msItem> <msItem corresp="DiBergmanden"><title>Bergmanden</title></msItem> <msItem corresp="DiBorte"><title>Borte!</title></msItem> <msItem corresp="DiBraendteSkibe"><title>Brændte skibe</title></msItem> <msItem corresp="DiByggeplaner"><title>Byggeplaner</title></msItem> <msItem corresp="DiDeUsynligesKor"><title>De usynliges kor</title></msItem> <msItem corresp="DiDigterensVise"><title>Digterens vise</title></msItem> <msItem corresp="DiEderfuglen"><title>Ederfuglen</title></msItem> <msItem corresp="DiEnBroderNoed"><title>En broder i nød!</title></msItem> <msItem corresp="DiEnFuglevise"><title>En fuglevise</title></msItem> <msItem corresp="DiEnKirke"><title>En kirke</title></msItem> <msItem corresp="DiEnSvane"><title>En svane</title></msItem> <msItem corresp="DiFolkesorg"><title>Folkesorg</title></msItem> ... </msContents> </msDescription>
Corresp-verdiene valideres mot id-verdiene i <div type="poem">.
kap-5.1.2: Om verskoding og notasjonssystem – <metDecl>
Bare tekster med verskoding, dvs. bare hovedtekster, skal inneholde <metDecl>. Se mer under Hovedtekstkoding eller Verskoding.
kap-5.2: Innholdsfortegnelser
Innholdsfortegnelsen er kodet som en tabell. Lenker er kodet inn med <ptr/> der target="" korresponderer med id="" i diktet det lenkes til.
Koding av innholdsfortegnelse (eks. fra Di71.xml):
<div type="contents">
<lb/><head>INDHOLD.</head>
<lb/><figure type="bar"/>
<join targets="t1 t2" targOrder="Y"/>
<table id="t1">
<lb/><row><cell></cell><cell></cell><cell role="label">Side</cell></row>
<lb/><row><cell role="data">Spillemænd</cell><cell role="filler"></cell>
<cell role="data">1.<ptr type="contents" target="DiSpillemaend"/></cell></row>
...
Dikt det lenkes til (eks. fra Di71.xml, forenklet koding):
<div type="poem" id="DiSpillemaend">
<lb/><head type="main">Spillemænd.</head>
<lb/><figure type="bar"/>
<lb/><lg type="strofe"><l>Til hende stod mine tanker</l>
<lb/><l>hver en sommerlys nat;</l>
...
kap-5.3: Tekstelementer i dikt
Nedenfor er en oversikt over de tekstelementene vi koder i dikt.
- <text>
- <front>
- <titlePage> – tittelside, jf. Tittelsider
- <div type="contents"> – innholdsfortegnelse, jf. Innholdsfortegnelser
- <body>
- <div type="collectionPart"> – avdeling innenfor diktsamling (benyttet i Blandede Digtninger)
- <div type="poem"> – det enkelte diktet; ev. id="{diktforkortelse}" legges hit
- <div type="section"> – større ikke-metriske enheter innenfor enkeltdikt
- <head type="collectionPart|main|sub"> – overskrift til henv. avdeling innenfor diktsamling, hovedtittel til dikt og undertittel til dikt. Overskrifter til avdelinger innenfor dikt (section) kodes <head> uten type=""
- <dateline> – høyrestilt datolinje (midtstilt datering kodes heller som <head type="sub">). Det benyttes ikke <date> innenfor <dateline>
- <salute> – tilegnelser som egne typografiske elementer, eks. «Til Stella!» i «Balminder»
- <signed> – signatur
- <tune> – musikkopplysninger
- <lg type="strofe"> – verslinjegruppe med strofeoppsett
- <l> – verslinje
- i <back> kodes f.eks. kolofonside som kommer etter teksten (se DSangWergWelhBust1863).
- <front>
kap-5.4: Tekststrukturer
kap-5.4.1: Strukturen i diktsamlinger
Kodestrukturen i diktsamlinger ser slik ut, med hvert dikt kodet i <div type="poem">:
<text> <body> <div type="poem" id="tekstkildebet"></div> <div type="poem" id="tekstkildebet"></div> ... <div type="poem" id="tekstkildebet"></div> </body> </text>
kap-5.4.2: Strukturen innenfor enkeltdikt
kap-5.4.2.1: Større avdelinger – <div type="section">
Noen dikt inneholder større avdelinger som er skilt ut med egne overskrifter og/eller nummerering. Slike avdelinger kodes med <div type="section">:
<div type="poem" id="tekstkildebet"> <head type="main">HELGE HUNDINGSBANE</head> <div type="section"> <head>1. HELGES UNGDOM.</head> ... </div> <div type="section"> <head>2. HELGE OG SIGRUN.</head> ... </div> <div type="section"> <head>3. HELGES DØD.</head> ... </div> </div>
kap-5.4.2.2: Verslinjegrupper – <lg>
Elementet <lg> (line group) kodes rundt grupper av verslinjer <l>.
Strofer, dvs. gjentatte identiske metriske enheter som består av minst to verslinjer, jf Strofiske formdannelser, kodes med <lg type="strofe">:
<div type="poem" id="tekstkildebet"> <lb/><head type="main">Kong Håkons gildehal.</head> <lb/><figure type="bar"/> <lb/><lg type="strofe"><l><hi rend="initial">D</hi>u gamle hal med de mure grå,</l> <lb/><l>hvor uglen bygger sig rede, –</l> <lb/><l>så tidt jeg dig ser, må jeg tænke på</l> <lb/><l>kong Lear på den vilde hede.</l></lg> <lb/><lg type="strofe"><l>Han gav sine døtre kronens skat,</l> <lb/><l>han gav dem sit dyreste eje;</l> <lb/><l>da jog de ham ud en uvejrs-nat,</l> <lb/><l>at færdes <sic>paa</sic> vildsomme veje.</l></lg> ... </div>
Verstekster som ikke er strofiske kodes med en enkel ytre <lg>, uten attributter:
<div type="poem" id="tekstkildebet"> <lb/><head type="main">Ballonbrev <lb/>til en svensk dame.</head> <lb/><figure type="bar"/> <lb/><dateline>Dresden, i <date>December 1870</date>.</dateline> <lg> <lb/><l first="yes"><hi rend="initial">J</hi>a, jeg frister det idag,</l> <lb/><l>jeg, som ved min tausheds længde,</l> <lb/><l>tvert mod alle løfters mængde,</l> <lb/><l>frygter jeg har tabt min sag, –</l> <lb/><l>jeg, som foer fra Stockholm, bunden</l> <lb/><l>af en takskyld uden lige,</l> <lb/><l>gæsted Faraonens rige,</l> <lb/><l>løfted Isis-slørets flige, –</l> <lb/><l>og til dato kunde svige,</l> <lb/><l>hvad med hånden og med munden</l> <lb/><l>jeg på «Lyran» sidste kvelden</l><pb ed="HU"/> <lb/><l>både loved og besvor, –</l> <lb/><l>nemlig: med et skrevet ord</l> <lb/><l>at betale lidt på gælden.</l> <lb/><l rend="indent1 line">Tør jeg? Har jeg endnu ret?</l> <lb/><l>Ak, Gud-nå's, hvem spør om retten?</l> <lb/><l>Nuomstunder skilles trætten</l> <lb/><l>af et magtsprog ret og slet.</l> ... </lg> </div>
Innholdsbaserte avsnitt (f.eks. i versdramaer og rimbrev), markert med innrykk, kodes med <l rend="indent1">, jf. Typografisk markering.
kap-5.4.2.3: Verslinjer – <l>
kap-5.4.2.3.1: Metrikk vs. typografi
Verslinjer kodes med <l>. Verslinjer defineres metrisk, ikke typografisk. (Utfyllende informasjon om metrikk finnes i kapitlet om verskoding.) Linjeoppsettet faller ikke nødvendigvis sammen med versoppsettet. Her er et eksempel der linjeskift pga. plassmangel forekommer inne i verslinjene:

Slike tilfeller kodes på denne måten (for oversiktens skyld er apparat- og verskoding fjernet):
<div type="poem" id="tekstkildebet"> <lb/><head type="main">Herr Kronberg.</head> <lb/><l>Det dufter som «Frühling» når De åbner Kor­ <lb/>ken; ‐</l> <lb/><l>det stammer fra hende som svæver på stor<note type="typo">Manglende bindestrek.</note> <lb/>ken.</l> </div>
Vi ønsker å bevare informasjon om det typografiske oppsettet av verstekstene, både fordi det kan ha en semantisk funksjon (som f.eks. innholdsbasert avsnittsinndeling) og for å dokumentere ev. endringer i oppsett i vershistorien. Innrykk og blanke linjer kodes henholdsvis med <l rend="indent"> og <l rend="line"> (gjelder verslinja under den blanke linja). Førsteinnrykk/avsnittsinnrykk kodes med "indent1". Lengre innrykk (for korte verslinjer) kodes med "indent2" (og ev. med "indent3" hvis vi ønsker å dokumentere flere innrykksgrader). Det typografiske oppsettet beskrives summarisk i typografibeskrivelsen.
Her er et eksempel:
<div type="poem" id="tekstkildebet"> <lb/><head type="main">Rimbrev <lb/>til fru Heiberg.</head> <lb/><figure type="bar"/> <lb/><dateline>Dresden, i <date>påske-ugen 1871</date>.</dateline> <lb/><l><hi rend="initial">H</hi>avde jeg på engang sendt</l> <lb/><l>alle takkens små billetter,</l> <lb/><l>i de vågne vinternætter</l><pb ed="HU"/> <lb/><l rend="indent2">sammenskrevne,</l> <lb/><l rend="indent2">sønderrevne,</l> <lb/><l>skulde, lig en snesky spændt</l> <lb/><l rend="indent2">over himlen,</l> <lb/><l rend="indent2">hele vrimlen,</l> <lb/><l rend="indent2">stumpen, strimlen,</l> <lb/><l rend="indent2">hver bemalet</l> <lb/><l>med et magtløst takkens ord,</l> <lb/><l>som et prosa-snefog dalet</l> <lb/><l>over Rosenvængets flor.</l> <lb/><l rend="line">Kunde jeg på engang sendt,</l> <lb/><l>uden bur af skrift og prent,</l> <lb/><l>alle tankens løse fugle, –</l> <lb/><l rend="indent2">ind dem smugle</l> ... </div>
kap-5.4.2.3.3: Inkomplette verslinjer
Inkomplette verslinjer, f.eks. uavsluttede verslinjer i manuskripter, kodes med <l part="Y"> ('Y' står for 'yes', som et bekreftende svar på at verslinja er ufullstendig).
kap-5.4.2.3.4: Linjer med tankestreker
I noen verstekster forekommer det hele linjer med tankestreker. Slike linjer kodes med <l type="dashes">.
Her er et eksempel, et avsnitt fra «Balminder» i HU:
...
<l>Maaskee klinger det lidt sært,</l>
<l>Dertil og lidt upoetisk, –</l>
<l>For et Øre, fiint æsthetisk</l>
<l>Var det maaskee mere kjært</l>
<l>I en Balnats Sted at høre</l>
<l>Noget «Skjønnere» og «Større»,<note type="met">Urent rim.</note></l>
<l>Retsom om den lyse Sal,</l>
<l>Festligt smykket til et Bal,</l>
<l>Hvor en yndig Flok Koketter</l>
<l>Slynger Blikkets Brandraketter</l>
<l>Mens Musiken stemmer i, –</l>
<l>Var foruden Poesi! – – –</l>
<l type="dashes">– – – – – – – – – – –</l>
...
Innenfor ikke-metriske tekster kodes linjer med tankestreker med det elementet som passer, f.eks. <p type="dashes">.
kap-5.5: Oppsplittede dikt
To av manuskriptene til Digte, NBO Ms.4° 1110b og Coll.sml.262, 4°, Vol.2.2, er bundet inn feil ved bibliotekene, slik at det forekommer oppsplittede dikt. Bibliotekenes ordning er bevart i arkiv-filer. Ved de oppsplittede diktene identifiseres diktdelene med attributtverdiene id="" (første del av diktet), corresp="" og part="":
<div type="poem" corresp="DiFredSyvMinde" part="F">
<lb/><lg type="strofe"><l>Thi han lever stærk i mindet,</l>
<lb/><l>Danmarks danske drot, –</l>
<lb/><l>kongemod i folkesindet</l>
<lb/><l>vidner det så godt.</l>
<lb/><l>Derfor frem til sandheds-sejren!</l>
<lb/><l>Fredrik er i danskelejren; –</l>
<lb/><l>Slaven, Venden og Kroaten</l>
<lb/><l>slår ej landsoldaten!</l></lg>
</div>
I attributtet part="" benyttes verdiene I om første del, M om midtre del og F om siste del. Dersom det er flere midtre deler nummereres disse med attributtet n="":
<div type="poem" id="DiFredSyvMinde" part="I"> <div type="poem" corresp="DiFredSyvMinde" part="M" n="1"> <div type="poem" corresp="DiFredSyvMinde" part="M" n="2"> <div type="poem" corresp="DiFredSyvMinde" part="F">
Dersom et manuskript inneholder flere versjoner av et dikt nummereres id-verdiene:
<div type="poem" id="DiTroensGrund1" part="Y"> <div type="poem" id="DiTroensGrund2" part="I"> <div type="poem" corresp="DiTroensGrund2" part="F"> <div type="poem" id="DiTroensGrund3" part="Y">
kap-5.5.1: Lenking mellom diktdeler
For oppsplittede dikt legger vi inn lenker og forklarende utgivertekst mellom diktdelene (her fra Di41110b):
<div type="poem" corresp="DiRimbrevFruHeiberg1" part="M" n="2" hand="HI-2" id="DiRBfH1b"> <note resp="editor">Til foregående del av diktet «Rimbrev til fru Heiberg». <ptr type="part" target="DiRBfH1a"/></note> <lb/><l rend="indent2">og så friste</l> <lb/><l rend="indent2">uden spor</l> <lb/><l>hænders værkers lod på jord.</l> ... <lb/><l rend="indent2">svanehammen</l> <note resp="editor">Til fortsettelsen av diktet.<ptr type="part" target="DiRBfH1c"/></note> </div>
Alle diktdelene trenger egne id="" for å kunne lenkes sammen. Det er viktig at ikke identiske id-verdier forekommer i fila. Her er verdiene satt sammen av en forkortelse av tekstkildebetegnelsen + versjonsnummer + bokstaver for hver diktdel.
For å gjøre det enklere å orientere seg i fila (både for leserne og for de som arbeider med fila), er det lagt til forklarende utgivernoter som identifiserer diktet og viser hvor lenkene fører.
kap-5.6: Dikthenvisninger
Dikthenvisninger kodes på litt ulik vis avhengig av tekststrukturen.
kap-5.6.1: Dikthenvisninger med titler
I trykkmanuskriptet til Digte (Di42622, faksimileside 53) har Ibsen satt inn dikttitler på riktige steder og opplyst om status til tekstene. Dette er kodet slik i <div type="ref">:
<div type="ref"> <lb/><head type="main">Hilsen til Svenskerne.<ptr type="ref" target="DiHilsenTilSvenskerne"/></head> <lb/><head type="sub">(I Trondhjem ved kroningen.)</head> <lb/><p><note resp="author" place="inline">NB! skal senere blive sendt!</note></p> </div> <lb/><figure type="bar"/>
Diktet er senere lagt ved manuskriptet og lenket til med <ptr/>.
kap-5.6.2: Enklere henvisninger
I Jakob Løkkes samling av avskrifter av trykte Ibsendikt (Di41110a, faksimileside 10) har avskriveren gjort oppmerksom på at en annen versjon av diktet forekommer annetsteds i manuskriptet. Dette er gjort ved et referansetegn fra tittel til note nederst på siden som viser videre til sidetallet for den andre versjonen. Dette er kodet slik:
<div type="poem" id="DiKongHaakonsGildehal"> <lb/><head type="main">4. Kong Haakons Gildehal. <ref type="refMark" id="nb1" target="n1">&referenceMark;</ref></head> <div type="section"> <lb/><head>I.</head> <lb/><lg type="strofe"><l>Du gamle Hal med de Mure graa,</l> ... <lb/><l>Omkring din graanende Tinde.</l></lg> <lb/><figure type="num"/> <lb/><note resp="author" place="bottom-left"> <ref type="refMark" id="n1" target="nb1">&referenceMark;</ref> S. s. 14.<ptr type="ref" target="DiKongHaakonsGildehalFortDigt"/></note>
Den andre versjonen av diktet er kodet slik, med tilhørende id-verdi:
<div type="poem" id="DiKongHaakonsGildehalFortDigt">
<lb/><head type="main">8. Kong Haakons Gildehal,</head>
<lb/><head type="sub">fortællende Digt.</head>
<lb/><head>II.</head>
<lb/><lg type="strofe"><l>De holdt en Fest i Bergens By;</l>
...
kap-5.7: Ufullstendige dikt
Ufullstendige dikt (f.eks. utkast til en strofe i arbeidsmanuskript) kodes også med attributtet part="":
<div type="poem" corresp="DiFuglOgFuglefænger" part="Y">
<lb/><lg type="strofe"><l>Og når han på gab tror ane</l>
<lb/><l>vinduet som til frihed bringer,</l>
<lb/><l>dratter han med brudte vinger,</l>
<lb/><l>bums, ifra sin stængte bane.</l></lg>
</div>
Dikt skal bare kodes som ufullstendige, hvis vi vet med sikkerhet at de er det, f.eks. hvis de er bruddstykker av eksisterende dikt.
kap-5.8: Musikkinformasjon
Ofte står det en melodiangivelse eller annen musikkinformasjon etter tittelen til en sang. Slik informasjon kodes innenfor <tune>:
<head>1. <lb/>REISEBILLEDER.</head> <lb/><tune>(Mel.: Sinclairsvisen.)</tune>
Eksempel fra DHU.
kap-5.9: Bibliografiske opplysninger
I Jakob Løkkes samling av avskrifter av trykte Ibsendikt (Di41110a) er det oppgitt bibliografiske opplysninger (hvor diktene sto trykt) under hvert dikt. Disse opplysningene kodes i <div type="bibl">:
<div type="poem" id="DiEtPuds"> ... </div> <div type="bibl"> <bibl corresp="DiEtPuds"> <lb/>(Illustreret Nyhedsblad, Nr. 1–2, 25<hi rend="raised">de</hi> Oktober <lb/>1851.)</bibl> <lb/><figure type="bar"/> </div>
De korresponderende id-verdiene knytter <div type="bibl"> til riktig <div type="poem">.
kap-5.10: Verksfiler
For ikke å få for mange små diktfiler er det opprettet verksfiler for de løse dikt. Dvs. tekstkilder til samme diktverk er samlet i en fil, f.eks. DiLincMord_verksfil.xml. Verksfilene er bygget opp som årgangsfilene for brev, med et <teiCorpus.2>-element som omslutter <TEI.2>-elementene med de enkelte tekstkilder (se <teiCorpus.2>).
Eksempel på <teiHeader type="corpus">: <teiHeader type="corpus" lang="nob"> <fileDesc> <titleStmt> <title level="s" type="main">Henrik Ibsens skrifter</title> <title level="a" type="main">Lincolns Mord</title> <title level="a" type="main">Grunntekst og øvrige tekstkilder</title> <funder>&funder;</funder> <editor>&editor;</editor> <respStmt> <resp>Oppretting av corpus-fil</resp> <name>Mette Witting</name> </respStmt> </titleStmt> <editionStmt><edition id="DiLincMord-0309"/></editionStmt> <publicationStmt> <publisher>Universitetet i Oslo ved Henrik Ibsens skrifter</publisher> <distributor id="HISb">H. Aschehoug & co</distributor> <date value="" id="HISb-date"/> <distributor id="HISe">Universitetet i Oslo</distributor> <date value="2007" id="HISe-date"/> <pubPlace>Oslo</pubPlace> </publicationStmt> <notesStmt> <note type="varNumber"> <list> <headLabel>Tekstkilde</headLabel><headItem>Antall varianter i forhold til grunntekst</headItem> <label>DiLincMord_Faedrelandet_gt_tr (grunntekst)</label><item>0</item> <label>DiLincMord81591_Ms</label><item></item> <label>DiLincMord_AftenBl_tr</label><item></item> <label>DiLincMord_DagNyheder_tr</label><item></item> </list> </note> </notesStmt> <sourceDesc><p> <list> <head>Grunntekstfiler</head> <item>DiLincMord_Faedrelandet_gt_tr.xml</item> <item>DiLincMord81591_Ms.xml</item> <item>DiLincMord_AftenBl_tr.xml</item> <item>DiLincMord_DagNyheder_tr.xml</item> </list></p> </sourceDesc> </fileDesc> <encodingDesc> <projectDesc><p>&projectDesc-corpus;</p></projectDesc> <editorialDecl> <stdVals><p>&stdVals;</p></stdVals> <p>&editorialDecl;</p> </editorialDecl> <tagsDecl> <tagUsage gi="pb-ed-HU">For synkroniseringsformål er sideskiftene fra Hundreårsutgaven (bd 14) kodet med pb ed="HU". Dette tekstvitnet dekker sidene 402-404. Det første sidetallet er oppgitt i et n-attributt.</tagUsage> <tagUsage gi="tei.2">&tagUsage-tei2;</tagUsage> </tagsDecl> <metDecl> <p>&metDecl;</p> </metDecl> <variantEncoding type="external" method="parallel-segmentation" location="internal" n=""/> </encodingDesc> <profileDesc> <langUsage> <language id="nob"/> <language id="Dano-Norwegian"/> <language id="lat"/> </langUsage> </profileDesc> <revisionDesc> <respStmt><name>MW</name><resp>Oppretting av verksfil</resp></respStmt> <item>Opprettet verksfil for DiLincMord. Kopierer inn tekstkilder som allerede er kodet andre steder.</item></change> </revisionDesc> </teiHeader>
De enkelte teiHeadere for tekstkildene må på noen punkter (<publicationStmt>, <langUsage>) forkortes siden opplysningene står i den overordnede teiHeader, eks.: <TEI.2 corresp="DiLincMord_Faedrelandet_gt_tr"> <teiHeader lang="nob"> <fileDesc> <titleStmt> <title level="s" type="main">Henrik Ibsens skrifter</title> <title level="s" type="sub">Diplomatarisk tekstarkiv</title> <title level="a" type="main">Abraham Lincolns Mord</title> <title level="a" type="sub">avistrykk, Fædrelandet</title> <title level="a" type="origYear">15. mai 1865</title> <author>Henrik Ibsen</author> <funder>&funder;</funder> <editor>&editor;</editor> <respStmt> <resp>Oppretting</resp> <name>Mette Witting</name> <resp>1. kollasjon</resp> <name>Eivor Finset Spilling</name> <resp>2. kollasjon</resp> <name>Mette Witting</name> </respStmt> </titleStmt> <editionStmt> <edition id="DiLincMord_Faedrelandet_gt_tr-0808"/> </editionStmt> <publicationStmt><p>Se samlefilens teiHeader.</p></publicationStmt> <sourceDesc> <p>Denne filen bygger på DiLincMord_DagNyheder_tr.xml (0608)</p> <bibl id="DiLincMord_Faedrelandet_gt_tr"> <orgName type="owner">Nasjonalbiblioteket</orgName> <idno>Ibsen/qSmåtr. 2/si, 03ga03782</idno> <monogr> <author>Henrik Ibsen</author> <title type="main">Lincolns Mord</title> <edition>avistrykk, Fædrelandet</edition> <imprint> <pubPlace></pubPlace> <printer></printer> <date value="1865-05-15">15. mai 1865</date> </imprint> </monogr> </bibl> </sourceDesc> </fileDesc> <encodingDesc> <projectDesc> <p>&projectDesc-tekstkilde;</p> </projectDesc> <editorialDecl> <typography> <list> <item>Overskriften er satt med fete typer</item> </list> </typography> <stdVals> <p>&stdVals;</p> </stdVals> <p>&editorialDecl;</p> </editorialDecl> <tagsDecl> <tagUsage gi="pb-ed-HU">For synkroniseringsformål er sideskiftene fra Hundreårsutgaven (bd 14) kodet med pb ed="HU". Dette tekstvitnet dekker sidene 402-404. Det første sidetallet er oppgitt i et n-attributt.</tagUsage> <tagUsage gi="tei.2">&tagUsage-tei2;</tagUsage> </tagsDecl> </encodingDesc> <profileDesc> <langUsage><language/></langUsage> </profileDesc> <revisionDesc> <change><date>24.06.08</date><respStmt><name>MW</name><resp>Oppretting og 1. kollasjon</resp></respStmt> <item>Kopierte DiLincMord_DagNyheder_tr og lot Eivor ta 1. kollasjon mot denne. Førte inn kollasjonsresultatene. Klar for 2. kollasjon mot originalutklipp.</item></change> </revisionDesc> </teiHeader>
Identifiseringen av den enkelte tekstkilde gjøres vha. id i <bibl>. Andre steder brukes det corresp. Det gjelder i elementene <TEI.2> og <text>. I teiheaderen for corpus-filen listes tekstkildene opp i en <list> i <sourceDesc>.
kap-5.10.1: Oppsplittede filer for versjonsvisninger
NB: Tekstkilder i verksfiler som skal inngå i versjonsvisninger, forekommer også i separate filer. Begge filene må oppdateres ved f.eks. transkripsjonsendringer.
kap-6: Dramakoding
kap-6.1: Tekstelementer i drama
Dramatekster kodes som andre teksttyper i <front>, <body> og <back> i <text>. Overordnet strukturkoding (tittelsider, forord, etterord, notebilag) er nærmere beskrevet i «Retningslinjer for strukturkoding».
Nedenfor følger en oversikt over de dramatekstelementene vi koder. Oversikten er ment å dekke behovene i trykte dramaer og trykkmanuskripter, mens man i arbeidsmanuskriptene ofte får bruk for mer spesiell koding - se manuskriptkapitlet.
- i <front> kodes disse tekstelementene:
- <castList> – rolleliste
- <castItem> – rolleinnførsel
- <castGroup> – rollegruppe
- <role> – rolle
- <roleDesc> – rollebeskrivelse
- <actor> – faktisk eller fiktiv skuespiller
- <set> – setting; innledende tids- og stedsbeskrivelse
- i <body> kodes disse tekstelementene:
- <div type="act"> – akt
- <div type="scene"> – scene
- <head> – overskrift i akt, scene, sanger, strofer
- <stage> – sceneanvisning
- <sp> – replikk
- <spOpener> – replikkåpning
- <speaker> – replikkinnehaver
- <p> – avsnitt
- <l> – verslinje
- <stageRole> – handlende
- i <back> kodes ingen spesielle dramaelementer.
For kriterier for når elementene skal brukes, se de enkelte elementenes forklaring.
kap-6.2: Rollelister – <castList>
kap-6.2.1: Elementer og prinsipper
Rollelister kodes, som eksemplet nedenfor viser, med elementene <castList>, <castGroup>, <castItem>, <role>, <roleDesc> og <actor>, jf. retningslinjene nedenfor.
NB! I april 2007 besluttet vi å slutte å bruke koden <performance>. Den var tidligere satt rundt rollelisten, men vi kom frem til at denne koding er overflødig. I allerede opprettede filer betyr det at rollelisteoverskriften skal flyttes innenfor <castList> samtidig som <performance> fjernes. Se eksemplet på kodet rolleliste nedenfor.
- <castList> omslutter hele rollelista.
- <castGroup> brukes for en gruppe av <castItem> markert f.eks.
- med klamme: rend="braced"
- med felles beskrivelse, men uten klamme: rend="desc"
- med felles overskrift: rend="header"
- i eget avsnitt (med et sett roller som skal ha <castItem id="">): rend="paragraph"
- <castItem>: en rolleinnførsel. <castItem> kan bestå av enten en enkelt rolleinnførsel (med eller uten id="") eller flere rolleinnførsler som ikke skal ha id="". Ved sistnevnte brukes type="list". Merk at én rolleinnførsel godt kan omfatte flere rollepersoner («Gjæster» f.eks.).
- som <role> kodes typografisk markerte rollenavn uavhengig av posisjon.
- som <roleDesc> kodes rollebeskrivelser. Brukes på to måter:
- etter <role> innenfor samme <castItem> (beskriver en rolle og krever da at rollen er typografisk markert)
- i slutten av <castGroup> (beskriver mer enn en rolle, som ikke nødvendigvis er typografisk markert)
- som <actor> kodes navn og initialer på faktiske/fiktive skuespillere (f.eks. i sufflørbøker og i Norma).
- id=""-attributter skal stå i <castItem>. For veiledning i å lage attributtverdier til id="", se «Hva skal brukes som id=""?»
- Interpunksjonstegn skal plasseres der de etter sin typografiske markering hører hjemme. Jf. likevel prosjektets husregel: ved «små enheter», dvs. et eller noen få ord, plasseres interpunksjon utenfor elementet teksten kodes i, uthevede tegn i forbindelse med enkeltord oppfattes ofte som feilsetting, og det er derfor intuitivt logisk å plassere dem utenfor elementene. – Der uthevingen i rollelisten er gjort med sperret, skal man heller ikke plassere interpunksjonstegnene innenfor foregående element, siden det vanligvis er vanskelig å si hvorvidt interpunksjonstegnene faktisk er sperret eller ei.
- Typografisk markert «og» mellom roller (og andre ord som ikke er rollenavn) kodes med <hi>.
kap-6.2.2: id="" og det tilhørende who=""
I rollelisten gis hver enkelt rolle en attributtverdi i attributtet id="" (<castItem id="">). Forekomstene av de enkelte roller i dramateksten knyttes sammen med rollelisten vha. who="". Attributtverdien i who="" må være av typen IDREF. I praksis betyr det at attributtverdien må være den samme verdien som den som er brukt i id="" i <castItem> (eventuelt i <label> i <tagUsage> - se Hvor plasseres id=""?). Oversikt over hvilke rollenavn som hører til hvilke id=""/who="" fins i <tagUsage gi="id-who"> i <teiHeader>.
kap-6.2.2.1: Hvilke roller skal ha id=""?
Det er ikke alle roller i en rolleliste som trenger id-verdi. Grupper av personer (f.eks. 'Gæster', 'Unge folk', 'Deltagere i et borgermøde') er det ikke nødvendig å gi id-verdi. De viktigste rollene er de som består av en person eller en avgrenset gruppe f.eks. 'Et Par Indflytterfolk' (Sovejgs foreldre) i PG. Dessuten bør rollen ha minst en replikk/opptre som 'speaker' i løpet av dramaet før det blir nødvendig å gi rollen egen id-verdi.
kap-6.2.2.2: Hva skal brukes som id=""?
For å avgjøre hvilket ord som skal brukes som attributtverdi for id="" i hvert tilfelle, har vi bestemt at man skal ta utgangspunkt i rollenavnet i grunntekstens rolleliste framfor i dramateksten, siden rollenavnene for den enkelte rollen (noen ganger) varierer i selve dramateksten (men ikke i rollelista).
Dessuten skal attributtverdien bestå av en sammenhengende tegnstreng, og i flerordsuttrykk må man derfor velge hovedordet til attributtverdi eller slå sammen ordene ("NILSLYKKE").
Eksempler:
- For rollelistens «En Olding» i C1, som i stykket kalles både «Soldaten» og «En gammel Soldat», velger vi attributtverdien "OLDING".
- For rollelistens «Sullas Gjenferd» i C2, som har rollenavnet «Aanden», velger vi attributtverdien "GJENFERD".
Som disse eksemplene viser, kan det være forskjell mellom hva rollen heter i rollelista og i dramateksten, men rollene er (foreløpig) gjenkjennelige, slik at man enkelt kan identifisere en rolleliste-innførsel med ett eller flere rollenavn i dramateksten.
kap-6.2.2.2.1: Rollenavnvarians mellom ulike tekstkilder
Så langt som mulig skal id=""-verdiene være de samme i tekstkilder som hører til samme verk. Grunntekstens navneformer legges til grunn for id=""-attributtene. Det innebærer at ulike rollenavn som kan føres tilbake til en rollelisteoppføring i grunnteksten, f. eks. «kvinden» og «Solvejg» i Peer Gynt, får samme id. Dette gjelder også på tvers av ulike tekstkilder til samme verk, eks. «Thorgjerd» og «Thorgejr» i Olaf Liljekrans. Merk at samkjøring av id=""-attributter ikke gjelder for ulike verk (for eksempel får PASOP i Svanhild og STYVER i Kjærlighedens Komedie forskjellig id selv om de to personene trolig er identiske).
Hvis et manuskript (eller et annet ikke-førstetrykk-tekstkilde) har flere roller enn førstetrykket, kan man legge til flere id=""-attributter.
Eksempel fra Peer Gynt:
Ulike navngitte troll i manuskriptet Ms 2869, 4°.2 til Peer Gynt, eks «Professortroldet» og «Bispetroldet», får egne id=""-attributter i manuskriptet, selv om de ikke finnes som roller i førstetrykket. Vi kan gjenkjenne replikkene i førstetrykket, og kan forstå at de alle er blitt omstøpt til «Dovregubben», men ønsker å respektere at de ikke er «Dovregubben» i manuskriptet. Derimot vil «Solvejg»s foreldre fremdeles få samme felles id=""-attributt i begge tekstkilder, selv om de er mulig å dele opp id=""-attributtene i manuskriptet. De heter «Et Par Indflytterfolk» i rollelisten i førstetrykket, og i manuskriptet «Sølve og Birgit, Indflytterfolk». Så lenge de er de samme figurene i begge tekstkilder, følges førstetrykkets oppsett. Fordi foreldrene i førstetrykket står oppført som en enhet i rollelista, har de fått felles id=""-attributt, selv om de har hver sine replikker senere. Det vil si at står det «faren», «han», «Sølve» eller «moren» eller «Birgit» i stykket, vil alle disse, altså begge foreldrenes replikker, komme frem ved søk. At «faren» har en mye mer fremtredende rolle i manuskriptet, med mange flere replikker, anser vi som prinsipielt uviktig.
Ulike navngitte troll i manuskriptet Ms 2869, 4°.2 til Peer Gynt, eks «Professortroldet» og «Bispetroldet», får egne id=""-attributter i manuskriptet, selv om de ikke finnes som roller i førstetrykket. Vi kan gjenkjenne replikkene i førstetrykket, og kan forstå at de alle er blitt omstøpt til «Dovregubben», men ønsker å respektere at de ikke er «Dovregubben» i manuskriptet. Derimot vil «Solvejg»s foreldre fremdeles få samme felles id=""-attributt i begge tekstkilder, selv om de er mulig å dele opp id=""-attributtene i manuskriptet. De heter «Et Par Indflytterfolk» i rollelisten i førstetrykket, og i manuskriptet «Sølve og Birgit, Indflytterfolk». Så lenge de er de samme figurene i begge tekstkilder, følges førstetrykkets oppsett. Fordi foreldrene i førstetrykket står oppført som en enhet i rollelista, har de fått felles id=""-attributt, selv om de har hver sine replikker senere. Det vil si at står det «faren», «han», «Sølve» eller «moren» eller «Birgit» i stykket, vil alle disse, altså begge foreldrenes replikker, komme frem ved søk. At «faren» har en mye mer fremtredende rolle i manuskriptet, med mange flere replikker, anser vi som prinsipielt uviktig.
NB! Grensegangene er vanskelige, og det er uunngåelig å måtte bruke en viss porsjon skjønn.
kap-6.2.2.3: Hvor plasseres id=""?
Hovedregelen er at id-attributtet plasseres i <castItem>.
<lb/><castItem id="BRAND"><role>Brand</role>.</castItem>
Eksempel fra Br.
I tekstkilder som ikke har rolleliste (rollehefter og fragmentariske tekstkilder), legges id-attributtet i oversikten over id og who-attributter i <tagsDecl> i TEI-headeren.
<tagsDecl> <tagUsage gi="id-who"> <list> <headLabel>castItem id=""</headLabel><headItem>speaker</headItem> <label id="FRUHALM">FRUHALM</label><item>Fru Halm, Fruen</item> <label id="SVANHILD">SVANHILD</label><item>Svanhild</item> <label id="ANNA">ANNA</label><item>Anna</item> <label id="FALK">FALK</label><item>Falk</item> <label id="LIND">LIND</label><item>Lind</item> <label id="GULDSTAD">GULDSTAD</label><item>Guldstad</item> <label id="STYVER">STYVER</label><item>Pasop, Styver</item> <label id="FRKSKJÆRE">FRKSKJÆRE</label><item>Frøken Skjære, Frøken S., Frøken</item> <label id="STRAAMAND">STRAAMAND</label><item>Straamand, Præsten</item> <label id="FRUSTRAA">FRUSTRAA</label><item>Fru Straamand</item> <label id="OPPASSER">OPPASSER</label><item>Oppasseren, Opp:</item> </list> </tagUsage> </tagsDecl>
Eksempel fra KK8375.
I tekstkilder der ikke alle rollene som skal ha id er ført i rollelisten, legges id=""-attributtene for disse rollene i <tagsDecl> i TEI-headeren. For roller som er oppført i rollelisten legges id=""-attributtet som vanlig i <castItem>.
I tekstkilder med mer enn n rolleliste (f.eks. arbeidsmanuskriptet FH41116 som har rollelister på faksimilesidene, 11, 32 og 36) legges id=""-attributtene i den mest endelige rollelisten. Rollenavnene i de øvrige rollelistene skal ha et corresp=""-attributt med tilsvarende attributtverdi som i id=""-attributtene i hovedrollelisten, for å lenke rollenavnene sammen. Eksempel på koding av rollenavn i en av de øvrige rollelistene:
<castItem corresp="ELLIDA">Fru Wangel, hans anden hustru.</castItem>
Variansen i rollenavn i rollelistene dokumenteres i <teiHeader> i <tagUsage gi="id-who">.
kap-6.2.2.4: who="" i <sp> og <stageRole>
Det er replikkene (<sp>) og de typografisk uthevede roller i sceneanvisninger (<stageRole>) som knyttes til rollelistens id-verdier med tilhørende who-verdier. Kodingen ser slik ut: <sp who="CATILINA">/<stageRole who="FURIA">.
Et who=""-attributt kan og skal inneholde flere attributtverdier når flere roller er sammen om en replikk eller er typografisk uthevede i en sceneanvisning. Attributtverdiene skal ha ett mellomrom/en blank mellom seg, og de skal sorteres alfabetisk. Flere attributtverdier skal imidlertid bare brukes der man med sikkerhet kan identifisere alle roller som er sammen om en replikk. Det fins f.eks. et tilfelle i C1 hvor rollenavnet «Begge» benyttes i stedet for Catilina og Furia. Dette tekststedet er kodet <sp who="CATILINA FURIA">.
Identifiserte rolleinnehavere skal ikke ha who=""-attributt når de opptrer sammen med uidentifiserte rolleinnehavere (f.eks. «Catilina og hans mænd»). For hvis man ikke er sikker på hvilke roller en samlebetegnelse dekker, skal man ikke sette inn who=""-attributt. Det er viktig å unngå den ekstra tolkningen som tvilsomme attributtverdier i <sp> og <stageRole> medfører.
kap-6.2.3: Eksempel på kodet rolleliste
Her er et eksempel på koding av en rolleliste, samt faksimile av rollelisten.
<lb/><castList><head>PERSONERNE.</head>
<lb/><castItem id="FRUHALM"><role>Fru Halm</role>,
<roleDesc>en Embedsmands Enke</roleDesc>.</castItem>
<lb/><castGroup rend="braced"><castItem id="SVANHILD">
<role>Svanhild</role></castItem>,
<lb/><castItem id="ANNA"><role>Anna</role></castItem>,
<roleDesc>hendes Døttre</roleDesc>.</castGroup>
<lb/><castGroup rend="braced"><castItem id="FALK"><role>Falk</role>,
<roleDesc>en ung Forfatter</roleDesc></castItem>,
<lb/><castItem id="LIND"><role>Lind</role>,
<roleDesc>theologisk Student</roleDesc></castItem>,
<roleDesc>hendes Logerende</roleDesc>.</castGroup>
<lb/><castItem id="GULDSTAD"><role>Guldstad</role>,
<roleDesc>Grosserer</roleDesc>.</castItem>
<lb/><castItem id="STYVER"><role>Styver</role>,
<roleDesc>Kopist</roleDesc>.</castItem>
<lb/><castItem id="FRKSKJAERE"><role>Frøken Skjære</role>,
<roleDesc>hans Forlovede</roleDesc>.</castItem>
<lb/><castItem id="STRAAMAND"><role>Straamand</role>,
<roleDesc>Præst fra Landet</roleDesc>.</castItem>
<lb/><castItem id="FRUSTRAA"><role>Fru Straamand</role>,
<roleDesc>hans Kone</roleDesc>.</castItem>
<lb/><castItem type="list"><role>Studenter</role>,
<role>gæster</role>, <role>familjer</role> <hi>og</hi>
<role>forlovede par</role>.</castItem>
<lb/><castItem><role>Præstefolkenes otte Pigebørn</role>.</castItem>
<lb/><castGroup rend="paragraph"><castItem><role>Fire
Tanter</role></castItem>, <castItem id="HUSJOMFRU">
<role>En Husjomfru</role></castItem>, <castItem id="OPPASSER">
<role>En Oppasser</role></castItem>, <castItem>
<role>Tjenestepiger</role></castItem>.</castGroup>
</castList>
<lb/><figure type="bar"/>
...
</front>
Eksempel fra KKHU.

kap-6.2.4: Setting – <set>
Sidene med rollelister inneholder vanligvis også en beskrivelse av tid og sted for dramaets handling; setting. Dette avsnittet kodes i elementet <set>. Teksten i <set> skal alltid kodes med et (evt. flere) <p>-elementer.
<front> <castList> ... </castList> <lb/><set><p>(Handlingen foregår ved sommertid i en liden fjordby i det nordlige <lb/>Norge.)</p></set> </front>
Eksempel fra FHFU.
kap-6.3: Akt- og sceneinndeling
kap-6.3.1: Akter
Vi koder akter etter aktinndelingen i tekstkildene. Den er markert typografisk med overskrifter. Til aktkodingen bruker vi elementet <div n="[fortløpende nummerering]" type="act">.
Vanligvis nummereres aktene fortløpende slik de forekommer i teksten. Bemerk imidlertid følgende:
- Hvis en akt er delt i flere biter pga. f.eks. innskutt materiale (i f.eks. NBO Ms 4° 936 er akt to delt i to av innskutte utkast til scenegang), brukes part=""-attributtet i <div type="act" n="" part=""> med attributtverdi "I" («initial»), "M" («medial») eller "F" («final»).
- Hvis tekstkilder er fragmentariske nummereres aktene (eller scenene) i forhold til den nummereringen de skal ha (mao. dramatekstens 2. akt nummereres som 2. akt også i fragmentet selv om den der forekommer som eneste akt). Her må man bruke skjønn, og det gjelder særlig når teksten i fragmentet avviker fra grunntekstens. Denne nummereringen gjøres av hensyn til den planlagte synkroniseringen av tekstkildene.
- Hvis en akt er ufullstendig, kodes den med part-attributtverdien "Y" («yes»).
kap-6.3.2: Scener
Til scenekodingen bruker vi elementet <div n="[fortløpende nummerering]" type="scene">. Vi koder scener bare når det fins sceneoverskrifter eller scenenummerering.
Når tekstkilden ikke har konsekvent sceneinndeling; f.eks. hvis det ikke fins sceneoverskrift ved starten av akten, men det fins noen sceneoverskrifter lenger inn i akten, må det første sceneelementet, <div type="scene">, omfatte all tekst fram til første sceneoverskrift. Man kan anta at aktstart i slike tilfeller også impliserer scenestart. Dersom en akt mangler sceneoverskrifter, mens andre akter har det, skal det også kodes en scene for den førstnevnte. Dette sceneelementet vil da omfatte all tekst i akten minus aktoverskrift. Dersom akten innledes med to sceneanvisninger, kan det vurderes om den første sceneanvisningen hører til aktnivået, mens den andre hører til scenenivået. I slike tilfeller starter første scene mellom de to sceneanvisningene.
Vanligvis nummeres scenene fortløpende slik de forekommer i teksten, det vil si at man ved første scene i ny akt begynner på 1 og teller scenene i akten fortløpende. Unntak fra denne regelen er hvis tekstkilden er fragmentarisk eller scenene er feilnummerert av skriveren, i slike tilfeller nummereres scenene utifra den nummereringen de skal ha og man legger inn en note om feilaktig nummerering. Dette gjøres av hensyn til den planlagte synkronisering av tekstkildene.
Merk at når tekstkilden ikke har sceneinndeling i form av sceneoverskrifter eller scenenummerering i det hele tatt, koder vi ikke scener.
kap-6.3.3: Akt- og sceneoverskrifter
Akt- og sceneelementer kodes med elementet <head>. Typografien (understreking etc.) beskrives i typografibeskrivelsen i <teiHeader>.
Hevet tekst i overskrifter, vanligvis «ste», «den» etc. i forbindelse med ordenstall, kodes med <hi rend="raised">.
kap-6.4: Replikk – <sp>
Replikkelementet <sp> skal forstås slik i kodearbeidet:
<sp>-elementene utgjør en sammenhengende struktur, som ikke kan avbrytes av andre elementer enn strukturelementer på samme eller høyere nivå.
Det vil si at <sp>-elementene kan avbrytes av <div>-elementer (høyere nivå) og av frittstående sceneanvisninger (samme nivå).
En vanlig replikk (<sp>) består av replikkåpner (<spOpener>), replikkinnehaver (<speaker>), sceneanvisning (<stage>) og replikktekst (på prosa (<p>) eller vers (<l>)).
<sp who="[ID-VERDI FRA <castList>]"> <spOpener> <speaker>ROLLEINNEHAVER</speaker> <stage>SCENEANVISNING</stage> </spOpener> <p>REPLIKKTEKST</p> </sp>
For beskrivelse av bruken av who="", se who="" i <sp> og <stageRole> ovenfor.
kap-6.4.1: «Avvikende» replikker
kap-6.4.1.1: Replikker uten replikkåpner
Replikker uten replikkåpner er replikker som mangler innledende rollenavn, sceneanvisning eller begge deler.
I slike tilfeller tillater vi at replikken kodes som replikk på grunnlag av en fortolkning av replikkens kontekst.

<sp> <spOpener><speaker>En af Gjæsterne</speaker>.</spOpener> <p>Og nu en Stevkamp!</p> </sp> <sp> <p>Ja, ja!</p> </sp>
Eksempel fra G1.
kap-6.4.1.2: Replikker med doble rollenavn
Et annet avvikende fenomen er replikker med dobbelte rollenavn i håndskriftsmateriale. De kodes slik:
<sp who="HEMMING">
<spOpener>
<speaker>
<lb/>Hemming<pb/>
<lb/>Hemming
</speaker>
</spOpener>
REPLIKKTEKST
</sp>
Eksempel fra K1 (apparatkoding er fjernet).
kap-6.4.1.3: Replikker med forkortede rollenavn
Forkortede rollenavn transkriberes i forkortet form. Avsluttende punktum plasseres i <speaker> siden det anses å høre til rollenavnet og ikke avslutte replikkåpner (som er den normale tolkningen av punktum etter rollenavn).
<lb/><sp who="AGNES">
<spOpener><speaker>Ag.</speaker></spOpener>
<lb/><l>Her er Lærer, Ven og Broder!</l></sp>
Eksempel fra Br42621.
kap-6.4.1.4: Replikker med feil rollenavn
I replikker som opplagt har feil rollenavn, oppgis det riktige navnet som who-attributt, mens rollenavnet i <speaker> transkriberes diplomatarisk. Feilen kommenteres i en editor-note. Her er et eksempel fra SSFU:
<lb/><sp who="FRURUMMEL"><spOpener><speaker>Fru Rummel</speaker>.</spOpener>
<lb/><p>Nej, nu må jeg sige –! Var ikke <emph>det</emph> bekendt
<lb/>over hele byen? Var ikke gamle fru Bernick nær
<lb/>ved at gå fallit for den sags skyld? Det har jeg
<lb/>da fra Rummel selv. Men Gud bevare <emph>min</emph> mund.</p></sp>
<lb/><sp who="FRUHOLT"><spOpener><speaker>Fru Rummel<note resp="editor">Feil for Fru Holt.</note></speaker>.</spOpener>
<lb/><p>Nå, til madam Dorf gik ialfald pengene ikke,
<lb/>for hun –</p></sp>
kap-6.4.1.5: Tomme replikker
Med tomme replikker mener vi replikker som består av bare rollenavn og sceneanvisning. Innholdet i disse er i praksis ikke annet enn en sceneanvisning, men siden det er satt opp typografisk som en replikk, koder vi det slik.
<sp who="FINN"> <spOpener><speaker>Finn</speaker> <stage>(nynner en stund for sig selv)</stage>. </spOpener> </sp>
Eksempel fra F2 (linjeskiftkoder og apparater er fjernet).
Oppsummerende kan man si at hvis noe skal kodes som replikk må én eller flere deler ha typografisk replikk-oppsett, jf. eksemplene ovenfor. Står all tekst i den antatte replikken inne i et enkelt element, f.eks. en sceneanvisning, koder vi det ikke som replikk, men som det det er typografisk markert som.
kap-6.4.1.6: Avvikende oppsett
I OL344 fins det en replikk som er satt opp på avvikende måte, jfr. faksimilen nedenfor. Vi oppfatter strukturen som én replikk med to replikkinnehavere og felles replikktekst.
Vi koder dette med rend="braced"="" i <spOpener> for å dokumentere klammen etter replikkinnehaverne samt en <note> som beskriver strukturen. Selv om replikkteksten ikke står på samme linje som siste replikkinnehaver markerer vi ikke linjeskift mellom denne og replikkteksten. Vi markerer likevel linjeskiftet mellom replikkinnehaverne.
<lb/><sp><spOpener rend="braced">
<speaker>Arne</speaker>
<lb/><speaker>Gjæsterne</speaker></spOpener>
<p>Olaf!</p></sp>
Eksempel fra OL344.
Vi har definert et eget element, <spOpener>, som replikkåpner. Dette elementet inneholder vanligvis elementene <speaker> og <stage> samt interpunksjon og småord (f.eks. «og» mellom to <speaker>), jf. eksemplet nedenfor.
<sp who="NILSLYKKE SKAKTAVL"> <spOpener><speaker>Nils Lykke</speaker> og <speaker>Olaf Skaktavl</speaker>.</spOpener> <p>Ingen.</p></sp>
Eksempel fra F2. Apparatkoder og linjeskift er utelatt for oversiktens skyld.
Dersom to rolleinnehavere deler en replikk, kodes disse i hvert sitt <speaker>-element og «og» mellom de to rolleinnehavere plasseres direkte i <spOpener>. Typografisk markering av «og» noteres i <typography> og evt. avvikende typografisk markerte «og» kodes med <hi>, se «Retningslinjer for detaljkoding», kap. 5.2 «Tilfeldige utheving - <hi>».
<spOpener> kan også inneholde bare <speaker> eller bare <stage>. En replikk skal ikke inneholde <spOpener> hvis det hverken fins et rollenavn eller en sceneanvisning som innleder replikken, jf. eksemplet til avsnittet «Replikker uten replikkåpner».
kap-6.6: Avsnitt i prosa – <p>
Vi koder alle typografisk markerte (markert f.eks. med luft før og etter, innrykk, adskilt med sceneanvisninger) avsnittsenheter som individuelle <p> i prosadrama.
kap-6.7: Verslinjer – <l>
Verslinjer kodes med <l>. Verslinjer defineres metrisk, ikke typografisk. Linjeskift innenfor verslinjer markeres på vanlig måte med <lb/>. Åpenbare feil i det typografiske oppsettet (f.eks. feilplasserte rimord) bemerkes i <note>.
<lb/><sp><spOpener><speaker>Gudmund</speaker>.</spOpener>
<lb/><l>Hvorlunde lever eders søster kære?</l></sp>
<lb/><sp><spOpener><speaker>Margit</speaker>.</spOpener>
<lb/><l part="I">Jeg takker; hel vel.</l></sp>
<lb/><sp><spOpener><speaker>Gudmund</speaker>.</spOpener>
<lb/><l part="F">Det blev sagt, hun skulde
<lb/>være<note resp="editor">feil linjeskift: rimordet 'være' tilhører linja over.</note></l> <l part="I">hos eder.</l></sp>
Eksempel fra G2.
kap-6.7.1: Oppdelte verslinjer
Verslinjer som går over flere replikker, markeres med part=""-attributt som kan inneholde attributtverdiene "I" (initial), "M" (middle) og "F" (final):
<lb/><sp><spOpener><speaker>Peer Gynt</speaker>.</spOpener> <lb/><l part="I">Fy da, Moer!</l></sp> <lb/><sp><spOpener><speaker>Aase</speaker>.</spOpener> <lb/><l part="M">Tvi!</l></sp> <lb/><sp><spOpener><speaker>Peer Gynt</speaker>.</spOpener> <lb/><l part="F">Giv mig heller</l> <lb/><l>din Velsignelse till Færden.</l> ... </sp>
Eksempel fra PG.
Dersom en verslinje er oppdelt i flere enn tre deler brukes verdien "M" for alle de midterste delene og det legges til nummerering av disse i et n-attributt:
<lb/><sp><spOpener><speaker>Margit</speaker> <lb/><stage>(i heftig Bevægelse)</stage>.</spOpener> <lb/><l part="I">Om jeg vil?</l></sp> <lb/><sp><spOpener><speaker>Gudmund</speaker>.</spOpener> <lb/><l n="1" part="M">Ja, jeg mener ‐</l></sp> <lb/><sp><spOpener><speaker>Margit</speaker>.</spOpener> <lb/><l n="2" part="M">Sig frem.</l></sp> <lb/><sp><spOpener><speaker>Gudmund</speaker>.</spOpener> <lb/><l part="F">Nu vel.</l> <lb/><l>Du kunde gjøre mig saa rig og saa fro ‐</l></sp>
Eksempel fra G1.
kap-6.7.2: Inkomplette verslinjer
Inkomplette (f.eks. avbrutte) verslinjer i versdramaer markeres med <l part="Y"> (y-en står for "yes" som er et bekreftende svar på at verslinja er inkomplett):
<lb/><sp><spOpener><speaker>Severus</speaker>
<stage>(omfavner Adalgisa.)</stage></spOpener>
<lb/><l>Elskede! du paa disse Steder!</l></sp>
<lb/><sp><spOpener><speaker>Norma</speaker>.</spOpener>
<lb/><l>Forræder! Forræder!</l></sp>
<lb/><sp><spOpener><speaker>Severus</speaker>
<stage>(forbløffet.)</stage></spOpener>
<lb/><l>Ih, Gud bevare's, Madam! er de her!</l></sp>
<lb/><sp><spOpener><speaker>Norma</speaker>.</spOpener>
<lb/><l>Forræder! Forræder!</l></sp>
<lb/><sp><spOpener><speaker>Severus</speaker>.</spOpener>
<lb/><l>Tys, vær dog stille, jeg beder, jeg beder!</l></sp>
<lb/><sp><spOpener><speaker>Norma</speaker>.</spOpener>
<lb/><l part="Y">For ‐ ‐</l></sp>
<lb/><sp><spOpener><speaker>Severus</speaker>
<stage>(hidsig.)</stage></spOpener>
<lb/><p>Nei, vil du nu bare holde Mund, (...)</p></sp>
Eksempel fra No.
Vi ønsker å bevare informasjon om det typografiske oppsettet av verstekstene, både fordi det kan ha en semantisk funksjon (som f.eks. innholdsbasert avsnittsinndeling) og for å dokumentere ev. endringer i oppsett i vershistorien. Innrykk, blanke linjer og midtstilling kodes henholdsvis med <l rend="indent">, <l rend="line"> (gjelder verslinja under den blanke linja) og <l rend="centre">. Dersom det finnes flere grader av innrykk, kodes disse med "indent1", "indent2", "indent3" osv. Det typografiske oppsettet beskrives i tillegg i typografibeskrivelsen.
kap-6.7.4: Grupper av verslinjer
Kodingen av verslinjegrupper utføres i sammenheng med den metriske kodinga, og beskrives utfyllende i «Retningslinjer for diktkoding».
kap-6.7.5: Metrikk vs. typografi
Dersom metrikken og typografien gir motstridende signaler, følger vi metrikken. F.eks. markeres oppdelte verslinjer i replikker med gradvis større venstreinnrykk. I andreutgaven til Peer Gynt (PG67 s. 50) er det gjort en feil, slik at siste del av verslinja står helt ut i venstre marg (og dermed ser ut som første del av ei verslinje). I slike tilfeller følger vi altså metrikken og koder verslinjeparten med <l part="F">. I en supplerende editor-note opplyser vi om feilen i det typografiske oppsettet.
kap-6.8: Sceneanvisninger – <stage>
Disse retningslinjene gjelder både versdrama og prosadrama.
- Sceneanvisninger som kommer først i akt eller scene plasseres i det aktuelle <div>-elementet.
- Sceneanvisninger som kommer etter rollenavn regnes som en del av replikkåpner og plasseres i <spOpener>, jf. «Replikkåpning – <spOpener> med <speaker> og <stage>».
- Sceneanvisninger som er en del av den løpende teksten i et replikkavsnitt, inngår i den strukturelle enheten de er plassert i, <p> eller <l>. (Dette innbærer at sceneanvisninger som starter på siste linje av replikkteksten, plasseres innenfor <p> selv om de overskrider linjenivået.)
- Sceneanvisninger som står i starten eller på slutten av verslinjer, plasseres utenfor <l>.
Eksempler:
<lb/><l>bla bla <stage>tekst</stage> bla bla</l>
<lb/><p>bla bla <stage>tekst</stage> bla bla <lb/>bla bla bla bla bla <lb/>bla bla <stage>tekst</stage></p>
<lb/><l>bla bla bla</l><stage>tekst <lb/>tekst tekst tekst tekst <lb/>tekst tekst</stage>
<lb/><stage>tekst</stage><l>bla bla bla</l> <lb/><l>bla bla bla</l><stage>tekst</stage>
Sceneanvisninger som står som egne, typografisk markerte avsnitt, er egne strukturenheter og står utenfor foregående/påfølgende <p>/<l>.
<lb/><l>bla bla bla</l> <lb/><stage>tekst</stage> <lb/><l>bla bla</l>
Sceneanvisninger som forekommer mellom replikker, skal stå innenfor den første av de to replikkene (dvs. før replikkslutt i denne), hvis de er ufullstendige setninger der replikkinnehaver fungerer som subjekt i setningen. Hvis sceneanvisningen derimot er en fullstendig setning, plasseres den utenfor replikken.
Eksempel med sceneanvisning utenfor <sp>:
<lb/><sp who="PETERSTOCKMANN"><spOpener><speaker>Byfogden</speaker>.</spOpener> <lb/><p>Jeg vil ikke udsætte mig for voldsomheder. <lb/>Du er nu advaret. Betænk så, hvad du skylder <lb/>dig og dine. Farvel.</p></sp> <lb/><stage>(han går.)</stage>
Eksempel med sceneanvisning innenfor <sp>:
<lb/><sp who="REGINE"><spOpener><speaker>Regine</speaker> <lb/><stage>(med en pakke, fra spisestuen)</stage>.</spOpener> <lb/><p>Her er kommet en pakke til fruen.</p> <lb/><stage>(rækker hende den.)</stage></sp>
kap-6.8.1: Ulike utforminger av sceneanvisninger
I Fj4935, den ufullendte renskriften til Fjeldfuglen, forekommer det spesielle sceneanvisninger. Som faksimilen viser, samler én sceneanvisning hele og deler av flere replikker som skal utsies samtidig:

Sceneanvisningen transkriberes foran den synkroniserte teksten (uten eget linjeskiftselement) og kodes med <stage rend="braced">. <stage> legges imidlertid rundt det innklammede partiet slik at sceneanvisningen omslutter teksten.
<stage rend="braced">paa engang. <lb/><sp who="THORGEJR"><spOpener> <speaker rend="noUnderline">Thorgejr</speaker>.</spOpener> <lb/><lg part="Y" type="strofisk strofe kortvers" an="single" met="bi+ 5" rhyme="X"> <l rend="indent1" met="v-v-v" rhyme="X">Det Kvad som kvædes</l> <lb/><l rend="indent1">o. s. v, – o. s. v.</l></lg></sp><pb ed="hu"/> <lb/><sp who="ALFHILD"><spOpener><speaker rend="underlined">Alfhild</speaker>. <lb/><stage rend="fineUnderline">(drømmende)</stage></spOpener> <lb/><lg type="strofisk strofe kortvers" an="single" met="bi+ (5 5)2 (5 4)2" rhyme="(X A)2 (X b)2"><l rend="indent1" first="yes" met="v-v-v" rhyme="X">Det Kvad, som kvædes</l> <lb/><l rend="indent1" met="v-vv-v" rhyme="A">I Fossen den stride, –</l> <lb/><l rend="indent1" met="v-vv-v" rhyme="X">Det tykkes mig rumme</l> <lb/><l rend="indent1" met="v-v-v" rhyme="A">Saa tung en Kvide;</l> <lb/><l rend="indent1" met="v-v-v" rhyme="X">Den Laat, som ljomer</l> <lb/><l rend="indent1" met="v-v-" rhyme="b">I Lauv og Bar,</l> <lb/><l rend="indent1" met="-vv-v" rhyme="X">Tykkes mig kræve</l> <lb/><l rend="indent1" met="v-v-" rhyme="b">Fra Bringen Svar!</l></lg></sp> <join targets="hougfolk-1 hougfolk-2" targOrder="Y"/> <lb/><sp who="HOUGFOLK" id="hougfolk-1" next="hougfolk-2"><spOpener><speaker rend="underlined">Chor af Hougfolk</speaker> <lb/><stage rend="fineUnderline">(idet de sagte nærme sig.)</stage></spOpener> <lb/><lg type="strofisk kortvers" an="single" met="bi+ 5 5 5 5" rhyme="X X X X | A B A B" part="I"><note type="met" resp="SBT">Usikker på formeloppsett. Jambisk el. trokeisk? (Tror det er folkevisevers i kortform, og dermed jambiske. Sjelden opptaktsavvik blant trokeene.)</note><lg type="strofe" rhyme="X X X X"><l first="yes" met="-vv-v" rhyme="X">Alfhild, den Væne!</l> <lb/><l rend="indent1" met="-v-v" rhyme="X">Stille, stille, –</l> <lb/><l rend="indent1" met="-vv-v" rhyme="X">Væk hende ikke,</l> <lb/><l rend="indent1" met="-vv-v" rhyme="X">Lad hende drømme!</l></lg> <lb/><lg type="strofe" rhyme="A B A B"><l rend="indent1" met="-vv-v" rhyme="A">Hør Strengen graater,</l> <lb/><l rend="indent1" met="-vv-v" rhyme="B">Hør Fossen kvæder!</l> <lb/><l rend="indent1" met="vv-vv-v" rhyme="A">Over Lien det laater</l> <lb/><l rend="indent1" met="v-vv-v" rhyme="B">Mens Dandsen vi træder!</l></lg></lg></sp> </stage> <lb/><sp who="HOUGFOLK" id="hougfolk-2" prev="hougfolk-1"> <stage rend="fineUnderline">(Thorgejr spiller, Alfhild synes drømmende <lb/>at lytte mens Hougfolket danser og gjen‐ <lb/>tager:)</stage> <lb/><lg type="strofisk kortvers" an="single" met="bi+ 5 5 5 5" rhyme="X X X X | A B A B" part="F"> <lg part="Y" type="strofe" rhyme="A"><l rend="indent1" met="-vv-v" rhyme="A">Hør Strengen graater</l> <lb/><l rend="indent1">o. s. v, – o. s. v.</l></lg></lg></sp>
Eksempel hentet fra Fj4935.
Replikker og verslinjegrupper som strekker seg utover den innklammede teksten blir splittet opp i flere <sp>- eller <lg>-elementer og lenket sammen.
Alle rollenavn/-betegnelser som er typografisk markert i sceneanvisninger skal kodes med <stageRole>. I who=""-attributtet brukes samme attributtverdier som i who="" i <sp>, dvs. id=""-attributtverdiene fra rollelista. (Se who="" i <sp> og <stageRole>)
Beskrivelsen av typografien i uthevingen av rollenavn/-betegnelser gjøres i <teiHeader>. Avvik, dvs. rollenavn med annen markering (ikke ingen markering) enn systemets, beskrives også og kodes med <stageRole who="" rend="deviation">.
Uthevede ord som ikke er rollenavn/-betegnelser skal kodes med <hi> (ikke <stageRole>):
en av <hi>Sigurds</hi> mænd <hi>Margretes</hi> kammer
Eksempel fra HH98 og KE.
Lengre sekvenser med sammenhengende markering kan få forskjellig koding alt etter hvordan det fortolkes. Sammenbinding av sekvens med side- («og») eller underordnende («med») ord kan bestemme om sekvensen skal kodes som helhet eller deles opp.
<stageRole>Kejser Konstanzios med hele sit følge</stageRole>
Eksempel fra KG/KGHU.
For plassering av interpunksjon som er uthevet (med f.eks. fet, kursiv eller understreking), se «Husregler for plassering av interpunksjon».
kap-7.1: Innledning
Sakprosa er samlet i fem samlefiler etter årstall. Kategorien inneholder både artikler og taler, og både trykte tekster og manuskripter. Tekstene skal likevel plasseres kronologisk i samlefilene. Varia ligger foreløpig i enkeltfiler, men skal samles før publisering i HISe. Se «Retningslinjer for strukturkoding, kap. 3» for detaljer om strukturen i samlefilene.
kap-7.2: TEI-header
Hver samlefil skal ha en overordnet TEI-header øverst i filen. I <sourceDesc> skal det finnes en liste over hvilke filnavn filen inneholder. Unike id-verdier samles i <teiHeader type="corpus">. Tilsvarende opplysninger fjernes i tekstenes interne <teiHeader>-elementer. I <langUsage> legges for eksempel språkattributtenes id-verdier kun i samlefilens overordnede <teiHeader>, mens et tomt <language>-element legges i tekstens interne <teiHeader>.
Slik er samlefilens teiHeader:
<?xml version="1.0" encoding="ISO-8859-1"?> <!DOCTYPE teiCorpus.2 PUBLIC "-//TEI P4 Ibsen-XML//DTD TEI P4 Unified for HIS//EN" "I:\Prosjekt\Oppslagsverk\Ibsen-dtder\ibsen-xml.dtd"> <teiCorpus.2> <teiHeader type="corpus" lang="nob"> <fileDesc> <titleStmt> <title level="s" type="main">Henrik Ibsens skrifter</title> <title level="s" type="sub">Diplomatarisk tekstarkiv</title> <title level="a" type="main">Prosa 1841–59</title> <title level="a" type="sub">Grunntekster</title> <funder>&funder;</funder> <editor>&editor;</editor> <respStmt> <resp>Oppretting av corpus-fil:</resp> <name>Ellen Nessheim Wiger</name> <resp>Kodekontroll</resp> <name></name> </respStmt> </titleStmt> <editionStmt><edition id="P1841-1859gt-0408"/></editionStmt> <publicationStmt> <publisher>Universitetet i Oslo ved Henrik Ibsens skrifter</publisher> <distributor id="HISb">H. Aschehoug & co</distributor> <date value="" id="HISb-date"/> <distributor id="HISe">Universitetet i Oslo</distributor> <date value="2007" id="HISe-date"/> <pubPlace>Oslo</pubPlace> </publicationStmt> <sourceDesc> <lb/><p><list> <head>Grunntekstfiler</head> <item>FILNAVN.xml</item> <item>FILNAVN.xml</item> <item>FILNAVN.xml</item> </list></p> </sourceDesc> </fileDesc> <encodingDesc> <projectDesc><p>&projectDesc-grt-ms;</p></projectDesc> <editorialDecl> <stdVals><p>&stdVals;</p></stdVals> <p>&editorialDecl;</p> </editorialDecl> <tagsDecl> <tagUsage gi="tei.2">&tagUsage-tei2;</tagUsage> <tagUsage gi="id-base">&Ibsen-keys;</tagUsage> </tagsDecl> <variantEncoding type="alteration" method="parallel-segmentation" location="internal"/> </encodingDesc> <profileDesc> <langUsage> <language id="nob"/> <language id="Dano-Norwegian"/> </langUsage> </profileDesc> <revisionDesc> <change><date></date> <respStmt><name></name><resp></resp></respStmt> <item></item></change> </revisionDesc> </teiHeader>
kap-7.2.2: Sakprosa-TEI-header
Hver enkelt tekst i samlefilen har sin egen <teiHeader> som er noe forkortet, og som er konsentrert om de spesifikke opplysningene for den angjeldende teksten. Det ligger fullstendige eksempler på teiHeader for de ulike teksttypene her: Eksempler.
Første del er lik for alle teksttyper og ser slik ut:
<TEI.2 corresp="FILNAVN"> <teiHeader lang="nob"> <fileDesc> <titleStmt> <title level="s" type="main">Henrik Ibsens skrifter</title> <title level="s" type="sub">Diplomatarisk tekstarkiv</title> <title level="a" type="main">FILNAVN</title> <title level="a" type="sub">Grunntekst/tekstkilde</title> <author>Henrik Ibsen</author> <funder>&funder;</funder> <editor>&editor;</editor> <respStmt> <resp>1. kollasjon, XXXX 2008</resp> <name>XXX</name> <resp>2. kollasjon, XXXX 2008</resp> <name>XXX</name> </respStmt> </titleStmt> <editionStmt><edition id="FILNAVN-0408"/> </editionStmt> <publicationStmt><p>Se samlefilens teiHeader.</p> </publicationStmt>
kap-7.2.2.1: <sourceDesc>
<sourceDesc> inneholder opplysninger om det aktuelle dokumentet. Ved trykte tekster brukes <bibl>, ved håndskrifter <msDescription>.
Ved trykt tekst:
<bibl id="FILNAVN"> <orgName type="owner">EIERINSTITUSJON</orgName> <idno>SIGNATUR</idno>
Ved håndskrifter:
<msDescription type="finalFairCopy" id="FILNAVN"> <msIdentifier> <settlement>STED</settlement> <repository>EIERINSTITUSJON</repository> <idno>SIGNATUR</idno> </msIdentifier> </msDescription>
kap-7.2.2.2: <analytic>
Inne i <analytic> oppgis opplysninger om forfatter, tittel og eventuelt innhold (ved titler som ikke er meningsbærende). <title type="main"> er den øverste overskriften som står over teksten, ofte et stykke før Ibsens tekst starter, mens <title type="sub"> er underoverskriften som står nærmest Ibsens tekst. Den kan være i form av en hilsen (Mine damer og herrer), en uthevet del av første linje i teksten eller en underoverskrift lenger opp i artikkelen. Når overskriftene ikke gir nok informasjon om hva teksten omhandler (f.eks. "Theatret"), suppleres de med en tilleggs-tittel med type-attributtet occasion, der man opplyser om hvilken begivenhet det dreier seg om, eller hva som anmeldes:
<analytic> <author>Henrik Ibsen</author> <title type="main">HOVEDOVERSKRIFT</title> <title type="sub">UNDEROVERSKRIFT</title> <title type="occasion">ANMELDELSE AV OSV.</title> </analytic>
kap-7.2.2.3: <monogr>
Deretter, i <monogr>, gis opplysninger om publisering:
<monogr> <title>PUBLIKASJONENS TITTEL (UKEDAG, NR., ÅRGANG)</title> <imprint> <pubPlace>STED FOR PUBLISERING</pubPlace> <publisher>FORLAG/UTGIVER</publisher> <printer>(kan utelates)</printer> <date>DATO FOR TRYKK</date> </imprint> </monogr>
kap-7.2.2.4: <proseinfo>
Siste punkt i <sourceDesc> er <proseinfo>, som inneholder opplysninger om teksttype og eventuelt anledning for taler o.l. Det er tillatt med arbeidsnoter her.
kap-7.2.2.4.1: Typeattributt i <proseinfo>
Vi oppgir hvilken type tekst det er snakk om ved hjelp av et type-attributt i <proseinfo>.
- <proseinfo type="article">
- <proseinfo type="speech">
- <proseinfo type="review">
Siden vi redegjør for hva slags teksttype det dreier seg om her, er det ikke nødvendig å ta med slike opplysninger i <matDesc>.
kap-7.2.2.4.2: <occasion>
Dette punktet vil som regel være overflødig ved artikler, men må alltid med ved taler og kan tas med ved behov også for andre teksttyper. Her oppgis det hvilken begivenhet det gjelder, f.eks. ved hvilken anledning en tale ble holdt. I <placeName> og <date value> oppgis
når og hvor den aktuelle begivenheten fant sted.
<occasion>BEGIVENHET</occasion> <placeName> <rs type="place" corresp="plXXX">STED FOR BEGIVENHET</rs> </placeName> <date value="yyyy-mm-dd">DATO FOR BEGIVENHET (EKS. 01.10.1888)</date> <matDesc>EKSTRAOPPLYSNINGER</matDesc> </proseinfo>
kap-7.2.2.4.3: <matDesc>
<proseinfo> skal også inneholde <matDesc>. I <matDesc> legges opplysninger som bør inkluderes i filen, men som faller utenfor kodingen. Her noteres det om teksten er i antikva eller fraktur, om typografien avviker fra den omkringliggende teksten, illustrasjoner, vedlegg, bibliotekstempler (ved manuskript), koblinger til andre tekster o.l. Ved taler legges transkripsjon av eventuell innledende tekst her. All originaltekst som gjengis i <matDesc>, settes i kodede anførselstegn. Det er ikke nødvendig å opplyse om teksttype her, siden det angis ved hjelp av type-attributtet i proseinfo.
kap-7.2.2.5: <projectDesc>
<projectDesc> er det eneste punktet som behøver tilpasning i <encodingDesc>. Grunntekster som bygger på manuskripter skal ha entiteten projectDesc-grt-ms i <projectDesc>. Ved grunntekster som bygger på trykk skal entiteten være projectDesc-grt-trykk.
<encodingDesc> <projectDesc><p>&projectDesc-grt-ms;</p></projectDesc> ... </encodingDesc>
kap-7.2.2.6: <profileDesc>
I <profileDesc> legges informasjon om hva som er gjort med filen, siste endring øverst:
<profileDesc> <langUsage><language/></langUsage> </profileDesc> <revisionDesc> <change><date>25.09.08</date> <respStmt><name>NME</name><resp>Koding</resp></respStmt> <item>La inn resultater etter IMKs førstekollasjon mot utskrift av mikrofilm.</item></change> <change><date>23.04.08</date> <respStmt><name>ENW</name><resp>Oppretting</resp></respStmt> <item>Konverterte dokpros transkripsjon til TEI XML. Klar for 1. kollasjon.</item></change> </revisionDesc> </teiHeader>
kap-7.2.3: Eksempler
Det er fire ulike teiheadere i sakprosa: artikler (trykk og manuskript) og taler (trykk og manuskript). Slik ser headeren ut for hver av teksttypene:
kap-7.2.3.1: Artikkel (trykk)
<TEI.2 corresp="filnavn"> <teiHeader lang="nob"> <fileDesc> <titleStmt> <title level="s" type="main">Henrik Ibsens skrifter</title> <title level="s" type="sub">Diplomatarisk tekstarkiv</title> <title level="a" type="main">FILNAVN</title> <title level="a" type="sub">Grunntekst/tekstkilde</title> <author>Henrik Ibsen</author> <funder>&funder;</funder> <editor>&editor;</editor> <respStmt> <resp>1. kollasjon, XXXX 2008</resp> <name>XXX</name> <resp>2. kollasjon, XXXX 2008</resp> <name>XXX</name> </respStmt> </titleStmt> <editionStmt><edition id="FILNAVN-0408"/> </editionStmt> <publicationStmt><p>Se samlefilens teiHeader.</p> </publicationStmt> <sourceDesc> <p>FILNAVN, elektronisk versjon. Bygger på dokpros transkripsjon av HU15.</p> <bibl id="FILNAVN"> <orgName type="owner">EIERINSTITUSJON</orgName> <idno>SIGNATUR</idno> <analytic> <author>Henrik Ibsen</author> <title type="main">OVERSKRIFT</title> <title type="sub">EV. UTHEVET FØRSTELINJE</title> <title type="occasion">ANMELDELSE AV OSV.</title> </analytic> <monogr> <title>PUBLIKASJONENS TITTEL (+ UKEDAG, NR, ÅRG.)</title> <imprint> <pubPlace>STED FOR PUBLISERING</pubPlace> <publisher>FORLAG/UTGIVER</publisher> <printer>(kan utelates)</printer> <date>DATO FOR TRYKK</date> </imprint> </monogr> <proseinfo type="article"> <matDesc></matDesc> </proseinfo> </bibl> </sourceDesc> </fileDesc> <encodingDesc> <projectDesc><p>&projectDesc-grt-trykk;</p></projectDesc> <editorialDecl> <stdVals><p>&stdVals;</p></stdVals> <p>&editorialDecl;</p> </editorialDecl> <tagsDecl> <tagUsage gi="tei.2">&tagUsage-tei2;</tagUsage> </tagsDecl> </encodingDesc> <profileDesc> <langUsage><language/></langUsage> </profileDesc> <revisionDesc> <change><date></date> <respStmt><name></name><resp></resp></respStmt> <item></item></change> </revisionDesc> </teiHeader>
kap-7.2.3.2: Artikkel (manuskript)
<TEI.2 corresp="filnavn"> <teiHeader lang="nob"> <fileDesc> <titleStmt> <title level="s" type="main">Henrik Ibsens skrifter</title> <title level="s" type="sub">Diplomatarisk tekstarkiv</title> <title level="a" type="main">FILNAVN</title> <title level="a" type="sub">Grunntekst/tekstkilde</title> <author>Henrik Ibsen</author> <funder>&funder;</funder> <editor>&editor;</editor> <respStmt> <resp>1. kollasjon, XXXX 2008</resp> <name>XXX</name> <resp>2. kollasjon, XXXX 2008</resp> <name>XXX</name> </respStmt> </titleStmt> <editionStmt><edition id="FILNAVN-0408"/></editionStmt> <publicationStmt><p>Se samlefilens teiHeader.</p></publicationStmt> <sourceDesc> <p>FILNAVN, elektronisk versjon. Bygger på dokpros transkripsjon av HU15.</p> <msDescription type="article" id="FILNAVN"> <msIdentifier> <settlement>STED</settlement> <repository>EIERINSTITUSJON</repository> <idno>SIGNATUR</idno> </msIdentifier> <msHeading> <author>Henrik Ibsen</author> <title type="main">OVERSKRIFT</title> <title type="sub">EV. UTHEVET FØRSTELINJE</title> <title type="occasion">ANMELDELSE AV OSV.</title> <origDate>DATERING</origDate> </msHeading> <proseinfo type="article"> <matDesc></matDesc> </proseinfo> </msDescription> </sourceDesc> </fileDesc> <encodingDesc> <projectDesc><p>&projectDesc-grt-ms;</p></projectDesc> <editorialDecl> <stdVals><p>&stdVals;</p></stdVals> <p>&editorialDecl;</p> </editorialDecl> <tagsDecl> <tagUsage gi="tei.2">&tagUsage-tei2;</tagUsage> </tagsDecl> </encodingDesc> <profileDesc> <langUsage><language/></langUsage> <handList> <hand hand="FILNAVN-HI" id="FILNAVN-HI" ink="XX" first="yes"><p>Blekk. Henrik Ibsen. Hovedhånd</p></hand> </handList> </profileDesc> <revisionDesc> <change><date></date> <respStmt><name></name><resp></resp></respStmt> <item></item></change> </revisionDesc> </teiHeader>
kap-7.2.3.3: Tale (trykk)
<TEI.2 corresp="filnavn"> <teiHeader lang="nob"> <fileDesc> <titleStmt> <title level="s" type="main">Henrik Ibsens skrifter</title> <title level="s" type="sub">Diplomatarisk tekstarkiv</title> <title level="a" type="main">FILNAVN</title> <title level="a" type="sub">Grunntekst/tekstkilde</title> <author>Henrik Ibsen</author> <funder>&funder;</funder> <editor>&editor;</editor> <respStmt> <resp>1. kollasjon, XXXX 2008</resp> <name>XXX</name> <resp>2. kollasjon, XXXX 2008</resp> <name>XXX</name> </respStmt> </titleStmt> <editionStmt><edition id="FILNAVN-0408"/> </editionStmt> <publicationStmt><p>Se samlefilens teiHeader.</p> </publicationStmt> <sourceDesc> <p>FILNAVN, elektronisk versjon. Bygger på dokpros transkripsjon av HU15.</p> <bibl id="FILNAVN"> <orgName type="owner">EIERINSTITUSJON</orgName> <idno>SIGNATUR</idno> <analytic> <author>Henrik Ibsen</author> <title type="main">OVERSKRIFT</title> <title type="sub">EV. UTHEVET FØRSTELINJE</title> </analytic> <monogr> <title>PUBLIKASJONENS TITTEL (UKEDAG, NR., ÅRGANG)</title> <imprint> <pubPlace>STED FOR PUBLISERING</pubPlace> <publisher>FORLAG/UTGIVER</publisher> <printer>(kan utelates)</printer> <date>DATO FOR TRYKK</date> </imprint> </monogr> <proseinfo type="speech"> <occasion>BEGIVENHET</occasion> <placeName> <rs type="place" corresp="plXXX">STED FOR BEGIVENHET</rs> </placeName> <date value="yyyy-mm-dd">DATO FOR BEGIVENHET (EKS. 01.10.1888)</date> <matDesc></matDesc> </proseinfo> </bibl> </sourceDesc> </fileDesc> <encodingDesc> <projectDesc><p>&projectDesc-grt-trykk;</p></projectDesc> <editorialDecl> <stdVals><p>&stdVals;</p></stdVals> <p>&editorialDecl;</p> </editorialDecl> <tagsDecl> <tagUsage gi="tei.2">&tagUsage-tei2;</tagUsage> </tagsDecl> </encodingDesc> <profileDesc> <langUsage><language/></langUsage> </profileDesc> <revisionDesc> <change><date></date> <respStmt><name></name><resp></resp></respStmt> <item></item></change> </revisionDesc> </teiHeader>
kap-7.2.3.4: Tale (manuskript)
<TEI.2 corresp="filnavn"> <teiHeader lang="nob"> <fileDesc> <titleStmt> <title level="s" type="main">Henrik Ibsens skrifter</title> <title level="s" type="sub">Diplomatarisk tekstarkiv</title> <title level="a" type="main">FILNAVN</title> <title level="a" type="sub">Grunntekst/tekstkilde</title> <author>Henrik Ibsen</author> <funder>&funder;</funder> <editor>&editor;</editor> <respStmt> <resp>1. kollasjon, XXXX 2008</resp> <name>XXX</name> <resp>2. kollasjon, XXXX 2008</resp> <name>XXX</name> </respStmt> </titleStmt> <editionStmt><edition id="FILNAVN-0408"/></editionStmt> <publicationStmt><p>Se samlefilens teiHeader.</p></publicationStmt> <sourceDesc> <p>FILNAVN, elektronisk versjon. Bygger på dokpros transkripsjon av HU15.</p> <msDescription type="speech" id="FILNAVN"> <msIdentifier> <settlement>STED</settlement> <repository>EIERINSTITUSJON</repository> <idno>SIGNATUR</idno> </msIdentifier> <msHeading> <author>Henrik Ibsen</author> <title type="main">OVERSKRIFT</title> <title type="sub">EV. UTHEVET FØRSTELINJE</title> <origDate>DATERING</origDate> </msHeading> <proseinfo type="speech"> <occasion>BEGIVENHET</occasion> <placeName> <rs type="place" corresp="plXXX">STED FOR BEGIVENHET</rs> </placeName> <date value="yyyy-mm-dd">DATO FOR BEGIVENHET (EKS. 01.10.1888)</date> <matDesc></matDesc> </proseinfo> </msDescription> </sourceDesc> </fileDesc> <encodingDesc> <projectDesc><p>&projectDesc-grt-ms;</p></projectDesc> <editorialDecl> <stdVals><p>&stdVals;</p></stdVals> <p>&editorialDecl;</p> </editorialDecl> <tagsDecl> <tagUsage gi="tei.2">&tagUsage-tei2;</tagUsage> </tagsDecl> </encodingDesc> <profileDesc> <langUsage><language/></langUsage> <handList> <hand hand="FILNAVN-HI" id="FILNAVN-HI" ink="XX" first="yes"><p>Blekk. Henrik Ibsen. Hovedhånd</p></hand> </handList> </profileDesc> <revisionDesc> <change><date></date> <respStmt><name></name><resp></resp></respStmt> <item></item></change> </revisionDesc> </teiHeader>
For nærmere beskrivelse av de delene av teiHeader som er felles for brev og sakprosa, se kap. 3 i brevkodepraksis.
kap-7.2.4: Varia-TEI-header
TEKST + EKS. KOMMER
kap-7.3.1: Overskrifter
Avisoverskrifter på egen linje kodes med <head> med linjeskift. Når overskriften består i at en del av første setning er uthevet eller understreket, kodes dette med <hi rend="bold"> eller <hi rend="underlined"> uten linjeskift. (Retorisk uthevet tekst kodes med <emph>.)
Hvis hovedoverskriften går over flere linjer, kodes den ved hjelp av <lb/> innenfor <head>.
Underoverskrifter ved artikler i flere deler kodes med <head type="articlePart"> i egen div.
kap-7.3.2: Nummerering av sider og spalter/kolonner
Ved avisartikler prøver vi så langt det er mulig å opplyse om artikkelens plassering i avisen for å gjøre det enklere å gjenfinne teksten.
Faktisk nummerering av side eller spalte legges i <fw> med type- og place-attributt, og med en <lb/> foran:
<lb/><fw type="page" place="bottom">124</fw>
<lb/><fw type="column" place="top-left">92</fw>
Når det finnes en nummerering å legge inn i <fw>, er det ikke nødvendig å legge inn noe attributt i <pb/> og <cb/>.
Hvis nummerering mangler, angir vi side- og spaltenummer i skarpe klammer ved hjelp av attributtverdier i <pb/> og <cb/> (columne break), hvis vi kan finne frem til det.
<pb n="[4]"/>
<cb n="sp. [1]"/>
Hvis man ikke klarer å slutte seg til side- eller spaltenummeret, lar man <pb/> og <cb/> stå uten n-attributt (sidetall genereres ikke automatisk dersom det mangler i <pb/>.)
For hver nye spalte legger man inn <cb n="sp. []"/> med fortløpende nummerering ut fra antall spalter på siden.
Skarpe klammer og sp. kan enkelt legges inn i textpad ved disse søkeuttrykkene:
<cb n="\([0-9]*\)" erstattes med <cb n="sp. \[\1\]"
<pb n="\([0-9]*\)" erstattes med <pb n="\[\1\]"
Eksempler:
Eksempel på koding av P18511130Stub fra Illustreret Nyhedsblad, der sider og spalter er unummerert:
<body> <pb n="[2]"/> <cb n="sp. [1]"/> <div> ... <cb n="sp. [2]"/>

Eksempel på koding av P18510810Stort fra Andhrimner, med spaltenummerering øverst på siden (når vi kjenner enten side- eller spaltenummer, trenger vi ikke legge inn tall i <pb> eller <cb>):
<body>
<pb/>
<cb/>
<lb/><fw type="column" place="top">92</fw>
<div>

Ved faksimiler som befinner seg i faksimilebasen, skal det presiseres i <pb> at det er faksimilebasens sidetall som angis. Dette kodes slik:
<pb ed="faksbase" n="[1]"/>.
kap-7.3.2.1: Koding av omkringliggende tekst
Dersom ibsenteksten begynner midt i en nummerert kolonne, og vi altså koder med <lb/><fw type="column" place=""></fw>, koder vi ikke den utelatte omkringliggende teksten med <gap/>, selv om vi strengt tatt hopper over ikke-ibsentekst mellom kolonnenummereringen og ibsenteksten.
I eksempelet nedenfor skal altså kodingen være:
<body> <pb/> <cb/> <lb/><fw type="column" place="top">62</fw> <div type="poem"> <lb/><head type="main">Edderfuglen.</head>
og ikke:
<body> <pb/> <cb/> <lb/><fw type="column" place="top">62</fw> <lb/><gap type="irrelevant/> <div type="poem"> <lb/><head type="main">Edderfuglen.</head>
kap-7.3.3: Illustrasjoner
Ved illustrasjoner på avissiden kodes de ulikt ut fra om de er tilknyttet Ibsens tekst eller ikke. Irrelevante bilder som avbryter teksten, kodes med <gap reason="irrelevant">, mens tekstillustrasjoner kodes med <figure type="illustration"> og lenkes til hvis det er en Ibsen-illustrasjon.
kap-7.3.4: Transkripsjon
For transkripsjonsretningslinjer, se «Retningslinjer for detaljkoding», kap. 8 «Transkripsjonsnormalisering» og «Retningslinjer for transkripsjon og koding av diverse håndskriftsfenomener», kap. 16 «Retningslinjer».
kap-7.3.5: Skillingstegn
Forkortelsen for skilling i trykte tekster er ofte en tysk dobbel-s, denne kodes med entiteten ß. I Ibsens tidlige håndskrift kan skillingstegnet være en lang s med strek over, denne kodes med entiteten &skilling;.
kap-7.3.6: Trykt tekst i håndskrifter
For pretrykt tekst brukes elementet <print> på samme måte som <emph> og <hi>. Elementet brukes ved innslag av trykt tekst som inngår i brødteksten i håndskriftmateriale, som pretrykte kontrakter o.l.
kap-7.3.7: Signatur
Signaturer kodes i <signed> direkte i <div>. Det gjelder både for signaturer som står på egen linje og for signaturer som inngår i den løpende teksten. Hvis en annen enn hovedhånden har undertegnet, legger vi inn et hand-attributt i <signed>. I trykte artikler med note fra redaksjonen kodes signaturen "Red." også i signed.
kap-7.3.8: Noter
kap-7.3.8.1: i trykk
Flere av de trykte artiklene har noter nederst på siden. Disse kodes som <note resp="publisher"> når det er redaksjonelle noter (som f.eks. ordforklaringer eller opplysninger om fortsettelse o.l.) og som <note resp="author"> når det er Ibsens noter.
Lenkingen mellom referansetegn i teksten og bunnote skal se slik ut:
<ref type="refMark" target="n2" id="nb2">*)</ref>
<note resp="publisher" place="bottom"><ref type="refMark" target="nb2" id="n2">*)</ref> (notetekst)</note>
Verdiene i target og id må være unike i fila.
kap-7.3.8.2: i manuskript
Noter i manuskript kodes med <add> og med <place-> og <hand->atributt, og vår beskrivelse av plasseringen legges i <note resp="editor">:
<add place="margin" hand="PAbydos_1a-HI-2"><note resp="editor">Plassering av margin-tilføyelse: I venstre marg, vertikalt</note> <ref type="refMark" hand="PAbydos_1a-HI-2" target="nb1" id="n1">1)</ref> Bemærkninger om hvorledes dette kaos o.s.v.</add>
kap-7.3.9: Tabellkoding
For å kunne tilpasse visningen av tabeller bedre til tekstoppsettet i originalen, kan man bruke rend-attributter som regulerer hvor tekstinnholdet i hver <cell> plasseres. Disse er i bruk:
- rend="left"
- rend="left-top"
- rend="left-bottom"
- rend="right-top"
- rend="right-bottom"
Dette er særlig relevant ved tabeller der teksten i hver <cell> går over flere linjer.
(Hvis man ikke legger inn noe rend-attributt, blir teksten høyrestilt og plassert nederst i cellen.)
kap-7.3.10: Koding av personnavn, stedsnavn og verkstitler
I sakprosa og varia – men bare i hovedtekster – skal personnavn, stedsnavn, verk og enkelte institusjonsnavn kodes, se «Retningslinjer for detaljkoding».
kap-8: Verskoding
kap-8.1: Hvilke tekster har verskoding?
I de teksttypene som inneholder vers (dikt og versdramaer) detaljkodes versstrukturene. Dette gjelder bare hovedtekstene, som brukerne vil kunne velge å se med løpende metrisk notasjon. Versstrukturene kodes i samsvar med Jørgen Fafners danske verslære, slik den blir framstilt i flerbindsverket Dansk Verskunst 1989-2000.
kap-8.1.2: Sjangeravgrensninger
kap-8.1.2.1: Sondring mellom prosa og vers
I enkelte tilfeller kan det være vanskelig å avgjøre om et tekststed er i prosa eller på vers. Her er et eksempel fra Norma, der de to første replikklinjene er på vers og den siste i prosa:
<lb/><sp><spOpener><speaker>Ariovist</speaker>.</spOpener> <lb/><l>Her staae vi paa Frihedens frieste Jord,</l> <lb/><l>I det gamle, ja, i det ældgamle Nor!</l> <lb/><stage>(afsides)</stage> <lb/><p>Ja, for Norge er Død og Pine et ældgammelt Land.</p></sp>
Den siste linja inneholder et ekstra taktledd og er uten rim. Dessuten bryter ordvalget («Død og Pine») med høystilen som kjennetegner versene ellers i stykket. Replikken har heller ikke innrykk, slik som de øvrige verslinjene. Derfor er denne kodet som prosa, ikke som vers.
Vi har kommet fram til følgende kriterier for å sondre mellom prosa og vers:
- metrisk mønster
- rimmønster
- typografisk oppsett
- stil, ordvalg
kap-8.2: <teiHeader>
Alle filer som inneholder metrisk koding (hovedtekstfiler for dikt og versdramaer) skal ha en standardtekst i <metDecl> i <encodingDesc>. Denne hentes fram med en entitet:
<metDecl> <p>&metDecl;</p> </metDecl>
kap-8.3: Verslinjer
Verslinjer kodes med <l>.
Informasjon om sjangerspesifikk verslinjekoding finnes i kapitlet om diktkoding (inkomplette verslinjer) og om dramakoding (koding av oppdelte verslinjer og inkomplette verslinjer).
kap-8.3.1: Metrikk vs. typografi
Verslinjer defineres metrisk, ikke typografisk. Linjeskift som forekommer innenfor verslinjer, kodes som vanlig med <lb/> innenfor <l>. Dersom linjeskiftet skyldes en feil i det typografiske oppsettet, bemerkes dette i en utgivernote (<note resp="editor">). Eksempler finnes i dramakapitlet og i diktkapitlet.
HIS' hovedtekster skal følge en enhetlig typografisk standard, mens de diplomatariske tekstene i tekstarkivet skal gjengi den originale typografien. Derfor behandles hovedtekster og grunntekster forskjellig på dette punktet.
I grunntekstene bevarer vi informasjon om det typografiske oppsettet av verstekstene, både fordi det kan ha en semantisk funksjon (som f.eks. innholdsbasert avsnittsinndeling) og for å dokumentere ev. endringer i oppsett i vershistorien. Innrykk, blanke linjer og midtstilling kodes henholdsvis med <l rend="indent">, <l rend="line"> (gjelder verslinja under den blanke linja) og <l rend="centre">. Dersom det finnes flere grader av innrykk, kodes disse med "indent1", "indent2", "indent3" osv. Slik typografisk koding legges til under opprettelsen av filene.
I hovedtekstene (som inneholder verskoding) kodes ikke gjennomgående innrykk av frittstående sanger/dikt. Det er bare verslinjer som skal ha ekstra innrykk i forhold til omliggende verslinjer som innrykkskodes, typisk gjelder dette for korte verslinjer. Det kodes inntil tre innrykksgrader: <l rend="indent1">, <l rend="indent2"> og <l rend="indent3">. Det avgjøres fra gang til gang hvilke innrykk som skal beholdes; f.eks. vil ofte to innrykksgrader slås sammen til ett. Innrykkede verslinjer i ustrofiske versreplikker, der innrykket fungerer som innholdsbasert avsnittsmarkering, kodes med <l rend="indent">. Innrykk først i replikk standardiseres bort. Jf. også Produksjonskoding.
kap-8.3.2: Linjer med tankestreker
I noen verstekster forekommer det hele linjer med tankestreker. Slike linjer kodes med <l type="dashes">. Disse inkluderes ikke i de overordnede metriske formlene.
Her er et eksempel, et avsnitt fra «Balminder» i HU:
<lg type="rapsodisk Wergelandstroké" an="no" met="bi 4|7|8" rhyme="r|R">
...
<l rend="line" rhyme="t" met="7">Maaskee klinger det lidt sært,</l>
<l rhyme="U" met="8">Dertil og lidt upoetisk, –</l>
<l rhyme="U" met="8">For et Øre, fiint æsthetisk</l>
<l rhyme="t" met="7">Var det maaskee mere kjært</l>
<l rhyme="V" met="8">I en Balnats Sted at høre</l>
<l rhyme="V" met="8">Noget «Skjønnere» og «Større»,<note type="met">Urent rim.</note></l>
<l rhyme="w" met="7">Retsom om den lyse Sal,</l>
<l rhyme="w" met="7">Festligt smykket til et Bal,</l>
<l rhyme="Y" met="8">Hvor en yndig Flok Koketter</l>
<l rhyme="Y" met="8">Slynger Blikkets Brandraketter</l>
<l rhyme="z" met="7">Mens Musiken stemmer i, –</l>
<l rhyme="z" met="7">Var foruden Poesi! – – –</l>
<l type="dashes">– – – – – – – – – – –</l>
...
</lg>
Innenfor ikke-metriske tekster kodes linjer med tankestreker med det elementet som passer, f.eks. <p type="dashes">.
kap-8.3.3: Førstelinjekoding
Førstelinjer i verstekster kodes med <l first="yes">. Som førstelinjer regnes første verslinje i dikt og versdramaer, samt første verslinje etter hvert skifte til et nytt versemål i versdramaer.
Førstelinjekodingen skal benyttes til arbeidet med versregistranter i utgaven.
kap-8.4: Grupper av verslinjer
Verslinjegrupper kodes med <lg>. Gruppene defineres etter metriske, ikke etter typografiske eller innholdsmessige, kriterier. Tekstdivisjoner som er definert av andre kriterier enn metrikk, kodes med <div>. Om <div>-koding i dikt, se mer informasjon i kapitlet om diktkoding.
Verslinjer med det samme metriske mønsteret som følger på hverandre, utgjør ei verslinjegruppe. Strofer i dikt kodes som egne verslinjegrupper innenfor en større verslinjegruppe (hele diktet), fordi de utgjør en metrisk enhet som gjentas. Typografiske avsnitt, markert med innrykk, har vi i stikiske og rapsodiske tekster som rimbrev og versreplikker. Slike avsnitt utgjør ingen metrisk enhet fordi versantallet varierer og rimene gjerne krysser avsnittsgrensene. I slike tekster finnes det bare ei stor verslinjegruppe, som omslutter hele teksten. Det gis likevel informasjon om innrykkene, med rend-attributt på verslinjenivå: <l rend="indent"> (jf. punktet om typografisk markering).
Dtd-en er modifisert slik at elementene <sp>, <stage> og <div> er tillatt innenfor <lg>. I versdramaer kan <lg> derfor opptre på alle nivåer innenfor <text>; elementet kan omslutte hele dramateksten (hvis hele dramaet er skrevet i ett versemål), det kan omslutte akter, scener, en eller flere replikker, eller det kan opptre innenfor replikker (hvis deler av replikken er i prosa, deler på vers). Stilarkene for versdramaer imidlertid satt opp slik at lg-ene bør avsluttes før ny div.
kap-8.4.1: Typifisering
Hva slags type verslinjegruppe vi har med å gjøre, spesifiseres i type=""-attributtet (som kan ha en eller flere verdier). Attributtverdiene gir informasjon om både formdannelse, sjanger, strofeform, versemål etc.
kap-8.4.1.1: Formdannelse
Det første vi gir opplysninger om i type=""-attributtet, er hvorvidt formdannelsen er strofisk, stikisk eller rapsodisk.
kap-8.4.1.1.1: Strofisk
Tekster med en strofisk formdannelse er bygget opp av strofer i periodiske gruppedannelser. Det vil si at ett og samme avsnitt, eller en og samme forbindelse av avsnitt, blir gjentatt regelmessig. Slike tekster får type-attributtverdien "strofegruppe" eller "strofe", avhengig av om det består av n eller flere strofer:
<lg type="strofisk strofegruppe" an="single" met="bi+ 8 9 8 8 7" rhyme="a B a a B"> <sp><spOpener><speaker rend="smallCaps">kor</speaker></spOpener> <lg rend="poem"> <lg type="strofe"> <l met="v-vv-vv-vv-" rhyme="a">Velkommen i vort, de Forlovedes, Lag!</l> <l met="-vv-vv-v-v" rhyme="B">Nu kan I elske for aabne Døre,</l> <l met="-vv-vv-v-" rhyme="a">Nu kan I favnes den lange Dag,</l> <l met="-vv-v-vv-" rhyme="a">Nu kan I kysses efter Behag; –</l> <l met="-vv-vv-v" rhyme="B">Frygt ikke Lytterens Øre.</l> </lg> <lg type="strofe"> <l met="-vv-vv-vv-" rhyme="a">Nu kan I sværme saa dejligt, I To;</l> <l met="-vv-v-vv-v" rhyme="B">Det har I Lov til ude og hjemme.</l> <l met="-vv-vv-vv-" rhyme="a">Nu kan jer Kjærlighed frit sætte Bo;</l> <l met="-vv-vv-vv-" rhyme="a">Plej den og vand den og lad den saa gro;</l> <l met="-vv-vv-v" rhyme="B">Vis os nu pent I har Nemme!</l> </lg> </lg> </sp> </lg>
Eksemplet er fra KKht.
kap-8.4.1.1.2: Stikisk
Stikiske tekster består av ensartede vers som er koblet til hverandre i stadig fortsatt følge, uten noen inndeling i strofer. Disse tekstene betegnes med type-attributtverdien "stikisk":
<lg type="stikisk femfotsjambe blankvers" an="single" met="bi 10|11" rhyme="x|X|r|R">
<sp who="CATILINA"><spOpener><speaker rend="smallCaps">catilina</speaker>
<stage>staaer lænet mod et Træ til Venstre, hensunken i Eftertanke</stage></spOpener>
...
<l first="yes" rhyme="X">Jeg maa, jeg maa, saa byder mig en Stemme,</l>
<l rhyme="x">i Sjælens Dyb, og jeg vil følge den; –</l>
<l rhyme="X">jeg føler Kraft og Mod til noget bedre,</l>
<l rhyme="x">til noget Høiere end dette Liv –</l>
...
</lg>
Eksemplet er fra C1ht.
kap-8.4.1.1.3: Rapsodisk
En tredje type formdannelse er den rapsodiske. Tekster med en slik form er inndelt i avsnitt (ikke strofer) som er innbyrdes inkongruente når det gjelder versantall og slagrekke (antall trykksterke stavelser i et vers). Rapsodiske tekster får type-attributtverdien "rapsodisk":
<lb/><head>BALMINDER
<lb/>Et Livsfragment i Poesi og Prosa.</head>
<lg type="rapsodisk Wergelandstroké" an="no" met="bi 4|7|8" rhyme="r|R">
<div type="section">
<lb/><head>PROLOG:
<lb/>Til Stella!</head>
<lb/><l first="yes" rhyme="a" met="7">For din Fod jeg lægger ned</l>
<lb/><l rhyme="B" met="8">En Bouket af friske Blommer,</l>
<lb/><l rhyme="B" met="8">Skudte frem i sidste Sommer</l>
<lb/><l rhyme="a" met="7">Ifra Mindets Urtebeed;</l>
...
</div>
...
</lg>
Eksemplet er fra DHU.
Etter å ha oppgitt hva slags formdannelse den aktuelle teksten har, spesifiseres den nærmere angående sjanger, strofeform, versemål o.l.
type-attributtet plasseres først av attributtene innenfor <lg>. De andre attributtene (an="", realAn="", met="", realMet="", rhyme="", realRhyme="") ordnes alfabetisk.
kap-8.4.2: Oppdelte verslinjegrupper
Oppdelte verslinjegrupper, f.eks. strofer som strekker seg over flere replikker i et versdrama, kodes med part-attributter, på samme måte som oppdelte verslinjer. Her er et eksempel fra Sa:
<sp who="ANNA"><spOpener><speaker>Anna</speaker></spOpener> <lg type="strofisk strofegruppe folkevisevers" part="I" an="single" met="bi++ fri (8|9 7)2" rhyme="(x|X A)2"> <lg type="strofe" part="I" met="8 7 9 7" rhyme="x A X A"> <l first="yes" met="v-vv-v-v-" rhyme="x">«Og hør, liden Fugl paa Furrukvist!</l> <l met="v-vv-vv-v" rhyme="A">Du monne saa klageligt kvæde;» –</l></lg></lg></sp> <sp who="FRUEN"><spOpener><speaker>Fruen</speaker></spOpener> <p>Anne, Anne!</p></sp> <sp who="ANNA"><spOpener><speaker>Anne</speaker></spOpener> <lg type="strofegruppe" part="M"> <lg type="strofe" part="F"> <l met="v-vv-vv-v-v" rhyme="X">«Hvi kviddrer Du ikke i Fruerstue,</l> <l met="v-vv-vv-v" rhyme="A">Derinde er Gammen og Glæde!»</l></lg></lg></sp> <sp who="FRUEN"><spOpener><speaker>Fruen</speaker></spOpener> <p>Men saa svar dog; hvad er det Du der tager Dig fore?</p></sp> <sp who="ANNA"><spOpener><speaker>Anna</speaker></spOpener> <lg type="strofegruppe" part="M"> <lg type="strofe" part="I" an="single" met="bi++ fri (8 7)2" rhyme="(x A)2"> <l met="v-vv-vv-vv-" rhyme="x">«Og Spurven den graa er mit Sødskendebarn,</l> <l met="v-vv-vv-v" rhyme="A">Og Farbroer er Haren den hvide – –»</l></lg></lg></sp> <sp who="FRUEN"><spOpener><speaker>Fruen</speaker></spOpener> <p>Nei hun bli'er værre og værre.</p></sp> <sp who="ANNA"><spOpener><speaker>Anna</speaker></spOpener> <lg type="strofegruppe" part="F"> <lg type="strofe" part="F"> <l met="v-vv-v-vv-" rhyme="x">I Høienloftssal vil Ingen forstaa</l> <l met="v-vv-vvv-v" rhyme="A">De Viser jeg kviddrer under Lide.</l></lg></lg></sp>
kap-8.4.2.1: Ufullstendige strofer
I flere versdramaer gjentas deler av en vise flere ganger utover i teksten. Ufullstendige strofer kodes <lg part="Y"> og forsynes med metrikknote. Her eks. fra Gildet paa Solhoug/Gildet på Solhaug:
<lb/><sp who="GUDMUND"><spOpener><speaker>Gudmund</speaker> <lb/><stage>(synger)</stage>.</spOpener> <lb/><lg type="strofisk strofegruppe folkevisevers kjempevise" an="single" met="bi+ 9 9 8 8" rhyme="A A b b"> <div type="section"> <head>1.</head> <lg type="strofe"> <l met="v-vv-vv-vv-v" rend="indent2" rhyme="A">Jeg vandred' i Lien saa tung og saa ene,</l> <l met="v-vv-vv-vv-v" rend="indent2" rhyme="A">De Smaafugle kviddred' fra Busker og Grene;</l> <l met="v-vv-vv-vv-" rend="indent2" rhyme="b">Saa listeligt kviddred' de Sangere smaa:</l> <l met="v-vv-vv-vv-" rend="indent2" rhyme="b">Hør til, hvordan Kjærlighed monne opstaa!</l> </lg> </div> <div type="section"> <head>2.</head> <lg type="strofe"> <l met="v-vv-vv-vv-v" rend="indent2" rhyme="A">Den voxer som Egen i Aarene lange,</l> <l met="v-vv-vv-vv-v" rend="indent2" rhyme="A">Den næres ved Tanker og Sorger og Sange.</l> <l met="v-vv-vv-vv-" rend="indent2" rhyme="b">Den spirer saa let; i den flygtigste Stund</l> <l met="-vv-vv-v-" rend="indent2" rhyme="b">Fæster den Rødder i Hjertets Grund!</l></lg></div></lg> <stage>(Gaaer under Efterspillet op mod Baggrunden.)</stage></sp> <sp who="SIGNE"><spOpener><speaker>Signe</speaker> <stage>(betragter ham drømmende og gjentager for sig selv, idet hun lægger Haanden paa Hjertet)</stage>.</spOpener> <lg part="Y" type="strofisk folkevisevers kjempevise" an="var" met="bi+ 8 8" rhyme="b b"> <l met="v-vv-vv-vv-" rend="indent1" rhyme="b">Den spirer saa let; i den flygtigste Stund</l> <lb/><l met="-vv-vv-v-" rend="indent1" rhyme="b">Fæster den Rødder i Hjertets Grund!</l> </lg><note type="met">ufullstendig strofe</note></sp>
kap-8.4.2.2: Refreng
Ulike typer refrenger (innstev, etterstev osv.) kodes med typeattributtverdien "refreng" innenfor <l> eller <lg>, avhengig av om det strekker seg over en eller flere linjer. Princeton encyclopedia definerer "refreng" som «A line, lines or part of a line repeated verbatim at intervals throughout a poem, usually at regular intervals, and most often at the end of a strofe – a burden, chorus, or repetend (qq.v.)»
<lg rend="poem"> <lg type="strofisk strofegruppe folkevisevers kjempevise" an="single" met="bi++ (8 7)2" rhyme="(a B)2"> <div type="section"> <head>1</head> <lg type="strofe"> <l first="yes" met="-vv-v-v-" rhyme="a">Bjergkongen red sig under Ø,</l> <l type="refreng" met="v-vv-vvv-v" rhyme="B">(Saa klageligt rinde mine Dage)</l> <l met="-vv-vv-v-" rhyme="a">Vilde han fæste den væne Mø.</l> <l type="refreng" met="v-vv-vv-v" rhyme="B">(Ret aldrig Du kommer tilbage.)</l> </lg> </div> <div type="section"> <head>2</head> <lg type="strofe"> <l met="-vv-vv-v-" rhyme="a">Bjergkongen red til Herr Haakens Gaard,</l> <l type="refreng" met="v-vv-vvv-v" rhyme="B">(Saa klageligt rinde mine Dage)</l> <l met="vv-vv-vv-v- & vv-vv-v-vv-" rhyme="a">Liden Kirsten stod ude, slog ud sit Haar.</l> <l type="refreng" met="v-vv-vv-v" rhyme="B">(Ret aldrig Du kommer tilbage.)</l> </lg> </div> ... </lg> </lg>
Eksemplet er fra G1ht.
kap-8.5: Metrikk-noter
Noter som innholder spesifikk metrisk informasjon skilles ut med type-attributtet "met":
<lg type="strofe" rhyme="(A b)2">
<l rhyme="A">Er de Glimt fra Sjælens Dunkle,</l>
<l rhyme="b">Der igjennem Mulmet brød,</l>
<l rhyme="A">Og som Lynblink monne funkle</l>
<l rhyme="b">Kun til evig Glemsel født? –<note type="met">Urent rim.</note></l>
</lg>
Teksten er hentet fra diktet «Resignation». For oversiktens skyld er verskodinga forenklet.
kap-8.6: Notasjonssystem
Vårt notasjonssystem er laget på grunnlag av Jørgen Fafners verslære, slik den er beskrevet i Dansk Verskunst 1989-2000. Fafner anbefaler å inkludere opplysninger om versgang, versenes stavelsesantall, opptaktsforhold og rimskjema, samt navn på versemål, strofeform etc.
Den metriske notasjonen skal beskrive strukturen i den aktuelle Ibsen-teksten, ikke strukturen til versemålet teksten tilhører. Når Ibsen endrer på det faste rimskjemaet i ottave rimaen, er det altså rimskjemaet i Ibsens tekst, ikke i ottavens normalform, som gjengis.
kap-8.6.1: Spesialtegn
Disse spesialtegnene for metrisk og logisk notasjon brukes innenfor attributtene met="" og rhyme="".
- / – "verslinjegrense": v-v-vv-v-/v-v-vv-v
- // – "strofegrense"
- \ – replikkslutt ved delt verslinje
- | – "eller": rhyme="((a B)2 (c D)2) | ((x A)2 (b C)2)" (Her ser strofene ut enten på den ene eller den andre måten.)
- , – oppramsing: met="(bi+ reg (8 7)2 (v-v-vv-v-/v-v-vv-v)2), (bi (8 7)2)" (Her gjelder den første formelen for de fire første verslinjene og den neste for de fire siste verslinjene i strofen.)
- & (entitet for ampersand) – "og": met="(v-vv-vv-v) & (vv-v-vv-v)" (Verslinja kan skanderes på to måter.)
- - – trykksterk (betont, aksentuert) stavelse
- v – trykksvak (ubetont, uaksentuert) stavelse
kap-8.6.2: Rimkoding
kap-8.6.2.1: Rimnotasjon
Rimskjemaet oppgis som en verdi til attributtet rhyme="". Attributtet legges på høyest mulig nivå, og verdien arves til verselementer på underliggende nivåer. Rimene spesifiseres dessuten for hver verslinje, i <l>.
Rimnotasjonen følger dette systemet:
- Enstavet (monosyllabisk), betont rim (-) markeres med liten bokstav (a).
- Tostavet (bisyllabisk) rim med ubetont utgang (-v) markeres med stor bokstav (A).
- Trisyllabiske (-vv), tetrasyllabiske (-vvv) og pentasyllabiske (-vvvv) rim markeres med (samme) dobbeltbokstav (Aa).
- Hver rimsekvens har sin egen bokstavrekke som begynner med A|a. Det skal være mellomrom mellom de enkelte rimnotasjonene i sekvensen, siden noen av dem markeres med dobbeltbokstaver.
- X og x markerer nullrim. Ellers kan alle bokstavene i alfabetet, bortsett fra æ, ø og å, benyttes til rimmarkering.
- Rimnotasjonen r|R på toppnivå markerer at teksten er rimet (og inneholder både monosyllabiske og bisyllabiske rim), men at rimmønsteret varierer.
- Der rimskjemaet ligger fast, men utgangen varierer mellom betonet og ubetonet, noteres var a b a b, jf. Gjennomgående variasjon
- Ved svært lange rimsekvenser kan det være at bokstavene i alfabetet ikke er mange nok. Da begynner vi på alfabetet på nytt, men markerer bokstavene med anførselstegn, slik: a b a b ... a' b' a' b' ... a'' b'' a'' b'' ...
Rim regnes fra og med den siste betonte vokalen. Rimparet 'rubin'/'turbin' er altså et monosyllabisk (mannlig) helrim.
kap-8.6.2.1.1: Forkortelse
Dersom rimsekvenser gjentas, forkorter vi rimnotasjonen. Diktet «Resignation» har tre strofer med det samme rimmønsteret, A b A b. Notasjonen legges på høyeste <lg>-nivå, slik at den arves av enkeltstrofene, og forkortes slik: (A b)². (Det opphøyde totallet kodes med entiteten ².) Totallet viser at innholdet i parentesen skal dobles. Mellom totallet og resten av rimskjemaet legges det inn et mellomrom. Stavelsestallet i versene forkortes på samme måte som rimskjemaet.
kap-8.6.2.2: Rimsekvens
En rimsekvens er en enhet som avgrenses ut fra det hierarkiske systemet den inngår i. Dette er ulikt for versdramaer og for dikt.
kap-8.6.2.2.1: Versdramaer
I versdramaer kan rimsekvensene fort bli svært lange, noe som er upraktisk å arbeide med (dersom det oppdages feil i rimanalysen, blir det en stor jobb å rette opp hele rimsekvensen). Rimsekvensene bør derfor avsluttes ved opphold av ulike slag i teksten (se listen nedenfor). Det er ikke nødvendig å avslutte <lg> når rimsekvensen avsluttes; <lg>-kodingen bør i større grad følge strukturen i teksten.
Grensemarkeringer for rimsekvenser innenfor versdramaer kan være:
- ulike verstyper, f.eks. versreplikker kontra strofer
- endring i versform, strofeform eller sjanger
- omkringliggende prosareplikker
- sceneskifter
- aktskifter
- nye personkonstellasjoner
- stedsskifter
I stikiske versdramaer bruker vi ikke samme rimbokstav for gjentatte rimpar med lang avstand mellom (over 2 sider), dersom rimene ikke virker intendert.
kap-8.6.2.2.2: Dikt
I diktene er tekstlige enheter (f.eks. strofer) kodet med <lg>-er, og rimskjemaene strekker seg over én eller flere slike. I sonettene f.eks. går rimskjemaet over fire strofer. Rimskjemaet til første sonett i "Vaagner Skandinaver" vil se slik ut: (A b)2//(C d)2//(E f G//)2. Strofegrensene markeres med doble skillestreker.
Dersom rimene ikke fortsetter over i påfølgende strofer, oppfattes og kodes én strofe som én rimsekvens - dvs. at rimskjemaet begynner på nytt på A|a for hver ny strofe.
For rapsodiske, og spesielt stikiske, tekster kan det være vanskelig å finne avslutningspunkter for rimsekvensene. Dersom hele diktet står i ett avsnitt, eller rimene tydelig krysser avsnittsgrensene, må vi la rimsekvensen omslutte hele diktet.
kap-8.6.2.3: Urene rim
Uttale, ikke skrivemåte, brukes for å avgjøre om et rim er rent eller urent. (Fan)tom/tom regnes altså som urent, mens vilde/spille regnes som rent. Urene (eller identiske) rim innenfor en rimsekvens kodes som vanlige rim, dvs. med samme rimbokstav i rhyme="". Vi legger til en <note type="met"> om urent el. identisk rim. Noten føres bare opp ved siste rim i rimparet.
kap-8.6.2.4: Variasjon og avvik
Generelt gjelder det at alle tekster skal ha en rimformel på øverste nivå, som viser hovedmønsteret. Denne kan være normalisert. Avvik fra mønsteret spesifiseres på lavere nivåer.
kap-8.6.2.4.1: Gjennomgående variasjon
Noen dikt har et fast rimskjema, men monosyllabiske og bisyllabiske rim veksler innenfor dette (f.eks. A b b A vs. a B B a). En slik gjennomgående variasjon markeres på øverste nivå ved at 'var' settes foran rimnotasjonen: <lg rhyme="var a b b a">. Rimnotasjonen skrives da med små bokstaver. På lavere nivåer spesifiseres de faktiske rimene.
Rimnotasjonen "r|R" settes på toppnivå for tekster som har rim, men ikke noe fastlagt rimskjema (gjelder spesielt stikiske og rapsodiske tekster). På lavere nivåer spesifiseres rimene på vanlig vis.
kap-8.6.2.4.2: Avvik
Tilfeldige eller enkeltstående avvik innenfor et ellers fast rimskjema markeres med realRhyme="". Verdiene i realRhyme="" formuleres på samme måte som i rhyme="". På eventuelt lavere nivåer kodes de faktiske rimene med rhyme=""-attributtet, siden avviket er spesifisert ovenfor. Her er et tenkt eksempel:
<lg type="strofegruppe" rhyme="(a b)2 c d d c"> <lg type="strofe">...</lg> <lg type="strofe" realRhyme="(a b)2 c x x c"> <l rhyme="a">...</l> <l rhyme="b">...</l> <l rhyme="a">...</l> <l rhyme="b">...</l> <l rhyme="c">...</l> <l rhyme="x">...</l> <l rhyme="x">...</l> <l rhyme="c">...</l></lg> <lg type="strofe">...</lg> </lg>
kap-8.6.2.5: Nullrim
Vi koder nullrim, uansett om de opptrer sporadisk eller i lengre partier. Betont utgang (f.eks. «rød») kodes med rhyme-attributtet "x", ubetont utgang (f.eks. «røde») med rhyme-attributtet "X".
kap-8.6.3: Metrisk mønster
I den metriske notasjonen inkluderer vi informasjon om versgang, versenes stavelsesantall og stavelsesfordeling. Det metriske mønsteret kodes innenfor attributtet met="". Dette legges på høyest mulig nivå, innenfor <lg>. Verdien arves av verselementer på underordnede nivåer.
kap-8.6.3.1: Versgang
Versgangen noteres med følgende forkortelsene "bi" (tostavet taktledd) eller "tri" (trestavet taktledd). Den aktuelle forkortelsen innsettes som attributtverdi til met="".
kap-8.6.3.1.1: Ren og blandet versgang
I rene versganger er stavelsestallet i taktleddene konstant, mens det i blandede versganger varierer. Substitusjon har vi når taktledd innenfor en bisyllabisk (tostavet) rekke skiftes ut med trisyllaber (trestavelser). Dette markeres med et plusstegn etter versgangen: "bi+". Teoretisk sett kunne vi like gjerne skrevet tri-, men siden det er mye vanligere innenfor vershistorien med bisyllabiske enn med trisyllabiske rekker, går vi ut fra de bisyllabiske. Betegnelsen tri- brukes bare der trisyllablene er klart i overvekt. Hypersubstitusjon er utskifting med større ledd enn trisyllaber i en bisyllabisk rekke. Dette markeres med doble plusstegn: "bi++". Reduksjon vil si at enkelte taktledd i en bisyllabisk rekke skiftes ut med mindre ledd, dvs. med monosyllaber. Dette markeres med minustegn: "bi-". Tekster som inneholder både substitusjon og reduksjon kodes med "bi+-".
Variasjonen av antall stavelser i taktleddene kan følge et fast mønster (fast blandet versgang), eller den kan være tilsynelatende vilkårlig (fritt blandet versgang). Fast blandet versgang noteres i met-attributtet som "bi+ reg" (reg = regular/regulær); fritt blandet versgang noteres "bi+", "bi++" eller "bi+-" (det er da underforstått at versgangen er fri).
kap-8.6.3.2: Versenes stavelsesantall
En stavelse defineres som den minste målbare enhet innenfor poetisk lyd (Preminger 1975). Ordet "blege" består f.eks. av to stavelser, 'ble' + 'ge'.
Antall stavelser i hvert vers innsettes som attributtverdi til met="" etter versgangsnoteringen. Første strofe fra «Til Stjernen» kan brukes som eksempel:
<lg met="bi (7 6)2"> <lb/><l>Blege Stjerne! send et Vink</l> <lb/><l>Fra det Evighøie! ‐</l> <lb/><l>Lys med venligt Flammeblink</l> <lb/><l>Klart for Sjælens Øie! ‐ ‐</l> </lg>
(Se her for mer informasjon om forkortelse av den metriske formelen.)
For tekster med varierende opptaktsforhold telles opptaktene med i stavelsestallet bare dersom teksten regnes som jambisk.
Måten teksten er bygd opp på – om den har strofisk, stikisk eller rapsodisk formdannelse – har betydning for oppstillinga av versenes stavelsesantall.
kap-8.6.3.2.1: Strofiske tekster
Strofiske tekster er inndelt i strofer eller strofegrupper. I slike tekster oppgis stavelsesantallet for hvert vers i strofene, og noteringa legges på høyest mulig nivå. Verdien i met="" arves så til underliggende nivåer, dvs. fra strofegruppa til de enkelte strofene og fra strofe til enkeltvers.
kap-8.6.3.2.2: Stikiske tekster
Stikiske tekster har ingen strofeinndeling, men består av (parvis) ensartede vers. Siden antallet stavelser i versene er konstant, noteres stavelsesantallet på øverste nivå, slik at det arves for underliggende vers. For blankverset vil det se slik ut: met="bi 10|11" (opptakt er ikke notert her).
kap-8.6.3.2.3: Rapsodiske tekster
Rapsodiske tekster er inndelt i innbyrdes inkongruente avsnitt, og lengden på versene varierer gjerne. For slike tekster oppgir vi på øverste nivå de stavelsestallene som forekommer i teksten, f.eks. slik <lg met="3|4|7|8">. De spesifikke stavelsestallene noteres på verslinjenivå.
kap-8.6.3.2.4: Forkortelse
Vi forkorter den metriske formelen på samme måte som vi forkorter rimskjemaet. Den fulle formelen til første sonett i «Vaagner Skandinaver» er: "bi 11 10 11 10 // 11 10 11 10 // 11 10 11 // 11 10 11", og rimskjemaet er: A b A b // C d C d // E f G // E f G. Den forkortede formelen vil da se slik ut: "bi (11 10)2 // (11 10)2 // (11 10 11 //)2". Totallet viser at innholdet i parentesen skal dobles. I visningsteksten blir totallet konvertert til entiteten ² (opphøyd totall), jf. Vasking av filer med metrikk-koding.
kap-8.6.3.3: Fordeling av trykksvake og trykksterke stavelser
For tekster med blandet versgang må fordelinga av trykksvake og trykksterke stavelser spesifiseres. Trykksvake stavelser kodes med bokstaven v (som konverteres til entiteten &bue;, jf. Vasking av filer med metrikk-koding), trykksterke med bindestrek (-). Grensen mellom taktledd (som strekker seg f.o.m. én trykksterk stavelse og fram til neste trykksterke stavelse) markeres ikke. Grensen mellom verslinjer markeres med én skråstrek og grensen mellom strofer med dobbel skråstrek. Informasjon om stavelsesfordeling legges etter noteringa av stavelsesantall i met="".
For tekster med fast blandet versgang (dvs. tekster der taktleddene er ulike, men stilles sammen i faste mønstre) spesifiserer vi trykkfordelinga for hver sekvens (f.eks. en strofe) som blir repetert. Noteringa legges som vanlig på høyest mulig nivå. Innenfor fritt blandede versganger (der taktleddene er ulike, og de ikke stilles sammen i noe fast mønster) spesifiserer vi fordelinga av trykksvake og trykksterke stavelser for hver enkelt verslinje.
Enkelte ganger kan det være vanskelig å avgjøre hvor trykket skal ligge fordi verslinja kan skanderes på flere måter. I slike tilfeller velger vi den lesemåten som passer inn i det metriske hovedmønsteret. Dersom flere lesemåter passer inn i dette mønsteret, oppgis de som føles riktige/naturlige på verslinjenivå. Lesemåtene skilles fra hverandre med spesialtegnet & ("og").
kap-8.6.3.3.1: Typografisk trykkmarkering
Typografisk markert trykk skal skilles fra metrisk trykk. Kursiv, understreking etc. kodes med <emph>, mens metriske trykkforhold angis i met=""-attributtet. I «Terje Vigen» finnes flere eksempler på trykkløs høytone (i kursiv). Slike metrisk trykksvake stavelser tillegges vekt i skanderingen ved å høyne stemmeleiet, men de noteres altså ikke i den metriske kodinga.
<lg type="strofe"> <lb/><l met="v-v-vv-vv-">Din rige lady er lys som en vår,</l> <lb/><l met="vv-vv-v-">hendes hånd er som silke fin, ‐</l> <lb/><l met="v-v-vv-v-"><emph>min</emph> hustrus hånd den var grov og hård,</l> <lb/><l met="vv-vv-vv-">men hun var nu alligevel min.</l> <lb/><l met="v-v-vv-v-"><emph>Dit</emph> barn har guldhår og øjne blå,</l> <lb/><l met="vv-vv-v-">som en liden Vorherres gæst;</l> <lb/><l met="v-vv-vv-v-"><emph>min</emph> datter var intet at agte på,</l> <lb/><l met="v-v-vv-vv-">hun var, Gud bedre det, mager og grå,</l> <lb/><l met="v-vv-v-">som fattigfolks børn er flest.</l> </lg>
kap-8.6.3.4: Normalisering, avvik, variasjon
kap-8.6.3.4.1: Normalisering
For tekster med blandet versgang, der stavelsesantallet i versene varierer, kan det være vanskelig å sette opp en samlende metrisk formel. I slike tilfeller beregnes versenes stavelsesantall ut fra det normale for versgangen. For tostavede taktledd ("bi") multipliseres antall trykksterke stavelser med to, for trestavede taktledd ("tri") multipliseres antall trykksterke stavelser med tre osv. Siste taktledd normaliseres ikke. Opptakter inkluderes i det samlede stavelsesantallet dersom teksten er jambisk; ellers inkluderes de ikke. Tegnene for substitusjon (+) og reduksjon (-) viser at stavelsesantallet varierer, og at formelen følgelig er normalisert.
Diktet «Terje Vigen» kan tjene som eksempel på en tekst med (fritt) blandet versgang. Her er første strofe:
<lg type="strofegruppe" met="bi+ (8 6)2 8 6 8 8 6" rhyme="(a b)2 c d c c d"> <lg type="strofe"> <lb/><l rhyme="a" met="v-vv-vv-v-">Der bode en underlig gråsprængt en</l> <lb/><l rhyme="b" met="vv-vv-v-">på den yderste, nøgne ø; ‐</l> <lb/><l rhyme="a" met="v-vv-v-vv-">han gjorde visst intet menneske mén</l> <lb/><l rhyme="b" met="-vv-vv-">hverken på land eller sjø;</l> <lb/><l rhyme="c" met="v-v-vv-v-">dog stundom gnistred hans øjne stygt, ‐</l> <lb/><l rhyme="d" met="-vv-v-">helst mod uroligt vejr, ‐</l> <lb/><l rhyme="c" met="v-vv-vv-v-">og da mente folk, at han var forrykt,</l> <lb/><l rhyme="c" met="v-vv-v-v-">og da var der få, som uden frygt</l> <lb/><l rhyme="d" met="v-v-v-">kom Terje Vigen nær.</l> </lg> ... </lg>
Fordelinga av trykksvake og trykksterke stavelser er spesifisert for hver enkelt verslinje. Ut fra disse og ut fra framgangsmåten som er beskrevet ovenfor, kan vi utlede den normaliserte formelen "bi+ (8 6)2 8 6 8 8 6". Denne gjelder for alle strofene og kan derfor legges på et overordnet nivå.
kap-8.6.3.4.2: Avvik
Avvik innenfor det metriske mønsteret kodes med realMet="". Dette attributtet legges innenfor <lg> eller <l>, på et lavere nivå enn notasjonen av hovedmønsteret. realMet="" overkjører da hovednotasjonen innenfor det området det omslutter. Verdiene i realMet="" formuleres på samme måte som i met="". Her er et tenkt eksempel:
<lg type="strofegruppe" met="bi (8 7)2"> <lg type="strofe">...</lg> <lg type="strofe" realMet="bi 8 7 8 5">...</lg> <lg type="strofe">...</lg> </lg>
kap-8.6.3.4.3: Variasjon
I diktet «På vidderne» skifter versemålet to ganger, og de tre ulike versemålene opptrer på samme nivå innenfor det tekstlige hierarkiet. I slike tilfeller har vi å gjøre med variasjoner i, ikke avvik fra, det metriske mønsteret. Slike variasjoner blir kodet innenfor met=""-attributter:
<lg type="strofegruppe" met="bi (8 6)2 8 6 8 8 6" rhyme="(a b)2 c d c c d"> <lg type="strofe">...</lg> ...</lg> <lg type="strofegruppe" met="bi (8 8)2" rhyme="(A B)2"> <lg type="strofe">...</lg> ...</lg> <lg type="strofegruppe" met="bi+ 8 7 8 8 7" rhyme="a B a a B"> <lg type="strofe">...</lg> ...</lg>
Som vanlig arver verselementer på underliggende nivåer de metriske egenskapene. På øverste <lg>-nivå listes alle versemålene opp i nummerert rekkefølge, jf. Tekster som inneholder flere metre.
kap-8.6.4: Opptaktsforhold
En opptakt er en trykksvak stavelse før den første trykksterke stavelsen i et vers. Et vers kan enten ha ingen, enkel eller dobbel opptakt. I første strofe av «Terje Vigen» er alle variantene representert:
<lg type="strofe"> <lb/><l rhyme="a" met="v-vv-vv-v-">Der bode en underlig gråsprængt en</l> <lb/><l rhyme="b" met="vv-vv-v-">på den yderste, nøgne ø; ‐</l> <lb/><l rhyme="a" met="v-vv-v-vv-">han gjorde visst intet menneske mén</l> <lb/><l rhyme="b" met="-vv-vv-">hverken på land eller sjø;</l> <lb/><l rhyme="c" met="v-v-vv-v-">dog stundom gnistred hans øjne stygt, ‐</l> <lb/><l rhyme="d" met="-vv-v-">helst mod uroligt vejr, ‐</l> <lb/><l rhyme="c" met="v-vv-vv-v-">og da mente folk, at han var forrykt,</l> <lb/><l rhyme="c" met="v-vv-v-v-">og da var der få, som uden frygt</l> <lb/><l rhyme="d" met="v-v-v-">kom Terje Vigen nær.</l> </lg>
Andre vers har dobbel opptakt, fjerde og sjette vers har ingen opptakt, og de øvrige versene har enkel opptakt.
Vi har innført et eget attributt for opptakt: an="" (for "anacrusis"). Til attributtet hører verdiene "single" (enkel), "double" (dobbel) og "no" (ingen). Opptaktene vises som enkel eller dobbel apostrof foran stavelsestallet i visningstekstene.
Når vi inkluderer opptaktsforholdene, blir den fulle metriske formelen til «Terje Vigen» seende slik ut: <lg type="strofisk strofegruppe Ibsenstrofe" an="single" met="bi+ (8 6)2 8 6 8 8 6" rhyme="(a b)2 c d c c d">. I visningsteksten blir opptaktene satt inn som apostrofer: "bi+ ('8 '6)2 '8 '6 '8 '8 '6", jf. Vasking av filer med metrikk-koding.
kap-8.6.4.1: Variasjon og avvik
Tekster med opptakt betegnes gjerne jambiske (dette er de vanligste i det nordiske språkområdet), tekster uten opptakt trokeiske og tekster med dobbel opptakt jambisk anapestiske. De jambiske tekstene (spesielt de med fritt blandet versgang, som «Terje Vigen», folkevisene m.fl.) tillater store variasjoner i opptaktsforholdene. Opptaktsnotasjonen betegner potensiell opptakt snarere enn faktisk. De opptaktsfrie verslinjene i teksteksemplet ovenfor skal altså ikke avvikskodes. De trokeiske tekstene er strengere regulert; her er det mindre vanlig med enkeltlinjer med opptakt.
For å markere avvik i opptaktsforholdene benyttes attributtet realAn="". Attributtverdiene "single" (sjeldnere "double") og "no" brukes for å spesifisere avviket. Her er et tenkt tilfelle:
<lg an="no"> <l>...</l> <l realAn="single">...</l> <l>...</l> ... </lg>
kap-8.6.4.2: Visning av faktisk opptakt
Opptaktsforholdene går vanligvis fram av den overordnede formelen eller av stavelsesfordelinga i met=""-attributtet. Der dette ikke er tilstrekkelig, koder vi opptaktsrealisasjonen på verslinjenivå. I dette eksemplet gjentas mønsteret for hver strofe:
<head>HIL SANGEN!</head> <lg type="strofisk strofegruppe Hildebrandstrofe" an="single" met="bi (7 6)2 (7 6)2" rhyme="(A b)2 (C d)2"> <lg type="strofe"> <l first="yes" an="single" rhyme="A">Længst taug de norske Tunger,</l> <l an="single" rhyme="b">Lig Fuglen stur og sky;</l> <l an="single" rhyme="A">Nu frigjort Sangen runger</l> <l an="single" rhyme="b">Fra Fjord og Bygd og By.</l> <l an="single" rhyme="C">Langs Led i lyse Sommer</l> <l an="single" rhyme="d">Gaar Sangens Sønners Lag, –</l> <l an="single" rhyme="C">Foran som Mærke flommer</l> <l an="no" rhyme="d">Fagre Kvinders Flag.</l></lg> ... </lg>
Eksempel fra DHU.
kap-8.6.5: Spesialtilfeller
kap-8.6.5.1: Trisyllabiske rim i bisyllabisk versgang
Enkelte versemål, f.eks. femfotsjamben, kan ha trisyllabiske rim selv om versgangen ellers er strengt bisyllabisk. Dette er helt vanlig og regnes ikke som avvikende substitusjon. Kodeeksempel:
<lg type="stikisk femfotsjambe" an="single" met="bi 10|11" rhyme="r|R|Rr"> ... <sp who="STYVER"><spOpener><speaker rend="smallCaps">styver</speaker></spOpener> <l rhyme="K">Nu er jeg jo officielt <emph>forlovet</emph>;</l> <l rhyme="L">Det er jo mere end <emph>forelsket</emph>, veed jeg!</l></sp> <sp who="FALK"><spOpener><speaker rend="smallCaps"><pb ed="hu"/>falk</speaker></spOpener> <l rhyme="L">Ret saa, min gamle Ven, jeg holder med Dig!</l> <l rhyme="Mm">Du avanceret har, bestaat det Sværeste:</l> <l rhyme="Mm">Forfremmelsen fra Elsker og til Kjæreste.</l></sp> ... </lg>
kap-8.6.5.2: Tekster som inneholder flere metre
Noen tekster inneholder flere forskjellige metre. Det vanligste er at teksten består av større grupper med ulikt meter, som f.eks. «På vidderne». Øverste nivå i diktet kodes slik:
<lg type="strofisk 1: Ibsenstrofe, 2: -, 3: -" an="1: single, 2: no, 3: single" met="1: bi (8 6)2 8 6 8 8 6, 2: bi (8 8)2, 3: bi+ 8 7 8 8 7" rhyme="1: (a b)2 c d c c d, 2: (A B)2, 3: a B a a B">
Andre tekster kan ha gjennomgående skifte av versemål midt inne i en strofe. I begge tilfellene legger vi formlene for de ulike metrene på øverste nivå, nummererer dem og skiller dem fra hverandre med et komma. Dette kodeeksemplet er hentet fra diktet «Sang for Universitetet ved Halvhundredeaarsfesten paa Klingenberg».
<lg type="strofisk strofegruppe" an="1: single, 2: N" met="1: bi 11 11 (7 6)2, 2: bi+ reg 8 8 3 -v-vv-v-v/-v-vv-v-v/-v-" rhyme="1: A A (X b)2, 2: C C d"> <lg type="strofe"> <lg an="single" met="bi 11 11 (7 6)2" rhyme="A A (X b)2"> <l rhyme="A">Der drog en disig Dæmring over Fjeldet;</l> <l rhyme="A">Den bar det Bud: Snart Mørkets Magt er fældet.</l> <l rhyme="X">Men Folket saa idrømme</l> <l rhyme="b">Et fjernt Morganasyn,</l> <l rhyme="X">Et Slot med Spir og Tinde</l> <l rhyme="b">Højt over Aasens Bryn.</l></lg> <lg an="no" met="bi+ reg 8 8 3 -v-vv-v-v/-v-vv-v-v/-v-" rhyme="C C d"> <l rhyme="C">Over Hav maa dog Snekken fare,</l> <l rhyme="C">For at naa til det solskinsklare</l> <l rhyme="d">Tankens Slot.</l></lg> </lg> ... </lg>
«Tankens Slot» går igjen som sistelinje i alle strofene; derfor er det markert som rim. (Rimsekvensen omslutter hele diktet.)
kap-8.6.5.3: Tekster som ligger midt mellom to metre
Noen tekster kan faktisk leses forskjellig, slik at flere metre er mulige. I slike tilfeller oppgir vi begge mulighetene. «Byggeplaner» er et slikt dikt:
<head>BYGGEPLANER.</head> <lg type="strofisk strofegruppe 1: Nibelungenstrofe langvers & 2: fireslagsrekke" an="single" met="1: bi- 14 14 14 14 & 2: bi++ 8 8 8 8" rhyme="a a b b"> <lg type="strofe"> <l met="1: v--v-v-v--v- & 2: v-vv-vvv-vv-">Jeg husker saa grant, som om idag det var hændt,</l> <l met="1: v-v-v-vv-v-v- & 2: v-vvv-vv-vvv-">Dengang jeg saa i Bladet mit første Digt paa Prent;</l> <l met="1: v-v-v-v-v--v- & 2: v-vvv-vvv-vv-">Der sad jeg i mit Kammer og med dampende Drag</l> <l met="1: v-v-v-vv-v-v- & 2: v-vvv-vv-vvv-">Jeg røgede min Pibe i saligt Selvbehag.</l></lg> </lg>
kap-8.6.5.4: Metrisk koding av strøkne verslinjer i manuskripter
Innenfor stikiske tekster, som replikktekst i versdramaer, inkluderes ikke strøkne verslinjer i rimsekvensene. Rimene markeres bare generelt, med r eller R. Dersom en hel strofe i en innlagt sang etc. er strøket kan rimsekvens oppgis (f.eks. a b a b), fordi denne ikke vil forstyrre de øvrige rimsekvensene i stykket. Det kan altså avgjøres fra gang til gang om det er fornuftig å legge inn rimsekvenser i strøket tekst (ofte kan det jo være feil i metrikken eller ufullstendige versformer innenfor strøket tekst).
kap-8.7: Produksjonskoding – <lg rend="poem">
kap-8.7.1: Diktoppsett
Selvstendige dikt/sanger i dramaer skal ha eget diktoppsett i hovedtekstene. Kriteriet for at et dikt eller en sang skal ha diktoppsett er at det er i strofisk form og har selvstendig innhold i forhold til dramaets innhold, dvs. at «diktfunksjonen» er sterkere enn «replikkfunksjonen». Alle tvilstilfeller tas opp med den andre verskoderen, samt med filologene som arbeider med det aktuelle dramaet.
Diktoppsett kodes med en egen <lg rend="poem"> på et så overordnet nivå som mulig. Koden <lg rend="poem"> tilhører altså produksjonskodinga, ikke verskodinga. Koden betyr 'diktoppsett', ikke 'dikt'. Derfor kan den legges rundt f.eks. ufullstendige strofer innenfor en replikk. Hvis diktet innleder eller utgjør en hel replikk, skal også replikkinnehaveren følge diktoppsettet og <lg rend="poem"> legges da rundt hele <sp>. Eventuelle sceneanvisninger mellom strofer skal også ha diktoppsett og inngå i <lg rend="poem">.
Dikt/sanger som står innenfor anførselstegn skal settes som alminnelige (stikiske) verslinjer, dvs. de skal ikke ha diktoppsett, og kodes dermed ikke spesielt.
kap-8.7.2: Innrykkede verslinjer
Gjennomgående innrykk av frittstående sanger/dikt kodes ikke. Det er bare verslinjer som skal ha ekstra innrykk i forhold til omliggende verslinjer som innrykkskodes, typisk gjelder dette for korte verslinjer. Det kodes inntil to innrykksgrader: <l rend="indent1"> og <l rend="indent2">. For hovedtekster kan oppsettet justeres noe, f.eks. slik at to innrykksgrader slås sammen til ett. Det avgjøres fra gang til gang hvilke innrykk som skal beholdes.
Innrykkede verslinjer i stikiske versreplikker, der innrykket fungerer som innholdsbasert avsnittsmarkering, kodes med <l rend="indent">.
kap-8.8: Vasking av filer med metrikk-koding
Metrikk-kodingen er utformet slik at filene fortsatt skal være lesevennlige. Når filene nærmer seg ferdigstilling, eller før det skal lages visning, «vaskes» filene med perl-script. I vaskeprosedyren settes det inn opptaktsnotasjon (apostrof foran tallene i stavelsesrekken), fordoblingstegn vises som opphøyd (to)tall og tegn for trykksvak stavelse gjøres om til en entitet (&bue;). Her er et eksempel på kodet tekst (igjen første strofe av Terje Vigen) før og etter vasking.
FØR VASKING:
<lg type="strofisk strofegruppe Ibsenstrofe" an="single" met="bi+ (8 6)2 8 6 8 8 6" rhyme="(a b)2 c d c c d"><lg type="strofe">
<l first="yes" rend="indent1" met="v-vv-vv-v-" rhyme="a">Der bode en underlig gråsprængt en</l>
<l met="vv-vv-v-" rhyme="b">på den yderste, nøgne ø; –</l>
<l met="v-vv-v-vv-" rhyme="a">han gjorde visst intet menneske mn</l>
<l met="-vv-vv-" rhyme="b">hverken på land eller sjø;</l>
<l met="v-v-vv-v-" rhyme="c">dog stundom gnistred hans øjne stygt, –</l>
<l met="-vv-v-" rhyme="d">helst mod uroligt vejr, –</l>
<l met="vv-v-vv-v- & v-vv-vv-v- & vv-v-v-vv-" rhyme="c">og da mente folk, at han var forrykt,</l>
<l met="v-vv-v-v- & vv-v-v-v-" rhyme="c">og da var der få, som uden frygt</l>
<l met="v-v-v-" rhyme="d">kom Terje Vigen nær.</l></lg>
ETTER VASKING:
<lg type="strofisk strofegruppe Ibsenstrofe" an="single" met="bi+ ('8 '6)² '8 '6 '8 '8 '6" rhyme="(a b)² c d c c d"><lg type="strofe">
<l first="yes" rend="indent1" met="&bue;-&bue;&bue;-&bue;&bue;-&bue;-" rhyme="a">Der bode en underlig gråsprængt en</l>
<l met="&bue;&bue;-&bue;&bue;-&bue;-" rhyme="b">på den yderste, nøgne ø; –</l>
<l met="&bue;-&bue;&bue;-&bue;-&bue;&bue;-" rhyme="a">han gjorde visst intet menneske mn</l>
<l met="-&bue;&bue;-&bue;&bue;-" rhyme="b">hverken på land eller sjø;</l>
<l met="&bue;-&bue;-&bue;&bue;-&bue;-" rhyme="c">dog stundom gnistred hans øjne stygt, –</l>
<l met="-&bue;&bue;-&bue;-" rhyme="d">helst mod uroligt vejr, –</l>
<l met="&bue;&bue;-&bue;-&bue;&bue;-&bue;- & &bue;-&bue;&bue;-&bue;&bue;-&bue;- & &bue;&bue;-&bue;-&bue;-&bue;&bue;-" rhyme="c">og da mente folk, at han var forrykt,</l>
<l met="&bue;-&bue;&bue;-&bue;-&bue;- & &bue;&bue;-&bue;-&bue;-&bue;-" rhyme="c">og da var der få, som uden frygt</l>
<l met="&bue;-&bue;-&bue;-" rhyme="d">kom Terje Vigen nær.</l></lg>
VISNING (her med skanderingen plassert etter verslinjene):
Versform: strofisk strofegruppe Ibsenstrofe
Metrisk hovedformel: bi+ ('8 '6)² '8 '6 '8 '8 '6
Rimskjema: (a b)² c d c c d
a Der bo’de en underlig graasprængt En ∪-∪∪-∪∪-∪-
b Paa den yderste, nøgne Ø; - ∪∪-∪∪-∪-
a Han gjorde vist intet Menneske Meen ∪-∪∪-∪-∪∪-
b Hverken paa Land eller Sjø; -∪∪-∪∪-
c Dog stundom gnistred hans Øjne stygt, - ∪-∪-∪∪-∪-
d Helst mod uroligt Vejr, - -∪∪-∪-
c Og da mente Folk, at han var forrykt, ∪∪-∪-∪∪-∪-
& ∪-∪∪-∪∪-∪-
& ∪∪-∪-∪-∪∪-
c Og da var der Faa, som uden Frygt ∪-∪∪-∪-∪-
& ∪∪-∪-∪-∪-
d Kom Terje Vigen nær. ∪-∪-∪-
Det er altså kodingen etter vasking som er den endelige.
kap-8.9: Litteraturliste
I dette kapitlet henvises det til en del metrisk litteratur. Her er en liten litteraturliste:
- Fafner, Jørgen 1989–2000. Dansk verskunst.København, Reitzel. 2 b. i 3
-
- 1. Digt og form : klassisk og moderne verslære. 1989, 254 s.
- 2. Dansk vershistorie. 1994–2000. 2 b.
- 2:1. Fra kunstpoesi til lyrisk frigørelse. 1994. 375 s.
- 2:2. Fra romantik til modernisme. 2000. 526 s.
- Preminger, Alex & Brogan, T.V.F. (ed.) 1993. The new Princeton encyclopedia of poetry and poetics. Princeton, New Jersey, Princeton University Press. 1383 s.
kap-9: Detaljkoding
kap-9.1: Paginering – <pb/>
<pb/> er et tomt element, og det inneholder vår fortløpende markering av sideskift fra første side til siste. Den faktiske tellingen av sider kan dermed gjøres automatisk på bakgrunn av <pb/>-elementene.
I tekstvitner som ikke begynner med side 1 (FU, HU o.l.) legges første sidetall inn i et n=""-attributt i første <pb/>-element (<pb n=""/>). Dersom tekstvitnet ikke har løpende nummerering (f.eks. i føljetonger, fragmenter etc.), skal alle n-attributter fylles ut. Unummererte sider settes i skarpe klammer (merk at bare tall skal stå innenfor klammer, eks. "1r", "1v").
For manuskripter teller vi recto- og verso-sider: 1r, 1v, 2r, 2v osv.
Generelt er dette retningslinjene våre for attributtverdier i n i <pb/>:
Vi følger det som faktisk finnes i manuskriptet. Er det paginert, bruker vi sidetallene. Er det foliert, bruker vi bladtallene med tilføyd r eller v, 1r, 1v osv. Er det bare delvis paginert/foliert, bruker vi det det er mest av og supplerer i samme system med tall i skarpe klammer, 1/1r. Er det hverken foliert eller paginert, bruker vi foliotall (bladtall) i
skarpe klammer, med tilføyd r eller v, 1r, 1v osv. Bokstavene 'r' og 'v' skal stå utenfor de skarpe klammene fordi de er begreper på samme måte som 's.' og 'bl.' Mye av varia-materialet er småting på en eller to sider og for disse passer nok brevsystemet med 1, 2 osv best, og siden en del varia er tett knyttet til brev er det fornuftig også av den grunn med samme nummereringssystem. Dette kan imidlertid blir rart for de større tingene som evt finnes i ms, som artikler og taler. I så fall vil bladtall med r og v være det fornuftige. Når manuskriptet består av nummererte legg (vanlig i dramamaterialet)
uten ytterligere paginering/foliering, bruker Tone kombinasjonen: legg 2, bl. 2r osv. - dvs. hun teller på nytt i hvert legg. Vi gjør det samme som Tone.
Pagineringen plasseres generelt sett så langt som mulig utenfor strukturelementer av typen <l>, <p>, <sp>, <div> etc., men aldri utenfor<text> (dvs. direkte i <group> i <text><group><text>-koding) eller utenfor <front>, <body> og <back>.
Den faktiske sidenummereringen skal transkriberes og kodes, se «Nummerering av ark/legg, blad og sider».
kap-9.2: Kolonnenummerering – <cb/>
<cb/> er et tomt element, og det inneholder vår fortløpende markering av kolonneskift. Den faktiske tellingen av kolonner kan dermed gjøres automatisk på bakgrunn av <cb/>-elementene.
I tekstvitner som ikke begynner med kolonne 1 legges første kolonnetall inn i et n=""-attributt i første <cb/>-element (<cb n=""/>). Dersom tekstvitnet ikke har løpende nummerering (f.eks. i føljetonger, fragmenter etc.), skal alle n-attributter fylles ut. Unummererte kolonner settes i skarpe klammer (merk at bare tall skal stå innenfor klammer, eks. "sp. 1".
<cb/> skal også inneholde place=""-attributt som viser til kolonnens plassering på siden. For gyldige verdier i place="", se «Attributtverdilisten».
<cb/> plasseres som <pb/> så langt som mulig utenfor strukturelementer av typen <l>, <p>, <sp>, <div> etc..
Den faktiske kolonnenummereringen skal transkriberes og kodes, se «Nummerering av ark/legg, blad og sider».
<fw>-elementet brukes til transkribering av leggnummerering, bladfoliering og paginering i håndskrifter, samt arksignaturer, kolonnenummerering og paginering i trykte tekstvitner. All tekst skal tas med, også f.eks. stjerner, tankestreker før og etter sidetallet. Eventuelle streker og parentesbuer under og rundt tallene skal derimot gjøres rede for i typografibeskrivelsen (og disse transkriberes derfor ikke).
Nummereringskoden plasseres ved begynnelsen (<fw> plasseres foran starttaggen) eller avslutningen (<fw> plasseres etter sluttaggen) av <div>-, <sp>-, <stage>- og evnt. andre strukturelementer, men aldri direkte i <text> (det vil si utenfor <body>, <front> eller <back>).
All nummerering av ark/legg, blad og sider skal kodes med linjeskift på samme måte som annen tekst. <fw> skal inneholde attributtene type="" og place="" i trykte tekstvitner, samt evnt. hand="" i håndskriftsmateriale. Attributtet type="" skal inneholde en attributtverdi som typologiserer nummereringen, for place="" brukes TEIs attributtverdier, i hand="" brukes samme verdier som for hand="" i manuskriptkoding generelt. Her er noen eksempler:
BLADFOLIERING:
<fw type="leaf" place="top-right" hand="h3">2</fw>
KOLONNENUMMERERING:
<fw type="column" place="top">8</fw>
ARKSIGNATUR:
<fw type="sheet" place="bottom-left">HENRIK IBSENS
SAMLEDE VÆRKER. I.</fw>
ARKSIGNATUR:
<fw type="sheet" place="bottom-right">15</fw>
PAGINERING:
<fw type="page" place="top">8</fw>
TOPP- ("header") OG BUNNTEKST ("footer"):
<fw type="header" place="top">FRU INGER TIL ØSTRÅT</fw>
Eksempel fra F2 og fiktivt tekstvitne.
kap-9.3.1: Bruken av <fw> i manuskripter
kap-9.3.1.1: Typologisering av <fw>
Følgende verdier er i bruk i <fw type="">:
- «page» brukes til paginering, dvs. når tallene som skal kodes angår tellingen av sider
- «leaf» brukes til foliering, dvs. når tallene teller blader (to sider utgjør et blad)
- «gathering» er telling av hele legg (i trykk kaller vi det ark, «sheet»)
- «msPart» brukes til å kode bokstav- eller romertallmarkering av deler av et manuskript (hvor deler ikke = legg), når disse er dokumentert i form av påskrifter på manuskriptet. Eksempler: Ro41291 s. 7 ('b' øverst til høyre) og FH41116 s. 29 og 33 ('I.' og 'II.')
- «unknown» brukes når det ikke er mulig å avgjøre hva slags type tallet representerer
Det finnes mange forskjellige nummereringssystemer i HIs ms,
hvorav slett ikke alle skyldes HI selv (merk at all nummerering likevel
transkriberes). Noen ganger er det også rettet i nummereringen slik at det
finnes parallelle nummereringer. Her er noen eksempler på hvordan ms kan
være nummerert:
- paginering: hver side paginert (1, 2, 3)
- annenhver side paginert (1, 3, 5)
- telling begynner på nytt for hvert legg
- paginering stemmer ikke overens med leggnummer
- paginering på første og siste side av et legg
- bokstavrekker istedenfor eller i tillegg til tall
- legg: antall sider i leggene i Ibsens ms varierer (4, 8, 12, 14, 16, 20), siden leggene gjerne består av et antall dobbeltblader, telling som inkluderer fire eller flere sider typologiseres derfor alltid som «gathering»
- leggene i samme ms kan inneholde forskjelllig antall sider
kap-9.3.1.2: Vanskelige <fw>-tilfeller
I arbeidsmanuskriptene har vi en del tilfeller hvor det er
vanskelig – og kanskje noen ganger umulig? – å avgjøre hva slags
nummerering det opprinnelig har vært snakk om fordi vi nå sitter igjen med
f.eks. enkeltblader nummerert med kun ett tall. I slike tilfeller må vi
undersøke så grundig som mulig for å finne en rimelig sikker type:
- det innebærer å undersøke ms-originalen hvis det er vanskelig å finne ut av slikt vha faksimilene
- se på plassering på siden: leggnummer er vanligvis plassert i venstre øvre hjørne, mens side- og bladnummer plasseres i høyre hjørne (hvis sidene nummereres fortløpende står tallene i ytre hjørne og veksler dermed mellom venstre og høyre, men da fins det til gjengjeld ikke leggnummer, såvidt jeg kan se)
- snakke med andre erfarne ms-kodere
I tilfeller hvor vi ikke klarer å avgjøre hva slags
nummerering det er snakk om, bruker vi «unknown».
kap-9.3.2: Bruken av <fw> i trykte tekstvitner
kap-9.3.2.1: Uthevet tekst i arksignaturer
Forekomster av uthevet tekst i arksignaturer – f.eks. i forbindelse med forfatternavn eller verktittel – kodes med <hi>. Denne kodingen skal bemerkes i typografibeskrivelsen i forbindelse med beskrivelsen av arksignaturene. Hvis all tekst er trykket i uthevet skrift, skal dette ikke kodes med <hi>, men beskrives i typografibeskrivelsen.
kap-9.3.2.2: Doble arksignaturer
Doble arksignaturer betyr at et tekstvitne har to arksignaturer nederst på samme side, gjerne både verkstittelen, f.eks. «HENRIK IBSENS SAMLEDE VÆRKER. I.» og arknummerering, som oftest tilnærmet på samme linje. Doble arksignaturer kodes i to <fw>-elementer på samme linje uten mellomrom mellom elementene.
kap-9.4: Linjeskift – <lb/>
All tekst skal ha linjeskiftskoder. Linjeskiftene kodes med elementet <lb/>.
Alle linjeskift skal registreres. Linjeskift skal noteres for all transkribert tekst, inkludert foliering, paginering og arksignaturer.
kap-9.4.1: Plassering av linjeskiftselementene
Linjeskiftene plasseres så langt som mulig utenfor andre elementer (jf. <pb/>).
Vi oppfatter linjeskift som skilletegn på samme nivå som blanke, jf. Typografi. Det medfører at innsetting av en linjeskiftkode mellom to ord erstatter mellomrommet og overtar dets skilletegnsfunksjon. Mao., vi koder slik: «Fru<lb/>Inger», og ikke slik: «Fru <lb/>Inger», siden det ville medføre dobbelt skilletegn mellom ordene.
kap-9.5: Utheving
kap-9.5.1: Retorisk utheving – <emph>
Elementet <emph> brukes kun til retorisk utheving av ord i avsnitt (replikk, verslinje, brevtekst), dvs. i samsvar med definisjonen i TEI. All annen bruk av elementet er uriktig. Det gjelder f.eks. koding av «utheving» i overskrifter etc., dette er typografiske trekk som i stedet skal beskrives i <typography> i <teiHeader>.
Vi koder emfatiske trykkmarkeringer av hele ord (<emph>saalenge</emph>) eller deler av ord (<emph>saa</emph>vidt). Dette gjelder uavhengig av om tekstvitnet er trykt eller håndskrevet. I håndskrifter kodes markeringene bare dersom de er utført av en hånd vi inkluderer ellers i håndskriftet. Øvrige markeringer, som kryss/prikk/strek under enkeltbokstaver, kodes ikke, men omtales i typografibeskrivelsen.
I håndskriftsmateriale er utheving som oftest markert med understreking. Understrekingen av retorisk uthevede ord dekker ikke alltid hele ordet, eller det dekker ordet samt mellomrom (foran/bak) eller interpunksjonstegn. I slike tilfeller kodes bare selve ordet med <emph> og manglende/overflødig understreking tas ikke hensyn til. Dette kodes slik siden intensjonen bak understrekingen er utheving av ordet.
I håndskriftsmateriale kan det være hensiktsmessig å bruke rend=""-attributt i <emph>, hvis det forekommer flere typer retorisk utheving i samme tekstvitne/teksttype. Attributtet hand="" kan også brukes når det (i håndskrifter) forekommer retorisk utheving med annen hånd enn hovedhånden.
Hvorvidt interpunksjonstegn skal tas med innenfor <emph>, er i noen grad et skjønnsspørsmål. For å gjøre det enklere å avgjøre, har vi satt opp et sett med husregler for dette.
kap-9.5.2: Tilfeldig utheving – <hi>
Tilfeldige uthevinger i teksten (dvs. avvik i forhold til det typografiske systemet) kodes med <hi>.
<hi> brukes med rend=""-attributt når det finnes flere forskjellige typografiske utforminger av tekst kodet med <hi>. Ellers er det tilstrekkelig å å dokumentere den typografiske utformingen i typografibeskrivelsen.
NB! Hvis den uthevede tekststrengen allerede er omsluttet av et annet element (f. eks. <speaker> eller <head>), brukes ikke <hi>, men et rend=""-attributt (vanligvis med verdien "deviation") direkte i det aktuelle elementet. Dette gjøres for å unngå dobbeltkoding av samme tekstbit.
For gyldige rend=""-verdier, se «Attributtverdier».
kap-9.5.5.1: Hevet tekst – <hi rend="raised">
Hevet tekst kodes med <hi rend="raised">.
4<hi rend="raised">de</hi> Scene
kap-9.5.5.2: Initialer – <hi rend="initial">
Initialer, dvs. forstørrede forbokstaver, kodes slik:
<l><hi rend="initial">J</hi>eg maa, jeg maa, saa byder mig en Stemme,</l>
Eksempel fra C1.
Fremmedspråklige ord og uttrykk som er markert typografisk i den løpende teksten skal kodes med elementet <foreign>. Attributtet lang="" skal inneholde en attributtverdi som identifiserer språket. Dersom et helt avsnitt er skrevet på et annet språk (og markert typografisk) legges lang=""-attributtet direkte i elementet.
<l>mandeviljens <foreign lang="lat">qvantum satis</foreign> –?</l>
Eksempel fra Br.
<p lang="lat">Pater noster, ‐ pater noster!</p>
Eksempel fra KE.
Attributtverdien må dessuten defineres i <langUsage>-elementet i <teiHeader>, for at kodingen skal være valid.
For plassering av interpunksjon, se «Husregler for plassering av interpunksjon».
Alle rollenavn/-betegnelser som er typografisk markert i sceneanvisninger skal kodes med <stageRole>. Se «Uthevede rollenavn/-betegnelser i <stage> – <stageRole>» i «Retningslinjer for dramakoding».
kap-9.5.5: Trykt tekst i håndskrift – <print>
Trykt tekst i håndskrifter, for eksempel deler av visittkort, kodes med <print>. <print> brukes på samme måte som <emph> og <hi>.
<lb/><p><print>Dr. <hi rend="italics">Henrik Ibsen</hi>.</print> takker <lb/>herr løjnant Lundh forbindtligst <lb/>for den godhedsfulle tilsendelse <lb/>af de to gamle breve.</p> <lb/><salute>Ærbødigst</salute> <lb/><signed>H. I.</signed>
Eksemplet er hentet fra B18990108ABL

kap-9.5.6: Husregler for plassering av interpunksjon
Hovedprinsipper:
- «små enheter», dvs. et eller noen få ord: interpunksjon plasseres utenfor elementet teksten kodes i, uthevede tegn i forbindelse med enkeltord oppfattes ofte som feilsetting, og det er derfor intuitivt logisk å plassere dem utenfor elementene.
- «store enheter», dvs. hele setninger, et eller flere avsnitt som inneholder tegnsetting (typisk fremmedspråklige sitater): tegnsettingen følger teksten inn i elementet
- skjønn: det åpnes for at man bruker skjønn i kodingen
kap-9.6: Noter – <note>
Midlertidige arbeidnoter kodes i <note type="workingNote"> med kollasjonistens initialer i resp="". Notene brukes særlig til å markere steder som er problematiske eller inneholder informasjon som (foreløpig) ikke er kodet (f.eks. i påvente av hva man skal gjøre med den), eller som «under arbeid»-informasjon til kolleger. Arbeidsnotene fjernes når fila er ferdig kodet fra kollasjonistenes side. Arbeidsnoter med informasjon som kan bli stående til filologenes gjennomgang, beholder type-attributtet mens resp-attributtet fjernes.
Filologene setter inn resp="editor" ved noter som inneholder nødvendig tilleggsinformasjon og derfor blir liggende i den ederte fila.
kap-9.6.2: Noter om feil i teksten – <note type="typo">
Vi bruker <note type="typo"> til å notere opplysninger om manglende og feil tegnsetting, manglende diakritiske tegn, minuskel-/majuskelfeil osv, se «Husregler for behandling av tekstfeil».
kap-9.6.3: Forfatternoter – <note resp="">
Egenhendige noter (ikke skriblerier, disse skal omtales i typografibeskrivelsen eller <note type="scribble">) skal alltid transkriberes. Attributtverdier i resp="":
- i manuskriptfiler brukes resp="author". Dersom det er hovedhåndens note, trengs ikke noe hand-attributt. Dersom det er en annen Ibsenhånds note, må hand-attributt kodes inn.
- håndskrevne noter i filer som inneholder trykt tekst: her brukes også resp="author", men alltid med hand-attributt.
kap-9.6.3.1: Noter uten referanse i teksten
Forfatternoter uten notereferanse i brødteksten og hvor selve noten er plassert i margen e.l., skal kodes med <note resp="" place=""> og plasseres nærmest det stedet hvor de ble skrevet. For gyldige attributtverdier til bruk i place="", se «Attributtverdier».
<lb/><sp who="FRKSKJAERE"><spOpener><speaker>Frøken Lærke</speaker>.
<lb/><stage>(til Falk.)</stage></spOpener>
<lb/><p>Vi faar vel ellers snart see noget større Arbeide
<lb/>fra <sic>dem</sic>, for <sic>de</sic> skriver vel flittigt herude.</p></sp>
<lb/><sp who="FRUHALM"><spOpener><speaker>Fru Halm</speaker>
<lb/><stage>(smilende.)</stage></spOpener>
<lb/><p>Det tror jeg ikke man skal beskylde Herr
<lb/>Falk for.</p></sp>
<lb/><sp who="FALK"><spOpener><speaker>Falk</speaker>.</spOpener>
<lb/><p>Hvad skulde jeg kunde skrive om her, hvor jeg
<lb/>Intet savner?</p></sp>
<lb/><note resp="author" place="bottom">Trang skaber Digte o. s. v</note>
<pb/>
<lb/><sp who="FRKSKJAERE"><spOpener><speaker>Frøken Lærke</speaker>.</spOpener>
<lb/><p>Ja, jeg mente just da.</p></sp>
<lb/><sp who="FALK"><spOpener><speaker>Falk</speaker>.</spOpener>
<lb/><p>Lad mig miste Synet saa skal jeg digte om
<lb/>den blaa Himmel. Jeg <del rend="overstrike">skulde</del> kunde fristes
<lb/>til at bede Vorherre om en stor Sorg, – havde jeg
<lb/>den saa skulde jeg ikke længere døse Tiden
<lb/>bort</p></sp><pb ed="HU" n="258"/>
<lb/><sp who="FRUHALM"><spOpener><speaker>Fru Halm</speaker>.</spOpener>
<lb/><p>Aa fy!</p></sp>
<lb/><sp who="FRKSKJAERE"><spOpener><speaker>Frøken Lærke</speaker>.</spOpener>
<lb/><p>Gud, hvor kan <sic>de</sic> sige sligt!</p></sp>
Eksemplet er fra Sv. Konteksten er tatt med for å vise hvordan noten innholdsmessig forholder seg til dramateksten.
kap-9.6.3.2: Noter med referanse i teksten
OBS! For tilføyelser med referansetegn som markerer hvor tilføyelsen skal inn: se manuskriptkapitlet
Forfatternoter med notereferanse i teksten og noteteksten plassert annet sted, skal kodes med <note resp="author" place=> (og eventuelt hand="") og plasseres så diplomatarisk som mulig. For attributtverdier i bruk i place="", se «Attributtverdier».
Referansetegnet – både i den løpende teksten og ved noten – kodes i <ref type="refMark" target="" id="">, eventuelt med hand-attributt. Attributtverdiene for id="" og target="" i <ref> ved noten bygges opp over formelen «n+siffer» («n» står for note) i id="", og «nb+siffer» («b» står for back) i target="". Notene nummereres fortløpende. Attributtverdiene til id="" og target="" i <ref> i den løpende teksten er bygget opp motsatt av verdiene til <ref> i <note>. Ved noten vil kodingen med andre ord se slik ut: <ref type="refMark" target="nb+siffer" id="n+siffer"></ref>, og i den løpende teksten vil kodingen se slik ut: <ref type="refMark" target="n+siffer" id="nb+siffer"></ref>. Slik lages det en kryssreferanse mellom referansetegnet i teksten og noten.
Transkripsjon av referansetegnet:
- når referansetegnet er trykt: referansetegnet transkriberes diplomatarisk (f.eks. '*)' i Norma-eksemplet i kap. 6.4. nedenfor)
- når referansetegnet er håndskrevet: med mindre referansetegnet består av tekst, transkriberes det med entiteten &referenceMark; (dette fordi tegnet ofte er utranskriberbart eller fordi tegnet i den løpende teksten ikke er likt som tegnet i den tilhørende noten).
Eksempel:

Koding:
<lb/><note resp="author" hand="HI-1" place="margin-left">(<ref type="refMark" target="nb1" id="n1">&referenceMark;</ref> spær!)</note> dels i Bakkerne. <stageRole who="FOGDEN">Fogden</stageRole> sidder i Midten paa en Sten; en Skriverkarl <ref type="refMark" hand="HI-1" target="n1" id="nb1">&referenceMark;</ref>
De øvrige rettelsene på siden er ikke tatt med i eksemplet.
kap-9.6.4: Fortellernoter og redaksjonelle noter
Hvis noten er så tett knyttet til den fiktive teksten at det er mer nærliggende å koble den til forteller- enn forfatterinstansen, bruker vi <note resp="narrator">.
<l>At holde mig en Hestelængde bagud for Tiden.<ref type="refMark" target="n1" id="nb1">*)</ref></l></sp> <stage>(de gaae.)</stage> (...) <l>Har her mig i Lunden et Stævne sat,</l> <note resp="narrator" place="bottom"><ref type="refMark" target="nb1" id="n1">*)</ref>Man vil bemærke at de Vers, der fremsiges afsides, ere anderledes byggede, end de, der maa høres af Alle og Enhver; dette er in&typHyp; genlunde nogen Skjødesløshed, men med Forsæt iagttaget, da vel underrettede Per­ soner ville vide, at vore politiske Skuespillere endog til Dagligbrug betjene sig af et særegent Versemaal, naar de tale afsides.</note>
Eksempel fra No. (linjeskiftkoding er fjernet)

Tilleggsopplysninger i den publiserte teksten som er lagt inn av utgiver, kodes med <note resp="publisher">. Se Kjæmpehøien (1854).
Se forøvrig: «Egenhendige og ikke-egenhendige noter»
kap-9.6.5: Metrikknoter – <note type="met">
Noter som angår metrikk skal typifiseres: <note type="met">. Se «Retningslinjer for verskoding».
Se avsnittet «Noter» i kapitlet om ekstern variasjon.
kap-9.7: «Tekstfeil» – <sic>
Filologene vil gjennomgå noter vedrørende tekstfeil og kodingen av disse før utlegging i HISe.
kap-9.7.1: Koding av tekstfeil
<sic> brukes for å markere tekstfeil; dvs. åpenbare skrivefeil eller trykkfeil o.l. Hele ordet skal da settes inn i elementet. Vi bruker ingen attributter. Det ser f.eks. slik ut:
<l>vær helt og holdent <sic>Muldels</sic> Mand.</l>
Eksempel fra Br.
<sic> skal brukes til feilskrevne ord. Ved manglende eller galt tegn, brukes <note type="typo"> istedenfor <sic> til å påpeke hva som mangler/er galt (f.eks. sluttparentes).
<l>Det gjør ej till, ej fra, en Snus,</l> <l>om Kirken er et Hundehus.<note type="typo">Feil tegn.</note></l> <l>naar Folk kun uforstyrret tror,</l>
Eksempel fra Br.
kap-9.7.2: Husregler for behandling av tekstfeil
Husreglene er utarbeidet i fellesskap av filolog og forskningsassistenter.
Man skal skille mellom en intern (verkets norm) og en ekstern rettskrivningsnorm (generell norm). Feil er inkonsekvenser i verkets egen norm. Markeringen av dette er ikke kollasjonistenes ansvar, men filologens. Kollasjonistene markerer derfor i disse tilfellene det vi finner underveis i kollasjoneringsarbeidet. Vi noterer større inkonsekvenser i typografibeskrivelsen og markerer tilfeldige enkeltfeil med noter. Vi skal imidlertid ikke bruke mye tid på dette.
Grammatiske feil markeres ikke, f.eks. entalls- og flertallsbøyning; dog kan man likevel markere f.eks. høflig "De", hvor majuskel "D" er endret til minuskel "d", siden det er vanskelig å avgjøre om dette er en trykkfeil eller ikke.
Feil utover dette som oppfattes som trykkfeil, markeres. Her er en liste over fenomener og hvordan de skal behandles:
- Feil/inkonsekvens i replikkåpner (<spOpener>). Det er unødvendig å notere dette siden vår utgaves oppsett skal være gjennomgående (endringer kan gjøres automatisk).
- Manglende(/feil) start- eller sluttparentes. Noteres i <note type="typo">.
- Manglende(/feil) anførselstegn. Noteres i <note type="typo">.
- Manglende tegnsetting ved slutten av avsnitt/replikk eller foran ny setning markert med stor bokstav. Noteres i <note type="typo">.
- Manglende bindestreker, se «Manglende bindestreker».
- Feilaktig tegn (komma og semikolon) ved slutten av avsnitt/replikk. Noteres i <note type="typo">.
- To bindestreker på rad (f.eks. -<lb/>-) – bare første forekomst transkriberes, og det bemerkes i typografibeskrivelse (hvis det fins mange tilfeller) eller note (hvis det kun fins få tilfeller).
- Majuskel etter komma og minuskel etter punktum. I hvert tilfelle blir det en fortolkningssak om man da skal kode ordet med <sic> pga. majuskel-/minuskelfeil eller notere i en <note> at tegnet er galt.
- Majuskel/minuskel etter semikolon? Her må man se på verkets tegnsettingsnorm, så dette er avgjørelser som kan/bør overlates til filologen.
- Minuskel etter utropstegn, spørsmålstegn og kolon? Her må man også se på verkets tegnsettingsnorm, så dette er avgjørelser som kan/bør overlates til filologen.
- "aa" for "å" (evt. omvendt) i tekster hvor det motsatte er normen, kodes med <sic>. Større inkonsekvenser i bruken kodes ikke, men bemerkes i typografibeskrivelsen.
- "å" uten bolle i trykte tekstvitner transkriberes som "a" og sicces som andre trykkfeil. Vi skiller ikke mellom tekniske feil på typen (bollen har falt av) og ekte setterfeil ("a" for "å").
- "å" uten bolle i manuskripter transkriberes som "å", men det bemerkes i påfølgende note at "å" mangler diakritisk tegn. Vi skiller ikke mellom uteglemt bolle over "å" og faktisk feilskriving ("a" for "å").
- tilfeldig bruk av "ö" noteres i typografibeskrivelsen og transkriberes som "ø" (unntatt i svenskspråklig tekst)
- "ø" uten strek over i trykte tekstvitner transkriberes som "o" og sicces som andre trykkfeil.
- "ø" uten diakritisk tegn (i manuskripter), transkriberes som "ø", men det bemerkes i påfølgende note at "ø" mangler diakritiske tegn. Hvis det er veldig mange forekomster av "ø" uten diakritiske tegn (gjerne tilfelle i utpreget kladdeskrift) transkriberes disse som "ø", og forholdet bemerkes dessuten generelt i typografibeskrivelsen.
- "i" uten diakritisk tegn (i manuskripter) transkriberes som "i" uten påfølgende note, såfremt det ikke er reell tvil om lesemåten.
- Ord (som ikke er personnavn) med innledende majuskel i løpende tekst kodes med <sic>. Unntak er majuskel i starten av verslinjer hvor systemet er at alle linjer innledes med majuskel samt tekstvitner hvor substantiver skrives med majuskel.
- Dittografier (bryllup)
- gjentakelse av samme ord: siste ord kodes med <sic>
- gjentakelse av stavelse/del av ord: hele ordet kodes med <sic>. Eks. «velvelkommen».
- Spesialtilfeller: hvis dittografien krysser foliert sideskift kodes bare den gjentatte delen hvis det medfører at folieringen holdes utenfor <sic>. Se også Replikker med doble rollenavn.
- Haplografier (begravelse)
- utelatelse av et helt ord: for at man skal oppfatte utelatelse av et helt ord som en haplografi må den nye teksten miste betydningen/bli vanskelig å forstå. Når ord utelates mellom tekstvitner uten at det ødelegger tekstens betydning, kan man ellers ikke være sikker på om det er en haplografi. Ved mistanke om haplografi kan man sette inn en <note>.
- utelatelse av stavelse/del av ord: hele ordet kodes med <sic>. Eks. «filogi» for «filologi».
- Bortfall av bokstaver:
- Dersom en bokstav har falt bort i begynnelsen eller slutten av et ord, transkriberes ikke det doble mellomrommet som oppstår mellom det bortfalte tegnet og påfølgende tegn. Ved slike tilfeller er det tilstrekkelig å opplyse om det overflødige mellomrommet i en typo-note.
- Ved bortfall av tegn inni et ord, skal mellomrommet derimot transkriberes.
For koding, se .
kap-9.7.3: Koding av snudde typer
- Det VAR mulig å snu typene ved håndsetting på Ibsens tid. Men dersom en type ble snudd 180° i planet, ville det være TILFELDIG om den kom på linje med de øvrige typene. Det er tale om svært små marginer, men de vil kunne avdekkes. I slike tilfeller vil vi kunne snakke om "ekte" snudde typer, men disse tilhører iflg. Rannem sjeldenhetene.
- For setteren vil det være lett å se om en type er snudd, siden hver type var forsynt med en "signatur" på baksiden, som regel øverst. Men dårlig lys f.eks. ville selvsagt kunne forårsake snudde typer.
- Dersom det man tror er en snudd type ER på linje, er det likevel mest sannsynlig at vi har å gjøre med såkalte "fisker", dvs. typer som er lagt i feil "fag" ved "avlegging" etter en brukt sats. Dette fenomenet lar seg også skille ut fra "ekte" snudde typer, ettersom det vil være små forskjeller mellom typene som forteller om vi har med en opprinnelig "n" el. "u".
- Det er naturligvis større sjanse for at en "u" havner hos en "n" enn at en "k" havner i faget for "m", noe som kan være grunnen til at vi oftere ser slike feil. Men vi ser like ofte "i" for "l".
Snudde typer kodes forskjellig avhengig av om det dreier seg om bruk av feil type eller om faktisk snudd type.
Faktiske snudde typer rettes umiddelbart, men det noteres i en <note type="typo"> hvilken type i ordet som er snudd i trykket.
<speaker>Kvinden<note type="typo">Siste "n" i "Kvinden"
er snudd.</note></speaker>.
Eksempel fra Br.
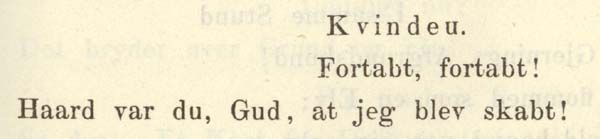
Falske snudde typer, f.eks. når en snudd «n» viser seg å være en «u», rettes ikke siden dette i en viss forstand kan betraktes som vanlige trykkfeil. Ordet transkriberes med trykkfeilen intakt og kodes med <sic>. Slike feil forutsetter at man kan se forskjell på «n» og «u» i den aktuelle skrifttypen. Forskjellen framtrer f.eks. gjennom forskjellig lengde på seriffene og/eller forskjellige proposjoner. I tillegg til «n» og «u», kan dette gjelde «p» og «d» (og muligens, men neppe «q» og «b»).
<sic>Hvermaud</sic>
Eksempel fra Br.
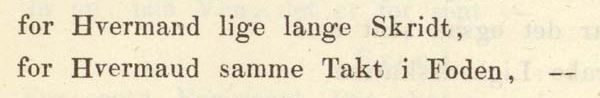
Forbytting av disse bokstavene skyldes nok gjerne at de har havnet i hverandres bokser i settekassa, men det kan selvfølgelig også være snakk om ekte trykkfeil.
Se også prosjektets tekstkritiske retningslinjer.
kap-9.8: Transkripsjonsnormalisering
Vi har vedtatt et sett retningslinjer for tillatt normalisering når man transkriberer.
kap-9.8.1: ...i trykt tekst
- majuskler/versaler (A, B, C...) gjengis som majuskler
- minuskler (a, b, c...) gjengis som minuskler
- kapitéler (bokstaver med majuskelform i minusklenes x-høyde) gjengis som minuskler
- FU gjengir bl.a. replikkinnehaver og arksignaturer med kapitéler. Dette transkriberer vi med majuskel forbokstav og minuskler.
- avvikende tegnbruk (fete tegn, større/mindre tegn, 'ö' for 'ø' etc.) transkriberes som normalt tegn, men anmerkes i noter/typografibeskrivelsen
- tilfeldig bruk av f.eks. "ö" noteres og transkriberes som "ø" (unntatt i svenskspråklig tekst)
- ujevn tegnavstand og utydelige tegn markeres ikke hvis det ikke kan medføre tvil om lesningen
- eventuelle streker over eller under pagineringen gjengis ikke
- manglende interpunksjon, parenteser etc. anmerkes i noter
kap-9.8.2: ...i manuskripter
- vi skiller ikke mellom latinsk og gotisk håndskrift, alle innslag av gotiske bokstaver normaliseres vekk. Håndskriften omtales imidlertid i typografibeskrivelsen (man angir hva slags håndskrift hendene bruker, blandingstendenser, flere utgaver av samme majuskel/minuskel, jf. forekomster av flere versjoner av «d» bla. i Sa)
- tankestrek etter et ord forstås og transkriberes som tankestrek når den ikke henger sammen med ordet, strek i fortsettelsen av siste bokstav i et ord kodes derimot ikke som separat tankestrek. Skjønnsunntak må gjøres f.eks. for «t», her kan tverrstreken noen ganger stå etter/ ikke henge sammen med resten av bokstaven (jf. RJ4932). I slike tilfeller skal tverrstreken ikke forstås som tankestrek
- bindestreker
- bindestreker plassert (tilfeldig) foran eller etter linjeskift transkriberes alltid (etter første halvdel av ordet) foran linjeskift
- doble bindestreker (to på rad) det forekommer at skriver har satt bindestrek både foran og etter linjeskift, i slik tilfeller transkriberer vi bare første forekomst og utelater andre forkomst
- doble bindestreker (=) transkriberes som vanlig bindestrek (-)
- man legger inn noter ved manglende typografiske bindestreker
- håndskriftets bindestreker beskrives i typografibeskrivelsen
- parenteser
- vi transkriberer alle varianter av parenteser (skråstreker med kolon etc.) med standardtegnene ()
- håndskriftets parenteser beskrives i typografibeskrivelsen
- manglende diakritiske tegn
- å uten bolle transkriberes som «å», men det bemerkes i påfølgende note at «å» mangler diakritisk tegn. Vi skiller ikke mellom uteglemt bolle over «å» og faktisk feilskriving («a» for «å»)
- ø uten diakritisk tegn transkriberes som «ø», men det bemerkes i noter etter ordet at «ø» mangler diakritiske tegn. Ved særlig mange forekomster/slurvete skrift bemerkes forholdet i typografibeskrivelsen
- tilfeldig bruk av «ö» noteres i typografibeskrivelsen og transkriberes som «ø» (unntatt i svenskspråklig tekst)
- i uten diakritisk tegn transkriberes alltid som «i», mangelen bemerkes vanligvis ikke (kun hvis evt. forveksling med «e» kan føre til reell tvil om lesemåten) hverken i note eller typografibeskrivelse
- ordenstall-endelser transkriberes velvillig, slik at man ikke blir stående med "1st" og "2de", men "1ste" og "2den". Kruseduller og tilsynelatende manglende tegn kan transkriberes som det de skal leses som
- når det ved forkortede skrivemåter er brukt spesielle abbreviaturtegn, dvs. tegn som representerer bestemte bokstaver, som f.eks. nasalstrek, skal disse løses opp og markeres spesielt, jf. Forkortede ord – <expan abbr="">
- ujevn tegnavstand og utydelige tegn markeres ikke hvis det ikke kan medføre tvil om lesningen
- manglende interpunksjon, parenteser etc. anmerkes i noter
- forkortelser transkriberes med mellomrom etter tegnsetting: "o. s. v.", "P. S."
- ved prosenttegn skal det legges inn blanke mellom tallet og prosenttegnet: 31 %
- ved adresser med tall og hevet bokstav skal det ikke være mellomrom mellom tallet og bokstaven: "Amalienstrasse 50<hi rend="raised">a</hi>"
- initialer transkriberes med mellomrom etter evnt. tegnsetting: "H. I.", "H: I."
- streker, omsluttende tankestreker og parentesbuer i forbindelse med foliering i manuskripter transkriberes ikke.
- det hender at Ibsen har skrevet to punktum i stedet for ett. Disse transkriberes uten mellomrom. Feilen kan gjerne kommenteres i en <note type="typo">.
kap-9.9: Faksimiler, logoer og illustrasjoner
Illustrasjoner etc., som f.eks. faksimilene i Hundreårsutgaven eller forlagslogo på tittelblad, skal kodes med <figure>. Faksimilene av tittelsidene i HU regnes altså ikke som tittelsider og kodes dermed ikke som <titlePage>. Bibliotekstempler transkriberes og kodes ikke.
Her er et eksempel på gyldig koding av en forlagslogo:
<figure type="logo"> <figDesc>Forlagslogo.</figDesc> </figure>
Her er et eksempel på gyldig koding av en illustrasjon:
<figure type="illustration"> <figDesc>Strektegning av gammel and.</figDesc> </figure>
Denne måten å kode på dokumenterer figurene og illustrasjonene, men viser dem ikke. Elementet <figDesc> skal derfor inneholde en kort beskrivelse av figuren/illustrasjonen, jf. eksemplet. <figure> skal dessuten inneholde et type=""-attributt som klassifiserer figuren nærmere, jf. eksemplet.
kap-9.9.1: Utelatt tekst/illustrasjoner – <gap/>
Når teksten i et tekstvitne avbrytes av tekst eller illustrasjoner som ikke skal være en del av teksten (særlig aktuelt i tekster fra føljetonger), markerer vi den utelatte teksten/illustrajonen med <gap reason="irrelevant"/>.
Vi markerer likevel ikke med <gap/> at vi utelater noe som ikke angår tekstvitnet vi transkriberer når vi jobber med manuskripter med flere tekstvitner fra forskjellige verk. Det utelatte kommenteres i disse tilfellene i «Bibliografiske opplysninger om kildene – <sourceDesc>».
kap-9.10: Skillestreker
Vi skiller mellom vanlige skillestreker (inkl. pyntestreker) og strofeskiller (hos Ibsen: skigard).
kap-9.10.1: Pynte- og skillestreker
Pynte- og skillestreker skal kodes som <figure type="bar"/>.
Vi forstår skillestreker som streker som avslutter foregående tekstelement. Når man er i tvil om plasseringen brukes skjønn. På tittelsider plasseres <figure>-elementet mellom de andre elementene, ditto plasseres <figure>-elementet mellom/etter overskrifter. I forbindelse med scene-, akt- eller tekstslutt plasseres <figure>-elementet innenfor det elementet det avslutter. Skillestreker sist i siste akt avslutter stykket og skal plasseres rett i <body>.
Vi markerer ikke forskjell på pynte- og skillestreker, og vi tar heller ikke med noen beskrivelse av strekene (vi bruker mao. ikke <figDesc> her).
kap-9.10.2: Strofeskiller
Hos Ibsen forekommer (i dikt og enkelte versdrama) strofeskiller i form av skigarder (#). Disse kodes som <figure type="num"/>.
kap-9.11: Tegnsetting
kap-9.11.1: Anførselstegn
For anførselstegn bruker vi disse entitetene:
- &lquo;
- &rquo;
Den første bokstaven i forkortelsene står for posisjon i forhold til sitatet: l for venstre og r for høyre; de tre neste, quo, er en forkortelse for «quotation mark», dvs. anførselstegn. #171 og #187 gir doble, «norske» anførselstegn.
kap-9.11.2: Tankestrek
For tankestrek bruker vi entiteten ‐.
kap-9.11.2.1: Tankestrek etterfulgt av interpunksjon
Vi har vedtatt at det ikke skal kodes mellomrom mellom tankestrek og etterfølgende interpunksjon, med mindre det er sterke argumenter for å gjøre dette. Dette gjelder både trykte tekstvitner og manuskripter.
kap-9.11.2.2: Tankestrek mellom tall i tidsspenn
Streker mellom tall/tallord i tidsspenn transkriberes som tankestrek, uten mellomrom før og etter, både når tidsspennet er gjengitt med tall og bokstaver. Dette gjelder også når tallsekvensen angir en omtrentlig mengde:
En væsentlig del findes i «Illustreret Nyhedsblad» årene 1864–68.
Det regnet fra første–tredje juli.
Januar–Marts
Reisen vil ta en 5–6 dager.
De bodde i Roma en fire–fem år
Merk at streker i forb. med angivelse av omtrentlig mengde tidligere ble gjengitt med bindestrek og at det kan ligge en del feilkodede streker igjen i filene
Hvis streken står mellom to eller flere ledd skal det være mellomrom før og etter tankestrek
fra 6. august – 9. august
Streker som binder sammen tall og ord, transkriberes som vanlig bindestrek:
1800-tallet
Det skal også være vanlig bindestrek i datoer av denne typen:
30/6-73
kap-9.11.2.3: Linjer med tankestreker
Linjer med tankestreker kodes med type="dashes"="" i det elementet som passer best:
I dikt:
<l type="dashes">– – – – – –</l>
I drama:
<stage type="dashes">– – – – – –</stage> eller <p type="dashes">– – – – – –</p>
kap-9.11.2.4: Tankestreker i manuskripter
Hovedregel for transkripsjon av tankestreker i mansukripter er at en strek transkriberes som tankestrek dersom den er helt adskilt fra forutgående tegn. Hvis derimot streken henger sammen med forutgående tegn regnes streken som avslutning av dette tegnet.
Unntak fra hovedregel: i kladdeskrift kan av og til punktum i replikkåpner være dratt ut slik at det ligner en strek. Disse «strekene» transkriberes likevel som punktum (men fenomenet bør noteres i typografibeskrivelsen). Merk at dette kun gjelder i replikkåpner. Frittstående streker i avsnitt transkriberes som tankestreker.
kap-9.11.3: Bindestreker
Vi behandler enkelt- (-) og dobbeltbindestrek (=) likt og transkriberer begge som enkeltbindestreker, men vi bemerker avvikende utforming (=) i typografibeskrivelsen.
kap-9.11.3.1: Typografiske/myke bindestreker ved linjeskift – &typHyp;
Typografiske bindestreker kodes med entiteten &typHyp;. Entiteten plasseres bak første del av det delte ordet, men foran <lb/>.
kap-9.11.3.2: Meningsbærende/harde bindestreker ved linjeskift
Meningsbærende bindestreker skal være absolutt sikre før de kodes inn, og da kodes de med bindestrekstegnet. Hvis det er tvil om bindestrekens funksjon, kodes den i stedet som typografisk bindestrek.
Ved verk med flere tekstvitner skal man, om det er tvil om bindestreken er meningsbærende eller typografisk, velge den samme type bindestrek som i de øvrige tekstkilder. Det gjelder også ved koding av eksterne varianter, se «Variasjon som ekskluderes»
kap-9.11.3.3: Manglende bindestreker
I de tilfellene hvor det mangler bindestrek ved linjeskift, men hvor det åpenbart skulle ha vært det, unnlater vi å sette inn &typHyp;. Istedenfor settes det inn en <note type="typo"> ved ordet som skulle hatt bindestreken. Manglende bindestreker kodes dermed som manglende tegn forøvrig («Husregler for behandling av tekstfeil»). Denne kodingen gjelder både for typografiske og meningsbærende bindestreker.
kap-9.11.3.4: To bindestreker på rad
To bindestreker på rad ved linjeskift (-<lb/>-) forekommer i enkelte håndskrifter. Bare første forekomst transkriberes, og fenomenet og behandlingen av den bemerkes i typografibeskrivelsen (hvis det fins mange tilfeller) eller i en note (hvis det kun fins få tilfeller). Se også Husregler for behandling av tekstfeil.
Merk at bare hovedtekster og kommentartekster skal <rs>-kodes. Merk dessuten at dikt ikke skal <rs>-kodes, dette gjelder altså både grunn- og hovedtekster.
I ikke-fiktive teksttyper som brev, forord ol. navnekoder vi personnavn, stedsnavn, verk og enkelte institusjonsnavn i elementet <rs> med attributtene corresp="" og type="". Verdien i type-attributtet bestemmes ut fra navnekategori; "place", "person", "work" og "org" brukes ved henholdsvis stedsnavn, personnavn, verk og institusjoner/organisasjoner. I corresp-attributtet plasseres det aktuelle navnets unike ID-verdi som ligger i ID-basen (se nedenfor). For å holde id-verdiene unike, har vi bestemt at hver person-id har foranstillt "pe", hver verks-id foranstillt "wo", hver steds-id foranstillt "pl" og institusjons/organisasjons-id har foranstillt "org".
Vi koder ikke bare egennavn, men også tiltale, titler og substantiv som kan kobles til et identifisert navn. For eksempel kodes 'min forlegger', 'din hustru' og 'mitt neste litterære verk'. Av verkstitler koder vi utelukkende tekster av Ibsen, i alle sjangre. Omtale av fiktive figurer i Ibsens verk kodes som verk, mens omtale av historiske personer i Ibsens verk kodes som personer. Ved tvilstilfeller kodes personene/figurene både som person og verk. Henvisninger til personer, steder og verk som ikke med sikkerhet kan identifiseres kodes ikke, ei heller fiktive figurer. Ved koding av stedsnavn kodes derimot både faktiske og fiktive steder. Institusjoner som er brevmottakerer kodes alltid, i selve brevteksten navnekodes kun de institusjoner som er markert av Vigdis Ystad i den sorte permen på det blå kollasjonistrommet.
Fiktive teksttyper (dikt- og dramatekster) navnekodes ikke. I rimbrev, hvor det kan være vanskelig å trekke en grense mellom fiktive og faktiske referanser, legger vi heller ikke inn navne-koding. Faktisk tekst rundt den fiktive teksten (datolinjer, pro- og epiloger) skal derimot navnekodes.
Ved koding av navn, steder og verk må alle attributtverdier i corresp="" kontrolleres mot ID-basen. For å sikre at alle corresp-verdier i fila er identiske med id-verdiene i ID-basen, valideres corresp-verdiene i fila mot ID-verdiene i basen. Dette gjøres ved at det legges en entitet i <tagUsage> som viser til en av ID-basen generert xml-fil. Se for øvrig kap. om ID-basen i arbeidsprosedyrer for en grundigere innføring.
Det er ikke så nøye hvor stor del av navnesekvensen som omsluttes av rs-elementet. Fremtidige søk kommer sannynligvis til å genereres ut fra personregistret, slik at det er denne navneformen som kommer opp i søkevinduet.
kap-9.12.1: I teiHeader/letterinfo
I brevfiler skal både sted, mottaker og avsender kodes egne <rs>-elementer i <letterinfo>. Elementet plasseres direkte i <sender>, <recipient> og <origPlace>. Merk at brevmottaker både kan ha "person" og "org" i type-attributtet, avhengig av om brevet er stilet til en person eller en institusjon/organisasjon.
Eksempel på koding:
<origPlace><rs type="place" corresp="plKri">Kristiania</rs></origPlace> <recipient><rs type="person" corresp="peGBr">Gerda Brandes</rs></recipient> <recipient><rs type="org" corresp="orgKNT">Kristiania Norske Theater</rs></recipient> <sender><rs type="person" corresp="peHI">Henrik Ibsen</rs></sender>
kap-9.12.2: I løpende tekst
Det er tilstrekkelig å kode navnet/verkstittelen ved første forekomst i hver grunntekstfil. Navn som er rs-kodet i <teiHeader> skal ikke kodes i brevtekst, bortsett fra stedsnavn, som kodes ved første forekomst i løpende teksten (men ikke i dateringslinjen) selvom det allerede er kodet i <origPlace> i <teiHeader>.
Eksempel på koding:
Hils <rs type="person" corresp="peKBj">Din Kone</rs> paa det Hjerteligste fra oss. De avisskrivende fingre, der kritiserer i <rs type="place" corresp="plN">Norge</rs>, forstaar det ikke. Til Jul udkommer af mig <rs type="work" corresp="woBr">dramatisk Digt</rs>
Dersom sekvensen som navnekodes viser til flere identifiserbare personer, skal alle id-verdiene settes i corresp-attributtet. Id-verdiene står da i alfabetisk rekkefølge innenfor samme anførselstegnpar, adskilt med en blank mellom seg.
Eksempel på koding:
Mangfoldige hilsener fra <rs type="person" corresp="peSiI peSuI">min familje</rs>.
Navnesekvensen som krever to (eller flere) rs-elementer med ulike type-attributt kan kodes med et rs-element inne i et annet rs-element.
Eksempel på koding:
<rs type="org" corresp="orgUHel">Universitetet i <rs type="place" corresp="plHel">Helsingfors</rs></rs>
På samme måte kan navn med kryssende roller kodes, som f.eks Frederik Hegel som både kan vise til forleggeren og personen.
Eksempel på koding:
<rs type="org" corresp="orgGyl"><rs type="person" corresp="peFH">Hegel</rs></rs>
kap-9.13: Koding av datoer
kap-9.13.1: I teiHeader
Hvis filen er basert på en trykt tekst kodes datoer med elementet <date> i <bibl>. <date> skal ha attributtet value="". Verdien i value="" bestemmes av den aktuelle dateringen etter standarden: yyyy-mm-dd. Ukjente deler av dateringen fylles ut med xx.
Eksempel på koding:
<date value="1889-08-20">20.08.1889</date> <date value="1890-xx-xx">1890</date>
I manuskripter kodes datoer i <msDesc> med <origDate> og value-attributt etter samme kodemønster som <date>. Ved usikker datering kan attributtene notBefore="yyyy-mm-dd" og notAfter="yyyy-mm-dd" plasseres i <origDate>. Datering som strekker seg over en definert periode suppleres med elemetet <dateRange> og attributtene from="yyyy-mm-dd" to="yyyy-mm-dd". Ukjente elementer i dateringen fylles ut med x som i det aktuelle leddet av attributtverdien.
Eksempel på koding:
<origDate value="1869-05-17">17.05.1869</origDate> <origDate notBefore="1879-06-15" notAfter="1879-07-01">1879</origDate> <origDate><dateRange from="1871-01-30" to="1871-02-20">Fra 30.01.1871 til 20.02.1871</dateRange></origDate> <origDate><dateRange from="1871-01-xx" to="1871-02-xx">Fra januar til februar 1871</dateRange></origDate>
Se «<teiHeader>».
Merk at egenhendige dateringer underveis i manuskripter (f.eks ved en akts begynnelse og slutt) ikke kodes med <origDate>, men som forfatternoter.
Kalender-problematikken er som regel ikke relevant; ved brev som er skrevet i Russland bør det forøvrig opplyses om at dateringen kan følge den ortodokse kalenderen.
kap-9.13.2: I innledende og avsluttende elementer
I <text> kodes datering kun i innledende og avsluttende elementer, ikke i den løpende teksten. I løpende tekst står <date> uten value-attributt.
Eksempel på koding:
<dateline>Rom den <date>15. Januar 1870</date>.</dateline>
kap-10: Lenkekoding
kap-10.1: Innledning
Vi skiller mellom referanser (<ref>) og pekere (<ptr>) innenfor et enkelt dokument, og pekere (<xptr/>) og referanser (<xref>) til andre dokumenter. Pekere og referanser kan plasseres overalt i XML-filene.
Innenfor et enkelt dokument brukes <ref> når Ibsen selv har laget en sammenlenking mellom to tekststeder (f.eks. tilføyd tekst vha. referansetegn). <ptr> brukes når HIS av forskjellige hensyn ønsker å lenke sammen to tekststeder. Fordi <ptr>-koden i seg selv innebærer at det er HIS som har lenket sammen de to tekststedene, trengs ikke resp="editor" i <ptr>.
Referanser som er egne tekstelementer kodes med elementet <ref type="" target="">. Attributtverdien til target="" må korrespondere med et likelydende id=""-attributt til teksten det lenkes til.
kap-10.2.1: «Forts»/«Slutning» i føljetonger
<ref type="serialRef" target=""> legges i <docImprint> i <titlePage>. Attributtverdien er bygd opp av verksnummer + utgivelsesår + føljetongnummer og er den samme som i id="" i <text>.
<front>
<lb/><titlePage>
<docTitle>
<titlePart type="main">Kjæmpehøien.</titlePart>
<lb/><titlePart type="Desc">Dramatisk Digtning i een Act </titlePart>
</docTitle>
<byline>af <docAuthor><hi>Henrik
Ibsen</hi>.</docAuthor></byline>
<lb/>
<docImprint>
<ref type="serialRef" target="K21854-11">(Slutning fra forr. No.).</ref>
</docImprint>
<lb/><figure type="bar"></figure>
</titlePage>
</front>
Eksempel fra K2.
kap-10.2.2: Notereferanse
For alle to-veis referanser mellom note og notetegn eller mellom tilføyelse og tilføyelsestegn brukes <ref type="refMark" target="" id="">.
Det lages en kryssreferanse mellom notemarkøren og noten vha. av <ref>-elementet. Notetegnet i den fortløpende teksten, f.eks. «*», kodes med <ref id="nb+siffer" target="n+siffer">. Attributtverdiene til id="" og target="" i <ref> er bygget opp motsatt av verdiene til <note>. Se også «Forfatternoter - <note resp="author">».
<l>At holde mig en Hestelængde bagud for Tiden.<ref type="refMark" target="n1" id="n1b">*)</ref></l></sp> <stage>(de gaae.)</stage> (...) <l>Har her mig i Lunden et Stævne sat,</l> <note resp="narrator" place="bottom"><ref type="refMark" target="n1b" id="n1">*)</ref> Man vil bemærke at de Vers, der fremsiges afsides, ere anderledes byggede, end de, der maa høres af Alle og Enhver; dette er in­ genlunde nogen Skjødesløshed, men med Forsæt iagttaget, da vel underrettede Per­ soner ville vide, at vore politiske Skuespillere endog til Dagligbrug betjene sig af et særegent Versemaal, naar de tale afsides.</note>
Eksempel fra No. (linjeskiftkoding er fjernet)
kap-10.2.3: <div type="ref">
Der referansen ikke kan legges i eksisterende strukturelement legges det til et <div type="ref">-element.
<div type="ref"> <lb/><p><ref target="No1851-10">(Forts.)</ref></p> </div>
I HU finnes det referanser til tekster andre steder i dokumentet. Disse ser oftest slik ut: dikttittel + «Se s. XXX». Vi setter inn faktiske lenker ved slike referanser:
<div type="ref"> <lb/><p>><ref target="po22">Se nedenfor s. 352.<ref><p></p> </div>
Attributtverdien til target="" må korrespondere med et likelydende id=""-attributt til teksten det lenkes til.
kap-10.3: Sammenlenking – <join/>
<join/> brukes når to eller flere deler av en tekst skal lenkes sammen. Så langt har vi hatt bruk for å lenke sammen føljetongtekster, delte replikker, lemma som krysser strukturgrenser og komplekse tabeller.
kap-10.3.1: Føljetonger
Elementet <join targets="" targOrder=""/> knytter sammen <text id="">-elementene i <group>, som til sammen utgjør skuespillet og hvis id=""-attributtverdier er listet i targets="" i <join/>.
<join targets="No1851-9 No1851-10" targOrder="Y"/>
Kodeutdraget er hentet fra No.
Attributtet targOrder="" (med attributtverdiene «Y» («yes»), «N» («no») eller «U» («unspecified»)) i <join/> forteller om rekkefølgen av føljetongnumrene er den samme som den som er spesifisert i attributtet targets="".
kap-10.3.2: Delte replikker
<join targets="" targOrder=""/> knytter sammen to eller flere deler av en replikk som av en eller annen grunn er delt, men hvor delene fortsatt logisk sett hører sammen. Et typisk eksempel vil være at replikken må deles opp pga. strukturkollisjoner, men se også eksemplene nedenfor. Verdiene i targets="" hentes fra id=""-attributtene som legges inn i hver av replikkdelene.
<join targets="FOGDEN_1 FOGDEN_2" targOrder="Y"/> <lb/><sp who="FOGDEN" id="FOGDEN_1"><spOpener><speaker>Fogden</speaker>.</spOpener> [...]</sp> <lb/><sp who="FOGDEN" id="FOGDEN_2"><l>med dem, som intet har at bide.</l> [...]</sp>
Eksempel fra Br4262I11
<join targets="ROSMER_1 ROSMER_2" targOrder="Y"/>
<lb/><sp who="ROSMER" id="ROSMER_1"><spOpener><speaker>Rosmer</speaker>..
<note type="typo">to punktum</note></spOpener></sp>
<lb/><sp who="ROSMER"><p><del rend="overstrike">Me</del><gap/></p></sp>
<sp who="ROSMER" id="ROSMER_2"><spOpener><stage>(efter en kort
taushed.)</stage></spOpener>
<lb/><p>Mener du, at dette kan anvendes på mig?</p></sp>
Eksempel fra Ro41291 (replikken deles i to pga. ikke-strøket <gap/> i strykning som må inneholde strukturelementer)
Attributtet targOrder="" (med attributtverdiene «Y» («yes»), «N» («no») eller «U» («unspecified»)) i <join/> forteller om rekkefølgen av replikkdelene er den samme som den som er spesifisert i attributtet targets="".
kap-10.3.3: Lemma som krysser strukturgrenser
I hovedtekstene kodes lemma i <xref>-elemeneter. Dersom lemmaet krysser strukturgrenser må kodingen fragmenteres. Lemmaet kodes da i to eller flere <xref>-elementer som lenkes sammen ved hjelp av <join/>:
<salute><join targets="noteT12_674 noteT12_674a" targOrder="Y"/> <xref type="tcNote" id="noteT12_674" url="B1844-1871ht_noter.xml" from="noteT12_674"> <supplied><diacrit type="left"/>Deres hengivne</supplied></xref></salute> <signed><xref type="tcNote" id="noteT12_674a"><supplied>Henrik Ibsen<diacrit type="right"/></supplied></xref></signed>
Eksempel hentet fra B1844-1871ht.xml.
kap-10.3.4: Flertabellkodede innholdsfortegnelser
Flerspaltede innholdsfortegnelser som strekker seg over flere sider, kodes med en tabell for hver side (jf. «Retningslinjer for strukturkoding»). Tabellene lenkes sammen med <join>.
<join targets="t1 t2" targOrder="Y"/> <table id="t1"> (...) <lb/><row><cell role="data">Folkesorg</cell><cell role="filler"></cell><cell role="data">41.</cell></row> <lb/><row><cell role="data">Til thingmændene</cell><cell role="filler"></cell><cell role="data">44.</cell></row> <lb/><row><cell role="data">Hilsen til Svenskerne</cell><cell role="filler"></cell><cell role="data">47.</cell></row> <lb/><row><cell role="data">Til de genlevende</cell><cell role="filler"></cell><cell role="data">49.</cell></row> </table> <pb/> <table id="t2"> <lb/><row><cell></cell><cell></cell><cell role="label">Side</cell></row> <lb/><row><cell role="data">Til professor Schweigård</cell><cell role="filler"></cell><cell role="data">50.</cell></row> <lb/><row><cell role="data">Vuggevise</cell><cell role="filler"></cell><cell role="data">52.</cell></row> <lb/><row><cell role="data">Borte!</cell><cell role="filler"></cell><cell role="data">53.</cell></row> (...) </table>
Eksempel fra Digte.
kap-10.4: Innhenting av xml-filer – <xptr/>
Når xml-filer skal hentes inn i kommentar- og produksjonsfiler bruker vi
<xptr type="getFile" url="filnavn.xml"/>. Se kodepraksis for produksjonskoding for detaljert koding.
Når bilder og illustrasjoner skal hentes inn i kommentar- og produksjonsfiler bruker vi
<figure type="getFile" id="illus-[siffer]" entity="filnavn"></figure>. Se kapittel 3 i produksjonskoding for detaljert koding.
Lemma i hovedtekst og noten i notelisten lenkes sammen ved hjelp av <xref>-koding.
Lemma kodes med <xref type="tcNote" id="note[verk]_[siffer]" url="[verk]ht_noter.xml" from="[verk]_[siffer]">. Verdien i from="" viser til (og må være identisk med) verdien iid="" i <note> i notelisten. Verdien i <url> er navnet på notelistefilen.
Fra notelisten pekes det tilbake til lemma. Dette gjøres ved å legge <xref type="tcNote" url="[verk]ht.xml" from="note[verk]_[siffer]> rundt lemmaet i noten. Verdien i from="" viser til (og må være identisk med) verdien i id="" i <xref>-elementet som ligger rundt lemma i hovedtekstfilen.
For at kodingen skal valideres må det legges til en entitetsdefinisjon i dokumenttoppen både i hovedtekstfilen og i notelistefilen:
<!ENTITY % HIS_notelister SYSTEM 'http://www.edd.uio.no:8088/his/hjemmeside/dtd/notelister/HIS_notelister.ent' > %HIS_notelister;
kap-10.7: Pekere til andre tekstvitner
I F274 og KG er det kodet inn kryssreferanser mellom grunnteksten og trykkfeillisten til grunnteksten.
Til pekerne er elementet <xptr/> benyttet. Det inneholder attributtene id="", url="" og from="":
F274.xml: <xptr id="refB1" url="F281939.xml" from="ref1"/> F21939.xml: <xptr id="ref1" url="F274.xml" from="refB1"/>
Pekerne er hentet fra henholdsvis F274 og F281939.
id="" skal ha en unik verdi, som brukes til å lage kryssforbindelser med det dokumentet det lenkes til vha. attributtet from="" (se på sammenhengen mellom id="" i første eksempel og from="" i andre og motsatt). from="" angir hvilken id=""-attributtverdi pekeren går til. Attributtet url="" inneholder referansen til dokumentet det pekes til (verdien i url="" er den samme som filnavnet på måldokumentet).
I tillegg til denne kodingen, skal det settes inn en entitetsdefinisjon i toppen av dokumentet:
<!ENTITY % HIS_linking SYSTEM 'http://www.edd.uio.no:8088/his/hjemmeside/dtd/linking/HIS_linking.ent' > %HIS_linking;
kap-10.8: Lenking innenfor diktkoding
Innholdsfortegnelsen er kodet som en tabell. Lenker er kodet inn med <ptr/> der target="" korresponderer med id="" i diktet det lenkes til.
Koding av innholdsfortegnelse (eks. fra Di71.xml):
<div type="contents">
<lb/><head>INDHOLD.</head>
<lb/><figure type="bar"/>
<join targets="t1 t2" targOrder="Y"/>
<table id="t1">
<lb/><row><cell></cell><cell></cell><cell role="label">Side</cell></row>
<lb/><row><cell role="data">Spillemænd</cell><cell role="filler"></cell>
<cell role="data">1.<ptr type="contents" target="DiSpillemaend"/></cell></row>
...
Dikt det lenkes til (eks. fra Di71.xml, forenklet koding):
<div type="poem" id="DiSpillemaend">
<lb/><head type="main">Spillemænd.</head>
<lb/><figure type="bar"/>
<lb/><lg type="strofe"><l>Til hende stod mine tanker</l>
<lb/><l>hver en sommerlys nat;</l>
...
kap-10.8.2: Oppsplittede dikt
Ved oppsplittede dikt (som forekommer i noen av arkivfilene til Digte-manuskriptene pga feil i innbindingen) identifiseres diktdelene med attributtverdiene id="" (første del av diktet), corresp="" og part="":
<div type="poem" corresp="DiFredSyvMinde" part="F">
<lb/><lg type="strofe"><l>Thi han lever stærk i mindet,</l>
<lb/><l>Danmarks danske drot, –</l>
<lb/><l>kongemod i folkesindet</l>
<lb/><l>vidner det så godt.</l>
<lb/><l>Derfor frem til sandheds-sejren!</l>
<lb/><l>Fredrik er i danskelejren; –</l>
<lb/><l>Slaven, Venden og Kroaten</l>
<lb/><l>slår ej landsoldaten!</l></lg>
</div>
I attributtet part="" benyttes verdiene I om første del, M om midtre del og F om siste del. Dersom det er flere midtre deler nummereres disse med attributtet n="":
<div type="poem" id="DiFredSyvMinde" part="I"> <div type="poem" corresp="DiFredSyvMinde" part="M" n="1"> <div type="poem" corresp="DiFredSyvMinde" part="M" n="2"> <div type="poem" corresp="DiFredSyvMinde" part="F">
Dersom et manuskript inneholder flere versjoner av et dikt nummereres id-verdiene:
<div type="poem" id="DiTroensGrund1" part="Y"> <div type="poem" id="DiTroensGrund2" part="I"> <div type="poem" corresp="DiTroensGrund2" part="F"> <div type="poem" id="DiTroensGrund3" part="Y">
kap-10.8.2.1: Lenking mellom diktdeler
For oppsplittede dikt legger vi inn lenker og forklarende utgivertekst mellom diktdelene (her fra Di41110b):
<div type="poem" corresp="DiRimbrevFruHeiberg1" part="M" n="2" hand="HI-2" id="DiRBfH1b"> <note resp="editor">Til foregående del av diktet «Rimbrev til fru Heiberg». <ptr type="part" target="DiRBfH1a"/></note> <lb/><l rend="indent2">og så friste</l> <lb/><l rend="indent2">uden spor</l> <lb/><l>hænders værkers lod på jord.</l> ... <lb/><l rend="indent2">svanehammen</l> <note resp="editor">Til fortsettelsen av diktet.<ptr type="part" target="DiRBfH1c"/></note> </div>
Alle diktdelene trenger egne id="" for å kunne lenkes sammen. Det er viktig at ikke identiske id-verdier forekommer i fila. Her er verdiene satt sammen av en forkortelse av tekstkildebetegnelsen + versjonsnummer + bokstaver for hver diktdel.
For å gjøre det enklere å orientere seg i fila (både for leserne og for de som arbeider med fila), er det lagt til forklarende utgivernoter som identifiserer diktet og viser hvor lenkene fører.
kap-10.8.3: Dikthenvisninger
Dikthenvisninger kodes på litt ulik vis avhengig av tekststrukturen.
kap-10.8.3.1: Dikthenvisninger med titler
I trykkmanuskriptet til Digte (Di42622, faksimileside 53) har Ibsen satt inn dikttitler på riktige steder og opplyst om status til tekstene. Dette er kodet slik i <div type="ref">:
<div type="ref"> <lb/><head type="main">Hilsen til Svenskerne.<ptr type="ref" target="DiHilsenTilSvenskerne"/></head> <lb/><head type="sub">(I Trondhjem ved kroningen.)</head> <lb/><p><note resp="author" place="inline">NB! skal senere blive sendt!</note></p> </div> <lb/><figure type="bar"/>
Diktet er senere lagt ved manuskriptet og lenket til med <ptr/>.
kap-10.8.3.2: Enklere henvisninger
I Jakob Løkkes samling av avskrifter av trykte Ibsendikt (Di41110a, faksimileside 10) har avskriveren gjort oppmerksom på at en annen versjon av diktet forekommer annetsteds i manuskriptet. Dette er gjort ved et referansetegn fra tittel til note nederst på siden som viser videre til sidetallet for den andre versjonen. Dette er kodet slik:
<div type="poem" id="DiKongHaakonsGildehal"> <lb/><head type="main">4. Kong Haakons Gildehal. <ref type="refMark" id="nb1" target="n1">&referenceMark;</ref></head> <div type="section"> <lb/><head>I.</head> <lb/><lg type="strofe"><l>Du gamle Hal med de Mure graa,</l> ... <lb/><l>Omkring din graanende Tinde.</l></lg> <lb/><figure type="num"/> <lb/><note resp="author" place="bottom-left"> <ref type="refMark" id="n1" target="nb1">&referenceMark;</ref> S. s. 14.<ptr type="ref" target="DiKongHaakonsGildehalFortDigt"/></note>
Den andre versjonen av diktet er kodet slik, med tilhørende id-verdi:
<div type="poem" id="DiKongHaakonsGildehalFortDigt">
<lb/><head type="main">8. Kong Haakons Gildehal,</head>
<lb/><head type="sub">fortællende Digt.</head>
<lb/><head>II.</head>
<lb/><lg type="strofe"><l>De holdt en Fest i Bergens By;</l>
...
kap-10.9: Koding for synoptiske versjonsvisninger
kap-10.9.1: Grunnlagskoding – <pb ed="hu"/>
Som grunnlag for å kunne koble sammen alle tekstkilder i synoptiske visninger i HISe, koder vi inn sideskiftene til Hundreårsutgaven i alle tekstkilder (foreløpig med unntak for rolleheftene).
<pb ed="hu"/>
Første <pb ed="hu"/>-element skal inneholde første sidetall i et n=""-attributt for at innsettingen av resten av sidetallene skal kunne gjøres automatisk.
Første <pb ed="hu"/>-element settes inn på det punkt hvor sammenlikningen av teksten i de to kildene skal begynne, dvs. vanligvis etter Hundreårsutgavens tittelsidefaksimile. Synkroniseringa skal med andre ord begynne ved den første siden som er transkribert og kodet som tekst i begge tekstkilder.
Elementet plasseres uten hensyn til annen koding. Elementet settes rett inn i ord uten typografiske bindestreker. Mellom ord plasseres det fortrinnsvis foran den blanke (mellomrommet blir med andre ord stående).
I manuskriptmateriale som skiller seg svært fra Hundreårsutgavens tekst plasseres sideskiftelementene så godt det lar seg gjøre. Filologene ser gjerne på spesielt vanskelig steder. Vi kan måtte finne andre måter å synkronisere tekstene på hvis forskjellene er uoverstigelig store. I slike manuskripter kan det være en fordel å legge inn n=""-attributt i <pb/>-elementene med det samme, siden man kan få tilfeller hvor det er umulig å identifisere enkelte sideskift innimellom de lokaliserbare. Slike «manglende» sideskift medfører at man ikke kan nummerere <pb/> automatisk i etterkant.
I manuskripter hvor flere forminger av samme tekst følger hverandre (og automatisk påføring av sidetall senere derfor blir vanskelig/umulig), skal man legge inn sidetallene fra Hundreårsutgaven med det samme. Sidetallene legges da i n=""-attributtet. Dette er f.eks. gjort i manuskriptmaterialet til Episk Brand (BE42869).
Uansett om referansene legges inn med eller uten n=""-attributt, skal man lage en <tagUsage gi="pb-ed-hu">/<tagUsage gi="pb-ed-hu-n">-innførsel i <tagsDecl> i <teiHeader> om hvordan HU-referansene er kodet, se «<tagUsage gi="pb-ed-hu">/<tagUsage gi="pb-ed-hu-n">». <tagUsage gi="pb-ed-hu">/<tagUsage gi="pb-ed-hu-n">-innførselen fjernes etter at <pb-ed="HU"/>-kodingen er erstattet med <synopticViewPtr/>-elementer.
kap-10.9.2: Generelt om synoptiske visninger
I HISe skal det være flere slags synoptiske visninger:
- hovedversjon mot hovedversjon (på grunntekstnivå), f.eks. C150 <–> C275
- grunntekst mot ms-tekstkilder som avviker så mye at variasjon ikke kan vises vha. variantapparat, f.eks. C150 <–> C14936 delt i tre versjonsfiler
- grunntekst mot trykk og trykkmanuskript som det p.g.a. tidsmangel ikke er kodet eksterne varianter i, f.eks. PG
- manuskripttekstkilder med flere skriveomganger, f.eks. Vi41115b
Kodingen av koblingene i disse forskjellige visningene blir beskrevet i avsnittene nedenfor.
kap-10.9.3: Synoptisk visning av hovedversjoner
For å klargjøre ulike hovedversjoner til samme verk for synoptisk visning, kan man basere seg på <pb ed="hu"/>-kodingen i en av hovedversjonene og legge inn parallelle punkter i de/n andre hovedversjonen/e. Denne innleggingen vil når formuleringene/teksten i de/n andre hovedversjonen/e avviker, være skjønnsbasert.
kap-10.9.3.1: Koding
Den gamle <pb-ed="HU"/>-kodingen erstattes med <synopticViewPtr/>-elementer etter at det vha. skript er lagt inn nummererte n-attributter i <pb-ed="HU"/>. <synopticViewPtr/>-elementene skal inneholde type-attributt med verdien «synopticView_mainVersions», url="" med navnet på filen det skal synkroniseres mot, og til slutt også en unik verdi i id-attributtet, slik at de to synkrone punktene kan lenkes opp mot hverandre. Verdien i id er bygd opp av verksbetegnelsen til en av de hovedversjonene som skal synkroniseres, «underscore», samt et tall (tallet vil ofte tilsvare <synopticViewPtr/>-elementets nummer i rekken av <synopticViewPtr/>-elementer i filen, siden man bruker skript til å nummerere <pb ed="hu"/>-elementene) pluss «main» rett etter tallet («main» er lagt til for å sikre unik verdi). Verdien i id skal være den samme i de filene som lenkes sammen. Nedenfor er et eksempel på kodingen:
I HH58: <synopticViewPtr type="synopticView_mainVersions" url="HH81935.xml" id="HH1_1main"/>
I HH81935: <synopticViewPtr type="synopticView_mainVersions" url="HH58.xml" id="HH1_1main"/>
kap-10.9.3.2: Eksempel: OL
Det er bestemt i HIS at disse tre skal lenkes sammen sånn at man kan sammenlikne to og to hovedversjoner; OL1 – OL2, OL1 – OL3, OL2 – OL3.
Slik bør kodingen settes opp:
I OL1 <synopticViewPtr type="synopticView_mainVersions" url="OL2.xml" id="OL1_1main"/> <synopticViewPtr type="synopticView_mainVersions" url="OL3.xml" id="OL3_1main"/> I OL2 <synopticViewPtr type="synopticView_mainVersions" url="OL1.xml" id="OL1_1main"/> <synopticViewPtr type="synopticView_mainVersions" url="OL3.xml" id="OL2_1main"/> I OL3 <synopticViewPtr type="synopticView_mainVersions" url="OL1.xml" id="OL3_1main"/> <synopticViewPtr type="synopticView_mainVersions" url="OL2.xml" id="OL2_1main"/>
Det gir nemlig følgende sammenlenkinger:
OL1-OL2 (url="OL2.xml" id="OL1_1" + url="OL1.xml" id="OL1_1main" kobles sammen) OL1-OL3 (url="OL3.xml" id="OL3_1" + url="OL1.xml" id="OL3_1main" kobles sammen) OL2-OL3 (url="OL3.xml" id="OL2_1" + url="OL2.xml" id="OL2_1main" kobles sammen)
kap-9.3.3: Når tekst ikke finnes i en av versjonene
Det legges bare inn pekere der begge tekstkilder har parallell tekst.
Eksempel: C150 har et etterord som ikke er med i C2. C2 har et forord som ikke finnes i C150. Det legges ikke inn pekere i disse tekstdelene.
Det er ønskelig med en editor-note som opplyser om manglende tekst - det må avklares hvordan vi gjør dette mest hensiktmessig.
Manuskripttekstkilder skal også presenteres i synoptiske visninger slik at man kan studere tilblivelses-versjonene til et verk. Her vil mye av kodingen være skjønnsbasert siden teksten/utformingen i de forskjellige tekstkildene kan avvike en del fra hverandre. Vi har bestemt at vi splitter et manuskript i to eller flere filer hvis manuskriptet (som i første omgang er kodet som en fil) inneholder flere versjoner av samme tekst. Det vil da være enklere å lage synoptisk visning av filene.
For de verkene der vi ikke rekker å kode inn eksterne varianter, lager vi synoptisk visning av alle trykte tekstkilder samt trykkmanuskript. I denne visningen er ingen varianter markert individuelt, men filene er koblet sammen slik at man kan sammenlikne teksten manuelt.
Kodingen er lik for synoptisk visning av manuskripttekstkilder og trykk. De samme koblingspunktene kan benyttes.
kap-10.9.4.1: Koding
Koblinger for disse visningene skal legges inn i grunntekst, alle forutgående manuskripter og alle trykk. Den gamle <pb-ed="HU"/>-kodingen erstattes med <synopticViewPtr/>-elementer for sammenlikning av tekstkilder (etter at det vha. skript er lagt inn nummererte n-attributter i <pb-ed="HU"/>).
<synopticViewPtr/>-elementene skal inneholde type-attributt med verdien «synopticView_textWitnesses», samt en unik verdi i id-attributtet, slik at de synkrone punktene kan lenkes opp mot hverandre. Verdien i id er bygd opp av verksbetegnelsen, «underscore», samt et tall (tallet vil ofte tilsvare <synopticViewPtr/>-elementets nummer i rekken av <synopticViewPtr/>-elementer i filen, siden man bruker skript til å nummerere <pb ed="HU"/>-elementene) pluss «ms» rett etter tallet («ms» er lagt til for å sikre unik verdi). Verdien i id skal være den samme i alle de filene som lenkes sammen. Nedenfor er et eksempel på kodingen:
<synopticViewPtr type="synopticView_textWitnesses" id="C1_1ms"/>
kap-10.9.4.2: Når tekst ikke finnes i en av filene
Det legges bare inn pekere der begge tekstkilder har parallell tekst.
C14936 har ikke mellomtittelblad slik C150 har. Det er følgelig ikke lagt inn peker fra C150 til C14936 her.
C14936 mangler slutten av dramaet og inneholder heller ikke etterordet som C150 har. Det er følgelig ikke lagt inn pekere på slutten av C150.
Det er ønskelig med en editor-note som opplyser om manglende tekst - det må avklares hvordan vi gjør dette mest hensiktmessig.
For alle de synoptiske visningene ovenfor gjelder at man kan komme over tilfeller hvor det er vanskelig å finne parallelle punkter, og hvor man derfor må plassere pekerne etter skjønn.
I arbeidet med sammenlenking av manuskripttekstkilder kan man også støte på liknende problemer, siden teksten her ofte kan skille seg veldig fra HIS' grunntekst. Da skal imidlertid lenkingen legges på <div>-nivå, slik at f.eks. versjoner av tekst til samme akt kobles sammen. Dermed blir det mulig å studere tilblivelse (om enn ikke i kronologisk rekkefølge, så høye ambisjoner har vi ikke).
Hvis to <synopticViewPtr/>-elementer blir liggende for nær hverandre (siden de som legges inn vha. <pb ed="hu"/>-kodingen havner litt tilfeldig i forhold til de øvrige tekstkildenes sideoppsett), er det tillatt å flytte på <synopticViewPtr/>-elementer og evt. også å slette <synopticViewPtr/>-elementer, slik at mellomrommet mellom koblingene blir mer hensiktsmessig.
Hvis det blir nødvendig å legge til nye <synopticViewPtr/>-elementer, får man følge malen for attributtverdier, slik at man sørger for å lage en unik attributtverdi. Når man gjør denne typen justeringer i <synopticViewPtr/>-kodingen er det viktig å sørge for at samme punkt i et sett filer, inneholder samme unike attributtverdi i id=""-attributttet.
kap-11: Manuskriptkoding
kap-11.1: Retningslinjer
Retningslinjene for kodingen av manuskripter kan deles inn i tre områder:
- koding av struktur: «normalisering»
- tyding av skrift: skjønn
- koding av endringer: integrert gjengivelse, tilnærmet diplomatarisk
kap-11.1.1: Koding av struktur: «normalisering»
kap-11.1.1.1: Paratekst
Når vi koder inn tekststrukturen i et håndskrift kan man si at vi foretar en viss «normalisering» av tekstorganiseringen. F.eks. ordner vi sideoppsettet slik at det har identisk struktur på alle sider: All paginering og foliering plasseres øverst på siden på egen linje selv om den i virkeligheten kan være plassert side om side med første linje eller kanskje tom. være skrevet med så store siffer at den spenner over to linjer tekst (det samme gjelder for paginering nederst på siden). Nummerering av forskjellig art plassert i hvert sitt hjørne øverst på siden, plasseres på samme linje selv om dette ikke nødvendigvis er helt i overenstemmelse med originalens plassering av dem (så fremt det ikke er veldig åpenbart at de bør plasseres på forskjellige linjer).
Slik ordning av sideoppsettet har ikke konsekvenser for selve teksten etter som paginering og foliering tilhører det vi har definert som paratekst. Den originale og nøyaktige plasseringen på siden kan brukeren studere i faksimilene.
kap-11.1.1.2: Tekstelementer
Vi gjør noe av det samme med andre typer strukturelementer som inngår i teksten, nemlig avgrensning av overskrifter (<head>), retorisk utheving (<emph>), rollenavn (<speaker>, <stageRole>), sceneanvisninger (<stage>) osv. Vanligvis vil tekstelementet være markert på flere måter (typografisk; rollenavn står midtstilt på siden og på egen linje, ofte understreket) og sammenholdt med det tekstlige innholdet vil det sjelden være tvil om hva slags tekstelement det dreier seg om.
Manuskripter er håndskrifter og preges av menneskelig unøyaktighet. Alt som er ment markert, er ikke nødvendigvis markert (gjelder særlig understreking). Siden det vi skal gjøre er å lage en ordnet struktur av teksten, bruker vi skjønn (sunn fornuft kan man kanskje også si) og koder tekstbiter som vi oppfatter (tolker) som sammenhengende strukturelle enheter innenfor samme strukturelementer. Her er et enkelt eksempel på koding av et retorisk uthevet ord.
En sekvens som dette (fete deler illustrerer understreking):
understreket tekst
kodes slik:
<emph>understreket tekst</emph>
og ikke slik:
u<emph>nderstreke</emph>t <emph>teks</emph>t
I de fleste tilfeller støttes selvfølgelig fortolkningene våre av andre typografiske markører: overskrifter er gjerne midtstilt og skrevet med større skrift e.l., sceneanvisninger er omsluttet av parenteser osv. Dette er ikke tilfelle med retorisk utheving og <stageRole>, derfor har vi eksplisitte/klarere retningslinjer for kodingen av disse tekstfenomenene. Vi behandler også strykninger etter egne retningslingjer, se Slettet tekst.
kap-11.1.2: Tyding av skrift: skjønn
Også her har vi vedtatt at det å bruke sunn fornuft i forhold til å lese og transkribere bokstaver man ikke kan skjelne i et ord, men som man likevel ut fra resten av bokstavene samt konteksten må anta at er et bestemt ord, er helt i orden. Et klassisk eksempel er at det er unødvendig å bruke <unclear>/<gap/>-elementer på deler av ord som f.eks. «kommer», hvor «mmer» kun er en kort, bølget strek. Her er det lov å transkribere hele ordet uten markering av uklarhet, hvis det ikke er reell tvil om lesningen av ordet.
Vi transkriberer med andre ord den skrivemåten vi vanligvis finner i manuskriptet selv om vi ikke tydelig kan skjelne bokstavene i det ordet vi har vanskelig for å tyde. Det samme gjelder transkribering av tegn som mangler diakritiske tegn, særlig «å», «i» og «ø», se mer om transkripsjonsnormalisering i detaljkapitlet.
For å si det litt forenklet; vi antar at skriveren har skrevet ordet riktig/ på sin vanlige måte og transkriberer deretter. Jf. forøvrig Uklar tekst – <unclear>.
Når det gjelder koding av rettelser er målet for kodearbeidet en visning med integrert gjengivelse av endringene, dvs. at endringene vises i den løpende teksten, ikke i et noteapparat. Vi forsøker å fortolke så lite som mulig, og vi gjør heller ikke forsøk på å gjenspeile skapelsesprosessens trinn i kodingen.
Kodingen vår skal derfor i henhold til denne retningslinjen, gi et beskrivende bilde av manuskriptet.
Vi overlater til brukeren å analysere tid, rekkefølge osv. i endringene på grunnlag av det bildet som kodingen vår gir av dem.
kap-11.1.4: Retningslinjene sett under ett
Målet for kodingen er: Teksten skal legges til rette for brukeren, vi skal lette brukerens videre arbeid med tekstene, og dette gjøres best ved 1) å ordne den underliggende teksten slik at struktur og typografi er lett forståelig samt 2) ved å gi et så enkelt og rett fram bilde av endringene som overhodet mulig. For både 1) og 2) gjelder det at vi skal innføre så lite fortolkning med kodingen som mulig.
Ved siden av å skulle være til hjelp ved koding av manuskripttyper som er ukjent for den som koder, er dette kapitlet også en oversikt over materialtypene og en dokumentasjon av løsningene vi har valgt. Kapitlet er delt inn i underkapitler, det første inneholder generelle retningslinjer for typologisering og organisering av manuskriptfiler, og de tre neste bolkene følger skillet mellom notat, arbeidsmanuskript og endelig manuskript. De siste kapitlene inneholder koding av diverse spesialtilfeller innen både trykket og håndskrevet materiale.
I kapitlet omtales bare koding som er spesiell for den omtalte materialtypen. Materialtyper som ikke krever egen koding blir dermed ikke omtalt her. Retningslinjer for kodingen av disse finnes i de generelle kapitlene.
kap-11.2.1: Overordnede prinsipper
Hvordan manuskriptmaterialet er organisert på biblioteket er ikke avgjørende for hvordan HIS til slutt ordner manuskriptene i utgaven. Dersom vår ordning avviker fra bibliotekets, beholder vi en arkivutgave av manuskriptet for å dokumentere bibliotekets ordning.
HIS kan velge å se bort fra den rekkefølgen materialet har i bokbindet eller mappen på biblioteket. Bokbindet er nærmest å betrakte som emballasje, som om de var en eske som manuskriptene var lagt i. Det avgjøres fra materiale til materiale hva som er fornuftigst å gjøre. Her er noen generelle retningslinjer:
- arkivutgaver (tekster som skal presenteres i tekstarkivet) skal transkriberes og kodes i den rekkefølge materialet har på biblioteket. De gis filnavn som viser at de dokumenterer bibliotekets ordning, f.eks. Hv-Ro41291ab_NBO.xml.
- materiale som hører til forskjellige verk og sjangre skilles deretter ut ; f.eks. hentes brev(-kladder) og varia som er gjort i dramamanuskripter, ut av manuskriptet og etableres i egne filer, materiale til forskjellige drama splittes også opp, jf. NBO Ms.8° 1937a som inneholder UF81937a og KG81937a
- et innbundet materiale holdes samlet i arkivutgaven; etter vurdering av praktisk nytte kan imidlertid også dette splittes opp . Bibliotekets ordning skal imidlertid dokumenteres slik at materialet kan presenteres samlet i tekstarkivet
- splitting av innbundet materiale i flere filer når materialet skal presenteres i synoptiske visninger, kan foretas etter vurdering av praktisk nytte
- materiale med bokstavspenn i signaturen, kan hvis det er av praktisk nytte splittes i en fil for hver bokstav, jf. NBO Ms.4° 1109a-b
- materiale som ikke er bundet sammen, kan deles opp allerede fra starten av. Bibliotekets ordning skal imidlertid dokumenteres slik at materialet kan presenteres samlet i tekstarkivet
kap-11.2.1.2: Ordning vha. type="" i <text>
Alle manuskript skal typologiseres. Typologiseringen hviler på definerte kriterier og skiller mellom ulike teksttyper. Her er en oversikt over prosjektets manuskriptbetegnelser:
- notat
- tekstversjon
- arbeidsmanuskript
- endelig manuskript
- endelig renskrift
- trykkmanuskript
- scenemanuskript
- sufflørbok
- rollehefte
I denne sammenhengen får disse betegnelsene størst betydning: notat, arbeidsmanuskript og endelig manuskript.
Typologiseringen legges i type="" i <text> og bestemmer den overordnede strukturen i filen. Et manuskript som består av en enkelt manuskript-type, kodes i ett <text>-element, mens et manuskript som består av flere manuskript-typer, kodes som en <text>-<group>-<text>-struktur.
<text> <group> <text type="notes"></text> <text type="workingManuscript"></text> <text type="finalManuscript"></text> </group> </text>
Typologiseringen gjøres i <msDescription> i <teiHeader> når manuskriptet bare inneholder en manuskripttype.
NB: Et manuskript bestående av bare en enkelt manuskript-type kan ordnes som en <text>-<group>-<text>-struktur hvis manuskriptet inneholder tekst fra mer enn en genetisk omgang. Det er likevel tilstrekkelig om typologiseringen bare gjøres i <msDescription>.
kap-11.2.1.3: Videre ordning, <text> eller <div>?
Her er retningslinjene for når man skal bruke <text> og når man skal bruke <div>.
- Det skal opprettes et nytt <text>-element når man kan skille genetisk mellom forskjellige deler av manuskriptet
- For å avgjøre hvorvidt man skal påbegynne et nytt <text>-element skal man studere eventuelle endringer i papirtype, blekk, skriftstil og lignende. Skillet bør være tydelig, og bør helst støttes av flere indisier. Skifte av innholdsmessig art alene genererer ikke et nytt <text>-element. En og samme manuskriptside kan transkriberes i flere <text>-elementer dersom noe tilsier at man kan skille genetisk mellom forskjellige deler av siden
- Det skal opprettes et nytt <div>-element når man kommer til en ny overskrift eller bestemmer at teksten er en overskrift
- Det skal opprettes et nytt <div>-element ved markert innholdsmessig strukturendring i teksten, det vil si når to deler av teksten ikke henger sammen innholdsmessig
Ro41291, side 244 kan tjene som eksempel på to genetisk ulike tekster på samme side. Første del av siden er skrevet med brunsort blekk, nederste del (etter skillestreken) med blyant. Skriftkvaliteten og størrelsen er også klart forskjellig. Første del av siden består av replikkveksling; andre del (etter skillestreken) er en enkeltreplikk. Her er faksimilen av siden:

Hver del kodes altså i et eget <text>-element. Attributtet hand="" inkluderes i <text> slik at den nye hånden blir kodet inn. Tilføyelsen denne hånden har gjort i teksten ovenfor på siden («nu straks»), kodes som vanlig med <add place="" hand="">.
FH41116, side 10 kan tjene som eksempel på hvor skillet mellom to <div>-elementer på samme side går. Første del av siden består av replikkvekslinger; andre del (etter skillestreken) ser ut til å være tanker og små utkast til slutten på første akt. Her er det brukt samme blekk, det er ikke noe påfallende skille i skriftkvalitet og heller ikke noe iøynefallende forskjell i oppsettet på siden. Det er altså neppe noe genetisk skille mellom de to delene. De skal derfor kodes i hvert sitt <div>-element. Her er faksimilen av siden:

kap-11.2.1.4: Ordning vha. av type="" og n="" i <div>
Innholdet i manuskriptet skal ordnes typologisk vha type="" og, om mulig, knyttes til rekkefølgen i grunnteksten vha n="".
kap-11.2.1.4.1: Ordning vha. av type=""
Alle <div>-element skal inneholde type-attributt. Følgende attributtverdier er vedtatt og definert for de overordnede nivåene:
- act: brukes med attributtet n="". Brukes til å kode tekst som vi kan klassifisere som tilhørende en bestemt akt i grunnteksten. Se for øvrig Ordning vha. n="".
- relatedToWork: til verksrelatert materiale, dvs. materiale vi ikke kan eller vil klassifisere mer detaljert, men som vi kan knytte til verket. Brukes f.eks. til overordnet typologisering av sceneutkastene i C14936
- paratext: til ikke-verksrelatert tekst, men f.eks. tekst knyttet til dokumentet. Brukes f.eks. til Ibsens dedikasjon til Hildur Andresen på arbeidsmanuskriptene til Rosmersholm (se Konvolutter - Ro41291) og Bygmester Solness.
- castList: til forstadier til rollelister eller tekst som ligner rollelister, men som ikke kan endelig defineres som dette. Se også Rolleliste (<castList>) eller vanlig <list>?.
kap-11.2.1.4.2: Ordning vha. n=""
n-attributtet skal bare brukes sammen med type-attributtverdiene «act» og «scene». I n-attributtet bruker vi nummereringen av akter og scener i grunnteksten, altså det vi regner for den endelige utformingen av verket. Nummereringen gjøres med sifre; 1, 2, 3 osv. Det eneste unntaket fra denne nummereringen er KGs to femaktere, hvor første del nummereres 1-1 ... 1-5 og andre del nummereres 2-1 ... 2-5. Ibsen går etter hvert bort fra sceneinndeling, så dette vil man sjelden støte på.
Når manuskriptet er delt inn i en fra førstetrykket avvikende struktur, koder vi denne strukturen, men relaterer den i attributtverdier til den endelige utformingen.
Vi bruker <div> med type="" og n="" selv om det bare er snakk om et kort utdrag fra en akt.
Når tekst er flyttet fra en akt til en annen mellom et manuskript og den endelige utformingen bruker vi nummereringen i den endelige utformingen i n-attributtet. Når tekst er flyttet fra en akt og fordelt på to andre akter mellom et manuskript og neste/ den endelige utformingen, bruker vi også nummereringen i den endelige utformingen i n-attributtet, men legger numrene til begge aktene i n-attributtet. Her er et eks. på det siste fra FH41116. I utkastet til scenegang (s. 9 og s. 12) er dramaet strukturert i 4 akter, mens det i førstetrykket er inndelt i 5 akter. Selv om det ikke stemmer helt overens med handlingsgangen i førstetrykket kan man grovt sett si at skissen over akt 3 nedenfor blir til de endelige akt 3 og 4, mens skissen til akt 4 nedenfor blir til akt 5 i førstetrykket.
<text type="workingManuscript"> <body> <pb n="12"/> <div type="act" n="3 4"> <lb/><head>3<hi rend="raised">dje</hi> akt.</head> <lb/><p>Denne akt foregår i den afsides liggende del af ha&typHyp; <lb/>ven<del rend="overwritten">.</del>med brygge og badehus. Thora opholder sig der. <lb/>Wangel kommer til hende. Derefter Hesler. Så en&typHyp; <lb/>delig Lyngstrand. Stor nyhed! Amerikaneren er <lb/>her! Han har set ham! ‐ Optrin mellem Thora og John&typHyp; <lb/>son. Hvad havet har sammenføjet skal ikke menne&typHyp; <lb/>sker adskille. Wangel kommer. Genkender Ameri&typHyp; <lb/>kaneren som styrmanden, der slog kaptejnen <lb/>ihjæl. Beråber sig på Thoras <del rend="overwritten"><gap/></del>udsagn. Hun. <q type="speech" who="ELLIDA">Nej <lb/>nej.</q> Nægter alt. Johnson går: <q type="speech" who="DENFREMMEDE">Ja, så får du gøre <lb/>dig rejsefærdig da, Thora.</q></p> </div> <div type="act" n="5"> <lb/><head>4<hi rend="raised">de</hi> akt.</head> <lb/><p>Samme sted. Nu kommer opgø<unclear reason="writing">e</unclear>t mellem <lb/>Wangel og Thora. Hesler kommer tilstede. Wan&typHyp; <lb/>gel indvilger i Thoras rejse. Gir afkald på hen&typHyp; <lb/>de.</p> </div> </body> </text>
Kodet eksempel fra FH41116, s. 12

Tilfellet over gjelder små mengder tekst, og det er i slike tilfeller denne typen koding i n="" er nyttig. Når det er snakk om en mindre del i en større tekst, f.eks. en scene i en akt, og denne delen ikke er kodet som egen strukturell enhet (f.eks. i <div>), skal vi ikke bruke n="".
Tekst/handling/innhold som ikke føres videre til den endelige utformingen av akten får ingen egen/spesiell koding når den inngår som del av annen tekst, mao. når den ikke utgjør en egen strukturell enhet (i så fall kodes den med verdien "relatedToWork").
kap-11.2.2: Notater
kap-11.2.2.1: Generelt
Prosjektets manuskriptbetegnelse er notat, et notat er «et manuskript som inneholder nedtegnelser til bruk i et verk. Teksten kan være tenkt til eget bruk og er ikke formet i f.eks. strofer eller replikker, kanskje heller ikke i fulle setninger, og utformingen kan ikke sees å inngå i noen kjent versjon av verket» (sitert fra prosjektets interndokument «Behandling av manuskripter i HIS»). Notat står i motsetning til tekstversjon. En tekstversjon «inneholder et verk eller deler av et verk i sin endelige form eller på et tidligere stadium i den dikteriske prosess» (sst.) og omfatter arbeids- og endelige manuskripter, jf. «Arbeidsmanuskripter» og «Endelige manuskripter» .
Eksempler på materiale som typologiseres som notat:
- lister over kildemateriale
- trykkfeillister
Eksempler på materiale som ikke typologiseres som notat:
- utkast til scenegang, jf. f.eks. utkastene i C14936
- utkast, f.eks. til replikker, som gjenfinnes i det ferdige dramaet
Attributtverdien for notat er «notes».
kap-11.2.2.2: «Huskelister»
Ibsen har skrevet «huskelister» over kilder og stoff han har forholdt seg til i arbeidet med Kejser og Galilæer (listene finnes i NBO Ms.4° 1111). Disse listene regnes som notater. Strykningene i disse listene har vi vedtatt å kode som vist nedenfor:
<del type="checkList" rend="overstrike"> Strøket innførsel i Ibsens huskeliste</del>

kap-11.2.2.3: Trykkfeillister
Trykkfeillister regnes også som notater.
Trykkfeillisten til Fru Inger til Østråt, NBO Ms.8° 1939, er kodet som andre lister, jf. Trykkfeillister i strukturkapitlet. Det er lagt inn <synopticViewPtr/>-elementer som synkroniserer trykkfeillisten med (trykkfeilene i) førstetrykket. Kodingen av dette er omtalt i Pekere til andre tekstvitner i kapitlet om lenking.
kap-11.2.3: Arbeidsmanuskripter
kap-11.2.3.1: Generelt
Arbeidsmanuskript er prosjektets manuskriptbetegnelse for «uferdig tekstversjon. Det kan være utkast til strofer, replikker, scener, større deler eller fullstendig tekst, i kladdeform eller renskrevet, men teksten befinner seg på et stadium før det endelige» (sitert fra prosjektets interndokument «Behandling av manuskripter i HIS»). Arbeidsmanuskript er stadiet mellom notat og endelig manuskript .
Attributtverdien for arbeidsmanuskript er «workingManuscript».
kap-11.2.3.2.1: Rolleliste (<castList>) eller vanlig <list>?
Rollelistekoding brukes når:
- Listens innhold ligger tekstlig nært rollelisten i andre/mer ferdige manuskripter og/eller grunntekst
- Listers struktur indikerer ferdig formet/midlertidig rolleliste (listen inneholder f.eks. også en setting), selv om personene ikke er (helt) de samme som i det endelige skuespillet
Vanlig listekoding (evt. tabeller), evt. i <div type="castList">, brukes når:
- Listens innhold ikke kan gjenkjennes i det øvrige materialet (med unntak for lister hvis struktur – inkl. f.eks. <set> – peker mot en ferdig formet rolleliste)
- Listen ikke inneholder (alle endelige) navn, men bare en betegnelse samt lengre/lange beskrivelser av rollen i form av Ibsens konseptuelle forståelse av karakteren
kap-11.2.3.2.2: Replikker (<sp> eller <q type="speech">)
Nedenfor følger kriterier for hvordan man bestemmer hva som er replikktekst i HIS samt diskusjon av kriteriene.
- Dramaoppsett kontra prosaoppsett
-
Til en viss grad vil man kunne bruke et overordnet skille mellom dramaoppsett og prosaoppsett til å avgjøre om man skal kode replikkteksten(e) med <sp> eller <q type="speech">. Hvis teksten er organisert som de (mer) ferdige manuskriptene (gjennomskrivninger av hele eller deler av stykket, midlertidige renskrifter, renskrifter og trykkmanuskripter), med inndeling av teksten i akter og scener og med overskrifter til disse, med innledende sceneanvisninger, og sceneanvisninger markert med parenteser e.l., med rollenavn (markert med understreking eller med plassering på egen linje e.l.) osv., så skal man velge dramakoding.Imidlertid vil det ofte være glidende overganger. Vi har sett mange eksempler på prosaskisser hvor den løpende teksten veksler mellom ren prosa og dialog i direkte tale. I slike tilfeller velger man prosakoding.Dette er ytterpunktene hvor valget nærmest gir seg selv. Mellom et tydelig dramaoppsett og et tydelig prosaoppsett finnes det mange varianter hos Ibsen. I tilfeller hvor teksten hovedsakelig er organisert som replikker (gjerne en replikk pr avsnitt, og med eller uten replikkåpner) vil den for kodingen avgjørende faktoren ofte være hvorvidt det forekommer rene prosaavsnitt, dvs. avsnitt som ikke kan bestemmes som replikktekst. Slike avsnitt medfører av rent kodetekniske årsaker at man må velge prosakoding, siden dramakoding ikke tillater en veksling mellom <sp> og <p> innenfor samme <div>.Hvis det derfor forekommer prosatekst, som ikke fungerer som sceneanvisning, mellom "replikkene", kodes "replikkene" med <q type="speech">, ikke <sp>. Løpende tekst med prosaoppsett hvor det veksles mellom direkte tale og ren prosa, tekst i parenteser og "Hun/Han:" e.l. som replikkinnehavere, bør kodes innenfor samme <div>, siden teksten framstår som en helhet i manuskriptet, og det medfører at man holder seg til prosakoding. Man bør se gjennom hele den tekstdelen man velger å kode innenfor et <div>-element før man avgjør om man skal bruke drama- eller prosakoding.
- Replikkåpner er med kontra replikkåpner mangler
-
Dette er ikke et skille for hva vi forstår som replikktekst, men det kan være et kriterium å se til når man forsøker å avgjøre hvorvidt man skal bruke drama- eller prosakoding.
- Direkte tale kontra indirekte tale
-
Grensen for hva som kan forstås som replikktekst går ved direkte tale, og kun direkte tale kodes som replikktekst.
- Prosatekst fungerer som sceneanvisning kontra prosatekst er scenegang, -plan, Ibsens konseptuelle forståelse av karakterene m.v.
-
Dette er ikke et skille for hva vi forstår som replikktekst, men det kan være et kriterium å se til når man forsøker å avgjøre hvorvidt man skal bruke drama- eller prosakoding.
- Gjenfinnbar tekst i ferdig drama kontra selvstendig prosatekst
-
Den ferdige dramateksten er en god hjelp i arbeidet med å lokalisere og avgjøre hva som er replikktekst, men man må samtidig ta høyde for at replikker og replikkvekslinger kan være forkastet. Dialog og individuelle replikkutkast skal alltid kodes som replikktekst (<sp> eller <q type="speech">), selv om de ikke kan kobles til den endelige dramateksten.
- Replikken inngår i en dialog med andre replikkinnehavere (som da ikke nødvendigvis trenger å ha replikkåpnere)
-
Dialogisk direkte tale skal kodes som replikktekst, men det er verdt å merke seg at Ibsen godt kan formulere utkast til enkeltreplikker i en kontekst av løpende prosa, og at mangel på dialog mellom flere roller ikke utelukker replikkoding (<sp> eller <q type="speech">).
Replikktekst kan kodes enten som <sp> med <p> vha dramakoding eller som <q type="speech"> i <p> vha prosakoding:
<sp><p></p></sp> <p><q type="speech"></q></p>
Med dramakoding har man anledning til å bruke <spOpener> med <speaker> og <stage>. Når man bruker prosakoding, kodes kun replikkteksten, dvs. all direkte tale, som <q type="speech">. All øvrig tekst står direkte i <p>. Tekst som i innhold likner sceneanvisninger, som f.eks. er markert med parenteser, kodes ikke spesielt, jf. avsnittet Sceneanvisning nedenfor om bruk av <stage>. Hvis slik tekst forekommer inne i replikktekst, avsluttes <q type="speech"> foran og påbegynnes etter ikke-replikkteksten.
I replikkvekslinger som er kodet i <q type="speech">, f.eks. mellom «Hun» og «Han», skal «Hun» og «Han» stå utenfor <q type="speech">. Det samme gjelder annen ikke-replikktekst, jf. ovenfor om sceneanvisninger. Kun selve replikkteksten (dvs. all direkte tale) skal kodes i <q type="speech">.
<sp who=""><p></p></sp> <p><q type="speech" who=""></q></p>
Det forekommer gjerne flere prosa-avsnitt etter hverandre i slike arbeidsmanuskripter, og hvert avsnitt kan inneholde flere replikker. Det skal kodes ny <p> for hvert markerte avsnitt i mset, og det skal kodes med ny <q type="speech"> for hver påviste replikk.
kap-11.2.3.2.3: who-attributtet i <sp> og <q type="speech">
Når det er mulig å identifisere replikkinnehaveren skal det legges til et who-attributt i <sp> og <q type="speech"> på vanlig måte. Dvs. at man i den grad det er mulig (dvs. i den grad man kan identifisere de samme personene) velger samme attributtverdier som ellers i verket. Hvis det ikke finnes en rolleliste i arbeidsmanuskriptet (eller rollelisten ikke inneholder de aktuelle roller), legges id=""-attributtene i en liste i <tagUsage gi="id-who"> i <teiHeader> . Dette er retningslinjene i dramakapitlet, se videre i avsnittene 6.2.2.2 og 6.2.2.4 der.
Kodingen vår gir grunnlag for å hente ut de replikkene som ikke er kodet med who slik at brukeren evt. selv kan arbeide videre med identifikasjonen.
kap-11.2.3.2.4: Sceneanvisning
<stage> brukes bare når <sp> brukes. For at vi skal kode tekst som sceneanvisning må den stå i sammenheng med tekst vi koder som replikker (kodet som <sp>). Det skal dermed først avgjøres om hele konteksten skal kodes som drama eller prosa før man tar stilling til hvordan enkelttekstdeler skal forstås. Samtidig inngår selvfølgelig alle enkelttekstdeler i bestemmelsen av kodingen, men det er altså helheten som først, før delene, skal bestemmes.
kap-11.2.3.3: Trykte tekster med håndskrevne rettelser
Det er flere forekomster av at Ibsen har ført inn rettelser for hånd i et trykt eksemplar av en utgave til et verk. Disse rettelsene danner grunnlag for neste utgave av verket.
kap-11.2.3.3.1: Retningslinjer for kodingen
Nedenfor følger en liste med retningslinjer for kodingen av trykte tekster med håndskrevne rettelser:
- Tekstene skal opprettes med de rettede lesningene og som løpende tekster, uten hensyn til de opprinnelige lesningene, siden disse allerede finnes dokumentert i den foregående tekstkilden
- I de tekstene der det er flere hender, skal disse markeres
- Endrede rettelser kodes som vanlige endringer
- Noter og margnotater tas med (men ikke vanlige korrekturmarkeringer plassert/gjentatt i margen)
- Ufullstendige/uteglemte rettelser markeres ikke spesielt (vha. <sic> e.l.), men teksten kodes som den står; alle eksplisitte rettelser kodes
- «Underforståtte» rettelser tas det ikke hensyn til (de kan evt. kommenteres i typografibeskrivelsen), vi transkriberer teksten slik den står
- En generell beskrivelse av hva slags rettelser som er gjort og evt. frekvensen av feil plasseres i typografibeskrivelsen
kap-11.2.3.3.2: Koding
Hver rettelse regnes som én endring og markeres med <corr>. Dette kan føre til mer enn en <corr>-tag i et ord. Unntak: Når det foreligger mer enn en retting av samme tegn/-sekvens (f. eks 'Aa' rettet til 'å'), brukes bare en <corr>-tag.
Vi bruker resp="" for å markere hender/hvem som har gjort rettelsene (slike tekstvitner skal mao. alltid inneholde en <handList> siden vi betrakter dem som håndskrifter). resp="" er overflødig i tekstvitner hvor bare en hånd har gjort rettelser. Når rettelsene er utført av to eller flere hender, håndmarkeres alle rettelser (eks. HH81926 hvor to hender har utført ca. halvparten av rettelsene hver). Når to hender har utført samme rettelse og det er mulig å avgjøre hvilken hånd som har utført rettelsen og hvilken hånd som har tydeliggjort rettelsen, kodes tydeliggjøringen som <clarification hand="">. Hvis det ikke er mulig å avgjøre hendenes rekkefølge legges begge hendene i resp="" i <corr>.
Ved rene strykninger av tegn, ord etc. bruker vi et tomt <corr>-element, evt. med resp="" for å markere hånd.
Tilfeller der det er markert at linjeskift skal legges til (f. eks. <stage> skal plasseres på ny linje), kodes med <corr> rundt <lb/>.
Til koding av margnotater o.l. bruker vi <note> med resp="". Attributtverdiene som vanligvis brukes i hand="", skal brukes i resp="" i både <corr> og <note>.
Tydeliggjøring av tegn som er utydelige/uleselige i den trykte teksten kodes med <clarification>. Ved tvil legges opplysning om fenomenet i typografibeskrivelsen.
Endrede rettelser kodes med vanlig endringskoding (med <corr> i), jf. det skisserte eksemplet nedenfor.
<app type="alteration"> <lem><corr>KORRIGERT RETTELSE</corr></lem> <rdg><corr>OPPRINNELIG RETTELSE</corr></rdg> </app>
Når korrekturmarkeringer oppheves, kodes det direkte med <restore>, uten <corr>, mens <corr> brukes som verdi i type="":
<restore type="corr" hand="h1">N</restore>orge
Kansellerte rettelser for øvrig kan kodes med <restore>. Her er et ord understreket og derfor kodet med <emph> og med <corr> utenpå, deretter er understrekningen opphevet, og opphevingen er kodet med <restore>. I type="" er <emph> brukt som verdi, siden det er uthevingen som oppheves.
<restore type="emph" desc="overstrike"> <corr><emph rend="underlined">Salighedens</emph></corr></restore>
Eksemplet er hentet fra KK8955

Ved kompliserte tilfeller (der lesemåtene ikke kommer skikkelig fram når man koder med <restore>), bør man imidlertid istedet kode de kansellerte rettelsene i apparat:
<app type="alteration"> <lem>T<corr resp="HI">h</corr>orolf</lem> <rdg>T<corr resp="SI"></corr>orolf</rdg> </app>
Eksemplet er hentet fra HH81926
<lb/><l>som kan Dovregubbens <app type="alteration"> <lem><corr resp="HI">g</corr><corr resp="HI">å</corr>denød<corr resp="HI">d</corr></lem> <rdg><corr resp="HI">g</corr><corr resp="HI">å</corr>denød<corr resp="HI"></corr></rdg> </app> kløve!</l>
Eksemplet er hentet fra PG8894
kap-11.2.4: Endelige manuskripter
kap-11.2.4.1: Generelt
- Endelige manuskripter
- endelig renskrift («et manuskript som vurderes som endelig, men som ikke bærer spor av å være brukt som trykkmanuskript»)
- trykkmanuskript («endelig manuskript brukt som forelegg for trykk»)
- scenemanuskript («endelig manuskript til bruk ved teateroppførelse»)
- Scenemanuskripter
- sufflørbøker («scenemanuskript som inneholder hele stykkets tekst, enten til bruk for teatersufflør eller for andre formål i tilknytning til en oppførelse»)
- rollehefter («scenemanuskript til bruk for en enkelt skuespiller. Det inneholder den enkelte skuespillerens replikker»)
Alle sitater er fra prosjektets interndokument «Behandling av manuskripter i HIS». Attributtverdiene som skal brukes, er:
- Endelig manuskript: «finalManuscript»
- Endelig renskrift: «finalFairCopy»
- Trykkmanuskript: «printersCopy»
- Scenemanuskript: «stageProductionCopy»
- Sufflørbok: «promptCopy»
- Rollehefter: «parts»
Nedenfor omtales kodingen av rollehefter siden strukturen her er spesiell. Andre endelige manuskripter er å likne med vanlige trykte kilder og krever ingen spesiell strukturkoding. Disse er derfor ikke omtalt her. Det kan likevel være nyttig å lese Retningslinjer før man går i gang med arbeidet.
kap-11.2.4.2: Rollehefter
kap-11.2.4.2.1: Overordnet struktur
Rolleheftene kodes fortløpende etter hverandre i en XML-fil, dvs. med <text> i <group> i <text>.
<text type="parts"> <group> <text id="Sa872r-Anna"> ... </text> <text id="Sa872r-Paulsen"> ... </text> (osv.) </group> </text>
Man skal ikke lenke sammen rolleheftene slik man gjør med føljetongtekstene siden rolleheftene ikke på tilsvarende måte utgjør en samlet struktur.
kap-11.2.4.2.2: Tittelblader
Rolleheftene har noe annerledes utformede tittelblader enn andre håndskrifter (se f.eks. tittelsiden til Blankas rollehefte fra K2). Disse skal likevel kodes som vanlige tittelblad.
<text id="K2238-Blanka"> ... <front><titlePage><docTitle> <lb/><titlePart>Blanka, <lb/>i <lb/>«Kjæmpehøien»: <lb/>Dramatisk Digtning i 1. Act</titlePart> </docTitle> <byline> <lb/>af <lb/><docAuthor>Henrik Ibsen</docAuthor> </byline></titlePage> <performance> <p><del>Mad: Brun</del> Jfr: Jensen 25/1.56. <del>28/12.53.</del> <del>Henr: Ibsen</del> Wiee<note resp="EN">resten av navnet skjult bak brettet hjørne.</note></p> </performance> </front> ... </text>
Opplysninger om skuespiller(e) og regissør(er) samt datoer på tittelblad skal kodes i <p>-er i en <performance>-tagg.
Opplysninger om antall legg i rolleheftet kodes som <measure> i <docImprint>.
kap-11.2.4.2.3: Gjennomgående «avvik» i typografiske oppsett
Det typografiske oppsettet i rolleheftene kan være nokså forskjellig. Nedenfor følger eksempel fra K2.
«Rollehefterollen» (Blanka i rolleheftet «Blanka», Roderik i rolleheftet «Roderik» etc.) har understreket rollenavn, men ikke understreket replikk. For de øvrige rollene er det motsatt. Se eksempel. Det innebærer at halvparten av rollenavnene og store deler av replikkvekslingen er «avvik» i forhold til de systemer vi tidligere har sett. Dette er informasjon som ikke skal kodes, men som skal omtales kort og samlet i typografibeskrivelsen siden den ikke er av større betydning for tekststrukturen, men har hatt som funksjon å framheve riktig/e rolle/replikker i rolleheftet.
kap-11.2.4.2.4: id=""- og who=""-attributter
Rolleheftene inneholder ikke rollelister, og dermed må rollene gis id=""-attributter vha. <tagUsage> på samme måte som andre filer som ikke inneholder rollelister, jf. <tagUsage gi="id-who"> i kapitlet om teiHeader.
kap-11.2.4.2.5: Tomme <speaker>-elementer
I en del av rolleheftene blir «rollehefterollen» ofte representert med en horisontal strek i replikkåpnerne. Dette koder vi med tom <speaker>, og med who=""-attributt i <sp>.
Når den rollenavnrepresenterende streken dukker opp i rollehefter hvor «rollehefterollen(e)» ikke skal ha id=""- og who=""-attributt, for eksempel rollehefter som innehas av flere rollefigurer samtidig (Gjæster, Mænd, Kvinder og Spillemænd, Terner o.l.), fjerner kombinasjonen <sp> uten who=""-attributt og tomt <speaker>-element referansen til replikkens opphav. Vi koder likevel på samme måte siden replikkinnehaverne kan gjenfinnes via id=""-attributtet i rolleheftets <text>-element.
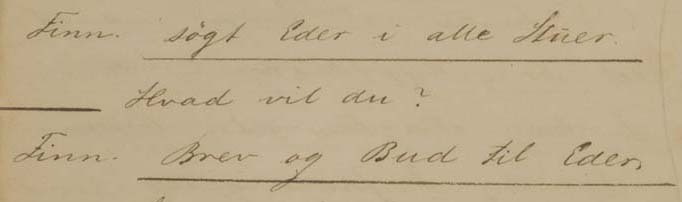
kap-11.2.5: Materiale til flere verk i samme manuskript
kap-11.2.5.1: Generelt
Det forekommer at en manuskript-signatur inneholder manuskripter til flere av Ibsens verker. For trykte tekster har vi helt parallelle tilfeller (bl.a. i samlede verker) hvor flere stykker er trykt i samme bok. Vi bruker de samme retningslinjene når det gjelder manuskripter i tilsvarende situasjon.
De enkelte verksvitnene oppfattes som selvstendige og gjengis i hver sin XML-fil. Det oppgis i <bibl id="">/<msDescription> (se Bibliografiske opplysninger om kildene – <sourceDesc> i <teiHeader>-kapitlet) at vitnet deler manuskriptsignatur med et tekstvitne fra et annet verk.
Se forøvrig også Manuskriptmaterialet, bibliotekets signaturer og arbeidsrutiner.
kap-11.2.5.2: UF81937a/KG81937a
NBO Ms.8° 1937a består av ett blad. På den ene siden står en rolleliste til De unges Forbund, denne er kladd til vedlegg i tapt brev. På den andre siden står notater til Kejser og Galilæer. De to sidene kodes i hver sine XML-filer, henholdsvis UF81937a og KG81937a.
kap-11.2.5.3: UF41109a+b
NBO Ms.4° 1109a og NBO Ms.4° 1109b er bundet sammen i samme bok. De to manuskriptene er begge utkast til De unges forbund. Tittelside og rolleliste står bare én gang, først i boka, og man kan se av innbindingen at disse tilhører NBO Ms.4° 1109a. Manuskriptene kodes i hver sin fil. Tittelsiden og rollelisten følger NBO Ms.4° 1109a.
kap-11.2.6: Dokumentasjon av kodeløsninger
I dette kapitlet er det samlet eksempler på kodeløsninger for spesielle og/eller sjeldne fenomener i manuskriptene.
kap-11.2.6.1: Huskelister – KG41111
Enkelte overstrykninger er ikke egentlige rettelser, men minner snarere om huskelister (hvor Ibsen har strøket ut etter hvert som han har tatt for seg punktene på lista). Eksempel på dette er funnet i notater i KG41111 . Slike overstrykninger skal kodes med <del type="checkList" rend="overstrike">.
kap-11.2.6.2: Konvolutter – Ro41291
I arbeidsmanuskriptet Ro41291 finnes det et blad som stammer fra en konvolutt. Konvolutten er sannsynligvis klippet opp og bundet inn sammen med resten av manuskriptet, da det ble bundet inn på det daværende UBO, nå NBO. Manuskriptet ble gitt til UBO av Hildur Andersen i 1928, og befant seg ifølge HU fortsatt i konvolutten i 1932, da HU publiserte Ro. Siden vi dermed kan anta at dette bladet virkelig stammer fra denne konvolutten, kodes det med utgangspunkt i HIS' brev-kodepraksis, som konvolutt, <envelope>. Texten kodes i et eget <text>-element, da vi kan skille den genetisk fra teksten i manuskriptet for øvrig, og videre i <div type="paratext">.
<text> <front> <div type="paratext"> <envelope type="envelope"> <minAddress> <lb/><addrLine>Tilhører Hildur!</addrLine> </minAddress> <div type="envelope_content" hand="HI-3"> <lb/><head>Rosmersholm.</head> <lb/><p>(Koncept.)</p> </div> </envelope> </div> </front> <body><p></p></body> </text>

kap-11.2.6.3: Materiale som ellers kodes i <front> eller <back>
Her er det eksempler på små manuskripter som inneholder materiale som vanligvis kodes i <front> eller <back>, men som i disse tilfellene selv utgjør dokumentets <body>, og derfor kodes i <body>.
kap-11.2.6.3.1: Kladd til vedlegg i tapt brev – NBO Ms. 8° 1937a
NBO Ms. 8° 1937a er et lite manuskript bestående av ett blad. På den ene siden finnes det en rolleliste til De unges Forbund med forslag til hvilke skuespillere som skal ha de forskjellige rollene, sannsynligvis er manuskriptet en kladd til et vedlegg til et tapt brev. På den andre siden fins det notater til et forord til Kejser og Galilæer. Dette omtales nedenfor.

Fordi rollelisten utgjør hele dokumentet, kodes den direkte i <body>. Videre benyttes det dramakoding, dvs. rollelistekoding, siden manuskriptet inneholder typiske dramaelementer; setting og rollebeskrivelser. <set> er gjort tillatt i <body> for at kodingen skal være valid.
<text lang="Dano-Norwegian"> <body> <pb/> <lb/><head>Rollebesættning.</head> <castList> <lb/><castItem id="KAMMERHERREN">Kammerherre Brattsberg ‐ ‐ <actor>Wolf</actor>.</castItem> ... </castList> <add place="margin"> <note resp="editor">Tilføyelsen...</note> <lb/><set><p>Handling<unclear reason="writing">en</unclear> forega<unclear reason="writing">a</unclear>r p<unclear reason="writing">aa</unclear> Værket i Nærheden af en Kjøbstad i <lb/>det syd<unclear reason="writing">ø</unclear>stlige Norge.</p></set> </add> </body> </text>
kap-11.2.6.3.2: Notater til forord – KG81937a
Siden med notater til et forord typologiseres som arbeidsmanuskript, siden det ut fra innholdet er mulig å anta at dette dreier seg om notater til et forord. Teksten er ikke fullført; den er usammenhengende og mangler overskrift og avslutning. Det finnes heller ikke noe forord i de trykte utgavene av Kejser og Galilæer.

Manuskriptet kodes i <body>, men for øvrig som andre forord:
<text type="workingManuscript" lang="Dano-Norwegian"> <body> <pb/> <div type="preface"> <lb/><p>Naar jeg kalder nærværende Digt et &lquo;verdens&typHyp; <lb/>historisk&rquo; saa sker det ikke af den uvæsentlige Grund at ... <lb/>hvad jeg digterisk taget havde seet og tænkt ‐</p> </div> </body> </text>
kap-11.2.6.3.3: Trykkmanuskript til forord – KK8955a
Trykkmanuskriptet til forordet til 2. utgave av «Kjærlighedens Komedie» er et eget manuskript og kodes derfor på samme måte som arbeidsmanuskriptet KG81937a direkte i <body>. Trykkmanuskriptet typologiseres som nettopp trykkmanuskript.

<text type="printersCopy" lang="Dano-Norwegian"> <body> <pb/><pb ed="HU" n="137"/> <div type="preface"> <lb/><head>Till anden Udgave.</head> <lb/><p>Nærværende Digt er skre&typHyp; <lb/>vet i Sommeren 1862 og første <lb/>Udgave udkom samme Aars Vin&typHyp; <lb/>ter.</p> ... <lb/><p>Enkelte lokale Hentydninger <lb/>vil maaske være uforstaaelige for <lb/>danske Læsere; men disse Hen&typHyp; <lb/>tydninger ere ikke mange og <lb/>desuden uvæsenlige for Forstaael&typHyp; <lb/>sen af Digtets Gang og Tanke.</p> <lb/><dateline>Rom, i <date>Januar 1867</date>.</dateline> <lb/><signed>Henrik Ibsen.</signed> </div> </body> </text>
kap-11.2.6.4: Manuskripter med flere rollelister
I arbeidsmanuskripter forekommer det at det finnes flere (midlertidige) rollelister. id=""-attributtet plasseres i slike tilfeller ikke i <castItem>, men i listen i <tagUsage> . Istedenfor id="" brukes corresp="" i <castItem>.
kap-11.3.1: Latinsk og gotisk håndskrift
Vi skiller ikke mellom latinsk og gotisk håndskrift, alle innslag av gotiske bokstaver normaliseres vekk. Håndskriften omtales imidlertid i typografibeskrivelsen (man angir hva slags håndskrift hendene bruker, blandingstendenser, flere utgaver av samme majuskel/minuskel, f.eks. forekomster av flere versjoner av «d»)
kap-11.3.2: Skriblerier, spesialtilfeller og Ibsens særheter
Skriblerier omtales vanligvis i typografibeskrivelsen og unntagelsesvis i noter underveis i teksten.
Ibsens særheter gjør vi rede for i typografibeskrivelsen, evt. i <note resp="editor">: skrift stilt på hodet, regnestykker osv.
kap-11.3.2.1: Julius Elias' klammeparenteser
I mange Ibsen-manuskripter dukker det stadig opp klammeparenteser skrevet med blyant. Det er overveiende sannsynlig at disse stammer fra Julius Elias og at de ble tilføyd under arbeidet med Efterladte skrifter. Disse ignoreres.
kap-11.3.4: Sider og paginering
I utgangspunktet følges følgende kriterium:
- Alle sider, inkl. blanke, markeres med <pb/>. For unntak og for plassering av <pb/>, se avsnittene nedenfor
- All paginering/foliering transkriberes uavhengig av om det er tekst på siden eller ikke
Paginering med rød blyant (som ikke følger dagens innbindingsrekkefølge) i bla. KG4111 er sannsynligvis tilføyd etter Ibsens tid. Denne pagineringen vil imidlertid være et nyttig verktøy når vi skal referere fra vår elektroniske tekst til originalmanuskript og faksimiler, så den inkluderes i filene våre i <fw>.
kap-11.3.4.1: Mange blanke sider etter hverandre
Når et stort antall sider er blanke, kodes ikke sideskiftene og evt. paginering/foliering på sidene transkriberes ikke. Istedenfor legges det inn en <note resp="editor">, hvor det blir redegjort for hva som er utelatt. Eksempel kan finnes i Hedda Gabler-manuskriptene NBO Ms. 8° 2638 og NBO Ms. 8° 2639, som er to notisbøker, hvor bare noen av sidene er påskrevet.
kap-11.3.4.2: Plassering av <pb/> for blanke sider
<pb/> for blanke sider (etter tekst) som skal inkluderes i filen, plasseres innenfor samme <div> eller <text> som teksten står i.
kap-11.3.5: Nummerering – <fw>
Nummerering og bruken av <fw> i manuskripter omtales i detaljkapitlet, Bruken av <fw> i manuskripter, men se også Paginering ovenfor.
kap-11.3.6: Egenhendige og ikke-egenhendige noter
Ibsens egenhendige noter kodes som forfatternoter i <note resp="author">. Hvis det ikke er Ibsens hovedhånd som har skrevet noten, legges det til et hand=""-attributt med håndens attributtverdi. Se detaljkapitlet for retningslinjer for transkripsjon av notemarkører.
Som forfatternoter kodes Ibsens metatekstlige kommentarer/ tematiske innholdskommentarer (Sv: «Trang skaber Digte o. s. v») og produksjonsnotater (datoer for renskrift, kommentarer om forsendelser til Hegel osv.) o.l. Egenhendige noter skal alltid ha egne linjeskiftselementer (<lb/>), siden de er Ibsen-tekst.
Her er et eksempel på en egenhendig note i Br81925 (trykt tekst med håndskrevne rettelser). Noten er transkribert og plassert rett innenfor <lb/> på den linjen den ligger nærmest. Slik ser kodingen ut:
<note resp="author" hand="HI-1" place="margin-left">(
<ref type="refMark" target="nb1" id="n1">&referenceMark;</ref> spær!)</note>
mens referansetegnene, både i noten og i teksten, er kodet med <ref type="refMark">:
<ref type="refMark" hand="HI-1" target="n1" id="nb1">&referenceMark;</ref>

Ikke-egenhendige noter utelates. Ikke-egenhendige noter inngår dermed blant skriblerier som det gjøres rede for i typografibeskrivelsen, evt. i <note>.
Om noter, se også Noter – <note> i kapitlet om detaljkoding.
kap-11.3.7: Brutt sammenheng
På enkelte blad (eller ved et leggs slutt) begynner eller slutter teksten midt i en setning. Det er grunn til å tro at dette ikke skyldes sammenstillingen av manuskriptene, men derimot at hele eller deler av legg mangler. I våre studier bør vi likevel undersøke muligheten for at manuskriptene kan føyes sammen på andre måter og at brutte sammenhenger slik kan leges.
I arbeidsmanuskripter, særlig de som består av løse blad og dobbeltblad, hender det f.eks at teksten på s. 1 fortsetter på s. 4, fordi et
blad i mellom plutselig inneholder noe annet. Struktureelementene som da blir delt i to kodes med <join> i arkivutgaven av filen. I vår ordning av materialet vil sammenhengen være leget.
kap-11.3.8: Feil rekkefølge
I arbeidsmanuskripter, særlig de som består av løse blad og dobbeltblad, hender det at Ibsen har benyttet flere skriveretninger, f.eks. brukt begge ender av et dobbeltblad som begynnelse, slik at teksten på s. 2–4 står bak frem. Opp-ned tekst over flere sider kommer derfor gjerne bak-frem i forhold til manuskriptets kronologiske ordning på biblioteket. I slike tilfeller transkriberer HIS teksten i riktig rekkefølge; først s. 1, deretter s. 4, 3 og 2. Dette dokumenteres i <note resp="editor">, og den opprinnelige rekkefølgen framgår også av foliering og <pb/>-tagger.

Med alternativ tekst mener vi formuleringer som står tilføyd utenfor teksten og hvis innhold er parallelt (omformuleringer, forkortende eller utvidende) med innholdet i (del av) nærliggende replikk, men som ikke er knyttet til et sted i teksten vha. innføyningstegn og som heller ikke klart kan bestemmes som erstatning til en avgrenset del av replikkteksten, for koding se Ufullførte endringer.
kap-11.3.10: Illustrasjoner
Tegninger kodes som <figure type="illustration">.
kap-11.3.11: Håndskriftsendring av pretrykt tekst
I brevene forekommer det enkelte ganger at Ibsen endrer med hånd i den trykte teksten.
Minimale endringer: Her er 'n' i «Ibsen» forlenget slik at streken overskriver punktum:
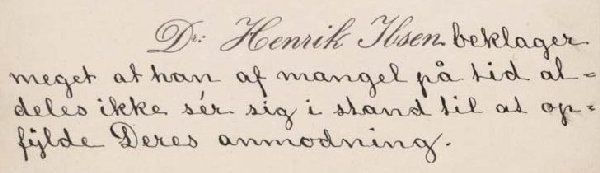
Disse rettelsene kodes som en kombinasjon av tydeliggjøring og overskriving:
<p><print rend="italics">D<hi rend="raised">r:</hi> Henrik Ibse<clarification place="inline">n<del rend="overwritten">.</del></clarification></print> beklager <lb/>meget at han af mangel på tid al&typHyp; <lb/>deles ikke sér sig i stand til at op&typHyp; <lb/>fylde Deres anmodning.</p>
Eksemplet er hentet fra B18910923PSw
Større endringer: I B18861001TAn (en kontrakt) har Ibsen gjort flere endringer og tilføyelser i den forhåndstrykte teksten.

Rettelsene kodes på vanlig måte :
<div type="letter"> <lb/><p><print>Herved overdrager jeg Hr. Skuespildirecteur Th. Andersen <lb/>Eneret til</print> <app type="alteration"><lem><add place="offline" hand="B18861001TAn-HI">på Dagmarteatret</add></lem><rdg><del rend="overstrike" hand="B18861001TAn-HI"><print>overalt i Danmark</print></del></rdg></app> <print>at lade opføre</print> «Gildet på Solhaug», <lb/>skuespil i 3 akter.</p> <lb/><p><print>Denne Ret overdrager jeg ikke alene Hr. Andersen personlig, <lb/>men ogsaa <del rend="overstrike">til hvem han igjen overdrager</del> den<del rend="overstrike">.</del></print>, hvem han måtte <lb/>overdrage ledelsen av Dagmarteatret.</p> <lb/><p><print>Kjøbenhavn. d. 18</print></p> <lb/><p>I honorar udbetales mig ved første opførelse <lb/>200 kroner og derefter 100 kroner for hver ti&typHyp; <lb/>ende opførelse.</p> <lb/><dateline>Mnchen, den <date>1. Oktober 1886</date>.</dateline> <lb/><signed>Henrik Ibsen.</signed> </div>
Eksemplet er hentet fra B18861001TAn
kap-11.3.12: Ufullførte tegn
Fra tid til annen kommer vi over ufullførte tegn, ofte strøkne eller overskrevne, noen ganger ikke. Nedenfor følger retningslinjer for behandling av ufullførte tegn:
- et tegn som er avsluttet før det i det hele tatt er mulig å avgjøre hvilket tegn det skulle bli, ignoreres (det hverken transkriberes eller kodes, men regnes som rusk)
- et tegn som kan forstås som begynnelsen på flere forskjellige tegn, kodes som <gap/>, siden vi ikke kan avgjøre hvilket tegn det skulle bli
- et tegn som er såvidt fullført at det er mulig med stor grad av sikkerhet å si hvilket tegn det er, transkriberes som dette tegnet
- kontekst; det er fornuftig å se på konteksten når man forsøker å identifisere hvilket tegn det er snakk om, se eksempler nedenfor på hvordan konteksten kan brukes til å analysere seg fram til hvordan det ufullførte tegnet skal behandles
Her er eksempler på ufullførte tegn og hvordan de er forstått, transkribert og kodet.
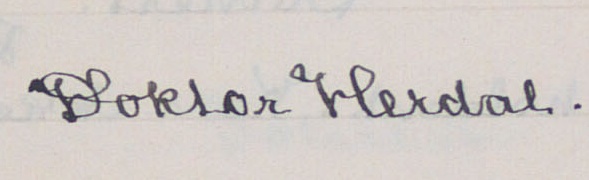
Bildet viser en overskrevet, nesten fullført «H» under «D» i «Doktor». Sammenlikn den overskrevne «H» med «H» i «Herdal». Siden bokstaven «H» er så godt som fullført og lar seg bestemme med rimelig sikkerhet, transkriberes bokstaven og kodes for øvrig som overskrivning.
<lb/><sp who="HERDAL"><spOpener><speaker><del rend="overwritten">H</del>Doktor
Herdal</speaker>.</spOpener>
<lb/><p>Og De har ikke fortalt Deres hustru sammenhængen
<lb/>i dette?</p></sp>
Eksemplet er hentet fra BS41292

Bildet viser et ufullført og overstrøket tegn, som kan forstås som begynnelsen av flere tegn. Sammenlikn f.eks. med «k», «l», «t» i bildet. Siden tegnet er stort nok til at man kan tenke seg hva det skulle bli, men uten at man kan avgjøre det, kodes dette med <gap/> i <del rend="overstrike">.
<lb/><sp who="SOLNESS"><spOpener><speaker>Solness</speaker>.</spOpener>
<lb/><p>Fordi jeg gik i funderinger. <stage>(dæmpet)</stage> Gennem den
<lb/>lille <add place="offline">svarte</add> sprækken <del rend="overstrike"><gap/></del>
i skorstenspiben kunde jeg kanske
<lb/>vinde mig tilvejrs – som bygmester.</p></sp>
Eksemplet er hentet fra BS41292

Bildet viser et nesten fullført og overstrøket tegn, som neppe kan forstås som noe annet enn en «d». Siden neste setning innledes ganske likt («Og så denne»), er det ikke urimelig å anta at Ibsen har gjort en klassisk avskriftsfeil; hoppet over en linje og skrevet «så d» før han har oppdaget feilen. Her transkriberes derfor «d» og kodes med <del rend="overstrike">.
<lb/><sp who="ROSMER"><spOpener><speaker>Rosmer</speaker>.</spOpener>
<lb/><p>Nej, nej, det forstår sig. – Å <del rend="overstrike">så d</del> hvilken
<lb/>kamp<pb ed="HU" n="394"/> hun må ha&rapo; kæmpet. Og så denne gri&typHyp;
<lb/>bende, anklagende sejr.</p></sp>
Eksemplet er hentet fra Ro41291

På denne siden er det tre tilfeller av samme slags feilskrivning; Ibsen har skrevet «Mor» – for «Mortensgård» – («r» er i varierende grad fullført) og så oppdaget at det skulle være «Madam Helseth», og derfor skrevet «ad(am Helseth)» over «or». Alle tre stedene transkriberer vi «or» og koder for overskrivning.
<pb n="170"/> <lb/><fw type="gathering" place="top-left">26.</fw> <lb/><sp who="REBEKKA"><spOpener><speaker>Rebekka</speaker>.</spOpener> <lb/><p>Hvad tror De da der stod? Å, kære snille <lb/>madam Helset, sig mig det!</p></sp> <lb/><sp who="MADAMHELSETH"><spOpener><speaker>M<del rend="overwritten">or</del>adam Helset</speaker>.</spOpener> <lb/><p>Nej da, frøken. Ikke for alt det, som i verden <lb/>er.</p></sp> <lb/><sp who="REBEKKA"><spOpener><speaker>Rebekka</speaker>.</spOpener> <lb/><p>Å til mig kan De da sige det. Vi to er jo så <lb/>gode venner.</p></sp> <lb/><sp who="MADAMHELSETH"><spOpener><speaker>M<del rend="overwritten">or</del>adam Helset</speaker>.</spOpener> <lb/><p>Gud bevare mig for at sige noget til Dem om <lb/>det, frøken. Jeg kan ikke sige andet, end at det <lb/>var noget stygt, som de havde gåt og bildt den <lb/>stakkers syge fruen ind.</p></sp> ... <lb/><sp who="MADAMHELSETH"><spOpener> <speaker>M<del rend="overwritten">or</del><unclear>a</unclear>dam Helset</speaker>.</spOpener> <lb/><p>Å jeg ved nok, hvad jeg tror. Men gud bevare <lb/><emph>min</emph> mund. Der går rigtignok en viss frue ...</p></sp>
Eksemplet er hentet fra Ro41291
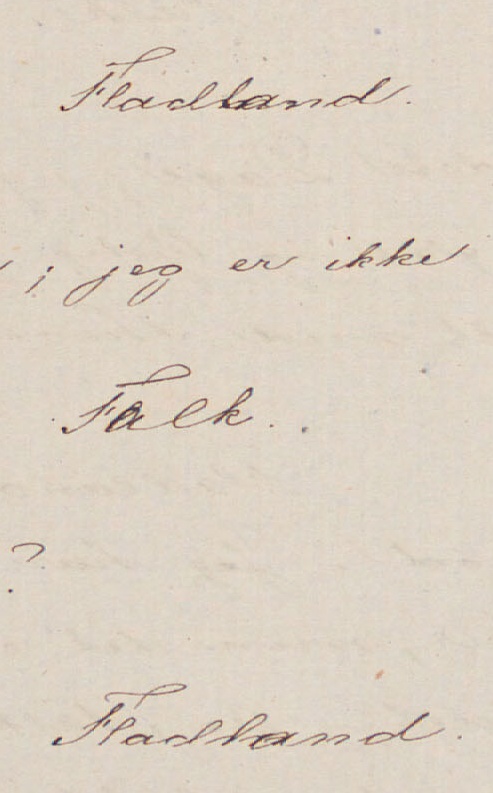
Her er det tre overskrivninger som alle skyldes feilskrevne navn. I Svanhild vaklet Ibsen en stund mellom navnene «Fladmark» og «Fladland» for en av de mannlige hovedpersonene, og det ser man konkrete eksempler på her. I begge «Fladland»-forekomstene kan man se en «m» under «la». Under «a» i «Falk» er det en «l» (for «Fladmark» eller «Fladland»). I alle tre tilfellene transkriberes de overskrevne bokstavene og kodes som overskrivninger.
<lb/><sp who="FLADLAND"><spOpener><speaker>Flad<del rend="overwritten">m</del>land </speaker>.</spOpener> <lb/><p>Aa, det gaar nok; jeg er ikke ræd for Nogenting.</p></sp> <lb/><sp who="FALK"><spOpener><speaker>F<del rend="overwritten">l</del>alk </speaker>.</spOpener> <lb/><p>Og Fremtiden?</p></sp> <lb/><sp who="FLADLAND"><spOpener><speaker>Flad<del rend="overwritten">m</del>land</speaker>.</spOpener> <lb/><p>Den tænker jeg ikke paa! <add place="offline">Jeg lever bare for Guds deilige Dag som skinner omkring mig</add> Derfor var jeg ogsaa <lb/>saa glad i din Vise. En prægtig Vise! Skaal <lb/>og Tak for den.</p></sp>
Eksemplet er hentet fra Sv4926
I ordet «sejr» er «e» skrevet over et delvis fullført tegn, sannsynligvis en «j». Dette tilfellet ligger på grensen mellom noe vi vil transkribere som tegn eller kode direkte som <gap/>. I slike tilfeller er det dermed i orden at den enkelte koder følger sitt eget skjønn, eller konfererer med andre kodere og blir enige om et resultat. At det dermed vil være ganske like tilfeller som behandles ulikt, må vi kunne leve med. Ufullførte tegn er alltid så godt som unike og står dessuten alltid i sin egen, unike kontekst.
ENTEN <sp who="ROSMER"><spOpener><speaker>Rosmer</speaker>.</spOpener> <lb/><p>Ja, du lyver. Du har aldrig trod på mig. <lb/>Aldrig har du trod at jeg var mand for at <lb/>kæmpe den sag frem til nogen s<del rend="overwritten">j</del>ejr.</p></sp> ELLER <sp who="ROSMER"><spOpener><speaker>Rosmer</speaker>.</spOpener> <lb/><p>Ja, du lyver. Du har aldrig trod på mig. <lb/>Aldrig har du trod at jeg var mand for at <lb/>kæmpe den sag frem til nogen s<del rend="overwritten"><gap/></del>ejr.</p></sp>
Eksemplet er hentet fra Ro41291
Bildet viser et ufullført og overskrevet tegn (under «m» i «mig»), som det er vanskelig å forstå hvilket tegn skulle bli. Også her er det mulig å velge mellom to kode- og transkripsjonsløsninger. Siden tegnet ikke er stort nok til at man kan tenke seg hva det skulle bli, og man heller ikke vha. konteksten enkelt kan gjette hvilket tegn det skulle bli, kan tegnet enten ignoreres helt (og derfor ikke kodes eller transkriberes) eller det kan kodes med <gap/>.
<lb/><sp who="HILDE"><spOpener><speaker>Hilde</speaker></spOpener> <lb/><p>Langt ifra <emph>det</emph>. Jeg gemmer mig ikke bort under <lb/>buskerne.</p></sp> <lb/><sp who="HILDE"><spOpener><speaker>Hilde</speaker></spOpener> <lb/><p>Langt ifra <emph>det</emph>. Jeg gemmer <del rend="overwritten"><gap/></del>mig ikke bort under <lb/>buskerne.</p></sp>
Eksemplet er hentet fra BS41292
kap-11.3.13: Tilfeldig utheving av overskrifter, rollenavn o. l.
Sporadisk utheving av overskrifter, rollenavn o. l. kodes i <hi rend="">. Gjennomgående utheving beskrives derimot i typografibeskrivelsen og kodes altså ikke.
Vi koder uthevingen velvillig, slik at tegn som ikke er uthevet, men som vi kan anta at er ment uthevet, kodes innenfor <hi>. For forkortede rollenavn etterfulgt av punktum innebærer dette at punktumet skal stå innenfor <hi> selv om det ikke er uthevet, da vi anser punktumet som tilhørende rollenavnet (jf. dramakapitlets kap. 4.1.3 Replikker med forkortede rollenavn).
kap-11.4: Skriverhender
kap-11.4.1: Skriveomganger
I mange av Ibsens arbeidsmanuskripter finnes det flere skriveomganger. Det skyldes ofte at manuskriptene er samlinger med felles biblioteksignatur med tilblivelsesmateriale til et verk. Det skyldes også at Ibsen gjenbrukte papir; det finnes eksempler på at han har rablet ned et replikkutkast opp-ned på et blad som for øvrig inneholder en påbegynt renskrift eller begynnelsen til et brev.
Med skriveomgang mener vi dermed at en del av manuskriptet (sannsynligvis) er skrevet på et annet tidspunkt enn (deler av) resten av manuskriptet. Man kan i så fall skille ut en del av materialet etter en vurdering av skrivestil, blekkfarge og papirtype. Alle tre kriterier trenger ikke være annerledes, men skillet må være tydelig; endringen skal være iøynefallende for å kvalifisere som egen skriveomgang.
Skriveomganger markeres vha. hand-attributtet . Dette kan brukes i <text>, <div> og <p>.
Man kan også finne egne revisjonsomganger, dvs. rettelser/endringer som tydelig er gjort i ettertid i forhold til når den løpende teksten er skrevet . Rettelser/endringer markeres også med hand-attributtet, og det plasseres i de taggene som markerer endringene, f.eks. <add> og <del>.
Egentlige håndskifter (<handShift/>) forekommer relativt sjelden. Med håndskifte forstår vi et markant skifte i skriftstil og/eller blekkfarge midt i løpende tekst. I slike tilfeller skal man bruke <handShift/>, siden det å splitte opp teksten med strukturkoding midt i løpende tekst ikke er fornuftig .
kap-11.4.2: Markering av hender – hand=""
Attributtet hand="" skal brukes når en annen hånd enn hovedhånden har endret tekst. Attributtverdiene skal utformes slik:
- for identifiserte hender: «INITIALER», hvor man fører skriverens initialer; f.eks. «CLD»
- hvis samme identifiserte hånd skriver med forskjellige skriveredskaper/blekkfarge, skiller vi de to fra hverandre ved nummerering og oppgir skriveredskap i ink=""; f.eks. «HI-1», «HI-2»
- NB: det er ikke nødvendig å nummerere når skriveren kun forekommer med en hånd, mao. finnes det kun en Christopher L. Due-hånd, kalles denne «CLD»
- NB: når skriveren er Henrik Ibsen bruker vi likevel alltid «HI-1», siden det gjør farging av tekst i HISe-visningen enklere
- for uidentifiserte hender: «hx», hvor «h» betyr «hånd» og «x» er et siffer; f.eks. «h2»
- første uidentifiserte hånd får attributtverdien «h1», andre «h2» osv
- hvis samme uidentifiserte hånd skriver med forskjellige skriveredskaper/blekkfarge, skiller vi de to fra hverandre ved nummerering (som for identifiserte skrivere) og oppgir skriveredskap i ink=""; f.eks. «h2-1», «h2-2»
Attributtverdiene for hand="" må defineres individuelt for hvert håndskriftstekstvitne i håndlista i <teiHeader>. Se Håndskriftets hender – <handList> i <teiHeader>-kapitlet for mer om kriteriene for håndattribuering.
kap-11.4.3: Skifte av skriverhender – <handShift/>
Ved tydelige håndskifter i løpende tekst, dvs. midt inne i et avsnitt eller en overskrift o.l., markerer vi håndskifte i teksten. Kriterier for å vurdere noe som håndskifte er markerte endringer i både penne-, blekk- og skriftkvalitet. Selve kodingen gjøres ved å legge inn milesteinselementet <handShift/> rett foran den første teksten som er skrevet med ny hånd (foran teksten, men innenfor elementene):
<handShift/> skal inneholde de to attributtene new="" og old="" samt ink="" og evt. character="" (character="" skal ikke brukes alene ettersom kvalitetsforskjell alene ikke har vært nok til at vi markerer håndskifte). Disse skal ha attributtverdier hentet fra <handList> i <teiHeader>, se Håndskriftets hender – <handList> i <teiHeader>-kapitlet.
kap-11.5: Uleselig/manglende tekst – <gap/>
I manuskripter forekommer det at tekst mangler fordi manuskriptet er skadet (avrevne blad etc.) eller fordi vi må utelate tekst som er uleselig (f.eks. pga. blekkflekk, slurvete skrift etc.). I slike tilfeller bruker vi <gap reason=""/>.
Det er ikke nødvendig å bruke reason="" i <gap/> når <gap/> står inne i <del> (evt. <rdg>), siden det framgår implisitt at årsaken er den samme som grunnen til strykningen/endringen, jf. nedenfor om <unclear>.
Vi markerer ikke lengde/størrelse på uleselig/manglende tekst, jf. likevel under.
Hvis et helt blad mangler (klippet/revet ut etc.) brukes i tillegg attributtet extent="": <gap extent="leaf"/>. Merk at dette bare gjelder blad der man vet det har vært tekst. Dersom man ikke har noen grunn til å tro at det var tekst på det manglende bladet, kan man nøye seg med å notere mangelen i typografibeskrivelsen. extent="" skal ikke brukes andre steder enn ved manglende blad. Årsaken til at vi noterer omfanget i forbindelse med manglende blad, er at en bruker her ikke kan få hjelp av faksimilene til å danne seg et inntrykk av skadens/mangelens omfang.
kap-11.6: Uklar tekst – <unclear>
Dette elementet brukes rundt tekst (ord eller bokstav/er) som er vanskelige å lese. Kun den teksten som er vanskelig å lese, kodes i elementet.
Når all tekst i rene strykninger (<del rend="overstrike">) er markert med <unclear>, må vi flytte <unclear> ut av <del> sånn at ikke også <unclear>-tegnene blir overstrøket i visningen.
Årsaken til at teksten er vanskelig å lese, anføres i attributtet reason="". Attributtet reason="" brukes vanligvis bare når <unclear> står alene. I kombinasjon med andre elementer, f.eks. <del>, vil vanligvis måten teksten/tegnet er strøket på også være årsaken til at det er uklart, og reason="" er dermed overflødig.
Man må kunne forutsette at det finnes et faktisk ord bak en skrift som ikke lar seg lese fullstendig tegn for tegn, mao. at man faktisk skriver ut det ordet som ser ut til å være det riktige, men markerer dette som uklart (<unclear>) hvis det er reell tvil om lesemåten. Tilsvarende kan man bruke konteksten rundt for å avgjøre hvilken/t bokstav/ord man har med å gjøre.
Elementet <unclear> skal bare brukes der det er reell tvil om lesemåten. Selv om enkelte bokstaver er utydelige, skal man ikke bruke <unclear> så lenge det er mulig å identifisere det aktuelle ordet gjennom slutninger fra kontekst.
kap-11.7: Tydeliggjøring
Til koding av tydeliggjøring, dvs. der hvor ord eller bokstav/er er overskrevet med det samme eller er gjentatt utenfor linjen for å gjøre utydelig skrift tydeligere, bruker vi elementet <clarification place="">.
Vi bruker place=""-attributtet for å markere om endringen er gjort på linjen eller utenfor linjen på samme måte som som vi bruker det i <add>.
<clarification place="inline">ord</clarification> <clarification place="offline">ord</clarification>
Når hånden som har tydeliggjort er en annen enn hovedhånden legges hand=""-attributt til, dvs. på tilsvarende måte som for hand=""-attributtet i <add>.
kap-11.7.1: Overskriving av tegn/bokstav/ord med samme tegn/bokstav/ord – <clarification place="inline">
<clarification place="inline"> brukes når tydeliggjøringen er gjort ved overskriving, jf. eksempel nedenfor. Det vil alltid være en grad av skjønn i bestemmelsen av om en overskrivning kan tolkes som en tydeliggjøring. I tilfeller hvor bare deler av tegnet/bokstaven er tydeliggjort (overskrevet) er dette særlig merkbart. Det er fornuftig å konsultere andre når man er i tvil om hvorvidt man skal kode med tydeliggjøring.
Sølvs<clarification place="inline">tøp</clarification>
Tydeliggjøring kan også utføres ved at tegnet/ordet er gjentatt på annen måte enn ved overskriving, f.eks. over linjen eller i margen, jf. eksempler nedenfor.
<clarification place="offline">Ja</clarification>, da lover jeg
stæ<clarification place="offline" hand="h1">n</clarification>gt
kap-11.7.3: Tydeliggjøring i tilknytning til andre endringer
Hvis det finnes andre rettelser i tilknytning til tydeliggjøringen brukes apparatkoding i stedet for <clarification>.

hal<app type="alteration"> <lem><add place="offline">vt</add></lem> <rdg><del rend="overwritten"><unclear>t</unclear></del>vt</rdg> </app>
kap-11.7.4: Tydeliggjøringer i trykt tekst
I brevene forekommer det enkelte ganger at Ibsen endrer med hånd i den trykte teksten. I noen tilfeller kombinerer vi da <clarification> med øvrige endringselementer, se Håndskriftsendring av pretrykt tekst.
kap-11.8: Hull i teksten – <space/>
<space/> skal ikke brukes til å beskrive manuskripters eller trykte kilders typografi (innrykk, luft mellom avsnitt etc.), men til å kode tomme linjer og hull i tekstlinjen.
Når det forekommer tilfeldige åpne linjer i replikkavsnitt eller hull i tekstlinjen (f.eks. plass satt av til et ord), brukes elementet <space/> med attributtet extent="" (med en godkjent attributtverdi, se attributtverdilisten).
<lb/><sp who="LIND"><spOpener><speaker rend="deviation">Lind </speaker>.</spOpener> <space extent="line"/><note resp="editor">Blank linje markert med store parentesbuer - har Ibsen satt av plass for senere tilføyelse?</note> <lb/><l part="M"><del rend="overstrike">Gaa foran!</del> Gaa forud.</l></sp> <lb/><sp who="FRUHALM"><spOpener><speaker>Fru Halm</speaker>.</spOpener> <lb/><l part="F">Kom saa med!</l></sp> <space extent="line"/><note resp="editor">Blank(e) linje(r) markert med store parentesbuer - har Ibsen satt av plass for senere tilføyelse(r)?</note>
Kodeeksempel fra KK8375
kap-11.9: Forkortede ord – <expan abbr="">
Når en bokstav i et ord er markert med tegn (såkalte nasalstreker) som markerer at enkel konsonant skal gjøres om til dobbel konsonant, koder vi med elementet <expan>. Den markerte bokstaven erstattes med dobbel konsonant, jf. eksemplet nedenfor, og som attributtverdi i abbr="" føres opplysning om hva slags markering bokstaven har i håndskriftet.
Foraarsblo<expan abbr="&mbar;">mm</expan>er
Kodeeksempel fra K1
Denne praksisen gjelder imidlertid bare for forkortelser markert med tegn. Normale forkortelser av typen «afs.», «Henr:», «etc.» osv. transkriberes som de står i teksten. De løses ikke opp, og de blir ikke kodet.
kap-11.10: Generelt om retningslinjer...
kap-11.10.1: ...for elementbruk
Til koding av endringer bruker vi <add> og <del> samt apparat-elementer (<app>, <lem> og <rdg>) i kombinasjon med <add> og <del>. Ved ikke-erstattende tilføyelser og frittstående strykninger bruker vi henholdsvis <add> og <del>. <add> og <del> kan brukes både alene eller i apparat, dvs. i <lem> og <rdg>, samt i hverandre.
- I <add> står tilføyd tekst (ord, bokstav/er eller tegnsetting)
- I <del> står slettet tekst (ord, bokstav/er eller tegnsetting)
- <add> og <del> skal alltid stå innenfor strukturelementer, jf. Tilføyelser som skal inneholde strukturelementer og Strykninger som skal inneholde strukturelementer.
- Alle apparater skal typologiseres (type=""). Når <app> brukes til endringer skal det alltid ha attributtet type="" med verdien «alteration»
- <app> inneholder <lem> og <rdg>. Rekkefølgen på elementene er obligatorisk: <lem> må stå foran <rdg>
- I <lem> kodes lesemåte(r) som er tilføyd (samt tilføyd og slettet) utenfor linjen
- I <rdg> kodes den erstattede lesemåten som står i linjen (enten den er slettet eller ikke)
- Manuskripttekst skal ikke gjentas i <lem>/<rdg>, mao. skal <lem>/<rdg> kun inneholde tilføyd eller strøket (evt. ikke-strøket, men antatt erstattet) tekst. Dette betyr også at flere endringer i ord/tekststed må kodes hver for seg
- Enkeltstående <add> og <del> kan inneholde apparater, <add> og/eller <del> hvis det er gjort endringer i det som først var tilføyd eller senere er slettet.
- I forbindelse med endringer som krysser strukturgrenser, må kodingen fragmenteres tilstrekkelig slik at ingen elementer krysser strukturer
- <restore> brukes ved gjenopprettet lesemåte
- <gap/> er en tom kode som brukes til å markere tekst som mangler, evt. med angivelse av en årsak for hvorfor teksten mangler
- I tillegg brukes ofte <unclear> for å markere at lesemåten er uklar og derfor usikker
- <clarification> brukes istedenfor apparat ved tydeliggjøring.
kap-11.10.2: ...for hvordan man begrenser størrelsen på apparatet
- Apparat brukes bare der det er gjort endringer utenfor linjen, «offline/infralinear»
- Man skal ikke ta med mer tekst enn selve endringen, selv om dette betyr at man tar med mindre enn et helt ord, alt som ikke er en del av endringen skal mao. utelates (NB: i de tilfellene hvor et ord er tilføyd utenfor linjen, mens ordet i linjen ikke er strøket, tas det ikke-strøkne ordet likevel med i <rdg>)
- Kodinga skal ikke gjenspeile skriveprosessen, men gi en diplomatarisk gjengivelse av endringene slik de er nedfelt på papiret. Det gjelder å dokumentere de enkelte endringene (tilføyelser, strykninger og substitusjoner) på mikronivå og hver for seg
Kriterier for spesialtilfeller:
- Der hvor enkeltreplikker splittes opp i flere replikker , unngås store apparater ved at man regner de nye <speaker>-elementene/replikkåpnerne som enkle tilføyelser. Det innebærer at bare mindre (lokale) endringer kodes i apparat, ikke hele formeringen av en replikk til mange. <sp>-kodingen følger den tekststrukturen som oppstår i og med tilføyelsen av disse elementene (de nye <sp>-taggene settes dermed ikke i apparat, men føyes inn der det er nødvendig, <spOpener> og <speaker> plasseres derimot innenfor <add>). Det samme gjelder verslinjer som splittes av replikksplittingen
- Når manuskriptet ikke fremviser noen ordnet lineær tekst, må kodingen rekonstruere teksten slik at den gir sammenheng og mening. Slik rekonstruksjon blir til som svar på spørsmålet om hvordan replikkene (tekstelementene) må ordnes for i det hele tatt å gi en meningsfull replikkveksling. Bare når elementene kan føyes sammen på to eller flere meningsgivende måter, blir det nødvendig å erklære (i <note resp="editor">) at transkripsjonen hviler på valg. Grunnteksten kan brukes som grunnlag for plassering og rekkefølge i et uordnet materiale.
Nedenfor følger et eksempel på koding og visning av en kompleks endring. <lem>-taggen i apparatet inneholder all koding som ligger over linjen, både tilføyelse og strøket tilføyelse, mens <rdg> inneholder kun det strøkne ordet i linjen.
<lb/><l>de<del rend="overwritten">n</del>t sidste <app type="alteration"> <lem><add place="offline" hand="CLD">Planke</add> <del rend="overstrike"><add place="offline">Stykke</add></del></lem> <rdg><del rend="overstrike">Levning</del></rdg> </app> han med sidste Kraft</l>
Eksempel fra C14936


kap-11.10.3: ...for behandling av blanke
Man skal ikke legge inn nye blanke mellom replikkelementer (<sp>) eller avsnitt/verslinjer som kommer på samme linje, siden disse er blokk-elementer. Blanke/luft mellom slike elementer ordnes via stilark. Nye blanke skal kun legges inn hvis det trengs inne i elementer, f.eks. i <spOpener> eller inne i <speaker>, <stage>, <p> eller <l>, dvs. i elementer hvor det er tillatt med tekst.
Merk at det ikke legges til blanke (for visningens skyld) når tegnsetting overskrives av bokstaver .
kap-11.11: Tilføyelser – <add>
Ved tilføyelser skal hånden som har gjort tilføyelsen, hvis denne er en annen enn hovedhånden, noteres i hand="" . I attributtet place="" skal det markeres hvor tilføyelsen er foretatt, jf. nedenfor.
Vi har definert attributtverdiene i place="" slik:
- «inBetweenLines»
- mellom avsnitt/linjer
- «infralinear»
- under linjen (lenger ned på siden i forhold til der tilføyelsen skal inn)
- «inline»
- i linjen; eller på begynnelsen/slutten av linjen (dette er altså ikke offline så lenge tilføyelsen kan sies å stå på samme linje som den øvrige teksten og selv om tilføyelsen strengt tatt står i margen)
- «margin»
- større tilføyelser (mer enn en linje tekst) gjort i marg, opp-ned, på lapper, baksiden av blad etc., se 11.1. Bør inneholde en <note resp="editor"> om hvor/hvordan tilføyelsen er gjort (noten plasseres fremst i <add>)
- enkeltord, enkeltuttrykk, mindre tilføyelser i margen: disse kodes i <add place="margin"> når de ikke tydelig hører til replikken de står ved siden av eller når de på andre måter synes løsrevet fra resten av teksten på siden.
- se for øvrig Store tilføyelser og tilføyelser i margen og på løse/limte/innbundne lapper/blad
- «offline»
- over linjen (høyere oppe på siden enn der tilføyelsen skal inn)
Man må tidvis bruke skjønn når man avgjør hvilken attributtverdi man skal bruke. En sammenlikning av visningen og manuskriptet vil også hjelpe til med avgjørelsen siden visningen skal være en tilnærmet diplomatarisk versjon av manuskriptet. Hvis man føler seg usikker kan man dessuten få litt hjelp på veien ved å se på disse eksemplene:
- «inBetweenLines»
- F1NT280 s. 218 (innskutt sceneoverskrift)
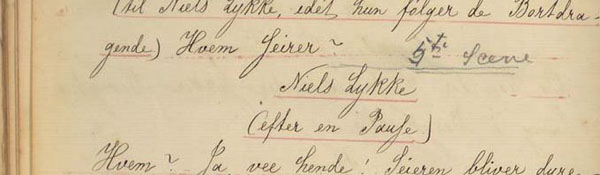
- KK8375 s. 7 (innskutt sceneanvisning)
- F1NT280 s. 218 (innskutt sceneoverskrift)
- «infralinear»
- OL82945 s. 2v (tilføyelse under linjen)
- OL82945 s. 2v (tilføyelse under linjen)
- «inline»
- F1NT280 s. 95 (tilføyet sceneanvisning etter rollenavn)
- F1NT280 s. 211 (tilføyelser til sceneanvisninger)
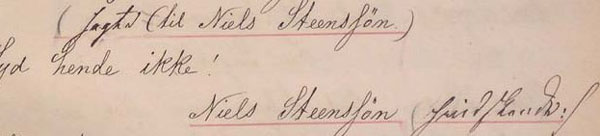
- F1NT280 s. 167 (rettet fra «6te» til «2den» scene)

- F1NT280 s. 95 (tilføyet sceneanvisning etter rollenavn)
- «margin»
- C14936 s. 2 (vertikal tilføyelse av verslinje i venstre marg)

- Vi41115b s. 115 (løsrevet ord ved siden av en replikk; det fremgår ikke klart hvor ordet hører til)

- C14936 s. 2 (vertikal tilføyelse av verslinje i venstre marg)
- «offline»
- Ro4262III2 s. 99 (tilføyet ord over linjen)

- Ro4262III2 s. 99 (tilføyet ord over linjen)
kap-11.11.2: Plassering av tilføyelsene
Vi plasserer tilføyelsene i xml-filen etter følgende retningslinjer:
- <add place="inline"> er alltid mulig å kode inn diplomatarisk, dvs. inline-tilføyelsen kodes inn der den står på siden. Et eksempel fra HH8808 (s. 17):
<sp who="TESMAN"> <spOpener><speaker>Tesman</speaker>.<add place="inline" hand="HI-2"><stage>(rejser sig.)</stage></add> </spOpener> - <add place="offline"> og <add place="infralinear">:
- dersom teksten er tilføyd vha. tilføyelsestegn, kodes tilføyelsen inn der hvor det er markert at den skal inn. Jf. eksempel på offline-tilføyelse i 11.1 (fra Ro4262III2, s. 99):
<lb/>og <add place="offline">med</add> de uædle øjne. - dersom den tilføyde teksten ikke har tilføyelsestegn, følger man førstetrykkets tekst hvis det er mulig og setter dessuten inn en note (<note resp="editor">) hvis vår plassering varierer mye fra den faktiske plasseringen på siden.
- dersom teksten er tilføyd vha. tilføyelsestegn, kodes tilføyelsen inn der hvor det er markert at den skal inn. Jf. eksempel på offline-tilføyelse i 11.1 (fra Ro4262III2, s. 99):
- <add place="margin">:
- dersom Ibsen bruker referansetegn, dvs. at selve tilføyelsen samt det stedet der teksten skal tilføyes, er merket med referansetegn, plasseres tilføyelsen så diplomatarisk som mulig. I slike tilfeller benyttes koding med <ref type="refMark">, og tilføyelsestegnene er klikkbare i visningen. For retningslinjer se Referansetegn som markerer tilføyelser og deres plassering.
- dersom den tilføyde teksten ikke har tilføyelsestegn, følger man førstetrykkets tekst hvis det er mulig og setter dessuten inn en note (<note resp="editor">) hvis vår plassering varierer mye fra den faktiske plasseringen på siden. I følgende eksempelet fra BS41292 medfører en plassering som følger førstetrykket, at en replikk må splittes opp. De to delene av replikken forbindes vha. join-koding, se Delte replikker i kapitlet om lenking.

<lb/><join targets="HILDE_1 HILDE_2" targOrder="Y"/> <lb/><sp who="HILDE" id="HILDE_1"><spOpener><speaker>Hilde</speaker> <lb/><stage>(afvissende.)</stage></spOpener> <lb/><p>Nej da! Fy! Det kendte jeg da vel indvendig at De ikke <lb/>var.</p></sp> <add place="margin"> <note resp="editor">Tilføyelsen er plassert i høyre marg, på høyde med Solness' replikk <q>Det rigtige?</q>. Tilføyelsen mangler tilføyelsestegn, følger derfor førstetrykket.</note> <lb/><sp who="HILDE"><p>For ellers kunde De jo ikke ståt <lb/>og sunget deroppe.</p></sp> <sp who="SOLNESS"><p>– Sunget? Sang <lb/>jeg?</p></sp> <sp who="HILDE"><p>– Ja, det gjorde De da rigtignok.</p></sp> <sp who="SOLNESS"><p>– Jeg har <del rend="overwritten"><gap/></del>aldrig <lb/>sunget en tone i mit liv.</p></sp> <sp who="HILDE"><p>– Jo, De sang. Det hørtes <lb/>som harper i luften.</p></sp> <sp who="SOLNESS"><spOpener><speaker>S.</speaker> <stage>(tankefuld)</stage></spOpener><p>Det er noget for&typHyp; <lb/>underlig noget, dette her.</p></sp> </add> <lb/><sp who="HILDE" id="HILDE_2"> <spOpener><stage>(tier en stund, ser på ham og siger <del rend="overstrike">sagt</del> <del rend="overwritten"><gap/></del>dæmpet:)</stage></spOpener> <lb/><p>Men så, – bagefter, – så kom jo det rigtige.</p></sp>
Store tilføyelser, dvs. på minst en linje (det kan være illustrerende å tenke på tilføyelsen som en egen tekstblokk i teksten), gjort i marg, ved siden av, over eller under øvrig tekst, vertikalt, opp-ned, diagonalt etc., eller på løse/limte/innbundne lapper/blad, kodes med <place="margin"> og med <note resp="editor"> med opplysning om hvordan tilføyelsen er gjort. Noten plasseres rett innenfor tilføyelsens start-tagg, altså foran den tilføyde teksten. Evt. sitater fra teksten i <note resp="editor"> kodes med <q>. Etter noten kodes selve tilføyelsen. Alle linjeskift vil dermed ligge inne i <add>, som i foregående eksempel. Faksimilene fra FH41116 nedenfor illustrerer også hva som skal kodes som <add place="margin">.

<lb/><stage>(Hun sætter skammelen foran gyngestolen.)</stage> <add place="margin"><note resp="editor">Tilføyelsen står i høyre marg.</note> <lb/><sp who="BOLETTE"><spOpener><speaker>B.</speaker> <lb/><stage>(l. af<gap/>)</stage></spOpener> <lb/><p>Så De ikke noget til fars båd ude <lb/>på fjorden?</p></sp> <lb/><sp who="LYNGSTRAND"><spOpener><speaker>L.</speaker></spOpener> <lb/><p>Jo, jeg syntes jeg så en, som styred <lb/>indover.</p></sp><pb ed="HU" n="58"/> <lb/><sp who="BOLETTE"><spOpener><speaker>B.</speaker></spOpener> <lb/><p>Det var visst far. Han har været <lb/>ude <del rend="overstrike">p</del> i sygebesøg på øerne.</p></sp> </add> <lb/><sp who="LYNGSTRAND"><spOpener><speaker>Løvstad</speaker> <lb/><stage>(et trin oppe på trappen til verandaen.)</stage></spOpener> <lb/><p>Nej, her er da rigtig staseligt med blomse<del rend="overwritten">t</del>r –</p></sp>

<pb n="80"/> <add place="margin"><note resp="editor">Tilføyelsen står øverst på siden, i høyre marg.</note> <lb/><p>Han talte jo med far i eftermiddag. <lb/>Jeg gad vide hvad far mener om ham</p> </add> <lb/><p>Ja det er det rigtignok. ...

<lb/><sp who="FRUALVING"><spOpener><speaker>Fru A</speaker></spOpener> <lb/><p>Ja, ja, jeg lover dig det; men bare tal!</p></sp> <add place="margin"> <note resp="editor">Eget dobbeltblad med tilføyde replikker. Den tilføyde teksten skal antagelig inn etter <q>Jeg tror det var galt, dette her.</q> i legg 24, bl.1v.</note> <pb/> <lb/><fw type="gathering" place="top-left"><gap reason="binding"/><unclear reason="binding">4</unclear>a</fw> <lb/><sp who="FRUALVING"><spOpener><speaker>Fru A:</speaker></spOpener> <p>Osvald, har det rystet dig stærkt?</p></sp> <lb/><sp who="OSVALD"><spOpener><speaker>Osv.</speaker></spOpener> <p>Alt dette om far, mener du?</p></sp> <lb/><sp who="FRUALVING"><spOpener><speaker>Fru A</speaker></spOpener> <p>Ja, om din ulykkelige far. Jeg er så bange, det <lb/>skal ha' virket for stærkt på dig.</p></sp> ... <lb/>til mig. For jeg ser det nok; <del rend="overstrike">d</del> jeg har dig ikke; du <pb/> <lb/>må vindes.</p></sp> <pb/> <pb/> </add>
kap-11.11.4: Strøket tilføyelse
Når et ord er tilføyd og deretter strøket og tilføyelsen dermed forsvinner med strykningen, koder vi slik:
<add place="margin"> <note resp="editor">Tilføyelsen er gjort i venstre marg.</note> <del rend="overstrike"> <lb/><sp who="SAETERJENTER"><spOpener><speaker>Første Jente</speaker></spOpener> <lb/><l part="I">Ikke Svig forstaar du!</l></sp> <lb/><sp who="SAETERJENTER"><spOpener><speaker>Anden</speaker></spOpener> <l part="F">Nej var det ligt!</l></sp> <lb/><sp who="SAETERJENTER"><spOpener><speaker>Trede</speaker>.</spOpener> <lb/><l><app type="alteration"><lem><add place="offline">De er langvejs. Og <unclear>saa har De</unclear> Forfald og sligt.</add></lem> <rdg><del rend="overstrike">Nej d</del></rdg></app></l></sp> </del> </add>
Eksempel fra PG42869

kap-11.11.5: Sideskift i lengre tilføyelser
Sideskift innenfor lengre tilføyelser kodes med <pb/>, jf. eksempel fra Ge41114 over.
kap-11.11.6: Linjeskift
kap-11.11.6.1: ... i tilføyelser generelt
Vi transkriberer linjeskift for alle linjer inkl. første linje, i tilføyelser gjort «inBetweenLines» og i «margin». For tilføyelser med de øvrige attributtverdiene kodes det ikke inn linjeskift, jf. også nedenfor om offline-tilføyelser.
kap-11.11.6.2: ... i lengre offline-tilføyelser
Linjeskift inne i tilføyelsen normaliseres vekk i transkripsjonen av lengre tilføyelser som skal kodes med attributtverdien «offline».
kap-11.11.6.3: ... i lengre inline-tilføyelser
Linjeskift inne i tilføyelsen inkluderes i transkripsjonen av lengre tilføyelser som skal kodes med attributtverdien «inline» i tilfeller som likner dette:
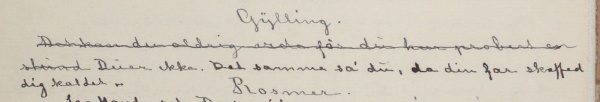
kap-11.11.7: Tilføyelser som skal inneholde strukturelementer
At det ifølge DTD'en er tillatt å kode med <add> og <del> uten strukturkoding, skyldes at vi har tillatt bruk av <add> og <del> tilnærmet overalt og at <add> og <del> kan inneholde ren tekst. Dette er dermed en uheldig konsekvens av DTD-endringer vi har gjort. Mellom replikker er dette valid, men logisk gal koding:
</sp> <add ...>tilføyd tekst</add> <sp ...>
Her skal det kodes med struktur inne i <add>. Tanken er at man alltid skal legge til det som er nødvendig av struktur for at kodingen ville være valid uten <add> eller <del>. Hvis det er replikktekst som er tilføyd kodes det slik:
</sp> <add ...> <sp who=""> <p>tilføyd tekst</p> </sp> </add> <sp ...>
I en del tilfeller gjøres tilføyelsen for langt unna det stedet den skal føyes inn på til at Ibsen bruker vanlige innføyningstegn. Da markeres innføyningsstedet og tilføyelsen med tegn som viser sammenhengen. Tegnene kan f.eks. være stjerner, tall eller bokstaver. For alle stjerner, kryss osv. samt tegn som ikke lar seg transkribere (f.eks. innføynings-hake/v), setter vi inn entiteten &referenceMark;. Når det er brukt bokstaver evt. i kombinasjon med tegnsetting, transkriberes disse som vanlig. Se for øvrig Noter med referanse i teksten i detaljkapitlet.
Vi koder tegnene med <ref type="refMark" target="" id=""> slik at det er mulig å lage lenker mellom tilføyelsen og innføyningsstedet. Her er et eks.:
S. 67, det markerte innføyningsstedet: <pb/> <lb/><note resp="author" place="top-left">NB</note><ref type="refMark" target="n1" id="nb1">&referenceMark;</ref> <lb/><stage>(Mellem Ronderne. Solnedgang. Skinnende Sne&typHyp; <lb/>toppe rundt om.)</stage> S. 68, tilføyelsen: <add place="margin"><note resp="editor">Tilføyelsen er skrevet på et løst dobbeltblad (av et annet format enn hoveddelen av manuskriptet).</note> <lb/><fw type="leaf" place="top-right" hand="h1">35</fw> <lb/><note resp="author" place="top-left">NB</note><ref type="refMark" target="nb1" id="n1">&referenceMark;</ref> <lb/><sp who="PEERGYNT"><spOpener><speaker>Peer Gynt</speaker></spOpener> <lb/><l>Slot over Slot sig bygger!</l> <lb/><l>Kors, for en skinnende Port!</l> ... </sp>
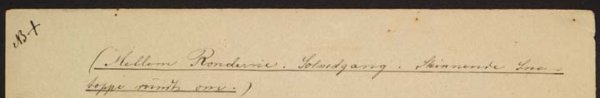

Som ellers avgjør vi etter skjønn og (der det er mulig) etter sammenlikning med senere manuskripter og/eller førstetrykket i de tilfellene hvor vi ikke umiddelbart kan si hvilke tilføyelser som hører til hvor (f.eks. fordi det er brukt samme tegn til markering av begge tilføyelser eller fordi et referansetegn mangler).
kap-11.11.8.1: Når ett referansetegn mangler
I tilfeller hvor ett av referansetegnene mangler (uansett om det skulle stått ved tilføyelsen eller i teksten), bruker elementet <ptr type="refMark" target="" id=""/> for å markere det manglende tegnet. Det tomme elementet skal i visningen generere referansetegnet vårt og som ellers være klikkbart.
kap-11.11.8.2: Når ett referansetegn viser til flere referansetegn
På s. 16 i HG8808 refererer teksten «flyttes ind» til en tilføyelse i høyre marg. Tilføyelsen består av replikker og er markert to steder med samme referansetegn (tall+parentes). Vi koder tilføyelsen som en enkelt tilføyelse og alle referansetegnene med <ref type="refMark">, men utelater attributtene target="" og id="" for det andre tegnet. «flyttes ind» kodes sammen med et <ptr type="refMark" target="" id=""/>-element (for at man skal kunne klikke seg til tilføyelsen) i <note resp="author"> og videre i <add place="margin">. Tilføyelsen plasseres diplomatarisk.
<lb/>Men sig mig så, – har du nu fåt st dig rig&typHyp; <lb/>tig om i lejligheden?</p></sp> <add place="margin" hand="HI-2"> <note resp="editor">Tilføyelsen står i høyre marg.</note> <lb/><ref type="refMark" target="nb2" id="n2">1.)</ref> <sp who="TESMAN"><spOpener><speaker>Tesman</speaker></spOpener> <lb/><p>Udmærket. Der er <lb/>bare det at der er et <lb/>par tomme værelser <lb/>mellem bagstuen <lb/>der og soverværelserne</p></sp> <lb/><sp who="FRØKENTESMAN"><spOpener><speaker>Fr. T.</speaker></spOpener> <lb/><ref type="refMark">1.)</ref> <note resp="editor"><q>flyttes ind</q> viser sannsynligvis både til referansetegnet foran <q>Tesman</q> og dette referansetegnet.</note> <p>Å dem blir der <lb/>vel med tiden <lb/>brug for.</p></sp> <lb/><sp who="TESMAN"><spOpener><speaker>T.</speaker></spOpener><p>Ja ja, du mener <lb/>når jeg har fåt min bogsamling</p></sp> </add> <lb/><sp who="TESMAN"><spOpener><speaker>Tesman</speaker>.</spOpener> <lb/><p>Ja, det kan du da vel tænke.</p></sp> ... <lb/>noget andet steds end i statsrådinde Falks <lb/>villa.</p></sp> <add place="margin"> <note resp="author" hand="HI-2"> <ptr type="refMark" target="n2" id="nb2"/>flytt<unclear reason="writing">es</unclear> ind<gap/> </note> </add> <lb/><sp who="FRØKENTESMAN"><spOpener><speaker>Frøken Rising</speaker>.</spOpener>

kap-11.11.8.3: Referansetegn uten tilføyelse
Referansetegn som ikke viser til noe, kodes med <ref type="refMark"> uten attributtene target="" og id="" samt en <note resp="editor"> om at referansetegnet ikke viser til noe.
<lb/><sp who="HEDDA"><spOpener><speaker>Hedda</speaker>.</spOpener>
<lb/><p>Men til mig, kære –. Herre gud, vi gik
<lb/>jo i institutet sammen.
<add place="margin"><ref type="refMark">&referenceMark;</ref>
<note resp="editor">Det er ikke funnet noen tekst å lenke til dette referansetegnet.</note></add>
</p></sp>
<lb/><sp who="FRUELVSTED"><spOpener><speaker>Fru Elfsted</speaker>.</spOpener>
<lb/><p>Men siden er vi da kommen så langt –
<lb/>langt ifra hinanden.</p></sp>

Det hender at Ibsen har satt inn referansetegnet på feil sted og så strøket det. Referansetegnet kodes da med <ref type="refMark"> uten attributtene target="" og id="" og i <del rend="overstrike">.
kap-11.12: Slettet tekst – <del>
kap-11.12.1: Retningslinjer
Faktisk strykning: Vi har vedtatt at vi koder kun de tegnene/ordene som er strøket. Selv om det tidvis vil være åpenbart at også f.eks. tegnsetting er ment strøket, tar vi ikke disse tegnene med i <del>-taggen. Dette skyldes at det ikke alltid er mulig å endelig avgjøre hva som er ment strøket, og å kode diplomatarisk innebærer derfor mindre grad av tolkning.
Hånd: Når en annen hånd enn hovedhånden har utført slettingen, skal dette noteres i hand="".
Type: Måten slettingen er utført på markeres i rend="". Disse verdiene er i bruk:
- erased="" – utvisket
- overstrike="" – overstrøket
- diagonalOverstrike="" – ved store diagonale e.l. strykninger
- overwritten="" – overskrevet
- <del type="checkList" rend="overstrike"> – strykninger i «huskelister»
Om bruken av de enkelte verdiene se avsnittene nedenfor.
Om inkomplette/unøyaktige strykninger i substitusjoner, se 14.3.
kap-11.12.2: Overstrykninger
kap-11.12.2.1: «Vanlige» strykninger
Når et ord er strøket, koder vi det slik:
de gamle og erfarne blandt os mente, <del rend="overstrike">at</del> det stod skrevet hist oppe
Kodeutdrag fra F274 (linjeskift er utelatt)
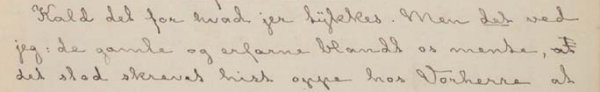
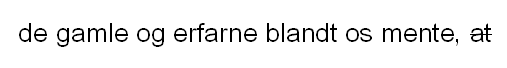
Når et ord er påbegynt, og deretter strøket før det er fullført, og hvor teksten umiddelbart løper videre, koder man kun ren strykning, erstatningsordet kodes ikke. Hvis påfølgende ord åpenbart er tilføyd (av annen hånd, eller det er presset inn i teksten), kodes dette ordet med <add place="inline">.
Store strykninger (f.eks. sider som er strøket med X- eller 8-talls-liknende kryss eller med diagonale streker) kodes med en egen rend-verdi, «diagonalOverstrike». I utgangspunktet får hvert kryss sin egen <del rend="diagonalOverstrike">-tagg. Foliering tas ikke med innenfor <del rend="diagonalOverstrike">, siden denne ikke regnes som strøket selv om teksten på siden er strøket. Også forfatternoter og evt. andre tekstelementer som ikke skal regnes som strøket, holdes utenfor elementet, og det medfører at <del rend="diagonalOverstrike"> avsluttes og at en ny <del rend="diagonalOverstrike"> påbegynnes igjen etterpå. Som en konsekvens av at vi koder hvert kryss/8-tall i en egen <del rend="diagonalOverstrike">, må man altså av og til splitte opp i flere elementer på en og samme side for å unngå kryssende strukturer.
Når et rollenavn som er strøket horisontalt ser ut til å begynne en lengre stor strykning og derfor umiddelbart etterfølges av et kryss over resten av replikken (evt. mere), er det fornuftig å la <del rend="diagonalOverstrike"> begynne foran hele replikken selv om det strengt tatt ikke er diplomatarisk, siden vi da sannsynligvis slipper å fragmentere kodingen. Hvis deler av det som er krysset ut også er strøket med horisontale streker, særlig hvis dette er skjedd i begynnelsen av det strøkne partiet, er det fint om dette blir kodet inn, siden det kan belyse Ibsens skriveprosess.
Vi regner det som at store/omfattende strykninger dekker hele linjer og ikke enkelttegn, slik <del rend="overstrike"> gjør. Dermed tas f.eks. hele l. 8 med innenfor <del rend="diagonalOverstrike"> i Ro41291, s. 227, jf. faksimile-eksempler nedenfor.
<lb/><del rend="diagonalOverstrike"> <div type="relatedToWork" n="1"><div type="act" n="1"><head>Anden Act. –</head> <lb/><div type="scene" n="1"><head>Et Værelse i Catilinas Huus</head> <lb/><p> ... <lb/>er iblandt dem – de ile alle afsted –</p></div></div></div></del>

Her er et eksempel fra FH41116, s. 196:
<lb/><sp who="ELLIDA"><spOpener><speaker>Ellida</speaker>.</spOpener> <lb/><p>Jeg <emph>må</emph> tale med ham selv. <del rend="diagonalOverstrike"><del rend="overstrike">Vil ikke du g</del>i&rapo; <lb/><del rend="overstrike">mig fri, så må han gøre det. Et af ægtesk</del>a&typHyp; <lb/><del rend="overstrike">berne må løses</del>.</del></p></sp> <del rend="diagonalOverstrike"> <lb/><sp who="WANGEL"><spOpener><speaker> <del rend="overstrike">Wange</del>l</speaker>.</spOpener> <lb/><p><del rend="overstrike">Du har selv løst det forhold, som du i syg</del>e&typHyp; <lb/><del rend="overstrike">lig overspændthed kalder et ægteskab. Du har <lb/>løst det og det er nok.</del></p></sp> <lb/><sp who="ELLIDA"><spOpener><speaker>Ellida</speaker>.</spOpener> <lb/><p>Nej nej, det er ikke nok. Hvad hjælper det <lb/>at du kommer med tusende fornuftsgrunde. <lb/>Det nytter mig ikke det mindste når jeg selv <lb/>føler det anderledes.</p></sp> <lb/><sp who="WANGEL"><spOpener><speaker>Wangel</speaker>.</spOpener> <lb/><p>Og det gør du altså fremdeles.</p></sp> </del>

Flere eksempler på omfattende strykninger, som (bare) kodes med rend="diagonalOverstrike"="" (kun faksimiler):

kap-11.12.2.3: «Dobbel» strykning
Når et ord er strøket to ganger, dvs. i to omganger, koder vi med <del> i <del>:
<lb/><stage>( <app type="alteration"> <lem><add place="offline">skrigende</add></lem> <rdg> <del rend="overstrike" hand="h1"> <del rend="overstrike">springer op</del> </del></rdg></app>)</stage>
Kodeutdrag fra Sa872r
<lb/><sp who="GREGERS"><spOpener><speaker><del rend="overstrike">Gregers</del></speaker>.</spOpener> <lb/><p><del rend="overstrike"><del rend="overstrike">Ja ser du</del>, <del rend="overstrike">for vi er ikke slig, hv</del></del><gap/> <lb/><del rend="overstrike">Ja det er nok ikke tvil om at de</del>t <lb/><del rend="overstrike">er mig som har set fejl</del>.</p></sp>
Kodeutdrag fra Vi41115b

kap-11.12.2.4: «Tomme» strykninger
Ibsen har noen steder i manuskriptene sine lagt inn overstrykningsstreker over én eller flere linjer. Disse koder vi inn som tomme linjer (vi legger mao. inn en <lb/> for hver linje) og vi noterer samtidig fenomenet i en <note resp="editor">. Noten plasseres foran strekene.
<lb/><stage>(Dovregubbens Kongshal. Stor Forsamling af <lb/><stageRole>Trolde</stageRole>. <stageRole who="DOVREGUBBEN">Dovregubben</stageRole> i Højsædet med Krone og <lb/>Spir. <stageRole who="PEERGYNT">Peer Gynt </stageRole> staar for ham. Stor Allarm <lb/>mellem <stageRole who="HOUGFOLK">Hougmænd</stageRole>, <stageRole>Tomtegubber</stageRole> og <stageRole who="HOFTROLD">Hoftrolde</stageRole>.)</stage> <note resp="editor">Ibsen har her laget 13 linjer med «overstrykningsstreker». Disse er ikke transkribert, men linjeskiftene er kodet inn.</note> <lb/> <lb/> <lb/> <lb/> <lb/> <lb/> <lb/> <lb/> <lb/> <lb/> <lb/> <lb/> <lb/>
Eksempel fra PG42869

kap-11.12.2.5: Strykninger som skal inneholde strukturelementer
Det hender at Ibsen begynner på feil sted når han skriver av et manuskript, f.eks. har vi sett at han begynner direkte på replikktekst før han har skrevet inn replikkinnehavers navn eller før han har skrevet inn sceneanvisning etter replikkinnehavers navn. Her er to typiske eksempler:
Vi koder i slike tilfeller den strukturen som blir strøket, inn i <del>. Denne kan vanligvis bestemmes ut fra gjenkjennelse av påbegynt tekst et annet sted på siden, den grafiske plasseringen av tekstelementet på siden, parentesbruk osv. Som en slags tommelfingerregel kan man si at <add> og <del> må inneholde det som skal til av kode for at kodingen ville vært valid uten <add> og <del>. I det første tilfellet kodes det derfor med <sp> og <p> inne i <del>:
<sp who=""> ... </sp> <del> <sp who=""> <p>strøket tekst</p> </sp> </del> <sp who=""> ... </sp>
Her kan who="" brukes i <sp>, siden replikkinnehaveren med rimelig sikkerhet kan regnes som identifisert. Det er viktig å være noe varsom med å bestemme hvilken replikkinnehaver den påbegynte replikken tilhører, siden det alltid innebærer en viss grad av fortolkning og usikkerhet. Er man i tvil, bør man la være å bruke who="", se id="" og det tilhørende who="" i dramakapitlet.
I det andre tilfellet kodes det med <p> inne i <del> selv om det er tillatt med tekst direkte i <spOpener> og selv om <p> ikke er tillatt direkte i elementet. Her er den underliggende tanken at det påbegynte elementet var et avsnitt, som derfor skulle kodes med <p>, og at det påbegynte avsnittet så ble strøket/fjernet.
<sp who=""> <spOpener> <speaker>replikknavn</speaker> <del><p>strøket tekst</p></del><stage>...</stage> </spOpener> </sp>
Det vil alltid være skjønn inne i bildet når man skal avgjøre om det er riktig å kode med eller uten struktur i slike tilfeller. Det avhenger ikke bare av hvor mye som er strøket (eller tilføyd), men også av hvordan man forstår endringen (hva har skjedd?) og hva slags tekstelementer man tror det er som er strøket (eller tilføyd); kan man identifisere det som replikk? Eller bare som prosa? Hvis det er replikk, er det mulig å identifisere replikkinnehaver? Vi er enige om at man må være rimelig sikker før man identifiserer replikkinnehaver. I Ro4262III2 finnes et eksempel hvor det er mulig å identifisere det strøkne ikke bare som en replikk (pga innholdet og det grafiske oppsettet til den strøkne teksten), men også identifisere replikkinnehaver og derfor både legge inn attributtverdi i who="" og lenke sammen de tre delene av den strøkne replikken.

<pb n="184"/> <lb/>gens og sejrens store hemmelighed. <del rend="overstrike">Basta!</del> <lb/>Det er summen <del rend="overstrike"><sp who="ROSMER" id="ROSMER-1"><spOpener><speaker>Rosmer</speaker></spOpener></sp></del> af al verdens vis&typHyp; <lb/>dom. Basta!</p></sp><del rend="overstrike"><sp who="ROSMER" id="ROSMER-2"><stage>(lavmælt.)</stage></sp></del> <lb/><del rend="overstrike"><sp who="ROSMER" id="ROSMER-3"><p>Nu skønner jeg at <gap/></p></sp></del><join targets="ROSMER-1 ROSMER-2 ROSMER-3" targOrder="Y"/> <lb/><sp who="ROSMER"><spOpener><speaker>Rosmer</speaker> <lb/><stage>(lavmælt.)</stage></spOpener> <lb/><p>Nu skønner jeg – at De går herfra fattige&typHyp; <lb/>re end De kom.</p></sp>
Kodeutdrag fra Ro4262III2
I FH4262III3 finnes et eksempel på en liten overskrivning, som kanskje kan være en feilaktig begynnelse på en replikkinnehaver, men som er så minimal at vi har valgt å ikke kode inn strukturelementer:
Eksempel fra FH4262III3

At det ifølge DTD'en er tillatt å kode med <add> og <del> uten strukturkoding på slike steder, skyldes at vi har tillatt bruk av <add> og <del> tilnærmet overalt og at <add> og <del> kan inneholde ren tekst. Dette er dermed en uheldig konsekvens av DTD-endringer vi har gjort.
Se også Tilføyelser som skal inneholde strukturelementer for parallelle tilfeller med <add>.
kap-11.12.3: Overskrevet tekst
kap-11.12.3.1: Hovedhåndens overskrivninger
Når et ord/en del av et ord er overskrevet av hovedhånden, koder vi det slik (legg merke til at det ikke skal være mellomrom mellom sluttaggen for <del> og det etterfølgende ordet og at det ikke skal kodes med <add> for tilføyelse):
<lb/><sp who="MERETA"><spOpener><speaker> <del rend="overwritten">Paal</del>Mereta</speaker></spOpener> ... </sp>
Kodeutdrag fra RJ4932

kap-11.12.3.2: Overskrivning og tilføyelse
Når overskrivingen er gjort av en annen hånd (dvs. f.eks. tydelig separat revisjonsomgang; annen blekkfarge, avvikende skriftkarakter og/eller annen persons håndskrift) skal det kodes med både <del rend="overwritten">- og <add place="inline" hand="">-elementer, slik at vi kan vise hva som er tilføyd. hand-attributtet skal bare brukes i <add>, ikke i <del>. Det skal ikke være mellomrom mellom </del> og <add>, jf. kodet eksempel.
<lb/><p>Ja men Gud bevares! <del rend="overwritten">De</del><add place="inline" hand="HI-1">Saa</add> maa
Kodeutdrag fra Sa872s

tungsindige<del rend="overwritten">.</del><add place="inline">endda.</add>
Kodeutdrag fra FH41116

kap-11.12.3.3: Usikker rekkefølge ved overskriving
Vi skiller mellom tilfeller hvor det er mulig å angi den sannsynlige rekkefølgen og tilfeller hvor det er umulig.
I tilfeller hvor det er mulig å sette opp den sannsynlige rekkefølgen i en endring (f.eks. pga. endringens utforming eller forhold i konteksten), kodes lesemåtene på vanlig måte, jf. ovenfor. Det er ikke nødvendig å opplyse om usikkerheten her.
I tilfeller hvor det er umulig å si hva som er sannsynlig rekkefølge i endringen, opplyses det om dette i <note resp="editor">. Noten plasseres etter ordet tegnet inngår i (eller hvis det er snakk om tegnsetting, rett etter tegnet/ene).
kap-11.12.3.4: Når bokstav overskriver tegnsetting
Når en bokstav (vanligvis begynnelsen på et nytt ord) overskriver foregående tegnsetting, koder vi overskriving som vanlig og legger ikke inn noe ekstra mellomrom i kodingen for visningens skyld. Overskrivningstegnene som genereres i visningen er tilstrekkelig som mellomrom mellom ordene.
kap-11.12.3.5: «Dobbel» overskrivning
I sjeldne tilfeller er ord skrevet over flere ganger, jf. eks. nedenfor. Kodemønsteret i eks. skal brukes.
<del rend="overstrike"> <del rend="overwritten"><unclear>er</unclear></del> <del rend="overwritten"><unclear>tror</unclear></del>kan jeg rædd </del>
Kodeutdrag fra Br4262I11. Kun relevant koding er tatt med.

<lb/> og <pb/> er ideell koding av linje- og sideskift. Disse kan plasseres hvor som helst i kodinga, men skal etter våre prinsipper så vidt mulig plasseres utenfor strukturelementer av typen <lg>, <l>, <p>, <sp>, <div> etc.
<fw> plasseres imidlertid bare inne i strykninger der hvor innholdet av <fw> også er strøket. Er innholdet derimot ikke strøket, f.eks. når en slettet replikk krysser et sideskift med ustrøket sidenummerering, må kodingen av strykningen splittes i to sånn at sidenummereringen blir stående mellom de to delene av strykningen. Dette er i overenstemmelse med at vi kun koder faktisk strøket tekst og for at visningen av endringen skal bli fornuftig.
kap-11.13: Substitusjon – <add> og <del> sammen
kap-11.13.1: Inline-substitusjoner
Substitusjoner som er gjort i linja skal kodes med diplomatarisk plasserte <add>- og <del>-elementer. Dette gjøres for strykning med åpenbart tilhørende tilføyelse; tilføyelser kodes bare hvis de faktisk forstyrrer det opprinnelige tekstbildet (annen hånd, presset inn i teksten e.l.), hvis ikke kodes kun strykning. Legg merke til at det her skal være naturlig mellomrom mellom ordene.
<lb/>optræder kun sporadisk. – K<del rend="overstrike" hand="HI-2">om s</del>å <lb/><del rend="overstrike" hand="HI-2">her, Molvik</del> <add place="inline" hand="HI-2">Tak for maden!</add>
Det hender at bokstaver eller tegnsetting er endret til nye tegn ved at deler av tegnet er strøket over og/eller overskrevet.
Man må bruke skjønn i kodingen siden det ikke alltid er enkelt å se hva slags endring som er foretatt. Ved usikkerhet skal man legge inn en <note resp="editor"> som gjør oppmerksom på fortolkningen man har gjort. Noten plasseres etter ordet tegnet inngår i (eller hvis det er snakk om tegnsetting, rett etter tegnet/ene).
Vi bruker vanligvis attributtverdien «overwritten» til disse endringene.
Her er et eksempel som viser koding og transkripsjon av en ø som er endret til æ ved at tødlene over ø er overstrøket.
pr<del rend="overwritten">ø</del>ægtigt
Kodeutdrag fra BE42869
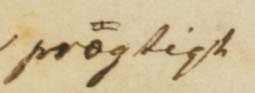
I noen tilfeller er det egentlig umulig å transkribere riktig siden tegnet ikke lar seg dele i to, jf. faksimilene nedenfor. Man kan likevel transkribere tegnene og kode som over.
Verdenskoret<del rend="overstrike">;</del>.
Kodeutdrag fra BE42869
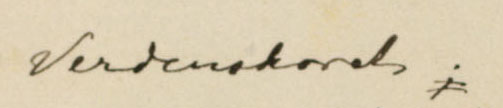
Døren<del rend="overwritten">!</del>;
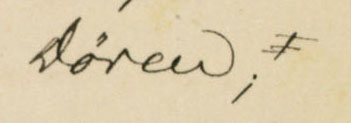
Alternativt kan man transkribere det endelige tegnet og legge inn en note som forklarer endringen (notetekstene i eks. nedenfor er veiledende). Det opprinnelige tegnet transkriberes i slike tilfeller ikke, og det endelige tegnet kodes ikke.
det?<note resp="editor">Semikolon endret til spørsmålstegn ved delvis overskriving.</note>
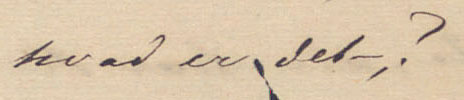
kap-11.13.3: Større substitusjoner
Når en stor tilføyelse erstatter en større strykning , skal tilføyelsen plasseres foran strykningen. Det spiller ingen rolle om strykningen er gjort ved «overstrike» eller «diagonalOverstrike». Erstatningen skal ikke kodes i apparat.
kap-11.14.1: Generelle retningslinjer
Når substitusjonen er gjort ved at tekst i linjen er strøket og erstattet av tekst tilføyd over eller under linjen tilnærmet ovenfor eller nedenfor det strøkne, bruker vi <app> (som inkl. <lem> og <rdg>) med <add> og <del>. Det skal da også gjerne være en erstattende funksjon i det som tilføyes, men kodingen kan også brukes når det er snakk om ufullførte endringer, jf. Ufullførte endringer.
Det er viktig at deler av lesemåten aldri gjentas i <lem> og <rdg>. Kodingen må fragmenteres nok til at det ikke skjer.
Her er et enkelt, men typisk eksempel på en substitusjon som skal kodes i <app>:
kæreste søster, sovet <app type="alteration"> <lem><add place="offline">i ligkælderen.</add></lem> <rdg><del rend="overstrike">tre alen under muld.</del></rdg> </app>
Kodeutdrag fra F28950

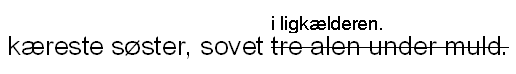
Her er «alvors» trukket ut av apparatet slik at teksten ikke blir gjengitt to ganger (både som del av <lem> og <rdg>):
alvors<app type="alteration"> <lem><add place="offline">tungt</add></lem> <rdg><del rend="overstrike">stærkt</del></rdg> </app>
Kodeutdrag fra BE42869
Her er et eksempel på tilføyelse under linjen.
en halvglemt <app type="alteration"> <lem><add place="infralinear">skibbrud</add></lem> <rdg><del rend="overstrike">drø</del>m</rdg> </app> i mit liv.

kap-11.14.2: Eksempler på substitusjoner
Endringene som er gjort over linjen legges diplomatarisk etter hverandre i <lem> og kodes hver for seg med <add> og <del> slik endringen krever.
PG428692:
Benene gaar som Trommestikker raske. <del rend="overwritten">h</del>Hm; Hun er <app type="alteration"> <lem><add place="offline">sandili</add> <del rend="overstrike"><add place="offline">egentlig</add></del> <del rend="overstrike"><add place="offline">virkelig</add></del></lem> <rdg><del rend="overstrike">igrunden</del></rdg> </app> <app type="alteration"> <lem><add place="offline">lækker</add></lem> <rdg><del rend="overstrike">vakker</del></rdg> </app>, den Taske.
Eksemplet er hentet fra PG428692
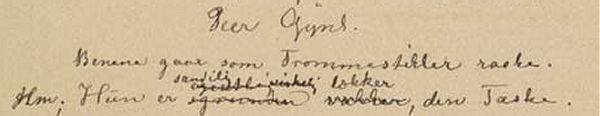

KK8375:
<lb/><l>Nu har jeg <app type="alteration"><lem> <add place="offline"><add place="offline">mistet</add><del rend="overstrike">avlet</del></add></lem> <rdg><del rend="overstrike">mistet</del></rdg> </app> Dig for dette Liv,</l>
Eksemplet er hentet fra KK8375
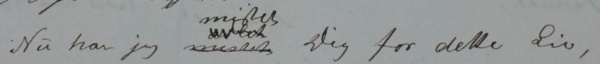

Når en substitusjon inneholder en inkomplett/unøyaktig strykning og denne blir kodet i <rdg>, vil noe av teksten bli stående utenfor <del>, jf. eks. nedenfor.
<lb/><sp who="NORA"><spOpener><speaker>Nora</speaker>.</spOpener> <lb/><p>Ak, Thorvald, <app type="alteration"> <lem><add place="offline">det er ikke godt at svare på det</add></lem> <rdg><del rend="overstrike">hvad skal jeg svare d</del>ig?</rdg> </app> Jeg ved det jo <lb/>sletikke. Jeg er ganske i vilderede med de ting. Jeg
Eksemplet er hentet fra Du41113a-g

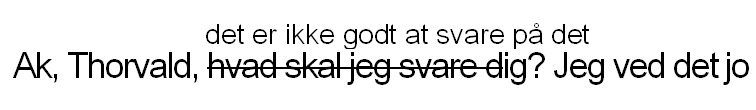
kap-11.14.4: Substitusjon hvor opprinnelig lesemåte gjenopprettes
Substitusjoner hvor den opprinnelige lesemåten gjenopprettes ved at den nye/tilføyde strykes (før den opprinnelige strykes), eller ved at – hvis den opprinnelige lesemåten er strøket – den opprinnelige gjentas, kodes som i eksemplene nedenfor. De kodes mao. som vanlige substitusjoner, men hvor lesemåten i <lem> (evt. bare den ene av dem), er strøket.
<app type="alteration"> <lem><del rend="overstrike"><add place="offline">rusked</add></del></lem> <rdg>skaked</rdg> </app>
Kodeutdrag fra Di42622

<app type="alteration"> <lem><add place="offline"><del rend="overstrike">til</del> som</add></lem> <rdg><del rend="overstrike">som</del></rdg> </app>
Kodeutdrag fra KK8375
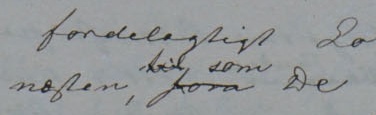
Det styrende for kodingen skal fortsatt være den diplomatariske gjengivelsen, så hvis den tilføyde gjentakelsen er skrevet i margen, inkluderes den ikke i <app>, men kodes så diplomatarisk (vha. <add>) som det lar seg gjøre.
kap-11.15: Ufullførte endringer
Fra tid til annen støter man på ufullførte endringer. Ufullførte endringer er endringer som ikke er gjort ferdig, f.eks. substitusjoner med ustrøket tekst og uavklart lemma eller endringer som resulterer i parallelle lesemåter. (For at man skal oppfatte tekst som feilaktig ustrøket, må den nye lesemåten etter tilføyelsen være meningsløs når den inkluderer både det tilføyde og det ustrøkne ordet; hvis det metriske mønsteret i verstekster blir ødelagt, har man f.eks. sannsynligvis med en slik type endring å gjøre.)
Ufullførte endringer av denne typen kodes likevel på vanlig måte, siden det vil framgå av innholdet og av visningen at endringen er ufullført (det framgår også av kodingen i de tilfellene der <rdg> ikke inneholder <del>). Den tilføyde teksten kodes i tillegg som vanlig med opplysning om plassering og evt. om hånd.
<app type="alteration"> <lem><add place="offline">TILFØYD ORD</add></lem> <rdg>ANTATT FJERNET ORD</rdg> </app>
I andre tilfeller lar ikke kronologien på tidligere lesemåter seg avgjøre selv om lesemåten som skal være lemma lar seg bestemme. Slike tilfeller kodes likevel på vanlig måte, som substitusjon, eller fragmentert med enkle <add>- og <del>-elementer, som eks. nedenfor, evt. i kombinasjon med <app>.
<lb/><l part="F">Amen, Gut!</l> <lb/><l><add place="infralinear">Brav Karl; <del rend="overwritten">h</del>Han blev <del rend="overstrike">sig</del></add> <add place="offline"><del rend="overstrike">Du <del rend="overstrike"> <del rend="overwritten">var</del>er og</del> blev</del></add> <del rend="overstrike">Brav Karl; han</del> <del rend="overstrike">dig</del> <add place="offline">sig</add> selv till <add place="offline"><del rend="overstrike">sidste</del></add> Slut.<add place="infralinear"><del rend="overstrike">Du er og</del></add></l> <lb/><stage>(svinger sig opp.)</stage>
Eksemplet er hentet fra PG428692
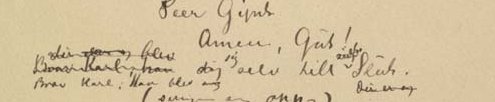
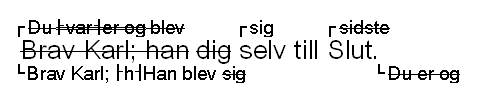
kap-11.15.2: Alternativ eller parallell tekst
Med alternativ tekst mener vi formuleringer som står tilføyd utenfor teksten og hvis innhold er parallelt (omformuleringer, forkortende eller utvidende) med innholdet i (del av) nærliggende replikk, men som ikke er knyttet til et sted i teksten vha. innføyningstegn og som heller ikke klart kan bestemmes som erstatning til en avgrenset del av replikkteksten.
Slike tilfeller kodes vanligvis bare med <add>, siden koding i <app> krever at man må avgrense innholdet i <rdg>, og det jo nettopp er dette som er vanskelig/umulig. Her er et enkelt og lite eksempel:
<add hand="h3" place="infralinear">fik dog lige fuldt</add> lige fuldt jeg fik
Eksemplet er hentet fra PG428692
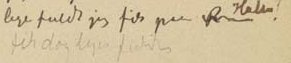

Alternativ tekst til replikktekst i arbeidsmanuskripter kodes mao. som tilføyelser og plasseres/transkriberes (om mulig) på det sted i teksten som ligger nærmest der tilføyelsen står. Hvis slike tilføyelser faller mellom replikker, skal man kode med strukturkoding (<sp who=""> + <p>) inne i <add>.
Her er et noe mer komplekst eksempel:
<lb/><sp who="REBEKKA"><spOpener><speaker>Rebekka</speaker> <lb/><stage>(griber begge hans hænder og bøjer hodet ned <lb/>mod hans bryst.)</stage></spOpener> <lb/><p>Tak, <del rend="overwritten">r</del>Rosmer. <stage>(slipper ham.)</stage> Og nu går jeg.</p></sp> <add place="margin"> <note resp="editor">Tilføyelsen...</note> <lb/><sp><p>Men jeg, – jeg vilde herefter dag bare være som et havtrold, <lb/>der hang og hæmmed det skib. .</p></sp></add>
Eksemplet er hentet fra Ro41291

kap-11.16: Endringer på tvers av strukturgrenser
Når man står overfor endringer som krysser strukturgrenser skal man velge løsninger som innebærer fragmentert koding, dvs. bruk av enkle <add>- og <del>-elementer (evt. sammen med apparater). Som regel vil brukeren selv kunne se at endringer hører sammen på tvers av strukturgrenser. Brukeren trenger ingen eksplisitt informasjon om dette.
kap-11.17: Splitting av replikk
I håndskrifter forekommer det at vi finner splitting av en lang replikk til flere mindre replikker. Vi koder endringene som splitter replikken som tilføyelser og setter inn start- og sluttagger til de nye replikkelementene og verslinjene uavhengig av tilføyelsen/e. Endringer internt i replikkene plasseres der de finner sted og kodes på vanlig måte. Nedenfor er et eksempel på oppsplitting av replikk fra Br42621:
<lb/><sp who="EJNAR"><spOpener> <speaker>Einar</speaker>.</spOpener> <lb/><l>Just som jeg gjennem Bygden strøg</l> ... <lb/><l>et Smil som lo i Sjælen ind ‐</l></sp> <lb/><sp who="AGNES"><add place="margin"><note resp="editor">Tilføyelsen...</note> <spOpener> <speaker>Agnes</speaker>.</spOpener></add> <lb/><l>Men <app type="alteration"><lem><add place="offline">hvad du</add></lem><rdg><del rend="overstrike">det jeg</del> </rdg></app> malte saa jeg neppe,</l> ... <lb/><l>med Stav i Haand og snøret Skræppe ‐</l></sp> <pb/> ... <lb/><sp who="EJNAR"><add place="margin"><note resp="editor">Tilføyelsen...</note> <spOpener> <speaker>Ejnar</speaker></spOpener></add> <lb/><l>Da strøg den Tanke mig forbi:</l> ... </sp>
Kodeutdrag fra Br42621. Deler av replikktekst er utelatt (markert), den relevante kodingen er markert med fet skrift

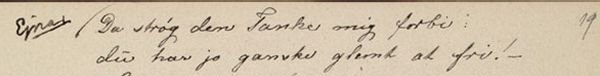
kap-11.18: Sammenslåing av replikker
Når replikker blir slått sammen ved at replikkinnehaveren er strøket (eller fjernet på annen måte), kodes dette som i eksemplet under. Etter mønster av kodingen for splitting av replikk, hopper man her over kodingen av den ene replikken som fjernes (<sp> for denne er utelatt), og bare replikkåpner (<spOpener>) legges inn i <del>.
<lb/><sp who="DOVREGUBBEN"><spOpener> <speaker>Dovregubben</speaker></spOpener> <lb/><l>Godt, Prins Peer, den Sagen blir din.</l> <del rend="overstrike"><lb/><spOpener> <speaker>Peer Gynt</speaker>.</spOpener></del> <lb/><l>Men den Ting er sikker, at gjort er gjort,</l> <lb/><l>item at <clarification>d</clarification>in Afkom vil voxe;</l> <lb/><l>sligt Blandingskræ voxer urimelig fort –</l></sp>
Eksempel fra PG428692

kap-11.19: Omrokkering
Ved omrokkeringer skiller vi mellom omrokkering av ord/fraser og av linjer. Generelle retningslinjer for transkripsjon og koding:
- understrekning e.l. av nummer ved omrokkering av ord/fraser, normaliseres vekk, jf. tilsvarende praksis ved foliering
- parenteser e.l. etter nummer ved omrokkering av linjer, normaliseres vekk, jf. tilsvarende praksis ved foliering
- klammer som markerer hvilke verslinjer som skal omrokkeres, når flere verslinjer skal bytte plass med hverandre, beholdes (suppleres evt.) for å lette forståelsen og vise vår tolkning eksplisitt
- klammer under fraser behandles på samme måte som klammer ved flere verslinjer, jf. ovenfor, og gjengis hos oss med stiplet linje under frasen
- tegnsetting (punktum e.l.) tas med som de står
- dobbel markering (nummer + omrokkeringstegn/piler); omrokkeringstegn/piler normaliseres vekk, kun nummer beholdes
- hvis nummereringen er gjort med annen hånd, legges hand-attributt i elementet som omslutter tallet
- evt. rettelser tas med (i BE42869 er f.eks. 2 rettet til 1 et sted), jf. tilsvarende praksis ved foliering
kap-11.19.1: Endring av rekkefølge på ord
Ved omrokkering av enkeltord brukes elementet <seg type="transposition" subtype="words_numbered">. Ett element omslutter alle ord som skal bytte rekkefølge. Både ord og tallet ovenfor/under ordet transkriberes. Ordet kodes i <seg subtype="word">, mens tallet kodes i <seg subtype="no">.
Her er et eks. på kodingen:
<seg type="transposition" subtype="words_numbered"> <seg rend="supralinear" subtype="no">2</seg><seg subtype="word">saa</seg> <seg rend="supralinear" subtype="no"><del rend="overwritten">2</del>1</seg> <seg subtype="word">du</seg> </seg>
Kodeutdrag fra BE42869
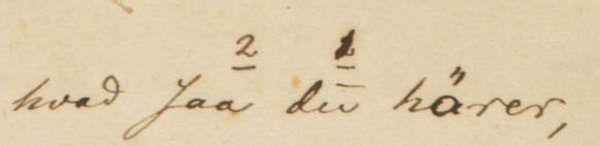
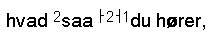
kap-11.19.2: Endring av rekkefølge på fraser
Ved omrokkering av fraser brukes elementet <seg type="transposition" subtype="words_numbered">. Ett element omslutter alt som skal bytte rekkefølge. Både frase og tallet ovenfor/under frasen transkriberes. Frasen kodes i <seg subtype="phrase">, mens tallet kodes i <seg subtype="no">.
Her er et eks. på kodingen:
<seg type="transposition" subtype="words_numbered"> <seg rend="supralinear" subtype="no">2</seg><seg subtype="phrase">Folkets sugende Længsel</seg> <seg rend="supralinear" subtype="no">1</seg><seg subtype="phrase">han løser</seg> </seg>
Kodeutdrag fra BE42869

kap-11.19.3: Endring av rekkefølge på ord og frase
Ved omrokkering av ord og frase brukes elementet <seg type="transposition" subtype="words_numbered">. Ett element omslutter alt som skal bytte rekkefølge. Både ordet/frasen og tallet ovenfor/under ordet/frasen transkriberes. Ordet kodes i <seg subtype="word">, mens frasen kodes i <seg subtype="phrase">, og tallet kodes i <seg subtype="no">.
Her er et eks. på kodingen:
<seg type="transposition" subtype="words_numbered"> <seg rend="infralinear" subtype="no">2</seg><seg subtype="phrase">er vort</seg> <seg rend="infralinear" subtype="no">1</seg><seg subtype="word">Folk</seg> </seg>
Kodeutdrag fra BE42869
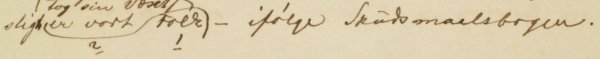

kap-11.19.4: Behandling av ord som kommer mellom
Det hender at enkeltord blir stående mellom ord/fraser som skal omrokkeres. Disse kan stå innenfor <seg type="transposition" subtype="words_numbered">. Her er et eks.:
<del rend="overstrike">Jeg ved ej om Livet er</del> <seg type="transposition" subtype="words_numbered"> <seg rend="supralinear" subtype="no"><del rend="overstrike">2</del></seg> <del rend="overstrike"><seg subtype="word">kort</seg> eller</del> <seg rend="supralinear" subtype="no">1</seg> <seg subtype="word"><del rend="overstrike">langt</del></seg> </seg>,
Kodeutdrag fra BE42869

kap-11.19.5: Endring av rekkefølge på enkeltlinjer
Ved omrokkering av to eller flere enkelt(vers-)linjer brukes elementet <blockSeg type="transposition_lines" id="tp_noTALL">. Ett element omslutter hver linje som skal byttes om på. Tallet kodes i <note type="transposition_lines" resp="author">.
Her er selve kodestrukturen:
<blockSeg type="transposition_lines" id="tp_no1"> <note type="transposition_lines" resp="author">2</note> ... </blockSeg> <blockSeg type="transposition_lines" corresp="tp_no1"> <note type="transposition_lines" resp="author">1</note> ... </blockSeg>
Her er et eks. på kodingen når to linjer bytter plass:
<blockSeg type="transposition_lines" id="tp_no1"> <lb/><note type="transposition_lines" resp="author">2</note> <l>thi da er du med Himmelen i Pagt; –</l></blockSeg> <blockSeg type="transposition_lines" corresp="tp_no1"> <lb/><note type="transposition_lines" resp="author">1</note> <l>da kan du Folkets Jøkelhjerter tine;</l></blockSeg>
Kodeutdrag fra BE42869

Her er et eks. på kodingen når fire linjer bytter plass:
<lb/><castItem id="FRUSØRBY">Fru Sørby, grossererens husbestyrerinde.</castItem> <blockSeg type="transposition_lines" id="tp_no1"> <lb/><note type="transposition_lines" resp="author">3.</note> <castItem id="GRAABERG">Gråberg, grossererens bogholder.</castItem></blockSeg> <blockSeg type="transposition_lines" corresp="tp_no1"> <lb/><note type="transposition_lines" resp="author">4.</note> <castItem id="PETTERSEN">Pettersen, tjener hos grossereren.</castItem></blockSeg> <lb/><castItem id="ENBLEGFEDHERRE"><del rend="overstrike">Kammerherre Flor</del>.</castItem> <lb/><castItem id="ENTYNDHÅRETHERRE"><del rend="overstrike">Kammerherre Kaspersen</del>.</castItem> <blockSeg type="transposition_lines" corresp="tp_no1"> <lb/><note type="transposition_lines" resp="author">1.</note> <castItem id="RELLING">Relling, mediciner.</castItem></blockSeg> <blockSeg type="transposition_lines" corresp="tp_no1"> <lb/><note type="transposition_lines" resp="author">2.</note> <castItem id="MOLVIK">Molvik, forhenværende teolog.</castItem></blockSeg> <lb/><castItem id="JENSEN">Lejetjener Jensen.</castItem>
Kodeutdrag fra Vi41115b

kap-11.19.6: Endring av rekkefølge på grupper av linjer
Ved omrokkering av grupper av (vers-)linjer brukes elementet <blockSeg type="transposition_lines_braced" id="tp_noTALL">. Ett element omslutter hver gruppe med linjer som skal bytte plass. Det genereres en klamme utenfor hver av gruppene med linjer, som hører sammen. Tallene kodes i <note type="transposition_lines" resp="author">.
Her er selve kodestrukturen:
<blockSeg type="transposition_lines_braced" id="tp_no1"> <note type="transposition_lines_braced" resp="author">2</note> ... </blockSeg> <blockSeg type="transposition_lines_braced" corresp="tp_no1"> <note type="transposition_lines_braced" resp="author">1</note> ... </blockSeg>
Her er et eks. på kodingen:
<blockSeg type="transposition_lines_braced" id="tp_no5"> <note type="transposition_lines_braced" resp="author">2</note> <lb/><l>Igjennem Dalen gaar e<del rend="overwritten">t</del>n leret Elv;</l> <lb/><l>et Fjellvand ligger der med sortblaa Skygger;</l> </blockSeg> <blockSeg type="transposition_lines_braced" corresp="tp_no5"> <note type="transposition_lines_braced" resp="author">1</note> <lb/><l rhyme="C"><add place="offline">I</add><del rend="overstrike">Af</del> Frost <add place="offline">i</add><del rend="overstrike">af</del> Tø <add place="offline">i</add><del rend="overstrike">af</del> Fygvejr Vintren bygger</l> <lb/><l rhyme="d">udover Væggen ludende <app type="alteration"> <lem><add place="offline">hint</add></lem> <rdg><del rend="overstrike">et</del></rdg></app> Hvælv.</l> </blockSeg>
Kodeutdrag fra BE42869
kap-11.20: Flytting av tekst vha. piler e.l.
Når flytting av ord/tekst er markert vha. f.eks. piler, transkriberer vi den opprinnelige plasseringen (siden det er den som gir oss diplomatarisk visning av tekststedet) og forklarer i note hvor teksten er ment flyttet.
<lb/><sp><spOpener><speaker>Fru Gunhilds følge</speaker>. <lb/><stage>(nærmere.)</stage></spOpener> <lb/><l rend="centre">Ung Olaf, ung Olaf, <note resp="editor">En strek fra foran <q>hvor</q> til ned under <q>vé</q> markerer sannsynligvis at Ibsen har ønsket å flytte <q>hvor sidder du tagen?</q> ned under <q>Vi vanker i vé.</q></note> hvor sidder du tagen?</l> <lb/><l rend="centre">Å vågn dog og se.</l> <lb/><l rend="centre">Vi vanker i vé.</l> <lb/><l rend="centre">Hvor sidder du tagen de nætterne tre</l> <lb/><l rend="centre">og på fjerde dagen?</l></sp>
Kodeutdrag fra OL81945

Ved slike endringer vil det nok bli nødvendig for brukeren å konsultere faksimilen.
kap-11.21: Gjenoppretting av tidligere lesemåte
I noen av Ibsens manuskripter finnes det oppheving av endringer som gjenoppretter et tidligere stadium av teksten. Gjenoppretting av tidligere lesemåte medfører at endringen er fjernet og at teksten dermed er ført tilbake til sitt utgangspunkt. I HIS brukes <restore> til følgende typer gjenoppretting av tidligere lesemåte:
- endringer oppheves vha. en rekke av prikker under f.eks. den overstrøkne teksten
- oppheving av retorisk utheving vha. strykning av understrekning
I tillegg omtales her følgende fenomener, som også gjelder oppheving av endringer, men hvor HIS ikke koder med <restore>:
- noter som opphever endringer. HI skriver f.eks. «Stryges ikke!» i margen. Slike tilfeller kodes ikke med <restore>, men forfatternoten transkriberes
- kansellert nummerert omrokkering, dvs. nummerert omrokkering hvor numrene er strøket
- kansellert erstatning, dvs. substitusjon hvor opprinnelig lesemåte gjenopprettes
For bruk av <restore> og koding av kanselleringer i trykte tekster med håndskrevne rettelser, jf. «Koding» i avsnittet «Trykte tekster med håndskrevne rettelser».
kap-11.21.1: Gjenoppretting av strykning
Gjenoppretting av strykning kodes med <restore> med attributtene type="" og desc="". type="" inneholder navnet på det elementet gjenopprettingen angår (mao. det elementet <restore> omslutter direkte), her altså <del>. desc="" skal inneholde en beskrivelse av gjenopprettingen (ikke den foregående endringen, kun selve gjenopprettingen). Se attributtverdilisten for attributtverdier i bruk.
Gjenoppretting av strykning kodes slik:
<restore type="del" desc=""> <del rend="overstrike">ORD</del> </restore>
Eksempel:
<restore type="del" desc="subpunction"> <del rend="overstrike">årker ikke</del> </restore>
Eksempel fra OL81945
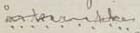
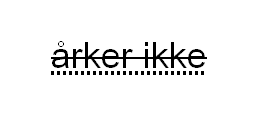
Hagl<app type="alteration"> <lem><add place="offline"><del rend="overstrike">vejr</del></add></lem> <rdg><restore type="del" desc="subpunction"><del rend="overstrike">slag</del></restore></rdg> </app>
Kodeutdrag fra KK8375
<lb/><l> <app type="alteration"> <lem><del rend="overstrike"><add place="offline">Og jeg i Verden ud</add></del></lem> <rdg><restore type="del" desc="subpunction"> <del rend="overstrike">I Verden ud</del></restore></rdg> </app> saa <restore type="del" desc="subpunction"><del rend="overstrike">frisk og</del></restore> glad og tryg,</l>
Kodeutdrag fra KK8375

I tilfeller der strykningen som senere oppheves, ikke er fullstendig, kodes strykningen diplomatarisk, men <restore>-koden omslutter hele ordet.
<lb/><stage> (<app type="alteration"><lem><add place="offline" hand="HI-2"> <unclear reason="writing">fægt</unclear><gap/></add></lem> <rdg><restore type="del" desc="subpunction" hand="HI-2"><del rend="overstrike" hand="HI-2">strække</del>r</restore></rdg></app> armene ud og mumler.)</stage>
Kodeutdrag fra Vi41115b
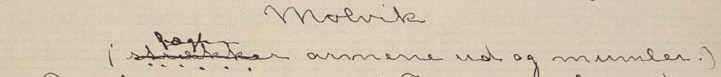
kap-11.21.2: Oppheving av utheving
Utheving oppheves vanligvis ved at understrekningen strykes over med korte diagonale streker, som nesten kan se ut som underprikking. I HISe kommer slik oppheving til å bli vist vha. underprikking. Oppheving av utheving kodes slik:
<restore type="emph" desc="overstrike"> <emph>Liv</emph></restore>
Kodeutdrag fra Br42621
kap-11.21.3: Noter som opphever endringer
Ibsen angrer av og til på strykningene sine og noterer i margen at tekst likevel ikke skal strykes. I slike tilfeller bruker vi ikke <restore>. Vi nøyer oss med å transkribere Ibsens margnotat som forfatternote, <note resp="author" place="">. Noten plasseres helst i forkant av den strøkne teksten, hvis ikke dette avviker for mye i forhold til diplomatarisk plassering. Her er et eksempel:
<lb/><note resp="author" place="margin-left">Stryges ikke</note> <lb/><l><del rend="overstrike">Endt er min Digtning <app type="alteration"><lem><add place="offline">indfor</add></lem> <rdg><del rend="overstrike">bag en</del></rdg></app> Stuevæg,</del></l> <lb/><l><del rend="overstrike">Mit Digt skal <emph>leves</emph> under Rogn og Hægg</del>,</l> <lb/><l><del rend="overstrike">Min Krig skal føres midt i Døgnets Rige</del>;</l> <lb/><l><del rend="overstrike">Jeg eller Løgnen – En af os <app type="alteration"><lem><add place="offline">skal</add></lem> <rdg><del rend="overstrike">maa</del></rdg></app> vige!</del></l>
Kodeutdrag fra KK8375
kap-11.21.4: Kansellert nummerert omrokkering
Kansellert nummerert omrokkering, dvs. nummerert omrokkering hvor numrene er strøket slik at rekkefølgen skal beholdes som den er, kodes slik:
<lb/><sp who="BJORN"><spOpener><speaker>Bjørn</speaker> <stage>forundret </stage></spOpener> <lb/><l>Inat! hvad mener du? <seg type="transposition" part="I"> <del rend="overstrike" hand="h2"><seg rend="supralinear" subtype="no">2</seg></del> <seg subtype="word">har</seg></seg> <seg type="transposition" part="F"> <del rend="overstrike" hand="h2"><seg rend="supralinear" subtype="no">1</seg></del> <seg subtype="word">jeg</seg></seg> <del rend="overwritten"><unclear>da</unclear></del>ei været</l> <lb/><l part="I">i Nat paa Fjeldet –</l></sp>
Kodeutdrag fra RJ4932
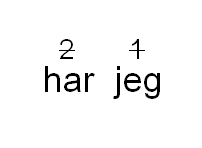
kap-11.21.5: Kansellerte erstatninger
kap-12: Internvariasjon
kap-12.1: Grunnkoding
Apparater som inneholder internvariasjon skal ha type="" med verdien «internal». I HIS er det gjort obligatorisk å bruke type="" i <app>, og de gyldige verdiene er definert i DTD-en.
Internvariasjon kodes i <app> med <rdg wit="">-elementer. Attributtverdien i wit="" skal være eksemplarnummeret (eks. HH58f3). Lesemåten fra hovedeksemplaret skal alltid legges (fremst) i første <rdg>. Filologene avgjør hvilket eksemplar som er hovedeksemplar. Vi dokumenterer kun variasjon fra de tre hovedeksemplarene (mao. ikke resultater fra kollasjoneringen av ekstraeksemplarer) i XML-filene våre. F.eks.:
<app type="internal">
<rdg wit="HH58f3 HH58f1">Hun</rdg>
<rdg wit="HH58f2">Han</rdg>
</app>
<app type="internal">
<rdg wit="HH58f3 HH58f1"><stage>(hæver Spydet.)</stage></rdg>
<rdg wit="HH58f2"><stage>(hæver Spydet)</stage>.</rdg>
</app>
Begge eksemplene er fra HH58
I de diplomatariske grunntekstene oppgir vi hvilken lesemåte de tre eksemplarene har, men vi overlater til filologen å peke ut den antatt riktige lesemåten når teksten skal ederes.
kap-12.2: Ved kryssende strukturer
Vi tillater at man flytter tegnsetting inn i <stage> (og <speaker>) når innkodingen av apparatet forårsaker overlappende kodestruktur.
<lb/><sp who="ROSMER"><spOpener><speaker>Rosmer</speaker>
<lb/><stage>(tar ligeledes sin <app type="internal">
<rdg wit="Ro86f2 Ro86f1">hat)</rdg>
<rdg wit="Ro86f3">hat).</rdg></app></stage></spOpener>
Eksemplet er fra Ro86
Vi har tillatt dette for å få enklere koding å prosessere og enklere tekst/noter å lese.
kap-13: Det eksterne variantapparatet
kap-13.1: Begrepsavklaring
Med ekstern variasjon menes forskjeller mellom ulike tekstkilder til et verk eller en versjon av et verk. Intern variasjon derimot er variasjon innenfor en og samme tekstkilde, som internvariasjon mellom ulike trykte eksemplarer av samme utgave.
kap-13.2: Behandling av eksternvariasjon i HIS
Bokutgaven til HIS (som bare inneholder ederte hovedtekster) vil kun opplyse om eksterne varianter i den grad disse har hatt betydning for etableringen av hovedteksten, f.eks. der grunnteksten har en åpenbar feil og andre tekstkilder har den riktige lesemåten. Den fulle visningen av de eksterne variantene legges til den elektroniske versjonen av HIS.
kap-13.2.1: Variantvisninger
E-utgaven vil tilby følgende variantvisninger:
- en variantliste med grunntekstvisning: skjermbildet er delt i to horisontale vinduer. I det øverste er en samlet oversikt over variantene i tekstmaterialet. I det nederste vinduet vises grunnteksten som løpende tekst; alle varianter er markert med farget bakgrunn. En kan klikke mellom variantoversikten og de aktuelle tekststedene i den løpende teksten
- en synoptisk visning med variantmarkering: grunnteksten vises i et vindu til venstre. Brukerne kan velge å se n eller to andre tekstkilder til høyre (dersom det er to, vises de i horisontaldelte vinduer). Øvrige tekstkilder som inngår i variantvisningen, markeres med faner i høyre marg. Tekstkildene skal fritt kunne byttes ut med andre på ethvert sted i teksten. Ved å klikke på en fargemarkert variant i den synoptiske visningen, synkroniseres vinduene til samme tekststed. Tekstkilder som har variasjon i forhold til grunnteksten på tekststedet det klikkes på, markeres ved fargelegging av de respektive fanene.
- en synoptisk visning uten variantmarkering: to eller tre tekstkilder sammenstilles på samme måte som i visningen ovenfor, men uten fargemarkering av varianter. I stedet benyttes synkroniseringsmarkører (pilsymboler) for omtrent hver bokside. Sidereferanser til Hundreårsutgaven (<pb ed="HU" n=""/>) benyttes til synkroniseringskoding.
De to første visningsalternativene er de vi helst benytter for å vise variasjonen mellom tekstkilder. Begge skal være tilgjengelige, slik at brukerne fritt kan velge mellom dem. Den siste visningstypen benyttes der variasjonen mellom tekstkildene er så stor at den vanskelig kan gjengis i de to øvrige visningstypene. Spesielt benyttes den for ulike versjoner av et verk (Ibsen skrev nye versjoner av sine ungdomsdramaer, som varierer mye både i innhold og form) og for arbeidsmanuskripter med store tekstforskjeller og/eller flere parallelle versjoner av samme tekst. Enkelte tekstkilder kan måtte holdes helt utenfor alle tekstsammenlikninger.
kap-13.2.2: Diplomatarisk gjengivelse
All variantvisning, og følgelig all variantkoding, knyttes til de diplomatariske grunntekstene. De ederte hovedtekstene skal altså ikke inneholde ekstern variantkoding. Siden disse tekstene er ederte ville inkluderingen av dem i variantvisningen føre til falsk variasjon og invariasjon (variasjon som forekommer i hovedtekst, men ikke i grunntekst og motsatt).
Den lemmatiserte variantlisten føres også diplomatarisk. Det vil si at variantene føres i sin bokstavrette form. Dette medfører i noen tilfeller at variasjon som vi ellers ekskluderer fra det eksterne variantapparatet (f.eks. Ibsens nye ortografi etter rettskrivningsmøtet i 1869) likevel kan forekomme dersom den opptrer samtidig med reell variasjon (f.eks. «Gaade.» vs. «gåde», der den reelle variasjonen angår interpunksjon).
kap-13.2.3: Rollehefter
Til teatermanuskriptene hører sufflørbøker og rollehefter. De siste er spesielt utfordrende å inkludere i et variantapparat fordi de har en annen struktur enn de øvrige tekstkildene. Rolleheftene ble delt ut til de enkelte skuespillerne ved teateroppsetninger og inneholder replikkteksten til den aktuelle rollen skuespilleren skulle spille. I tillegg inngår noe omkringliggende tekst (sceneanvisninger og andre rollers replikker) for at skuespilleren skulle vite når hun/han skulle opptre. Vi vil inkludere rolleheftene i variantapparatet, men bare ta hensyn til den aktuelle rollens replikktekst i de enkelte heftene. Rolleheftene er samlet i en fil, heftevis etter hverandre.
For variantvisningen vil vi lage en spesialvisning av rolleheftene der teksten i heftene stokkes i kronologisk ordning etter dramateksten. Bare replikktekst fra replikkinnehaveren(e)s rollehefte(r) inkluderes. Dermed kan rollehefteteksten vises samlet i ett vindu i den synoptiske variantvisningen. Det finnes forekomster av fellesreplikker med varianter mellom de enkelte rolleheftene. Slik variasjon kodes og behandles som internvariasjon og vises bare i løpende tekst (dersom det ikke samtidig er ekstern variasjon på tekststedet; da inkluderes variasjonen også blant de eksterne variantene).
Ortografisk variasjon inkluderes også for teatermanuskriptene, selv om disse er skrevet for muntlig oppførelse. Grunnen er at det ofte mangler arbeidsmanuskripter fra denne tidlige perioden i Ibsens forfatterskap og at teatermanuskriptene godt kan være avskrifter av tapte arbeidsmanuskripter. Det finnes også trykte tekstkilder med i verkmaterialet, der ortografi er interessant, og disse tekstkildene trenger andre tekstkilder å sammenliknes med.
Eksterne variantvisninger ligger i de respektive verksmappene. Variantvisningene er under utarbeidelse.
kap-13.3: Arbeidsprosedyrer
Under arbeidet med ekstern variantkoding arbeider forskningsassistenter og filologer sammen. n forskningsassistent (verksansvarlig) har ansvaret for å føre inn i de eksterne variantene i hele verket. Filologene trekkes inn i vurderingene av hvilke tekstkilder som skal inngå i variantapparatet, samt hvilke varianter som skal inkluderes. Det er en fordel om personsammensetningen varieres på de ulike verkene slik at det ikke oppstår ulike praksiser.
For nyopprettede verk fanges all ekstern variasjon opp under kollasjoneringa av tekstkildene og kodes under opprettelsen av filene. Alle tekststeder som inneholder variasjon skal kodes i alle tekstkilder. Når nye varianter dukker opp, må en altså gå tilbake til tidligere opprettede filer og føre inn disse her også.
For tidligere opprettede verk der ekstern variasjon ikke er kodet inn, og heller ikke tatt vare på i kollasjoneringsnotater, må variasjonen hentes fram igjen ved hjelp av kollasjoneringsprogrammet Juxta. SGREP (søk på innhold i <app> i arkiverte flertekstfiler) kan benyttes for å kontrollere kollasjonen Juxta har foretatt.
For manuskripter med usikre lesemåter, utydelig skrift etc. leser vi velvillig i forhold til de øvrige tekstkildene, slik at variantapparatet ikke overfylles med uinteressant variasjon. For ferdige verk kan vi endre tidligere transkripsjon i tråd med dette, men konsulter først filologene.
Ved tvil om en lesemåte er variererende eller ikke, f.eks. om første bokstav er majuskel eller minuskel ved kapitlbruk, antas den riktige (ikke-varierende) lesemåten.
Når variantkodingen av et verk er fullført, holdes et avsluttende verksmøte med filologene og forskningsassistenten der visningene gjennomgås. Til slutt avholder filolgene et ferdigstillingsmøte der notetekster gås gjennom og visningen sluttstilles.
Status for arbeidet med de eksterne variantene skal føres i verkenes respektive statusrapporter. Dette gjelder både nye og ferdige verk.
kap-13.4: Avgrensning av variantapparatet
Variantapparatet avgrenses som tidligere nevnt først ved at sterkt avvikende tekstkilder utelukkes fra variantvisningene, og hvis mulig presenteres i en synoptisk visning uten variantmarkering i stedet. Slike tekstkilder skal altså ikke inneholde variantkoding.
For å gjøre variantapparatet anvendelig begrenser vi omfanget ved å luke ut variasjon som vi anser som mindre vesentlig eller uhensiktsmessig å vise, og ved å beskrive gjennomgående variasjon generelt, jf. punktene nedenfor.
kap-13.4.1: Variasjon som ekskluderes
Blant tekstkildene som inngår i variantapparatet ekskluderes følgende varianttyper:
- manuskripter: strøkne/overskrevne lesemåter. Disse vises som integrerte endringer i de løpende tekstene i det synoptiske variantapparatet, men de fargemarkeres ikke som eksterne varianter, og de innlemmes ikke i det lemmatiserte apparatet. De regnes som interne endringer innenfor en tekstkilde, ikke som eksterne varianter mellom tekstkilder. Med strøkne/overskrevne lesemåter menes her intendert, ikke faktisk strøkne/overskrevne lesemåter. Vi inkluderer altså heller ikke variasjon som skyldes at deler av ord er faktisk ustrøkne.
- trykte tekster: internvariasjon, jf. Internvariasjon. Lesemåten til grunntekstens hovedeksemplar velges. (Hvilket eksemplar som er hovedeksemplar skal gå fram av verkenes statusrapporter etter edering; ev. kan filologene konsulteres.) På samme måte som for manuskriptendringer vises internvariantene i den løpende grunnteksten, men de fargemarkeres ikke som eksterne varianter.
- på tittelsider:
- type, antall og rekkefølge på tittelsider
- all variasjon som angår utgave- og trykkeopplysninger, dvs. innhold i <docEdition> og <docImprint>
- all tegnsettingsvariasjon utenom indre interpunksjon i verktittel og utropstegn/spørsmålstegn til slutt i tittel
- innholdsfortegnelser og rollelister: tegnsettingsvariasjon, utenom indre interpunksjon i titler og utropstegn/spørsmålstegn til slutt i tittel
- overskrifter/titler: avsluttende interpunksjon, bortsett fra utropstegn/spørsmålstegn
- dramatekst: ytre tegnsettingsvariasjon og parentesbruk utenom replikktekst, dvs. etter rollenavn og sceneanvisninger i replikk. Tegnsetting før eller etter parentesslutt ved sceneanvisning utelates også. Feil i systemet, f.eks. en manglende ytre parentesbue ved sceneanvisning, skal følgelig heller ikke regnes som variasjon. Indre tegnsetting og parenteser inne i sceneanvisninger inkluderes derimot, eks.: «dæmpet, bag ham» og «Olaf (kommer fra Venstre).». (Det siste eks. er altså en sceneanvisning, ikke en replikkåpning.) Feilsatt parentes inne i sceneanvisning inkluderes også, eks.: «(han sætter sig; (hun flytter en skammel under hans fødder)».
- dikt: tegnsetting før eller etter parentesslutt ved undertitler
- variasjon vedrørende myke bindestreker, f.eks. når en tekstkilde mangler myk bindestrek
- rent typografisk variasjon, som f.eks.:
- minuskel-/majuskelvariasjon i hele elementer, f.eks. i replikkåpner (<speaker>)
- markering av rollenavn i sceneanvisninger (<stageRole>)
- ulike typer utheving, f.eks. at en tekstkilde har sperring mens en annen har kursiv. Det er usikkert om skrivemåte med aksent, som f.eks. «dét», «véd» og «sés», benyttes til retorisk utheving. Derfor inkluderes slike som variasjon.
- typografiske avvik (<hi>)
- forstørret initial
- foliering
- skillestreker
kap-13.4.1.2: Gjennomgående variasjon
Variantapparatet avgrenses ytterligere ved at gjennomgående variasjon ikke inkluderes i apparatet, men beskrives generelt. Etter språkmøtet i 1869 endret Ibsen rettskrivning. Disse punktene (jf. Dag Gundersens oppsummerende punkter i HIS 12k, 480f) er konsekvent gjennomført og kan derfor regnes som gjennomgående variasjon:
- 2) majuskel > minuskel ved substantiver
- 5) aa > å
- 6) g og k mister j foran e, i, y, æ, ø (såkalt «bløte» vokaler, eks.: gjøre > gøre)
- 7) q og x ut av rettskrivningen (strax>straks)
- 10) ei, øi > ej, øj
Variasjon som inngår i punktene ovenfor, må ha sammenheng med rettskrivningsmøtet i 1869 for å ekskluderes fra variantapparatet. I rolleheftene til Gildet paa Solhoug (1856) forekommer f.eks. variasjonen Kirke/Kjirke og Gilde/Gjilde. Dette er gjort på et tidspunkt før rettskrivningsmøtet er avholdt og speiler snarere et ønske om norsk uttale ved teatret. Det er altså ikke snakk om gjennomgående rettskrivningsendringer, og følgelig skal variasjonen inkluderes.
Variasjon innenfor kategoriene som er listet ovenfor, men som ikke har sammenheng med rettskrivningsendringen, skal inkluderes i variantapparatet. Dette gjelder f.eks. når noen kilder feilaktig har 'paa' for 'på' eller majuskel for minuskel først i substantiv.
Øvrige retningslinjer for gjennomgående variasjon:
- minuskel/majuskel ved verslinjestart: Dersom bruk av minuskel/majuskel ved verslinjestart er gjennomgående innenfor de enkelte tekstkildene, er det ikke nødvendig å inkludere variasjon mellom tekstkildene i variantapparatet. Variasjonen gjøres rede for generelt. Ved inkonsekvenser inkluderes derimot variasjonen i variantapparatet.
Dersom flere kategorier ser ut til å være gjennomgående varierende i et verk, kan disse tas opp til diskusjon mellom forskningsassistenten og filologen som arbeider sammen om et verk, men hovedprinsippet er at variasjonen skal være gjennomgående innenfor hele forfatterskapet for å tas ut av variantapparatet, slik overgangen til ny rettskrivning er.
kap-13.4.2: Variasjon som inkluderes
Til slutt en oversikt over variasjon som vi inkluderer:
- variasjon på ord- og frasenivå inkluderes alle steder innenfor verkteksten, også innenfor titler og overskrifter til forord, akter, scener og rollelister
- all tegnsettingsvariasjon i replikktekst, indre tegnsettingsvariasjon i titler/overskrifter og sceneanvisninger, variasjon ved spørsmålstegn/utropstegn til slutt i tittel/overskrift
- retorisk utheving (kodet med <emph>)
kap-13.4.3: Øvrige retningslinjer
At variantene skal føres diplomatarisk, medfører i noen tilfeller at variasjon som vi ellers ekskluderer fra det eksterne variantapparatet (f.eks. Ibsens nye ortografi etter rettskrivningsmøtet i 1869) likevel kan forekomme dersom den opptrer samtidig med reell variasjon (f.eks. «Gaade.» vs. «gåde», der den reelle variasjonen angår interpunksjon).
Tekstenes diplomatariske status medfører også at diverse setter- og trykkfeil inngår i variantapparatet. Et tegn som har falt ut i trykken (mellomrommet står igjen), transkriberes ikke. Dersom de andre tekstkildene har tegn på dette stedet, fører dette altså til tegnsettingsvariasjon som føres i variantapparatet. Tilsvarende vil en bokstav som har falt ut, føre til ordvariasjon på tekststedet.
Ved tvil om en bindestrek ved linjeskift er myk eller fast, velges den slik at den ikke blir varierende i forhold til de andre tekstkildene. Dersom ordet i de andre tekstkildene forekommer både uten bindestrek, med fast bindestrek og med bindestrek ved linjeskift, så bestemmes bindestrekene ved linjeskift i samsvar med foregående tekstkilde, eller med den tekstkilden som sannsynligvis har vært forelegg.
kap-13.5: <teiHeader>
kap-13.5.1: Bibliografiske opplysninger – <listBibl>
I grunntekstfila til et verk, der alle tekstkildene inngår i variantapparatet, må de enkelte tekstkildene listes opp i <listBibl> i <teiHeader>. Her er eksempel fra C2.xml:
<sourceDesc> <bibl id="C2"> <orgName type ="owner">Deichmanske bibliotek</orgName> <idno id="C2f1"></idno> <orgName type ="owner">Nasjonalbiblioteket</orgName> <idno id="C2f2">74ga05815</idno> <orgName type ="owner">Vigdis Ystad eksemplar</orgName> <idno id="C2f3"></idno> <monogr> <author>Henrik Ibsen</author> <title type="main">CATILINA</title> <title type="desc">DRAMA I TRE AKTER, ANDEN OG GENNEMARBEJDET UDGAVE</title> <imprint> <pubPlace>København</pubPlace> <publisher>Gyldendalske Boghandels Forlag (F. Hegel) </publisher> <printer>Thieles Bogtrykkeri</printer> <date>1875</date> </imprint> </monogr> </bibl> <listBibl> <head>Tekstkilder inkludert i det eksterne variantapparatet</head> <msDescription type="workingManuscript" id="C21938-1"> <msIdentifier> <settlement>Oslo</settlement> <repository>Nasjonalbiblioteket</repository> <idno>NBO Ms.8° 1938:1</idno> </msIdentifier> <msHeading> <title>[Catilina]</title> <author>[Henrik Ibsen]</author> <origDate>[1875]</origDate> <matDesc>Ms.8° 1938:1. «Forord til anden udgave». Egenhendig utkast med rettelser.</matDesc> </msHeading> </msDescription> <msDescription type="workingManuscript" id="C21938-2"> <msIdentifier> <settlement>Oslo</settlement> <repository>Nasjonalbiblioteket</repository> <idno>NBO Ms.8° 1938:2</idno> </msIdentifier> <msHeading> <title>[Catilina]</title> <author>[Henrik Ibsen]</author> <origDate>[1875]</origDate> <matDesc>Ms.8° 1938:2. «Første akt». Påbegynt egenhendig renskrift med rettelser.</matDesc> </msHeading> </msDescription> <msDescription type="finalFairCopy" id="C21395"> <msIdentifier> <settlement>Oslo</settlement> <repository>Nasjonalbiblioteket</repository> <idno>NBO Ms.4° 1395</idno> </msIdentifier> <msHeading> <title>Catilina</title> <author>Henrik Ibsen</author> <origDate>1875</origDate> <matDesc>Egenhendig renskrift med rettelser.</matDesc> </msHeading> </msDescription> <bibl id="C291"> <orgName type="owner">Ibsensenteret</orgName> <idno>74ga01151</idno> <monogr> <author>Henrik Ibsen</author> <title type="main">CATILINA</title> <title type="desc">DRAMA I TRE AKTER, TREDJE UDGAVE</title> <imprint> <pubPlace>KØBENHAVN</pubPlace> <publisher>GYLDENDALSKE BOGHANDELS FORLAG (F. HEGEL & SØN)</publisher> <printer>GRÆBES BOGTRYKKERI</printer> <date>1891</date> </imprint> </monogr> </bibl> <bibl id="C2FU"> <orgName type="owner">Ibsensenteret</orgName> <idno>74ga05933</idno> <author>Henrik Ibsen</author> <title type="main">Catilina</title> <edition>Folkeutgave</edition> <series> <editor>J. B. Halvorsen</editor> <title>Samlede værker</title> </series> <imprint> <pubPlace>København</pubPlace> <publisher>Gyldendalske Boghandels Forlag (F. Hegel & søn)</publisher> <printer>Græbes Bogtrykkeri</printer> <date>1898–1902</date> </imprint> <monogr> <title>Samlede værker. Første bind. Catilina. Gildet på Solhoug. Fru Inger.</title> <imprint> <biblScope type="volume">Bd. 1</biblScope> <date>1898</date> </imprint> </monogr> </bibl> </listBibl> </sourceDesc>
kap-13.5.1.1: Antall varianter – <notesStmt>
Vi gir opplysninger om hvor avvikende de enkelte tekstkildene er i forhold til grunnteksten i <notesStmt>, som skal stå mellom <publicationStmt> og <sourceDesc> i <fileDesc>. I grunntekstfilen føres alle tekstkildene, i tekstkildefilene bare den enkelte tekstkilden. Her er eksempel fra Olaf Liljekrans, andre versjon:
<fileDesc> ... </publicationStmt> <notesStmt> <note type="varNumber"> <list> <headLabel>Tekstkilde</headLabel><headItem>Antall varianter i forhold til grunntekst</headItem> <label>OLFU (grunntekst)</label><item>0</item> <label>OL04</label><item>4</item> </list> </note> </notesStmt> ... </fileDesc>
Opplysningene om hvor avvikende de enkelte tekstkildene er skal benyttes til utarbeidelse av statistikker, hjelpetekster etc. i e-utgaven.
kap-13.5.2: Variantapparatdeklarasjon – <variantEncoding/>
Den eksterne variantkodinga skal dokumenteres i hver fil som inneholder ekstern variantkoding. Dette gjøres i <teiHeader>, helt til slutt i <encodingDesc>:
<variantEncoding type="external" method="parallel-segmentation" location="internal" n="[antall forekomster/apparater]"/>
I n-attributtet oppgis antall eksterne apparater i filene.
kap-13.6: Variantkoding
kap-13.6.1: Tekstkilder som ikke er grunntekster
De tekstkildene som ikke benyttes som grunntekst til et verk inneholder bare koding av tekstkildens lesemåte på tekststedet; apparatet har altså bare én lesemåte:
<app type="external" subtype="word" id="varC2-1"> <rdg>Vinteren</rdg> </app>
kap-13.6.1.1: Id-verdier
Id-verdien brukes til synkronisering av vinduer i den synoptiske variantvisningen og må derfor være felles for det aktuelle tekststedet i alle tekstkildene. Id=""-verdiene nummereres fortløpende for hver kollasjonsrunde. Det betyr at id-verdiene ikke vil ligge i kronologisk rekkefølge i filene når hele tekstmaterialet er opprettet, siden varianter fra nye kollasjonsrunder vil legges innimellom variantene fra tidligere kollasjonsrunder. Vi kan f.eks. få id-rekkefølgen: varC2-1, varC2-21, varC2-2, varC2-3, varC2-22, varC2-4, varC2-57, varC2-58, varC2-5...varC2-20, der numrene 1–20 stammer fra 1. kollasjonsrunde, numrene 21 og 22 stammer fra 2. kollasjonsrunde og 57 og 58 fra 3. kollasjonsrunde. At numrene ikke står i kronologisk rekkefølge spiller ingen rolle, så lenge id-verdiene er identiske innenfor de enkelte filene og felles for samme tekststed i alle filene.
kap-13.6.2: Grunntekster
Grunntekstene til hvert verk skal benyttes både til synoptisk og lemmatisert variantvisning. For å hente ut en lemmatisert variantoversikt må alle lesemåtene i tekstmaterialet inkluderes i fila. Disse plasseres i hver sine <rdg wit=""> med respektive kildebetegnelser/filnavn i wit="":
<app type="external" subtype="word" id="varC2-1"> <rdg wit="C2 C21938-1 C21395" var="N">vinteren</rdg> <rdg wit="C291 C2FU" var="Y">Vinteren</rdg> </app>
Innførselen i det lemmatiserte apparatet vil se slik ut:
vinteren ] 1. utg., NBO Ms. 8° 1938:1, NBO Ms. 4° 1395, Vinteren 2. utg., FU
Tekstkildebetegnelsene i wit="" valideres mot tilhørende id="" i <listBibl> i <teiHeader>. Her føres <bibl> for alle tekstkilder som inngår i det eksterne variantapparatet.
kap-13.6.2.1: Rekkefølge av tekstkilder
I grunntekstkodinga føres alltid grunntekstens lesemåte i første <rdg>, siden det er denne som skal stå som lemma i det lemmatiserte variantapparatet. Innenfor wit="" ordnes tekstkildene slik at grunnteksten føres først, og dernest de andre tekstkildene i kronologisk rekkefølge, fra første manuskript til siste trykte utgave, jf. eksemplet ovenfor. Dersom det blant variantene også finnes lesemåter med variasjon som ignoreres, føres disse til slutt, jf. eksempel nedenfor. Ved tvil om rekkefølge konsulteres filologene. Det er den samme ordningen av tekstkilder som benyttes i filologenes tekstkritiske noter.
KODING: <head>Fjerde <app type="external" subtype="word" id="varHH1-626"> <rdg wit="HH58" var="N">Akt</rdg> <rdg wit="HH73 HH74 HH75 HH78 HH85 HH94" var="Y">HANDLING</rdg> <rdg wit="HH98 HHFU HH04" var="N">AKT</rdg> </app> .</head> VARIANTLISTE: Akt] 1.utg., HANDLING 2.–7.utg., AKT 8.utg, FU, 10.utg.
Det forekommer at likelydende tekststed regnes som variant i en tekstkilde, men ikke i en annen. I slike tilfeller skal likelydende tekst føres to ganger i variantlista. Et eksempel på dette har vi i diktet «Maaneskinsvandring efter et Bal»:
VARIANTLISTE paa] NBO Ms. fol. 3215, NBO Brevs. 39, paa Jæger 1888, på FU
Her er skrivemåten 'paa' feilaktig i Jæger som har moderne ortografi ellers, mens den er riktig i de to tidlige manuskriptene.
kap-13.6.2.2: Forenkling av koding i andre tekstkilder
I grunnteksten kan de andre tekstkildenes opprinnelige koding forenkles, slik at bare den rene lesemåten står igjen. Det er jo bare denne som skal føres i det lemmatiserte variantapparatet. Det betyr at f.eks. manuskriptendringer, side- og linjeskift, typografiske bindestreker, siccing og foliering kan utgå. Slik koding må selvfølgelig stå igjen for grunntekstens egen lesemåte, samt i de andres tekstkildenes egne filer.
TEKSTKILDEKODING
<app type="external" subtype="word" id="varC2-23">
<rdg><sic>brettigede</sic></rdg>
</app>
GRUNNTEKSTKODING
<app type="external" subtype="word" id="varC2-23">
<rdg wit="C2 C21395 C291 C2FU" var="N">beret&typHyp;
<lb/>tigede</rdg>
<rdg wit="C21938-1" var="Y">brettigede</rdg>
</app>
I grunntekstkodinga er <sic> fjernet fra en av tekstkildenes opprinnelige koding. Linjeskiftet og den typografiske bindestreken som står igjen tilhører grunnteksten.
Retorisk utheving (<emph>) skal derimot stå igjen også i grunntekstkodingen, slik at lemmaet framstår på samme vis i variantlisten som i den løpende teksten.
kap-13.6.3: Varianttyper
Vi differensierer mellom to ulike varianttyper i variantkodinga: ord-/frasevariasjon og tegnsettingsvariasjon. I visningene kan brukerne velge mellom å se all variasjon, å velge vekk tegnsettingsvariasjon eller å velge vekk ordvariasjon.
Typifiseringa gjøres i subtype="" i <app>:
<app type="external" subtype="word" id="varC2-1"> <rdg wit="C2 C21938-1 C21395" var="N">vinteren</rdg> <rdg wit="C291 C2FU" var="Y">Vinteren</rdg> </app> <app type="external" subtype="interpunction" id="varC2-44"> <rdg wit="C2 C21395 C291 C2FU" var="N">Kristiania,</rdg> <rdg wit="C21938-1" var="Y">Kristiania</rdg> </app>
Av og til kan det være vanskelig å skjelne mellom varianttypene. Her er noen veiledende eksempler:
ORDVARIANTER
- retorisk utheving
- særskriving vs. sammenskriving (med eller uten bruk av bindestrek)
- majuskel-/minuskelvariasjon som ikke er oppstått som følge av tegnsettingsendring
- variasjon angående trykkaksent (gråbenene/gråbénene)
- variasjon i sammentrekking av orddeler (lakuner): s'gu vs. sgu'
- strukturell variasjon som
- feil ved verslinjeoppsett
- variasjon i avsnittsinndeling
- eksisterende/manglende akt- og/eller sceneinndeling
- "kære, trofaste" vs. "kære"
Strukturell variasjon ledsages gjerne av en forklarende utgivernote, jf. Utgivernoter.
Merk at tegnsettingsvariasjon som følger av ordvariasjon ("kære, trofaste" vs. "kære") ikke føres som tegnvariasjon.
TEGNSETTINGSVARIANTER
- parenteser
- anførselstegn
- punktum og etterfølgende majuskel kontra komma og etterfølgende minuskel (eks. fra HH: Gjæster. Mænd] 1.utg., gæster, mænd 2.–8.utg., FU, 9.utg.)
BÅDE ORD- OG TEGNSETTINGSVARIANTER
- Huusbond.] 1.utg., Huusbond BOB hBI, NBO TS ark A2 505a, TarkUiB NT348 Husbond TarkUiB NT348r
- "smiler, alvorligt" vs. "smiler"
- "Jo, jo, –" vs. "Jo,"
For varianter som inneholder både ord- og tegnsettingsvariasjon føres begge i subtype="":
<app type="external" subtype="interpunction word" id="varG1-16">
<rdg wit="G156" var="N">Huusbond.</rdg>
<rdg wit="G1hBI G1505 G1348s" var="Y">Huusbond –</rdg>
<rdg wit="G1348r" var="Y">Husbond –</rdg>
</app>
kap-13.6.4: Variasjon i forhold til grunntekst
Det skal gis informasjon om de enkelte lesemåtene varierer i forhold til grunnteksten eller ikke. Slik informasjon gis i <rdg var="">. Attributtverdiene er 'Y' for 'yes' og 'N' for 'no'. Kodinga utføres bare i grunntekstfiler:
<app type="external" subtype="word" id="varC2-1"> <rdg wit="C2 C21938-1 C21395" var="N">vinteren</rdg> <rdg wit="C291 C2FU" var="Y">Vinteren</rdg> </app>
I grunntekstfila vil første lesemåte alltid ha verdien <rdg var="N">.
I tilfeller der grunnteksten helt mangler teksten som varianten forekommer i, som i Digte der nye dikt ble lagt til i senere utgaver, vil begge variantene få Y-verdi:
<app type="external" subtype="word" id="varDi_183a"> <rdg wit="Di75 Di79 Di82 Di86 Di91 Di96 DiFU Di01" var="Y">Ved Tusendårs-festen</rdg> <rdg wit="Di71 Di42622" var="N"><note resp="editor" type="variant">diktet <q>Ved Tusendårs-festen</q> mangler i 1. utg. og KBK Collin 262, 4°, II.2</note> <note resp="editor" type="variant" rend="text">Diktet <q>Ved Tusendårs-festen</q> mangler i 1. utg.</note></rdg></app> <app type="external" subtype="interpunction" id="varDi_184"> <rdg wit="Di75 Di79 Di82 Di86 Di91" var="Y">sunde</rdg> <rdg wit="Di96 DiFU Di01" var="Y">sunde,</rdg></app>
Kodingen med var="" gir informasjon om hvor varierende de enkelte tekstkildene er i forhold til grunnteksten. Ut fra informasjonen i subtype="" og var="" kan det lages hjelpetekster, statistikk og grafer over variasjonen i tekstmaterialet til e-utgaven.
kap-13.6.5: Kontekst
De samme retningslinjer som gjelder for inkludering av kontekst ved interne varianter, følges for eksterne varianter. Det vil si at foregående ord inkluderes ved tegnsettingsvariasjon og ekstra/manglende tekst, mens det ikke tas med noe ekstra ord ved en-til-en-forhold mellom variantene:
- menneskeheden, ] menneskeheden
- nu for tiden ] nu
- vinteren ] Vinteren
Kodes slik:
<app type="external" subtype="word" id="varC2-12">
<rdg wit="C2 C21395 C291 C2FU" var="N">nu for tiden</rdg>
<rdg wit="C21938-1" var="Y">nu</rdg>
</app>
Det kan utvises skjønn her. Dersom det er mer illustrerende å velge etterfølgende ord i stedet for foregående som kontekst, er dette helt i orden. Noen ganger er det også nødvendig, ut fra kodemessige og/eller strukturelle årsaker.
kap-13.6.6: Internvariasjon
Internvariasjon i grunnteksten skal i prinsippet ikke inkluderes i det eksterne variantapparatet. Her er det hovedeksemplarets lesemåte som gjelder som lesemåte for grunnteksten, selv om alle lesemåtene selvfølgelig vises i den løpende teksten. Men det forekommer at samme tekststed inneholder både internvariasjon i grunnteksten og eksternvariasjon mellom ulike tekstkilder. Her er et tilfelle med både intern- og eksternvariasjon på samme tekststed i Fruen fra havet. FHf1 er grunntekstens hovedeksemplar. Grunntekstkodinga blir slik:
<app type="external" subtype="word" id="varFH-9">
<rdg wit="FH88" var="N">
<app type="internal">
<rdg wit="FH88f1 FH88f2">se</rdg>
<rdg wit="FH88f3">s</rdg>
</app>
</rdg>
<rdg wit="FHFU FH02" var="N">se</rdg>
<rdg wit="FH4262III3" var="Y">s</rdg>
<note resp="editor" type="variant" rend="text">tekststedet har internvariasjon</note>
</app>
I variantliste og løpende grunntekst vil begge internvariantene føres, med hovedeksemplarets lesemåte først. Utgivernoten om internvariasjon skal bare vises i den løpende teksten (som pop-up e.l.), ikke i variantlisten. Derfor har den attributtverdien "text", jf. Utgivernoter. Innførselen i variantlisten blir seende slik ut:
se|sé FH88, se FHFU, FH02, sé FH4262III3
kap-13.6.7: Forskjeller i linjeskift
Forskjeller i linjeskift inkluderes i prinsippet ikke i variantapparatet. Det er ikke interessant i prosatekst, og heller ikke der verslinjer er delt i to pga. plassmangel. Noen ganger er likevel linjeskiftet interessant, som når rimordet opptrer i feil linje eller det forekommer haplo- eller dittografier ved linjeskift.
kap-13.6.7.1: Feilaktig verslinjeoppsett
I Gildet på Solhaug (1883) er rimordet i en verslinje plassert først i neste verslinje. Slik variasjon er interessant og innlemmes i variantapparatet. Variasjonen kan være vanskelig å oppdage med Juxta, men vil fanges opp i den metriske analysen av tekstene.
Varianttypen karakteriseres som "word" (jf. Varianttyper), og linjeskiftet kodes med rend-attributtet "solidus", slik at skråstrek kan genereres til variantlisten. En forklarende utgivernote, <note resp="editor">, legges til:
KODING: <lb/><sp who="GUDMUND"><spOpener><speaker>Gudmund</speaker>.</spOpener> <lb/><l part="F">Det blev sagt, hun <app type="external" subtype="word" id="varG2-x"> <rdg wit="G283 G2FU" var="N">skulde <lb rend="solidus"/>være</rdg> <rdg wit="G28951" var="Y">skulde være</rdg> <note resp="editor" type="variant">i 1. utg. og FU er rimordet feilaktig plassert innenfor neste verslinje</note> </app></l> <l part="I">hos eder.</l></sp> VARIANTLISTE: skulde / være] 1. utg, FU, skulde være NBO Ms.8° 951, i 1. utg. og FU er rimordet feilaktig plassert innenfor neste verslinje
kap-13.6.7.2: Haplo- og dittografier ved linjeskift
Noen ganger forekommer haplo- og dittografier (dvs. utelatt ord/stavelse eller dobbeltskriving av ord/stavelse) ved linjeskift. Slike forskjeller inkluderes selvfølgelig i variantapparatet. For å forklare varianten gjengis bindestreken i variantlisten og linjeskiftet omtales i en utgivernote:
KODING: <app type="external" subtype="word" id="varSS-272"> <rdg wit="SS77 SS77a SS93 SSFU SS00" var="N">ikke</rdg> <rdg wit="SS8956" var="Y">ik- <note resp="editor" type="variant">NBO Ms. 8° 956, haplografi ved linjeskift</note></rdg> </app> VARIANTLISTE: ikke] 1.–3.utg., FU, 4.utg. ik- NBO Ms. 8° 956, haplografi ved linjeskift
kap-13.6.8: Store avvikende tekststeder, fragmenter
Som stort avvikende tekststed regnes et helt tekstelement (f.eks. en overskrift, sceneanvisning eller replikk) som mangler i n eller flere tekstkilder. Ved slik variasjon føres den manglende teksten for alle tekstkildene som har lesemåten i apparatet. Ved store tekstspenn føres bare første eller siste ord som lemma. Ved tekstkilden(e) som mangler lesemåten legges det inn en utgivernote, <note resp="editor" type="variant">, som gir informasjon om manglende (eller ekstra) tekst i forhold til grunnteksten. Noten vises både i variantlisten og inne i den aktuelle løpende teksten i den synoptiske variantvisningen. I slike tilfeller er det altså manglende tekst, samt noten, som fargemarkeres i variantvisningen.
I tekstmaterialet til Catilina (1875) hører to mindre fragmenter, NBO Ms. 8° 1938:1 og NBO Ms. 8° 1938:2. Det første inneholder utkast til forord, det andre en påbegynt renskrift (3 s.) av dramateksten. Kodingen av slutten på fragmentene ser slik ut:
VED C219382'S BEGYNNELSE: <lb/><head> <app type="external" subtype="word" id="varC2-151"> <rdg wit="C275 C241395 C291 C2FU" var="N">FØRSTE</rdg> <rdg wit="C2819381" var="Y"><note resp="editor" type="variant">teksten slutter her i NBO Ms. 8° 1938:1</note></rdg> <rdg wit="C2819382" var="N">Første</rdg> </app> AKT.</head> VED C219382'S SLUTT: <sp>...<l>ved list og rænker blir man hersker her!</l></sp> <sp who="OLLOVICO"><spOpener><speaker> <app type="external" subtype="word" id="varC2-152"> <rdg wit="C275 C241395 C291 C2FU" var="N">Ollovico</rdg> <rdg wit="C2819382" var="Y"><note resp="editor" type="variant">teksten slutter her i NBO Ms. 8° 1938:2</note></rdg> </app> </speaker>.</spOpener>
Innførslene i variantlisten blir seende slik ut:
FØRSTE] 1. utg., NBO Ms. 4° 1395, 2 utg., FU, teksten slutter her i NBO Ms. 8° 1938:1, Første NBO Ms. 4° 1938:2 Ollovico] 1.utg., NBO Ms. 4° 1395, 2 utg., FU, teksten slutter her i NBO Ms. 8° 1938:2
kap-13.6.8.1: Manglende dikt i diktsamlinger
Til senere utgaver av Digte ble det lagt til stadig flere dikt. Siden diktene blir kodet i egne <div type="poem"> og vi trenger en ny <div> å legge noten om manglende dikt i, benyttes <div type="externalApparatus">. Når grunntekstfilen, som jo inneholder alle variantene til variantlisten, mangler dikt, føres likevel variantene som skal med i variantlista:
<div type="externalApparatus"> <p> <app type="external" subtype="word" id="varDi_167"> <rdg wit="Di75 Di79 Di82 Di86 Di91 Di96 DiFU Di01" var="Y">Sanger-hilsen</rdg> <rdg wit="Di71 Di42622" var="N"> <note resp="editor" type="variant">diktet <q>Sanger-hilsen til Sverig</q> mangler i 1. utg. og KBK Collin 262, 4°, II.2</note> <note resp="editor" type="variant" rend="text">Diktet <q>Sanger-hilsen til Sverig</q> mangler i 1. utg.</note></rdg> </app> <app type="external" subtype="interpunction" id="varDi_168"> <rdg wit="Di75 Di79 Di86 Di91 Di96 DiFU Di01" var="Y">1875.)</rdg> <rdg wit="Di82" var="Y">1875.</rdg> </app> <app type="external" subtype="word" id="varDi_169"> <rdg wit="Di75" var="Y">ad</rdg> <rdg wit="Di79 Di82 Di86 Di91 Di96 DiFU Di01" var="Y">da</rdg> </app> <app type="external" subtype="word" id="varDi_170"> <rdg wit="Di75" var="Y">fra</rdg> <rdg wit="Di79 Di82 Di86 Di91 Di96 DiFU Di01" var="Y">for</rdg> </app> <app type="external" subtype="word" id="varDi_171"> <rdg wit="Di75 Di79 Di82 Di86 Di91 Di96 DiFU Di01" var="Y">Langt borte</rdg> <rdg wit="Di71 Di42622" var="N"> <note resp="editor" type="variant">diktet <q>Langt borte</q> mangler i 1. utg. og KBK Collin 262, 4°, II.2</note> <note resp="editor" type="variant" rend="text">Diktet <q>Langt borte</q> mangler i 1. utg.</note></rdg> </app> ... </p> </div>
kap-13.7: Noter
I dette kapitlet omtales både utgivernoter som hører til variantvisningen og arbeidsnoter som brukes underveis i arbeidet med filene.
Utgivernoter benyttes til forklaringer i variantvisningen. De står innenfor eller utenfor en <rdg> i <app type="external">, plasseringen kan velges etter oppsett i variantlisten eller etter innhold i noten (om det omhandler en av variantene eller hele apparatet).
Foreløpig benyttes noter ved:
- internvariasjon
- store avvikende tekststeder
- haplo- og dittografier ved linjeskift
- transkripsjonsnormalisering
Noter angående transkripsjonsnormalisering er bare nødvendig dersom denne forstyrrer den faktiske variasjonen på tekststedet, f.eks. i Samfundets støtter som har en ekstern variant hånd/hand, men der et av manuskriptene (NBO Ms. 8° 956) har normalisert nettopp 'hand' til 'hånd' (manglende prikker over i-er og boller over a-er forekommer hyppig og rettes stilltiende). Dermed plasseres denne tekstkilden sammen med tekstkildene som har 'hånd' på dette stedet. Slike noter skal ikke forekomme på andre steder enn der det er ekstern variasjon. Transkripsjonsnormaliseringen av manuskripter vil det gjøres generelt rede for annetsteds i HISe.
kap-13.7.1.1: Noter til variantlisten vs. noter til løpende tekst
Grunntekstfilen kan trenge både variantnoter som angår grunnteksten spesielt, og variantnoter som gjelder flere utgaver. Samtidig kan det være nødvendig å skille mellom noter som skal vises i løpende tekst og noter som skal vises i variantlisten. For noter som bare skal vises i løpende tekst legges det til et eget rend="":<note resp="editor" type="variant" rend="text">. Her er noen eksempler:
KODING: <app type="external" subtype="word" id="varDi_1"> <rdg wit="DiFU Di01" var="Y">Til Frederik Hegel</rdg> <rdg wit="Di71 Di42622 Di75 Di79 Di82 Di86 Di91 Di96" var="N"> <note resp="editor" type="variant">diktet <q>Til Frederik Hegel</q> mangler i 1. utg., KBK Collin 262, 4°, II.2 og 2.–7. utg.</note> <note resp="editor" type="variant" rend="text">Diktet <q>Til Frederik Hegel</q> mangler i 1. utg.</note></rdg></app> VARIANTLISTE: Til Frederik Hegel] FU, 8. utg., diktet Til Frederik Hegel mangler i 1. utg., KBK Collin 262, 4°, II.2 og 2.–7. utg. KODING: <app type="external" subtype="word" id="varOL2-3"> <rdg wit="OLFU" var="N"> <app type="internal"> <rdg wit="OLFUf2">jeg</rdg> <rdg wit="OLFUf1 OLFUf3">eg</rdg> </app> </rdg> <rdg wit="OL04" var="Y">eg</rdg> <note resp="editor" type="variant" rend="text">tekststedet har internvariasjon</note> </app> VARIANTLISTE: jeg ] FU, eg 2. utg. KODING: <app type="external" subtype="word" id="varSS-272"> <rdg wit="SS77 SS77a SS93 SSFU SS00" var="N">ikke</rdg> <rdg wit="SS8956" var="Y">ik- <note resp="editor" type="variant">NBO Ms. 8° 956, haplografi ved linjeskift</note></rdg> </app> VARIANTLISTE: ikke] 1.–3.utg., FU, 4.utg. ik- NBO Ms. 8° 956, haplografi ved linjeskift
kap-13.7.1.2: Generering av tekstkildebetegnelser
Dersom en note står inne i en <rdg>, genereres ikke tekstkildebetegnelsen av wit=""-attributtet. Tekstkildebetegnelsen må da skrives inne i noteteksten (ikke først), slik at det blir et tydelig skille mellom de ulike lesemåtene i variantlisten. I noteteksten benyttes de faktiske tekstkildebetegnelsene, ikke våre interne betegnelser (filnavn). Se eksempler ovenfor.
kap-13.7.2: Sluttnote – <note type="varThrough">
Beskrivelser av gjennomgående variasjon, større avvikende tekststeder, spesialtilfeller vedrørende transkripsjon (f.eks. (fra forordet til G2) at det i et manuskript benyttes '' til svensk tekst og 'ø' til norsk, mens det i et annet benyttes '' gjennomgående, men at vi transkriberer alle som 'ø') og ev. andre opplysninger som angår det eksterne variantapparatet legges til en <note type="varThrough"> til slutt i grunntekstfila. Her er et eksempel fra G1.xml (det er også tillatt med løs prosatekst i <p> i stedet for eller i tillegg til listestrukturen nedenfor):
<note type="varThrough">
<text>
<body>
<div>
<head>Oversikt over gjennomgående variasjon, samt store tekstavvik i
G1-materialet</head>
<list>
<item>manglende innførsler i rollelisten:
<list>
<item>G1505 mangler følgende innførsler: 'En gammel Mand'</item>
<item>G1348s mangler følgende innførsler: 'Første Huskarl', 'Anden
Huuskarl', 'En Pige'</item>
</list>
</item>
<item>annen rekkefølge i rollelisten:
<list>
<item>G1505 har 'Et sendebud' rett etter 'Erik fra Hægge'.</item>
<item>G1348s har 'En gammel mand' og 'Et sendebud' (i denne
rekkefølgen) skrevet til under rollelisten</item>
</list>
</item>
</list>
</div>
</body>
</text>
</note>
Slike noter kan ligge i alle tekstkilder underveis i variantkodearbeidet. Når arbeidet med et verk er ferdigstilt, skal imidlertid informasjonen samles i noten i grunntekstfila og notene i de øvrige filene slettes. Informasjonen benyttes til å skrive informasjonstekst til de enkelte verkenes variantapparater i e-utgaven.
kap-13.8: Kontroll av variantene
Etter at variantkodinga til et verk er fullført skal alle variantene som er ført i apparatet, sjekkes. Noen av kontrollene bør tas av forskningsassistenter, andre kan tas av studentmedarbeidere. Dette blir spesifisert nedenfor. Det er viktig at kontrollene utføres i den rekkefølgen de er listet opp her:
- kontroll av <app>: søk fram alle startelementer til <app type="external"> vha. SGREP. Ta utskrift av slike lister for alle tekstfilene. Sjekk at kodinga, dvs. id-numre og word/interpunction, stemmer overens for alle filene. Kontrollen utføres av en forskningsassistent, før det lages variantvisninger.
- transkripsjonskontroll: de oppførte lesemåtene i den lemmatiserte variantlisten sjekkes mot de faktiske tekstkildene (for manuskripter kan faksimiler benyttes). Samtidig sjekkes det at alle tekstkilder står oppført til riktig lesemåte. Kontrollen kan utføres av en studentmedarbeider.
- kontroll av var="": Kan enkelt ses hvis man tar et Sgrep-søk på alle apparater. 'N' skal alltid stå først sammen med grunnteksten, og 'Y' sist. (Om tekstkildene er ført riktig opp i forhold til grunnteksten er allerede kontrollert i punktet over "transkripsjonskontroll"). Kontrollen utføres av en forskningsassistent.
- kontroll av subtype="": det kontrolleres om de enkelte variantene er typifisert riktig, som ord- eller tegnsettingsvariasjon. Til kontrollen benyttes visningen av ordvarianter og visningen av tegnsettingsvarianter. Ved tvil konsulteres retningslinjene i Kodepraksis. Kontrollen utføres av en forskningsassistent.
- synkroniseringskontroll: alle varianter i alle filer sjekkes ved å klikke seg gjennom alle fargemarkerte steder i den synoptiske variantvisningen. De enkelte variantene (+ nærmest omliggende kontekst) sammenholdes med lesemåtene i den lemmatiserte variantlisten. Konteksten tas med for å oppdage ev. duplisering ved klippe-lime-operasjoner. Kontrollen kan tas av en studentmedarbeider. Ev. korrekturer fra tidligere kontroller bør først føres inn i filene, slik at det kan lages nye visninger til denne synkroniseringskontrollen.
- opptelling av varianter, for oppføring i <notesStmt>, samt i <variantEncoding n=""/>: kan gjøres ved å ta et Sgrep-søk på alle apparater, kopiere denne listen over i TextPad som txt-fil og flytte rundt på app-kodene så de med lik fordeling av tekstkildene blir samlet i grupper. Da kan man telle opp innenfor hver gruppe og summere opp de enkelte tekstkildenes variasjon i forhold til grunnteksten ut fra dette.
- la en annen forskningsassistent se gjennom den endelige lemmalisten for eventuell overflødig variantkoding.
- utførelsen av variantkontrollen loggføres i de enkelte verkenes statusrapporter
kap-14: Edering og hovedtekstkoding
kap-14.1: Innledning
Dette kodepraksiskapitlet inneholder all koding som angår ederingen av hovedtekster, inkl. endringer i <teiHeader>.
kap-14.2: <teiHeader> og dokument-topp
kap-14.2.1: Dokument-topp
Følgende dokument-topp skal brukes i hovedtekstfiler:
STANDARDTOPP <?xml version="1.0" encoding="ISO-8859-1"?> <?xml-stylesheet type="text/xsl" href="../../Stilark/hovedtekst/hovedtekst_X_X.xsl"?> <!DOCTYPE TEI.2 PUBLIC "-//TEI P4 Ibsen-XML//DTD TEI P4 Unified for HIS//EN" " http://www.edd.uio.no:8088/his/DTD/ibsen-xml.dtd"> MED <rs>-KODING I FILEN INKL. FØLGENDE: <!ENTITY Ibsen-keys SYSTEM 'http://helmer.aksis.uib.no/his/ID-verdier.xml' >
kap-14.2.2: Filbeskrivelse – <fileDesc>
kap-14.2.2.1: Den elektroniske tekstens tittel – <titleStmt>
Opplysninger som må være med:
- <title level="" type=""> – tittel
- hovedtekstfiler skal ha HIS-tittel og hovedteksttittel
- «Henrik Ibsens skrifter/Historisk-kritisk utgave»
- «Catilina»
- verkets tittel hentes fra grunntekstens tittelblad og gjengis diplomatarisk
- eventuell undertittel tas ikke med
- for tekster uten tittel suppleres en tittel i klammeparenteser. Prosjektet/redaksjonen vedtar titler for grunntekster som mangler tittel
- det skal opplyses om hvilken hovedversjon teksten tilhører når det er flere verkversjoner samt om den er grunntekst eller hovedtekst (alle tekster er tekstkilder til verket, status som grunntekst eller hovedtekst kommer i tillegg), tekstkildebetegnelsene som brukes i de tekstkritiske notene skal brukes (termen "førstetrykk" skal ikke brukes i XML-filene).
- det skal opplyses om årstall, usikre årstall angis i skarpe klammer
- level="" – tittelnivå innenfor utgaven
- level="s" – «series» (flerbindsverk) – HIS-tittel
- level="a" – «analytic» (del av et bind) – den enkelte hovedtekstens deler
- type="" – tittelnivå
- type="main" – hovedtittel, eks.:
- level="s": «Henrik Ibsens skrifter»
- level="a": «Catilina» (verktittel)
- type="sub" – undertittel/tekstens status i HIS, eks.:
- level="s": «Historisk-kritisk utgave»
- level="a": «Annen hovedversjon, hovedtekst, 1. utg.»
- type="origYear" – årstall
- type="main" – hovedtittel, eks.:
- hovedtekstfiler skal ha HIS-tittel og hovedteksttittel
- <author> – forfatter
- <funder> – finansiering, inneholder entiteten &funder; som henter frem en tekst som dokumenterer prosjektets finansiering
- <editor> – vitenskapelig ansvarlige, inneholder entiteten &editor; som henter frem en liste over de som er/ har vært vitenskapelig ansvarlige
- <respStmt>: det skal opplyses om hvem som har arbeidet med en tekst, hva vedkommende medarbeider har gjort: edering, ederingskoding, metrisk koding, kollasjonering, koding og/eller korrektur/kodekontroll (kodeoppdateringer regnes som koding). Hver medarbeider føres en gang for hver av de oppgavene de har hatt (forsøk å minimere listene). Samkjør med statusrapportene under oppdatering. Dato er unødvendig (listen kan føres slik at de som er ansvarlige for/har gjort mest med ei fil føres øverst, jf. eks. nedenfor). AKSIS føres opp under «Kodeteknisk støtte og utvikling»
Eks. C2ht.xml:
<titleStmt> <title level="s" type="main">Henrik Ibsens skrifter</title> <title level="s" type="sub">Historisk-kritisk utgave</title> <title level="a" type="main">Catilina</title> <title level="a" type="sub">Annen hovedversjon, hovedtekst, 1. utg.</title> <title level="a" type="origYear">1875</title> <author>Henrik Ibsen</author> <funder>&funder;</funder> <editor>&editor;</editor> <respStmt> <resp>Edering</resp> <name>Christian Janss</name> <name>Ståle Dingstad</name> <name>Hilde Bøe</name> <name>Stine Brenna Taugbøl</name> <resp>Kodeteknisk støtte og utvikling</resp> <name>AKSIS: Avdeling for kultur, språk og informasjonsteknologi, Universitetsforskning i Bergen (Unifob AS)</name> <resp>Ederingskoding</resp> <name>Hilde Bøe</name> <name>Stine Brenna Taugbøl</name> <name>Ellen Nessheim Wiger</name> <resp>Metrisk koding</resp> <name>Stine Brenna Taugbøl</name> <resp>Kollasjonering, koding og korrektur</resp> <name id="HIS-HL">Hanne Lauvstad</name> <name id="HIS-HY">Hallvard Ystad</name> <name id="HIS-MW">Mette Witting</name> <name id="HIS-IF">Ingrid Falkenberg</name> <resp>Koding og korrektur</resp> <name>Hilde Bøe</name> <name id="HIS-MS">Margit Sauar</name> <resp>Koding</resp> <name id="HIS-HG">Helene Grønlien</name> <name>Espen S. Ore</name> <resp>Kollasjonering</resp> <name id="HIS-HMS">Henninge Margrethe Solberg</name> <name id="HIS-GW">Gunnhild Wiggen</name> </respStmt> </titleStmt>
Hovedtekst-brevfil:
<titleStmt> <title level="s" type="main">Henrik Ibsens skrifter</title> <title level="s" type="sub">Historisk-kritisk utgave</title> <title level="a" type="main">Brev 1844-1871</title> <author>Henrik Ibsen</author> <funder>&funder;</funder> <editor>&editor;</editor> <respStmt> <resp>Edering</resp> <name>Christian Janss</name> <name>Ståle Dingstad</name> <name>Stine Brenna Taugbøl</name> <name>Ellen Nessheim Wiger</name> <resp>Ederingskoding</resp> <name>Stine Brenna Taugbøl</name> <name>Ellen Nessheim Wiger</name> <resp>Metrisk koding</resp> <name id="HIS-IF">Ingrid Falkenberg</name> <name>Stine Brenna Taugbøl</name> <resp>Kollasjonering, koding og korrektur</resp> <name id="HIS-IAA">Ingvald Aarstein</name> <name id="HIS-MW">Mette Witting</name> <name id="HIS-HG">Helene Grønlien</name> <name id="HIS-NME">Nina M. Evensen</name> <name id="HIS-MS">Margit Sauar</name> <name id="HIS-AMB">Aasta Marie Bjorvand Bjørkøy</name> <resp>Kollasjonering og korrektur</resp> <name id="HIS-CB">Cathrine Brøymer</name> <name id="HIS-MA">Maria Alnæs</name> <name id="HIS-MD">Marianne Dahl</name> <name id="HIS-HS">Henninge Solberg</name> <name id="HIS-GW">Gunnhild Wiggen</name> </respStmt> </titleStmt>
Hovedtekst-diktfil:
<titleStmt> <title level="s" type="main">Henrik Ibsens skrifter</title> <title level="s" type="sub">Historisk-kritisk utgave</title> <title level="a" type="main">Dikt</title> <author>Henrik Ibsen</author> <funder>&funder;</funder> <editor>&editor;</editor> <respStmt> <resp>Edering</resp> <name id="HIS-CJ">Christian Janss</name> <name id="HIS-ENW">Ellen Nessheim Wiger</name> <name id="HIS-SBT">Stine Brenna Taugbøl</name> <resp>Kodeteknisk støtte og utvikling</resp> <name>AKSIS: Avdeling for kultur, språk og informasjonsteknologi, Universitetsforskning i Bergen (Unifob AS)</name> <resp>Ederingskoding</resp> <name>Stine Brenna Taugbøl</name> <name>Ellen Nessheim Wiger (kodekontroll, registre, lemmareferanser)</name> <resp>Metrisk koding</resp> <name>Stine Brenna Taugbøl</name> <name id="HIS-IF">Ingrid Falkenberg</name> <resp>Kollasjonering, koding og korrektur</resp> <name id="HIS-MW">Mette Witting</name> <name>Ingrid Falkenberg</name> <name>Stine Brenna Taugbøl</name> <name id="HIS-KK">Kari Kinn</name> <name id="HIS-AAH">Åshild Haugsland</name> <name id="HIS-MS">Margit Sauar</name> <name id="HIS-SL">Sigrid Larsson</name> <name id="HIS-IAA">Ingvald Aarstein</name> <name id="HIS-EFS">Eivor Finset Spilling</name> <name id="HIS-IMK">Inger Marie Kjølstadmyr</name> <name>Ellen Nessheim Wiger</name> <name id="HIS-AA">Asbjørn Aarseth</name> <name id="HIS-AMB">Aasta Marie Bjørkøy</name> <name id="HIS-GW">Gunnhild Wiggen</name> <name id="HIS-HMS">Henninge Solberg</name> <name id="HIS-HG">Helene Grønlien</name> <name id="HIS-GB">Gry Berg</name> <name id="HIS-III">Ingunn Ims</name> <name id="HIS-NME">Nina Marie Evensen</name> <resp>Skanning av tekst</resp> <name>Ramazan Tashakori</name> </respStmt> </titleStmt>
Hovedtekst-prosa:
<fileDesc> <titleStmt> <title level="s" type="main">Henrik Ibsens skrifter</title> <title level="s" type="sub">Historisk-kritisk utgave</title> <title level="a" type="sub">Sakprosa</title> <author>Henrik Ibsen</author> <funder>&funder;</funder> <editor>&editor;</editor> <respStmt> <resp>Edering</resp> <name>Christian Janss</name> <name>Aina Nøding</name> <name>Ellen Nessheim Wiger</name> <resp>Ederingskoding</resp> <name>Ellen Nessheim Wiger</name> <resp>Kodekontroll</resp> <name>Stine Brenna Taugbøl</name> <resp>Kollasjonering, koding og korrektur</resp> <name>Nina Marie Evensen</name> <resp>Kollasjonering</resp> <name>Kari Kinn</name> <name>Inger Marie Kjølstadmyr</name> <name>Oliver Blomqvist</name> <name>Eivor Finset Spilling</name> <name>Ellen Nessheim Wiger</name> <name>Mette Witting</name> <name>Ingvald Aarstein</name> <resp>Korrekturkollasjonering</resp> <name>Kari Kinn</name> <name>Inger Marie Kjølstadmyr</name> <name>Oliver Blomqvist</name> <name>Eivor Finset Spilling</name> </respStmt> </titleStmt>
kap-14.2.2.2: Tekstens utgave – <editionStmt>
Her føres versjonsspesifikk dato. Se forøvrig «Metainformasjon – <teiHeader>».
<editionStmt>
<edition id="G1ht-0603"/>
</editionStmt>
kap-14.2.2.3: Publiseringsinfo – <publicationStmt>
<publicationStmt> er et av en rekke <teiHeader>-elementer som i fasen før publisering av den elektroniske utgaven skal ha standardisert innhold. Årstall for publisering må justeres for den enkelte hovedtekst.
<publicationStmt> <publisher>Universitetet i Oslo ved Henrik Ibsens skrifter</publisher> <distributor id="HISb">H. Aschehoug & co</distributor> <date value="2006" id="HISb-date"/> <distributor id="HISe">Universitetet i Oslo</distributor> <date value="2010" id="HISe-date"/> <pubPlace>Oslo</pubPlace> </publicationStmt>
kap-14.2.2.4: Bibliografiske opplysninger om kildene – <sourceDesc>
kap-14.2.2.4.1: Dramafiler
Hovedtekstfilen bygger alltid på den utgaven av grunntekstfilen(e) som den i utgangspunktet var kopi av, og dette opplyses det om i et innledende <p>-element.
<sourceDesc> <p>Denne filen bygger på C1.xml (C1-1003).</p> ... </sourceDesc>
Deretter gis de bibliografiske opplysningene for grunnteksten(e) i egen <bibl>/<msDescription>. Denne/disse følges av en liste over øvrige tekstkilder, som er konsultert i ederingsarbeidet. Her tas bare versjonens kilder med selv om man har konsultert øvrige verksversjoner i arbeidet. Disse kodes samlet i en <listBibl> med egen <head>, jf. nedenfor.
<bibl id="C1"> <orgName type="owner">Deichmanske Bibliotek</orgName> <idno id="C1f1">Ib8ca</idno> <orgName type="owner">Odd Syse, Bibliofiliklubben</orgName> <idno id="C1f2">[i privat eie]</idno> <orgName type="owner">Damms antikvariat</orgName> <idno id="C1f3">[i privat eie]</idno> <monogr> <author>Henrik Ibsen</author> <title type="main">Catilina</title> <title type="sub">Drama i tre Acter</title> <edition>Førsteutgave</edition> <imprint> <pubPlace>Christiania</pubPlace> <publisher>P. F. Steensballe</publisher> <printer>F. Steens Bogtrykkeri</printer> <date>1850</date> </imprint> </monogr> </bibl> <listBibl> <head>Tekstvitner konsultert i ederingen</head> <msDescription type="workingManuscript" id="C14936"> <msIdentifier> <settlement>Oslo</settlement> <repository>Nasjonalbiblioteket</repository> <idno>NBO Ms.4° 936</idno> </msIdentifier> <msHeading> <title>Catilina</title> <author>Henrik Ibsen. Av Brynjolf Bjarme.</author> <origDate>1849</origDate> <matDesc>Første utarbeidelse med mange overstrykninger og rettelser. Egenhendig. Se forøvrig Tone Modalslis manuskriptbeskrivelse.</matDesc> </msHeading> </msDescription> <bibl id="C1HU"> <orgName type="owner">HIS</orgName> <idno>Ekspl. 1</idno> <author>Henrik Ibsen</author> <title>Catilina</title> <edition>[Hundreårsutgave]</edition> <series> <editor>Francis Bull, Halvdan Koht og Didrik Arup Seip</editor> <title>Hundreårsutgave. Henrik Ibsens samlede verker</title> </series> <imprint> <pubPlace>Oslo</pubPlace> <publisher>Gyldendal</publisher> <date>1928-57</date> <printer>Dreyer, Stavanger</printer> </imprint> <monogr> <title>Samlede verker. Første bind. Catilina. Kjæmpehøien. Norma.</title> <imprint> <biblScope type="volume">Bd.1</biblScope> <date>1928</date> </imprint> </monogr> </bibl> </listBibl> </sourceDesc>
kap-14.2.2.4.2: Brevfiler
I hovedtekstfiler for brev skal <sourceDesc> inneholde en liste over grunntekstfilene hovedtekstfilen baserer seg på (<list> i <p>) og <msDescription>/<bibl> for hvert brev.
Her er listen over grunntekstfiler i HIS 13:
<sourceDesc> <p> <list> <head>Grunntekstfiler</head> <item>B1871juni-desgt.xml</item> <item>B1872gt.xml</item> <item>B1873gt.xml</item> <item>B1874gt.xml</item> <item>B1875gt.xml</item> <item>B1876gt.xml</item> <item>B1877gt.xml</item> <item>B1878gt.xml</item> <item>B1879gt.xml</item> </list> </p> <msDescription>/<bibl> </sourceDesc>
<msDescription>/<bibl> for hvert brev hentes inn fra grunntekstfilene.
I <msDescription> ligger også <letterinfo>, som kopieres fra grunntekstfila (type="" erstattes med resp="", med brev-ID som attributtverdi). Opplysninger herfra hentes ut til brevhodet for de enkelte brevene. Opplysninger som benyttes er (i denne rekkefølgen): Mottaker, sted, datering. Opplysninger om hvorvidt brevet er et telegram, og om oversettelser av fremmedspråklige brev, skal også stå i <letterinfo> og hentes ut til brevhodet. Tekst i <letterinfo> skal gjengis i kapitler og transkriberes derfor med minuskler, unntak er tekst i <translation> som skal stå i majuskler og minuskler (både i kodet fil og i bokutgaven).
Eksempel på fremmedspråklig telegram:
<msDescription type="letter" id="B18751030EaE">
<msIdentifier>
<settlement>Stockholm</settlement>
<repository>Stockholms stadsarkiv</repository>
<idno>Af Edholms samling, F:25 (Theaterpapper III), spelåret 1875-76, nr. 38</idno>
</msIdentifier>
<letterinfo corresp="B18751030EaE">
<sender><rs type="person" corresp="peHI">henrik ibsen</rs></sender>
<recipient><rs type="person" corresp="peEaE">erik af edholm</rs></recipient>
<origDate value="1875-10-30">30. oktober 1875</origDate>
<origPlace><rs type="place" corresp="plMun">mnchen</rs></origPlace>
<lettertype>telegram</lettertype>
<translation>Oversettelse av telegrammet finnes i kommentarbindet.</translation>
</letterinfo>
</msDescription>
kap-14.2.2.4.3: Diktfiler
Hovedtekstfilen for dikt skal inneholde en liste over grunntekstfilene den bygger på:
<sourceDesc> <p> <list> <head>Grunntekstfiler</head> <item>DSkjaerMinPen.xml</item> <item>DSigFinkelbechsGrav_gt_Ms.xml</item> <item>BlaDigt8191.xml</item> <item>BlaDigtIHoesten_verksfil.xml</item> <item>BlaDigtSkjaldenValhal_ChrPosten_gt.xml</item> <item>BlaDigtINatten_verksfil.xml</item> <item>BlaDigtMaaneskinsvandEftBal_verksfil.xml</item> <item>BlaDigtResignation_verksfil.xml</item> <item>BlaDigtTvivlHaab_verksfil.xml</item> <item>BlaDigtTilUngarn_verksfil.xml</item> <item>BlaDigtTilNorgesSkjalde_verksfil.xml</item> <item>BlaDigtDoedningeballet_Folkebl_gt.xml</item> <item>BlaDigtLedigtLogis_verksfil.xml</item> <item>BlaDigtTilStjernen_verksfil.xml</item> <item>BlaDigtVedHavet_Tilsk_gt.xml</item> ... </list> </p> </sourceDesc>
<msDescription>/<bibl> for de enkelte diktene/verkene hentes inn fra grunntekstfilene:
<bibl id="DSkjaerMinPen_Eidsvold"> <orgName type="owner">Nasjonalbiblioteket, Mo i Rana</orgName> <idno></idno> <monogr> <author>Henrik Ibsen</author> <title type="main">uten tittel</title> <edition>avistrykk</edition> <imprint> <pubPlace></pubPlace> <printer></printer> <date value="1900-10-08">8. okt. 1900</date> </imprint> </monogr> </bibl> <msDescription type="finalFairCopy" id="DSigFinkelbechsGrav_Ms"> <msIdentifier> <settlement>Drøbak</settlement> <repository>J. Feght-Holst</repository> <idno>Ms. i privat eie</idno> </msIdentifier> <msHeading> <author>Uten forfatternavn</author> <title type="main">Sigurd von Finkelbech's Gravsted</title> <origDate>Uten datering</origDate> <matDesc>Grunntekst. Renskrift med dekor. Det finnes også et usignert håndskrevet dikt nederst på venstre side av arket med annen tekstretning, håndskriften tilhører antakelig ikke Ibsen. Obs NBO Ms.fol. 3848 (kopi)</matDesc> </msHeading> </msDescription> ...
kap-14.2.2.4.4: Sakprosafiler
Hovedtekstfilen for sakprosa skal inneholde en liste over grunntekstfilene den bygger på:
<sourceDesc> <p><list> <head>Grunntekstfiler</head> <item>P1841-59gt.xml</item> <item>P1860-69gt.xml</item> <item>P1870-79gt.xml</item> <item>P1880-89gt.xml</item> <item>P1890-1900gt.xml</item> <item>Nye_gt_sakprosa.xml</item> <item>Flere_nye_sakprosatekster.xml</item> </list></p> ... </list> </sourceDesc>
<msDescription>/<bibl> for de enkelte tekstene hentes inn fra grunntekstfilene:
<msDescription type="workingManuscript" id="P1850Fangen"> <msIdentifier> <settlement>Grimstad</settlement> <repository>Ibsenhuset</repository> <idno/> </msIdentifier> <msHeading> <author>Henrik Ibsen</author> <title type="main">Fangen paa Agershuus</title> <title type="sub">En Skitse fra Slutningen af forrige Aarhundrede</title> <title type="occasion">Romanforsøk</title> <origDate>1850</origDate> <matDesc>Manuskript. Deler av overskriften er understreket, ikke kodet inn. Manuskriptbeskrivelse er utført og finnes i sakprosapermen.</matDesc> </msHeading> </msDescription>
<bibl id="P18611222Fort"> <orgName type="owner">UBO</orgName> <idno>51ka43337</idno> <analytic> <author>Henrik Ibsen</author> <title type="sub">Fortællinger af Klaus Groth</title> <title type="occasion">Anmeldelse</title> </analytic> <monogr> <title>Illustreret Nyhedsblad (søndag, nr. 51, 10. årg.)</title> <imprint> <pubPlace>Kristiania</pubPlace> <publisher/> <printer/> <date>22.12.1861</date> </imprint> </monogr> <proseinfo type="article"> <matDesc>Fraktur. Utheving ved sperring og fet (overskriften). Litteraturavdelingen er trykt i mindre font enn den øvrige teksten på siden.</matDesc> </proseinfo> </bibl>
kap-14.2.3: Beskrivelse av kodingen – <encodingDesc>
kap-14.2.3.1: Prosjektbeskrivelse – <projectDesc>
For prosjektbeskrivelsen er det utarbeidet tre standardtekster: en for trykte hovedtekster (&projectDesc-ht-trykk;); en for hovedtekster basert på manuskriptgrunntekster (&projectDesc-ht-ms;) og en for filer med større tekstkorpora, der både trykte tekster og manuskripter kan være inkludert (&projectDesc-ht-corpus;).
<projectDesc>
<p>&projectDesc-ht-trykk;</p>
</projectDesc>
<projectDesc>
<p>&projectDesc-ht-ms;</p>
</projectDesc>
<projectDesc>
<p>&projectDesc-ht-corpus;</p>
</projectDesc>
kap-14.2.3.2: Filologisk praksis – <editorialDecl>
Elementet <editorialDecl> deklarerer hva slags filologisk praksis som er fulgt i arbeidet med å kode teksten. Det inneholder dessuten beskrivelser av typografien til de tekstkildene som XML-filen inneholder. Sist i elementet skal det ligge en <p> med en generell redegjørelse for filologisk praksis og henvisning til prosjektets tekstkritiske retningslinjer, jf. nedenfor om referanse til tekstkritiske retningslinjer.
kap-14.2.3.2.1: Typografibeskrivelse – <typography>
kap-14.2.3.2.1.1: Dramafiler
Hovedtekstens typografi beskrives ikke. Det henvises til beskrivelsen av grunntekstens typografi i grunntekstfilen.
<typography>
<p>Grunntekstens typografi finnes beskrevet i
typografibeskrivelsen i grunntekstfilen (C2.xml).</p>
</typography>
kap-14.2.3.2.1.2: Brev- og sakprosafiler
For brev og sakprosa beskrives ikke typografien (gjelder både grunntekster og hovedtekster) og <typography> kan derfor utelates.
kap-14.2.3.2.1.3: Diktfiler
Hovedtekstens typografi beskrives ikke. Det henvises til beskrivelsen av grunntekstens typografi i grunntekstfilene.
<typography>
<p>Grunntekstens typografi finnes beskrevet i
typografibeskrivelsen i grunntekstfilene.</p>
</typography>
kap-14.2.3.2.2: <stdVals> – standardized values
<stdVals> inneholder en standardtekst om standardiserte verdier som brukes i koding av datoer. Skal bare brukes når det faktisk er kodet med standardiserte verdier i attributtet value="" i <date>.
<stdVals>
<p>&stdVals;</p>
</stdVals>
kap-14.2.3.2.3: Referanse til tekstkritiske retningslinjer
Til slutt i <editorialDecl> opplyses det om prosjektets generelle filologiske praksis og henvises til tekstkritiske retningslinjer. Dette gjøres vha. en entitet. Strukturen ser slik ut:
<editorialDecl>
...
<stdVals>...</stdVals>
<p>&editorialDecl;</p>
</editorialDecl>
kap-14.2.3.3: <tagsDecl>
<tagUsage gi="id-who"> og <tagUsage gi="pb-ed-HU">/<tagUsage gi="pb-ed-HU-n"> beholdes som de står i grunnteksten. <tagUsage gi="tei.2"> skal (som i grunntekstene) inneholde en henvisning til TEI Guidelines og til vår kodepraksis. Lenke hentes inn via entiteten nedenfor.
<tagUsage gi="tei.2">
&tagUsage-tei2;</tagUsage>
Hvis filen inneholder navnekoding må i tillegg <tagsDecl> inneholde <tagUsage gi="id-base">. Id-basefilen vi validerer corresp-verdiene i <rs> mot hentes inn under valideringen ved hjelp av entitet i <tagUsage gi="id-base">:
<tagUsage gi="id-base">&Ibsen-keys;</tagUsage>
kap-14.2.3.4: <metDecl>
For hovedtekster med metrisk koding skal det vises til kodepraksis for vers og til Jørgen Fafners verslære. Dette gjøres vha. entiteten nedenfor.
<metDecl>
<p>&metDecl;</p>
</metDecl>
kap-14.2.3.5: <variantEncoding>
<variantEncoding> beholdes i de hovedtekstene som inneholder manuskriptkoding (mao. egenhendige arbeidsmanuskripter).
Internvariasjon som er kodet i <app> i grunnteksten blir i hovedtekstfilene kodet om til tekstkritiske noter. Apparatkodingen blir dermed fjernet, og det er derfor heller ikke nødvendig å beholde <variantEncoding> i <teiHeader> i disse hovedtekstfilene.
kap-14.2.4.1: <langUsage>
I <langUsage> defineres alle språk i filen (både i <teiHeader> og i <text>).
<langUsage>
<language id="nob"/>
<language id="Dano-Norwegian"/>
<language id="lat"/>
<language id="ger"/>
</langUsage>
kap-14.2.4.2: <handList>
i <handList> defineres alle hender i filen. Her eksempel fra Diktht.xml:
<handList> <hand hand="DSigFinkelbechsGrav-HI-1" id="DSigFinkelbechsGrav-HI-1" ink="pen-black" first="yes"><p>Sort penn. Steilskrift. Henrik Ibsen. Hovedhånd</p></hand> <hand hand="BlaDigt8191-HI-1" id="BlaDigt8191-HI-1" ink="pen-black" first="yes" rend="SaddleBrown"><p>Brunsort penn. Henrik Ibsen. Hovedhånd</p></hand> <hand hand="BlaDigt8191-JN" id="BlaDigt8191-JN" ink="pen-black" rend="DarkGreen"><p>Sort penn. Jacob Nandrup. Har skrevet forfatternavn på tittelsiden, samt sitt eget navnetrekk.</p></hand> <hand hand="BlaDigt8191-h1" id="BlaDigt8191-h1" ink="pencil" rend="Orange"><p>Blyant. Foliering.</p></hand> <hand hand="BlaDigt8191-h2" id="BlaDigt8191-h2" ink="pen-black" rend="BlueViolet"><p>Sort penn. Innholdsfortegnelse på siste side, samt nummerering av dikt. Ukjent hånd.</p></hand> <hand hand="BlaDigtINatten_SamfBl-h1" id="BlaDigtINatten_SamfBl-h1" ink="pen-black" first="yes"><p>Sort penn. Ikke egenhendig (Paul Botten-Hansen?). Hovedhånd</p></hand> <hand hand="DStemmerSkoven-h1" id="DStemmerSkoven-h1" ink="pen-blue" first="yes"><p>Blå penn. Ukjent hånd.</p></hand> <hand hand="DBlandtRuiner-HI-1" id="DBlandtRuiner-HI-1" ink="pen-black" first="yes"><p>Sort penn. Henrik Ibsen. Hovedhånd.</p></hand> <hand hand="DUngdomsdroemme-HI-1" id="DUngdomsdroemme-HI-1" ink="pen-black" first="yes"><p>Sort penn. Henrik Ibsen. Hovedhånd.</p></hand> ... </handList>
kap-14.2.5: <revisionDesc>
Gammel logg slettes. Ny påbegynnes med henvisning til grunnteksten. Innførsler i gammel logg om metrisk koding skal stå av hensyn til arbeidet med den metriske kodingen.
kap-14.3: Tekstkritisk noteapparat
Det tekstkritiske appratet i HIS kodes vha. en kombinasjon av elementet <xref type="tcNote"> og en liste med notene i en ekstern fil.
kap-14.3.1: Koding av lemma i hovedteksten
<xref type="tcNote" id="ID-VERDI" url="VERKht_noter.xml" from="ID-VERDI"> omslutter lemma i teksten og peker til noten i det eksterne dokumentet. I tillegg skal <xref> brukes til å generere linjehenvisninger (starttagg brukes) og linjespenn (start- og sluttagg brukes) i notene i bokutgaven.
<xref type="tcNote" id="noteOL2_1" url="OL2ht_noter.xml" from="noteOL2_1">husbond</xref>
Verdiene i id="" skal lages på følgende mal: noteVERK_SIFFER Samme verdi brukes i lemma og notelisten. Det er en fordel, men ikke nødvendig, at verdiene er nummerert fortløpende.
I tilfeller hvor det pga. strukturforskjeller ikke går an å bruke en enkelt <xref>-tagg, brukes det flere. Taggene kobles sammen med et <join/>-element som legges rett foran første <xref>.
<salute> <join targets="noteT12_674 noteT12_674a" targOrder="Y"/> <xref type="tcNote-part" id="noteT12_674" url="B1844-1871ht_noter.xml" from="noteT12_674"> <supplied><diacrit type="left"/>Deres hengivne</supplied></xref></salute> <signed><xref type="tcNote-part" id="noteT12_674a"><supplied>Henrik Ibsen<diacrit type="right"/></supplied></xref></signed>
Eksempel hentet fra B1844-1871ht.xml.
<sp who="ALFER"><spOpener><speaker rend="smallCaps"> <join targets="noteSa_111 noteSa_111a noteSa_111b noteSa_111c noteSa_111d noteSa_111e" targOrder="Y"/> <xref type="tcNote-part" id="noteSa_111" url="Saht_noter.xml" from="noteSa_111">chor af usynlige alfer</xref></speaker></spOpener></sp> <pb n="149"/> <sp who="ANNA"><spOpener><speaker rend="smallCaps"><xref type="tcNote-part" id="noteSa_111a">anna</xref></speaker></spOpener> <p><xref type="tcNote-part" id="noteSa_111b">Johannes! Johannes! min Barndomsven!</xref></p> <stage><xref type="tcNote-part" id="noteSa_111c">(kaster sig i hans Arme)</xref></stage></sp> <sp who="BIRK"><spOpener><speaker rend="smallCaps"><xref type="tcNote-part" id="noteSa_111d">birk</xref></speaker></spOpener> <p><xref type="tcNote-part" id="noteSa_111e">Anna! nu kjender jeg dig igjen!</xref></p></sp>
Eksempel hentet fra Saht.xml.
Verdiene i id="" i de ekstra <xref>-elementene skal lages på følgende mal: noteVERK_SIFFERBOKSTAV.
kap-14.3.2: Koding av notelisten
De tekstkritiske notene kodes i en egen XML-fil. Filnavn gis etter følgende mal: HT-BETEGN._noter.xml. F.eks. C1ht_noter.xml.
kap-14.3.2.1: <teiHeader> og dokumenttopp
<teiHeader> lages etter denne malen:
<?xml version="1.0" encoding="ISO-8859-1"?>
<?xml-stylesheet type="text/xsl" href="../../Stilark/hovedtekst/hovedtekst_note.xsl"?>
<!DOCTYPE TEI.2 PUBLIC "-//TEI P4 Ibsen-XML//DTD TEI P4 Unified for HIS//EN"
"http://www.edd.uio.no:8088/his/DTD/ibsen-xml.dtd">
<TEI.2 lang="nob">
<teiHeader>
<fileDesc>
<titleStmt>
<title>Henrik Ibsens skrifter</title>
<title id="Sv">Svanhild</title>
<title>Sv: tekstkritiske noter</title>
<funder>&funder;</funder>
<editor>&editor;</editor>
<respStmt><resp>Oppretting</resp>
<name id="HIS_HB">Hilde Bøe</name></respStmt>
</titleStmt>
<publicationStmt><p/></publicationStmt>
<sourceDesc><p>Filen er opprettet internt.</p></sourceDesc>
</fileDesc>
<encodingDesc>
<projectDesc><p/></projectDesc>
<tagsDecl><tagUsage gi="tei.2">Kodingen her er gjort
så enkel som mulig.</tagUsage></tagsDecl>
</encodingDesc>
<profileDesc><langUsage><language id="nob"/></langUsage></profileDesc>
<revisionDesc>
<change><date>11.05.2005</date><respStmt><name>HB</name>
<resp>Opprettet fil</resp></respStmt><item/></change>
</revisionDesc>
</teiHeader>
kap-14.3.2.2: Øvrig filstruktur
Notene kodes innenfor et <div type="tcNote">-element. En tom <p> er satt inn til slutt av valideringshensyn.
<text> <body> <div type="tcNote"> ... <p/> </div> </body> </text> </TEI.2>
kap-14.3.2.3: Koding av notene
Notene utformes slik:
<note resp="editor" id="noteOL2_1">
<xref type="tcNote" url="OL2ht.xml" from="noteOL2_1">husbond</xref>
<hi rend="italic">HIS,</hi> hushond <hi rend="italic">FU, 2. utg.</hi>
</note>
<note resp="editor" id="noteOL2_23">
<xref type="tcNote" url="OL2ht.xml" from="noteOL2_23">jeg</xref>
eg <hi rend="italic">ekspl. 2 og 3</hi>
</note>
<note resp="editor" id="noteOL2_25">
<xref type="tcNote" url="OL2ht.xml" from="noteOL2_25">stamper med</xref>
<hi rend="italic">HIS,</hi> stammed
<hi rend="italic">FU, 2. utg., haplografi ved linjeskift</hi>
</note>
Hvis deler av kursivert innhold skal settes i normal, f.eks. sitater fra Ibsen-tekst, avsluttes <hi rend="italic"> foran normal-teksten og påbegynnes igjen etterpå. Verkstitler som forekommer i notene skal utheves med normal for å skilles fra kursivteksten og settes dermed utenfor <hi rend="italic">.
HIS-interne tekstkildebetegnelser kan godt brukes i arbeidet med notene, men disse skal oversettes til HIS' offisielle sigla før notelisten sendes setteriet.
&tu20;-entiteten settes inn mellom punktum og «utg.»: 1.&tu20;utg.
Notene skal som utgangspunkt nummereres fortløpende (note[VERK]_1, note[VERK]_2, note[VERK]_3 osv.), innskutte noter (noter som kommer til sent i kodingen) nummereres med a, b, c (note[VERK]_253, note[VERK]_253a, note[VERK]_254).
kap-14.3.3: Utforming av noter
Hovedregel er at vi skal ha minst mulig tekst i lemma, men nok tekst til at noten blir entydig og klar.
Store lemma forkortes direkte i noten:
<note resp="editor" id="noteSa_44">
<xref type="tcNote" url="Saht.xml" from="noteSa_44">
er <hi rend="italic">(…)</hi> skal han</xref>
<hi rend="italic">egenhendig på innlimt lapp, endret fra</hi> er et Umiddelbarhedens Bad,
so<diacrit type="left"/>m<diacrit type="right"/> Umiddelbarhede<diacrit type="left"/>ns<diacrit type="right"/>
Bad! det <diacrit type="left"/>var<diacrit type="right"/> et godt Udtryk, – det skal han</note>
kap-14.3.3.1: Rollenavn som lemma
Vi bruker ikke kapitéler i notene. Hvis rollenavn (eller andre ord) som i hovedteksten står i minuskler for å kunne generere kapitéler er lemma, føres «normalformen» som lemma i notelisten:
<note resp="editor" id="noteUF_1"> <xref type="tcNote" url="UFht.xml" from="noteUF_1">Gjæster,</xref> <hi rend="italic">HIS,</hi> Gjæster. <hi rend="italic">1.&tu20;utg., KBK Collin 262, 4°, 2.&tu20;utg.,</hi> gæster, <hi rend="italic">3.–6.&tu20;utg., FU,</hi> gæster. <hi rend="italic">NBO Ms.8° 1924</hi> </note>
kap-14.3.4: Manuskriptendringer
Manuskriptendringer i sufflørbøker, brev og diktmanuskripter gjøres om til noter.
ut endret fra inn
ut tilføyd
kun!] endret fra kun, (usikker rekkefølge)
- <gap/> – større uleselige strykninger, dvs. når det strøkne antas å være et helt/store deler av et ord
- <space/> – rom i teksten i forbindelse med endringer noteres i noten sammen med andre forhold rundt endringen, <space/>-taggen fjernes fra hovedteksten
- hand="" – egenhendige rettelser i ikke-egenhendig tekst, eksempelvis sufflørbøker
kap-14.3.4.2: Håndskriftsfenomener som ikke noteres i noteapparatet
kap-14.3.4.2.1: Uklar tekst – <unclear>
Uklare lesemåter noteres ikke i noteapparatet, men markeres med vinkelparenteser (<diacrit type="left"/> og <diacrit type="right"/>) direkte i teksten.
bidraget meget til at <unclear reason="smudge"><diacrit type="left"/>afskjedige<diacrit type="right"/></unclear> et Savn
kap-14.3.5: Manglende tekst
Vi skiller mellom tekst som mangler fordi den er uteglemt og tekst som er tapt på grunn av manuskriptskade.
kap-14.3.5.1: Uteglemt tekst
Når f.eks. overskrift eller strofenummerering er uteglemt emenderes teksten inn.
kap-14.3.5.2: Utfylling av tapt tekst – <supplied>
Når tekst mangler fordi manuskriptet er skadet fyller vi ut tekst dersom dette er mulig å gjøre med stor grad av sannsynlighet. Supplert tekst kodes i <supplied> og markeres med vinkelparenteser i den løpende teksten. Vinkelparentesene genereres av de tomme elementene <diacrit type="left"/> og <diacrit type="right"/>.
<supplied reason="damage"><diacrit type="left"/>vi<diacrit type="right"/></supplied>lde
Vi bruker kun ett sett diakritiske tegn i den løpende teksten: <>. Disse tegnene omslutter uklar, uleselig og utfylt tekst, kodet med henholdsvis <unclear>, <gap/> og <supplied>. De tre kodene skal aldri ligge innenfor hverandre i filen. For uleselig tekst genereres tegnene, med tre prikker mellom (<...>), fra koden <gap/>. For uklar og utfylt tekst hardkoder vi de diakritiske tegnene med de tomme kodene <diacrit type="left"/> og <dicrit type="right"/>. Dette gjør vi fordi uklar og utfylt tekst ofte følger etter hverandre, og vi bare ønsker diakritiske tegn rundt hele sekvensen med uklar/utfylt tekst. Grunnen til at vi har kodet uklar og utfylt tekst på ulik måte, selv om vi ikke ønsker å skille mellom dem i visningen i bokutgaven, er at vi ønsker å ta vare på informasjonen i de elektroniske filene og ha muligheten for å vise kategoriene med ulike tegn i en ev. detaljert visning i e-utgaven.
KODES SLIK: <unclear><diacrit type="left"/>Hvad</unclear> <supplied>va</supplied><unclear>r det<diacrit type="right"/></unclear> VISES SLIK: <Hvad var det>
kap-14.3.6: Noter i grunnteksten
kap-14.3.6.1: Originale noter
Forfatternoter (<note resp="author">) beholdes der de står.
Noter som inngår i fiksjonen (<note resp="narrator">) (eks. notene i No):
- noter uten notetegn som er plassert ved teksten de kommenterer beholdes der de står. Kodes <note resp="author" place="inline">
- noter som er plassert nederst på siden og har notetegn, kodes om slik at de plasseres inn i teksten ved notetegnet (notetegnene fjernes). Kodes <note resp="author"> (uten place=""). De kan deretter prosesseres i ombrekkingen slik at de plasseres nederst på den aktuelle siden.
Eks. på flyttet note nedenfor:
<sp>... <l met="bi++ v-vvv-vvv-vv-v" rhyme="N">At holde mig en Hestelængde bagud for Tiden.<note resp="narrator">Man vil bemærke at de Vers, der fremsiges afsides, ere anderledes byggede, end de, der &koNo_49a;maa høres af Alle og Enhver; dette er ingenlunde nogen Skjødesløshed, men med Forsæt iagttaget, da vel underrettede Personer ville vide, at vore politiske Skuespillere endog til Dagligbrug betjene sig af et særegent Versemaal, naar de tale afsides.</note></l></sp> <stage>De gaae.</stage>
NB: Dette endres ikke i grunnteksten!
Redaksjonelle noter (eks. avisredaksjonens note i K2, kodet <note resp="publisher"> i grunnteksten) siteres i en tekstkritisk note i hovedtekstens notefil:
<div type="tcNote"> <note resp="editor" id="noteK2_1"><xref type="tcNote" url="K2ht.xml" from="noteK2_1">Ibsen</xref> <hi rend="italic">1. utg. har følgende note:</hi> Forfatteren har velvilligen overladt Redactionen denne vakkre, paa det norske Theaters Stiftelsesdag iaar med udeelt Bifald opførte Digtning til Optagelse i Bladet, af hvis Læsere den sikkert vil modtages med megen Interesse.</note> ... </div>
kap-14.3.6.2: Arbeidsnoter
Arbeidsnoter som skal med til den elektroniske utgaven gjøres om til <note resp="editor">. Øvrige arbeidsnoter fjernes.
kap-14.4: Typografisk koding (bokproduksjon)
kap-14.4.1: Grunntekstkoding som fjernes
kap-14.4.1.1: Typografikoding
Grunntekstens typografi skal ikke videreføres i vår utgave og ren typografisk koding kan dermed fjernes fra hovedtekstene. Dette gjelder elementene/attributtene:
- <foreign>/<foreign rend="quote">
- <hi> (se unntak nedenfor!)
- rend=""
- <stageRole>
Følgende typografibaserte koding skal likevel beholdes:
- <hi rend="raised">
For brevhovedtekster må <hi rend="underlined"> endres til <emph> dersom uthevingen skal tas vare på (som kursiv) i bokutgaven, f.eks. hvis en adresse er understreket for å gjøre mottakeren oppmerksom på ny adresse (18791101FH).
kap-14.4.1.2: Koding som ellers skal undertrykkes
Koding som ellers skal undertrykkes, fjernes fra hovedteksten. Dette gjelder:
- sammenlenking av fragmentert koding (f.eks. replikker)
- noter (bortsett fra metriske noter)
kap-14.4.2: Linjeskift
kap-14.4.2.1: Fjerning av linjeskift
Grunntekstens originale linjeskift (<lb/>) fjernes fra hovedtekstene. Linjeskiftene i vår utgaves tekst genereres på bakgrunn av koding av strukturelementer (<p>, <l>, <head> osv.), og løpende tekst brekkes om på nytt under setting.
kap-14.4.4: Transkriberte tittelsider
Generelt: Alle tittelblader inngår i hovedteksten, inkl. gjentatte tittelblader i føljetonger.
Tittelsider som kommer etter hverandre i grunnteksten skal settes på samme side (smuss- + hovedtittel, hoved- + mellomtittel). Av hensyn til settingen må derfor type-attributtene endres:
- smusstittelsider som har verdien type="flyleaf", skal ha "main_flyleaf"
- deltittelsider som har verdien type="part", skal ha "main_part"
- kolofonsider som har verdien type="colophon", skal ha "main_colophon". For småtrykk av dikt gjengis ikke egne kolofonsider; kolofonopplysningene gjengis i stedet i tekstredegjørelsene for de enkelte diktene
Eksempel på en transkribert tittelside (forenklet koding!):
<front>...
<titlePage type="main">
<docTitle>
<titlePart type="main">catilina</titlePart>
<titlePart type="sub">drama i tre acter</titlePart>
</docTitle>
<byline>af
<docAuthor>brynjolf bjarme</docAuthor>
</byline>
<docImprint>
<pubPlace>christiania</pubPlace>
<publisher>i kommission hos p. f. steensballe</publisher>
<printer>f. steens bogtrykkeri</printer>
<date>1850</date>
</docImprint>
</titlePage>
...</front>
kap-14.4.4.1: Tittelsider til føljetonger
Første tittelside til føljetonger skal stå på egen side i bokutgaven, mens de følgende føljetongtittelsidene skal starte på egen side, med tekstfortsettelsen følgende på samme side. De må derfor skilles fra hverandre i kodinga. Dette gjøres med fortløpende nummerering i n=""-attributter (forenklet koding!):
<titlePage type="serial" n="1"> <docTitle> <titlePart type="main">norma</titlePart> <titlePart type="sub">eller en politikers kjærlighed</titlePart> <titlePart type="sub">musik-tragedie i tre akter</titlePart> </docTitle> </titlePage> <titlePage type="serial" n="2"> <docTitle> <titlePart type="main">norma</titlePart> <titlePart type="sub">eller en politikers kjærlighed</titlePart> <titlePart type="sub">musik-tragedie i tre akter</titlePart> </docTitle> <docImprint> ... </docImprint> </titlePage>
kap-14.4.5: Overskrifter
Når bokstavtypene i grunnteksten ikke er de samme som vi skal bruke i typografien til HIS' hovedtekst, endrer vi disse. Når tekst skal gjengis med majuskler eller kapiteler, legges det til rend-attributt, jf. nedenfor:
- Aktoverskrifter og noen andre tittelelementer, f.eks. prologen til Sancthansnatten, skal ha majuskler og kodes <head rend="majuscule">
- Overskrifter til etterord skal ha kapiteler og kodes <head rend="smallCaps">
- Overskrifter til forord, rollelister skal ha majuskler og minuskler og kodes uten rend=""-attributt
- Overskrifter til innholdsfortegnelser skal ha kapiteler og kodes <head rend="smallCaps">
- Overskrifter til scener skal ha majuskler og minuskler, men annen skytning enn overskrifter til forord og rollelister, og kodes <head rend="12,5_scene">
Her er kodeeksempler for de ulike overskriftstypene:
Aktoverskrift <head rend="majuscule">ANDEN AKT</head> Overskrift til etterord <head rend="smallCaps">anmærkninger</head> Overskrift til forord <head>Forord til anden udgave</head> Overskrift til innholdsfortegnelse <head rend="smallCaps">indhold</head> Overskrift til rolleliste <head>Personerne</head> Prologoverskrift <head rend="majuscule">PROLOG</head> Sceneoverskrift <head rend="12,5_scene">Første scene</head> Overskrift (øverste nivå) i sakprosatekst <head rend="11,5_majuscule">HATTEMAGERFEIDEN PAA RINGERIKE</head> Overskrift (nummerering av kapitler) i sakprosatekst <head rend="11,5_smallCaps">første kapitel</head> Underoverskrift i sakprosatekst <head rend="12,5_italic">Om Redaktionens Punschegilde og Krigens Udbrud</head>
kap-14.4.6: Rollenavn og replikkinnehavere
Rollenavn i <role>-tagger i rollelista (<role> skal kodes inn i rollelister som mangler elementet) og replikkinnehavere i <speaker>-tagger skal gjengis som kapiteler (grunntekstens bokstavtyper endres til minuskler) og kodes med rend="smallCaps"="":
<sp who="NORMA"><spOpener>
<speaker rend="smallCaps">norma</speaker>
</spOpener>
...</sp>
...
<castItem id="NORMA">
<role rend="smallCaps">norma</role></castItem>
...
...
<castItem id="HROLLOUG">
<role rend="smallCaps">hrolloug</role></castItem>
...
Behandling av spesielle fenomener:
- «og» mellom <speaker>-tagger skal ikke gjengis i kapiteler og «og» skal mao. være kodet direkte i <spOpener>. Tilfeller hvor «og» er del av <speaker> må derfor kodes om. Dette gjelder imidlertid ikke tilfeller hvor hele frasen er å regne som en enhet, jf. f.eks. «Kor af Falk og Studenterne» (Kjærlighedens Komedie)
kap-14.4.7: Underskrift og datering av forord/etterord
Datolinje skal gjengis i vanlige majuskler og minuskler (i kursiv), mens underskrift skal stå i majuskler og kapiteler.
<closer>
<dateline>
<rs type="place" corresp="plDre">Dresden</rs> i <date value="1875-02-xx">Februar 1875</date>
</dateline>
<signed rend="capSmallcap">Henrik Ibsen</signed>
</closer>
kap-14.4.8: Innholdsfortegnelser
Teksten i selve innholdsfortegnelsen skal settes som kapiteler og teksten gjøres derfor om til minuskler i filen.
<div type="contents"> <list> <head rend="smallCaps"><pb n="5"/><pb ed="hu" n="25"/>indhold</head> <item><list> <item>I</item> <item><anchor type="lemma" id="koKG_5"/>cæsars <anchor type="lemma" id="koKG_6"/>frafald</item> <item>skuespil i fem <anchor type="lemma" id="koKG_7"/>handlinger</item> </list></item> <item><list> <item>II</item> <item>kejser julian</item> <item>skuespil i fem handlinger</item> </list></item> </list> </div>
kap-14.4.9: Kolumnetitler
Venstre kolumnetittelen plasseres så nært første side som skal ha kolumnetittel som mulig, det vil vanligvis si ved akt-/forordstart:
<fw type="header" place="leftPage">Catilina 1850</fw> <fw type="header" place="leftPage">Sancthansnatten</fw> <fw type="header" place="leftPage">Olaf Liljekrans, NBO Ms.8° 1945 [1877/78]</fw> <fw type="header" place="leftPage">Brev 1844-1871</fw> <fw type="header" place="leftPage">Sakprosa 1841-98</fw>
Høyre kolumnetittelen plasseres så nært første side som skal ha kolumnetittel som mulig, dvs. rett foran akt-/prologoverskrift, ny brevårgang osv.:
<fw type="header" place="rightPage">Første akt</fw> <fw type="header" place="rightPage">Annen handling</fw> <fw type="header" place="rightPage">Brev 1844</fw> <fw type="header" place="rightPage">Appendiks: replikkutkast</fw> <fw type="header" place="rightPage">Appendiks: forord til annen utgave</fw> <fw type="header" place="rightPage">Appendiks: korsanger til Kongs‐Emnerne 1871</fw>
Slik er taggene plassert:
C1ht: <div type="act" n="1"> <fw type="header" place="leftPage">Catilina 1850</fw> <fw type="header" place="rightPage">Første akt</fw> C2ht: <div type="preface"> <fw type="header" place="leftPage">Catilina 1875</fw> <fw type="header" place="rightPage">Forord</fw> . . . <div type="act" n="1"> <fw type="header" place="rightPage">Første akt</fw>
kap-14.4.10: Side-/spaltereferanser i margene
Hovedtekstene skal ha margreferanser til grunntekstens og HUs paginering. Referansene hentes fra <pb n=""/>, <cb n=""/> og <pb ed="hu" n=""/>. Merk at <pb/> og <cb/> i hovedtekstene ikke lenger representerer side- og spalteskift i teksten (slik de gjør i grunntekstene og øvrige tekstkilder i HIS), men er referanser til grunntekst eller HU.
Sidetalls-/kolonnenummereringen overføres til n-attributtet i <pb/>-elementet. <fw>-kodingen av de faktiske sidetallene/kolonnenumrene fjernes.
Ingen annen foliering skal gjengis og all <fw>-koding skal derfor fjernes fra hovedtekstene.
kap-14.4.11: Tegn og entiteter
kap-14.4.11.1: Generelt
- Harde bindestreker kodes om til ‐
- Apostrofer kodes om til &rapo;
- Skråstreker (solidus, slash) kodes om til /
- Myke/typografiske bindestreker fjernes eller endres til ‐
kap-14.4.11.2: Mellomromsentiteten &tu20;
For å unngå at forkortelser og enheter som prosenttall brekkes ved linjeskift koder vi mellomrommet med en egendefinert entitet, &tu20; (typographical unit 20). Den brukes mellom bokstaver og tegnsetting i forkortelser, mellom tall/tegnsetting og ordet «utg.» (i tekstkritiske noter), mellom tall og prosenttegn i prosenttall.
kap-14.4.11.3: Mellomromsentiteten
For å unngå feilaktig linjebrekking før tankestreker som hører til forutgående tekst koder vi mellomrommet før tankestreker som etterfølges av enten tegnsetting (punktum, komma, spørsmålstegn, utropstegn, semikolon, kolon), ikke-frittstående sceneanvisning eller slutt-<p> med .
kap-14.4.12: Diktoppsett
kap-14.4.12.1: Frittstående dikt og sanger i drama
Frittstående dikt og sanger i versreplikk skal rykkes ytterligere inn i forhold til øvrig replikktekst. Slike frittstående dikt og sanger kodes med en ytre <lg rend="poem">.
Hvis en slik sekvens innleder eller utgjør hele replikken skal også rolleinnehaver markeres og <lg rend="poem"> må da legges rundt <sp>. Dersom man får problem med kryssende strukturgrenser splittes replikken opp: hver del får en id-verdi og delene lenkes sammen med et <join/>-element:
<join targets="BLANKA_1 BLANKA_2" targOrder="Y"/> <lg rend="poem"> <sp who="BLANKA" id="BLANKA_1"><spOpener><speaker rend="smallCaps">blanka</speaker> <stage>alene</stage></spOpener> <lg type="strofisk strofegruppe firfotstroké" an="no" met="bi 7|8" rhyme="r|R"> <lg type="strofe" rhyme="(A b)2 C D D C"><l first="yes" rhyme="A">Han er borte! Lydløst Stille</l> <l rhyme="b">Raader paa den øde Kyst.</l> ... <l rhyme="D">Ak! snart seiler han som Maagen</l> <l rhyme="C">Langt herfra for Nattens Vinde.</l></lg> <lg type="strofe" part="Y" rhyme="A B B A"><l rhyme="A">Og hvad har jeg saa tilbage?</l> <l rhyme="B">Kun en Blomst for mine Drømme,</l> <l rhyme="B">Ensomheden for at svømme,</l> <l rhyme="A">Som Petrellen om hans Drage</l></lg></lg> </sp></lg> <sp who="BLANKA" id="BLANKA_2"> <stage>(Vikingernes Krigsluur høres fra Venstre)</stage> <lg type="stikisk femfotsjambe blankvers" an="single" met="bi 10|11" rhyme="x|X|r|R"><l rhyme="X">Ha! hvad var det! Et Horn, det kom fra Skoven.</l></lg></sp>
Eksempel fra K2ht.xml
Hvis sekvensen bare er en del av replikken (og altså ikke innleder den), skal <lg rend="poem"> bare legges rundt verslinjene som skal ha ytterligere innrykk.
kap-14.4.12.2: Innrykkede verslinjer
Innrykkede verslinjer i ustrofiske versreplikker, der innrykket fungerer som innholdsbasert avsnittsmarkering, kodes med <l rend="indent1">.
Større innrykk i dikt eller versdramaer kodes med <l rend="indent2"> (mellomstort innrykk) og <l rend="indent3"> (størst innrykk).
kap-14.4.12.3: Fire- og femdelte verslinjer
I versdramaer kan det forekomme fire - og femdelte verslinjer. Disse kodes med henholdsvis <l part="I|M|F">. For at de midtre delene skal kunne ha innrykksforskjell må det legges til n-attributter:
<lb/><sp><spOpener><speaker>Margit</speaker> <lb/><stage>(i heftig Bevægelse)</stage>.</spOpener> <lb/><l part="I">Om jeg vil?</l></sp> <lb/><sp><spOpener><speaker>Gudmund</speaker>.</spOpener> <lb/><l n="1" part="M">Ja, jeg mener ‐</l></sp> <lb/><sp><spOpener><speaker>Margit</speaker>.</spOpener> <lb/><l n="2" part="M">Sig frem.</l></sp> <lb/><sp><spOpener><speaker>Gudmund</speaker>.</spOpener> <lb/><l part="F">Nu vel.</l> <lb/><l>Du kunde gjøre mig saa rig og saa fro ‐</l></sp>
Eksempel fra G1.
kap-14.4.12.4: Optisk justering
All tekst som skal justeres optisk kodes i <lg rend="opAlign">.
kap-14.4.13: Prosaavsnitt
Prosaavsnitt som ikke skal ha innrykk, dvs. første avsnitt etter replikkåpner og første avsnitt etter sceneanvisning i replikk, kodes med <p rend="noIndent">.
For å skille setting fra andre prosaavsnitt legges det til rend-attributt i <p>: <p rend="set">.
kap-14.4.14: Plassering av sceneanvisninger ved ombrekking
For sceneanvisninger som klart tilhører foregående eller etterfølgende tekst spesifiseres tilhørigheten med <stage rend="previous"> og <stage rend="next">:
<stage rend="previous">Han gaaer.</stage> <stage rend="next">Efter en Pause høres dæmpet i Baggrunden følgende Chor.</stage>
Eksempel fra G1 (forenklet koding).
Det er typisk sceneanvisninger mellom replikker som vil få slik koding. Det kan imidlertid også være nødvendig innenfor replikker:
<sp who="FRUKIRSTEN"><spOpener><speaker>Fru Kirsten</speaker></spOpener> <p>Jeg veed det, Alfhild! jeg veed hvad han har sagt. <stage rend="next">(afsides)</stage> Han har nævnt sit Bryllup for hende, kan jeg skjønne. <stage rend="next">(høit)</stage> Og alt ikvæld skal det gaa for sig.</p></sp>
Eksempel fra OL1 (forenklet koding).
Sceneanvisninger som får rend="previous", skal flyttes inn i foregående <p>, mens sceneanvisninger med rend="next" kan bli stående der de står (vanligvis utenfor strukturelementer som <l>, <p> og <sp>). Sceneanvisninger som ikke hører klart til foregående eller etterfølgende tekst skal stå uten rend="". Sceneanvisninger i <spOpener> eller rett før/etter aktoverskrift trenger ikke rend="", siden disse vil bli satt på riktig sted i forhold til omliggende elementer. Kodinga baseres på skjønn, etter tekstens innhold.
kap-14.4.15: Sceneanvisninger først i akt
Hvis det er to sceneanvisninger først i akt skal det være ekstra luft mellom de to sceneanvisningene. Dette kodes med rend="2lines"- attributt i sceneanvsning nr. 2:
<head rend="majuscule">FØRSTE AKT</head>
<stage>Dagligstuen på Rosmersholm; rummelig, gammeldags og hyggelig. ...
Ligeså forstuedøren og den ydre husdør. Udenfor ss store gamle trær i en all, som fører til gården. Sommeraften. Solen er nede.</stage>
<stage rend="2lines">Rebekka West sidder i en lænestol ved vinduet og hækler på et stort hvidt uldsjal, som næsten er færdigt.
Af og til kikker hun spejdende ud mellem blomsterne. Lidt efter kommer madam Helseth ind fra højre.</stage>
Eksempel fra Ro (forenklet koding).
kap-14.4.16: Typologisering av <text>
For bl.a. å kunne sette noteapparatet forskjellig avhengig av teksttype legger vi inn typologisering i <text>-elementet:
- Versdrama: <text rend="verseDrama">
- Prosadrama: <text rend="proseDrama">
- Visualisert tekst: <text rend="visualized">
- Brev: <text rend="letter">
- Dikt: <text rend="poem">
- (Kommentar: <text rend="commentary">)
kap-14.5: Sjangerspesifikk koding
Følgende hovedtekster blir publisert basert på Ibsens egenhendige, ufullførte manuskripter: RJ, Fj, OL3, HH2, BE, Sv, Hv og ni av sakprosatekstene.
kap-14.5.1.1: Generelt
- Standardisering av tegnsetting utgår
- Tekstkritiske supplerende noter legges til som vanlig
- Ikke-egenhendig foliering fjernes
- rend="visualized"="" legges inn i <text>
kap-14.5.1.2: Typografisk tilleggskoding
De egenhendige arbeidsmanuskriptene som skal publiseres som såkalt visualiserte hovedtekster, skal presenteres så diplomatarisk som mulig. Det betyr bla. at original typografi skal gjengis så langt som mulig.
For å få til dette legger vi inn <hi rend=""> overalt hvor det er nødvendig.
<lb/><sp who="IVAR"><spOpener><speaker><hi rend="underlined">Ivar</hi></speaker>.</spOpener> <lb/><l part="I" met="-v-v">Naa, hvad er det?</l></sp> <lb/><sp who="GJÆSTER"><spOpener><speaker><hi rend="underlined">Gjæsterne</hi></speaker>.</spOpener> <lb/><l part="F" met="-vv-" rhyme="i">Sig du det frit!</l></sp><pb ed="hu"/>
Vi aksepterer at understrekingen ikke blir helt diplomatarisk i forbindelse med overskrifter, rollenavn etc. forøvrig siden et krav om fullstendig diplomatarisk gjengivelse her ville gi mye arbeid med <hi>-kodingen. Spesialtilfeller må imidlertid påregnes og skjønn er tillatt og påkrevd i dette kodearbeidet.
Generelt legges <hi rend=""> til der teksten krever formatering utover HISb-designet og/eller der HISb-designet skal overkjøres. Nærmere detaljer for de forskjellige elementene som blir berørt, følger nedenfor.
kap-14.5.1.2.1: <role>
I <role> legges det til rend="underlined" når rollenavnet er understreket (HISb-designet skal overkjøres).
kap-14.5.1.2.2: <head>
<head> får lagt til <hi rend=""> når overskriften har en eller annen form for understreking. NB: Krøllete understreking er behandlet som vanlig understreking. Overskrifter som ikke er understreket på noe vis, gjøres det ikke noe med.
kap-14.5.1.2.3: <emph>
<emph> får alltid lagt til rend="underlined" (HISb-designet skal overkjøres).
kap-14.5.1.2.4: <stageRole>
<stageRole> kan stå umarkert, skal alltid ha understreking (fjernes alltid i alle øvrige hovedtekster).
kap-14.5.1.2.5: <stage>
I <stage> legges <hi rend=""> til når sceneanvisningene er understreket.
kap-14.5.1.2.6: <spOpener> og <speaker>
<hi rend=""> legges til i <speaker>, inneholder formateringsinfo uansett om det er standardformateringen eller avviket (avvik i form av annerledes understreking enn gjennomgående markering). Det er ikke nødvendig å legge til <hi rend=""> når rolleinnehaveren ikke er understreket/ er umarkert.
Når flere rolleinnehavere er kodet i hver sin <speaker> og hele sekvensen inkl. 'og' mellom rollenavnene skal ha sammenhengende understreking, legges <hi rend=""> til rundt hele den understrekede sekvensen (inkl. evt. <speaker>-tagger).
Når 'og' mellom rollenavnene har annen understreking enn rollenavnene (og understrekingen dermed heller ikke er sammenhengende) er <hi rend=""> lagt rundt 'og' for seg.
kap-14.5.1.2.7: <figure type="bar/num"/>
Skillestreker og strofeskiller («skigard») skal gjengis diplomatarisk. Strek o.l. gjengis som strek, strofeskille som skigard. Kodingen av streker kan beholdes som den er; <figure type="bar"/>. Skigarder kodes slik; <figure type="num"/>.
kap-14.5.1.2.8: Innrykkskoding
Innrykksgradene (se attributtverdilisten for attributtverdier) kan gjerne normaliseres slik at ikke alle små detaljer gjengis. Målet er å gjenskape et system, hvis et slikt kan avdekkes.
Innrykkskoding (rend="") av vers beholdes, men kontrolleres mot faksimiler og oppdateres evt.
Det kodes også innrykk og justering i prosa når dette er nødvendig. Her legges rend="" enten i eksisterende <p> eller man legger til <seg rend=""> inne i <p>. I HH2ht er f.eks. høyrejusterte «linjerester» kodet med <seg rend="alignRight"> for å gjenskape det originale uttrykket.
kap-14.5.1.2.9: Farging av tekst
I to av de egenhendige manuskriptene, Fjht og BEht, kan man avgrense skriveomganger. Dette gjengis med farget tekst. I tillegg til den opprinnelige <handShift>-kodingen, legges det inn hand-attributter på det ytterst mulige strukturnivået (<div>) i forhold til den teksten som skal farges.
Også en del enkeltendringer i BEht skal gjengis i annen farge enn sort, og disse kodes også med hand-attributt.
Evt. elementer med tekst som fortsatt skal gjengis i svart, og som kommer innenfor farget tekst, har i Fjht fått et eget attributt, rend="nocolour"="", mens det for BEht bare er opplyst til setteriet at kolumnetitler alltid skal settes med sort skrift.
kap-14.5.1.3: Omkoding
I et fåtall tilfeller har Ibsen strøket en del av et tegn for å tydeliggjøre eller forbedre det egentlige tegnet. Strykning av del av tegn lar seg ikke visualisere på en god måte. Vi har derfor valgt å forstå strykning av del av tegn som tydeliggjøring, og koder følgelig med <clarification place="inline">. Her er et eksempel:
han l<clarification place="inline">o</clarification> med
kap-14.5.1.4: Tilleggskoding
Kodefilologene er enige om at det i noen tilfeller må være lov å juksekode for å unngå vanskeligheter i visninga av teksten, jf. under om et tilfelle i OL3ht. Det noteres i loggen til fila at dette er gjort.
kap-14.5.1.4.1: OL3ht – kryssende strukturer
En tilføyelse krysser en strukturgrense, det gjelder tilføyd rollenavn og punktum, jf. rettelsen av "Ingebo" til "Gertrud." (2r i OL3). For å unngå at tilføyelsestegnene repeteres (som jo blir konsekvensen av å legge inn to add-elementer her) er punktum flyttet inn i add; jf. gammel koding:
<lb/><sp who="GERTRUD"><spOpener><speaker><del rend="overstrike">Ingebo</del><add place="inline">Gertrud</add></speaker>. <lb/><stage>(ser nedover.)</stage></spOpener>
Ny koding:
<lb/><sp who="GERTRUD"><spOpener><speaker><del rend="overstrike">Ingebo</del><add place="inline">Gertrud.</add></speaker> <lb/><stage>(ser nedover.)</stage></spOpener>
kap-14.5.1.4.2: OL3ht – flyttemarkering
I OL3 fins en strek som filologene forstår som en flyttemarkering. Denne streken skal gjengis slik den er (teksten skal mao. ikke flyttes). Start- og sluttpunkt for streken er markert med <ptr/> og <anchor/>:
<lb/><l rend="centre" met="v-vv-v" rhyme="X">
Ung Olaf, ung Olaf,<ptr target="OL3ht-move-1"/>
<note type="production">Det skal genereres en bue utenom teksten fra ptr til anchor,
buen markerer at "hvor sidder du tagen" er ment flyttet ned under "Vi vanker i v.".</note>
</l><l met="v-vv-v" rhyme="B">hvor sidder du tagen?</l>
<lb/><l rend="centre" met="v-vv-" rhyme="a">Å vågn dog og se.</l>
<lb/><l rend="centre" met="v-vv-" rhyme="a">Vi vanker i v.</l>
<anchor id="OL3ht-move-1"/>
<lb/><l rend="centre" met="v-vv-vv-vv-" rhyme="a">Hvor sidder du tagen de nætterne tre</l>
kap-14.5.1.4.3: Fjht – <stage> med klammer
Innklammede sceneanvisninger er kodet slik:
<stage rend="braced">
<stage rend="bracedLeft">
<hi rend="fineUnderline">paa engang.</hi>
</stage>
.
.
.
</stage>
kap-14.5.1.4.4: Fjht – «Dekorationsforandring»
Det strøkne «Dekorationsforandring» kodes som aktoverskrift i hovedtekstfilen som sendes setteriet:
</div> </div> <div type="act" n="0"> <lb/><head>(<del rend="overstrike">Dekorationsforandring</del>.)</head> </div>
Når bind to er klart, endres kodingen tilbake til sceneanvisningskoding, slik at hovedtekstfilen i e-utgaven blir riktig:
</div> <lb/><figure type="bar"/> <div type="scene" n="2"> <lb/><stage rend="deviation">(<del hand="HI-h2" rend="overstrike">Dekorationsforandring</del>.)</stage> </div> </div>
kap-14.5.2: Brev
kap-14.5.2.1: Rettelser i brevmaterialet
Brev skiller seg fra dramatekstene i det at det svært sjelden finnes mer enn et tekstkilde til hvert brev (kun for noen få brev har vi utkast). De aller fleste av våre rettelser vil derfor være konjekturer (rettelser uten støtte i andre tekstkilder).
kap-14.5.2.2: Noter om manuskriptskader
I en del brev er manuskriptskadene så omfattende at det er lite hensiktsmessig å ha en egen «ms. skadet»-note ved hver supplering. I slike brev legges en generell «ms. skadet»-note knyttet til første ord på den aktuelle siden. Omfanget av skaden beskrives i noten.
Vises slik i noteapparatet:
havde] på s. [9] og [10] har ms. skader
kap-14.5.2.3: «Tilføyelser» i margen
I enkelte brev har Ibsen skrevet avslutningshilsener på tvers av vanlig skriveretning i margene. Dette er kodet som vanlige offline-tilføyelser i grunntekstene. Men siden grunnen til at teksten er plassert der den er er at Ibsen har sluppet opp for plass på brevarket regner vi i hovedtekstene ikke dette som (senere) tilføyelser. <add>-kodingen fjernes og teksten plasseres der den hører hjemme i tekstkronologien. Slike «tilføyelser» tas dermed ikke med i noteapparatet, men omtales kun i manuskriptbeskrivelsene.
kap-14.5.2.4: Typografisk utheving
Det er bare n type typografisk utheving innenfor brev i bokutgaven, nemlig kursiv. Uthevinger kodes med <emph>. Dersom vi vil ta vare på uthevinger som er kodet annerledes i grunnteksten (oftest med <hi rend="underlined>) må koden endres til <emph>. Et eksempel på dette kan være understreket adresse i brevtekst (for å gjøre mottakeren oppmerksom på ny adresse) (18791101FH).
kap-14.5.2.5: Koding av personer, steder, verk og institusjoner
I brevhovedtekster skal personer, steder, verk og institusjoner kodes med <rs>, se detaljkoding.
kap-14.5.2.6: Kodeendringer: <dateline rend="">/<salute rend="">
I <dateline> og <salute> legges det til rend-attributt med attributtverdien "opener" eller "closer" avhengig av om dateringslinjen og hilsenen står i begynnelsen eller på slutten av brevteksten. Eks.:
...
<p>I henhold hertil ansøger jeg om at det nådigst må blive mig tilladt at bære bemeldte dekoration som kommandør af Medjidih‐ordenen.</p>
<dateline rend="closer">Dresden den <date>30<hi rend="raised">te</hi> August 1871</date>.</dateline>
<salute rend="closer">underdanigst</salute>
<signed>Henrik Ibsen.</signed>
...
Kodeeks. fra B1871-1879ht.xml, brev B18710830KongK4.
kap-14.5.3: Dikt
kap-14.5.3.1: Generelt
Hovedtekstfilen for dikt inneholder både trykk og manuskripter. Manuskriptene behandles på samme måte som brev og sufflørbøker, dvs. at endringer opplyses om i tekstkritiske noter, de gjengis altså ikke i løpende tekst som for de visualiserte, ufullførte (drama)manuskriptene.
kap-14.5.3.1.1: Standardisering
Diktene standardiseres på samme vis som andre hovedtekster: avsluttende tegnsetting (bortsett fra utropstegn og spørsmålstegn) fjernes fra elementer rundt diktteksten: tittelsideelementer, overskrifter, datolinjer, tilegnelser, datolinjer, melodiangivelser og signaturer. Omliggende tegn (anførselstegn, parenteser) rundt hele diktet fjernes. Ikke-strukturerende skillestreker (herunder også skigarder mellom strofer) fjernes. For småtrykkene gjengis ikke egne kolofonsider (som ofte står etter diktteksten); kolofonopplysningene gjengis i stedet i de tekstkritiske redegjørelsene. Full redegjørelse for standardiseringen finnes i prosjektets overordnede tekstkritiske retningslinjer (regulativ).
Alle tekster finnes i uedert, diplomatarisk form i prosjektets tekstarkiv.
kap-14.5.3.2: <text>
Hovedtekstfilen til dikt kodes i <text rend="poem">.
kap-14.5.3.3: Hovedstruktur
Hovedtekstfilen til dikt kodes med en text-group-text-struktur. Diktsamlinger kodes i n felles <text>, enkeltstående dikt i separate <text>.
kap-14.5.3.4: Id-verdier
Id-verdiene til de enkelte diktene står i <div type="poem" id="">. Først i id-verdiene står verkstilhørighet: DSigFinkelbechsGrav = enkeldiktet «Sigurd von Finkelbech's Gravsted», BlaDigt8191SkjaldenValhal = «Skjalden i Valhal» i Blandede Digtninger, BlaDigtftSkjaldenValhal = førstetrykket av «Skjalden i Valhal», DiEtRimbrev = «Et Rimbrev» i Digte og DiftEtRimbrev = førstetrykket til «Et Rimbrev».
kap-14.5.3.5: Diktkoding, samt typografisk tilleggskoding
Selve diktene har samme strukturkoding som grunntekstfilene, se nærmere beskrivelse i diktkapitlet. I hovedtekstfilen er en del typografiske spesifikasjoner knyttet til bokproduksjonen lagt i rend="". Nedenfor er en oversikt over de elementer som forekommer i kodingen av dikt i hovedtekstfilen:
- <div type="contents_simple"> – innholdsfortegnelse
- <div type="collectionPart"> – rundt del av diktsamling (f.eks. årganger i Blandede Digtninger)
- <div type="poem" id=""> – rundt hele diktet
- <div type="section"> – rundt deler av diktet, skilt ut med nummer eller overskrifter
- <div type="ref"> – føljetongtekst («Forts.»)
- <head type="main|sub|collectionPart|poemPart"> – hovedtittel, undertittel, tittel på del av diktsamling, tittel på del av dikt
- <head rend="centre_italic"> – overskrift til innholdsfortegnelse
- <salute rend="opener"> – tilegnelse, foran diktet
- <dateline rend="poem_opener"> – datolinje plassert før diktteksten
- <dateline rend="poem_closer"> – datolinje plassert etter diktteksten
- <date> – dato
- <tune> – melodiangivelse
- <lg> – verslinjegruppe
- <l> – verslinje
- <signed> – signatur/underskrift
- <note resp="publisher"> – utgivernoter, typisk ved avistrykk
kap-14.5.3.6: Metrikk-koding
Hovedtekstfilen inneholder den metriske kodingen av diktene. For nærmere beskrivelse se verskodingskapitlet.
kap-14.5.4: Sakprosa
kap-14.5.4.1: Hovedstruktur
Hovedtekstfilen til sakprosa kodes med en text-group-text-struktur. Hver tekst kodes i <text rend="proseText"> med mindre de skal gjengis såkalt visualisert (jf. «Drama: Hovedtekster basert på egenhendige manuskripter» over), i såfall kodes de i <text rend="visualized">.
Tekstene struktureres hovedsaklig i <div>, <head> og <p>, jf. «Koding av sakprosatekster og varia».
kap-14.5.4.2: Standardisering
Sakprosatekstene standardiseres på samme vis som andre hovedtekster: avsluttende tegnsetting (bortsett fra utropstegn og spørsmålstegn) fjernes fra elementer rundt teksten: tittelsideelementer, overskrifter, datolinjer, tilegnelser, datolinjer og signaturer. Omliggende tegn (anførselstegn, parenteser) rundt hele teksten fjernes. Ikke-strukturerende skillestreker (herunder også skigarder mellom strofer) fjernes. Full redegjørelse for standardiseringen finnes i prosjektets overordnede tekstkritiske retningslinjer (regulativ).
Alle tekster finnes i uedert, diplomatarisk form i prosjektets tekstarkiv.
kap-14.5.4.3: Koding av personer, steder, verk og institusjoner
I sakprosahovedtekster skal personer, steder, verk og institusjoner kodes med <rs>, se «Detaljkoding», kap. 12.
kap-14.6: Appendiks
Appendiks kodes i <back> og HIS-tittelsiden (en av bokproduksjonsfilene) kodes direkte inn i <back>, jf. eks. nedenfor.
Tekstgrunnlaget for appendikset skal dokumenteres. Det gjøres i <p> i <sourceDesc>. Hvis appendikset hentes fra en annen tekstkilde enn grunnteksten, legges <bibl>/<msDescription> for tekstkilden sammen med <bibl>/<msDescription> for grunnteksten.
</body> <back> <titlePage type="appendix_main"> <titlePart type="main" rend="[VERDI KOMMER]">APPENDIKS</titlePart> <titlePart type="sub" rend="[VERDI KOMMER]">Ibsens forord til annen utgave 1867</titlePart> </titlePage> <div type="appendix"><div type="preface"> <fw type="header" place="rightPage">Appendiks: forord til annen utgave</fw> <head><pb n="III"/><pb ed="hu" n="137"/>Till anden Udgave.</head> <p>Nærværende <rs type="work" corresp="woKK">Digt</rs> er skrevet i <date value="1862">Sommeren 1862</date> og første Udgave udkom samme Aars Vinter.</p> ... <closer>... <signed rend="capSmallcap">Henrik Ibsen</signed></closer> </div></div> </back></text>
Kodeeks. fra KKht.xml
</text> </group> <back> <titlePage type="appendix_main"> <titlePart type="main" rend="[VERDI KOMMER]">APPENDIKS</titlePart> <titlePart type="sub" rend="[VERDI KOMMER]">Replikkutkast</titlePart> </titlePage> <div type="appendix" hand="HI-h1"> <fw type="header" place="rightPage">Appendiks : replikkutkast</fw> <lb/><sp><spOpener><speaker><pb n="33r"/><handShift new="HI-h1" old="HI-h3"/> <hi rend="underlined">Første</hi></speaker></spOpener> <lb/><l>Se, hun stirrer paa ham nøje,</l> <lb/><l>Spejder lig i Fiendelejr, –</l></sp> <lb/><sp><spOpener><speaker><hi rend="underlined">Anden</hi></speaker></spOpener> <lb/><l>Nu hun søger Vennens Øje</l> <lb/><l>venter taus paa Svarets Sejr.</l></sp> <pb n="33v"/> </div> </back> </text>
Kodeeks. fra BEht.xml
kap-15: KOMMENTARKODING
kap-15.1: INNLEDNING
I dette kapitlet av Kodepraksis gjøres det rede for for den innholdsstrukturen som alle kommentarbindene i HIS skal følge. Materialet skal tilpasses kodepraksis, ikke omvendt, siden kodepraksis er bygget opp rundt en innholdsstruktur vedtatt av HIS.
Om implementering av kode, innhenting av spesifikasjoner og oppdatering av kodepraksis og elementbeskrivelse:
Manusredaktørene har ansvar for å oppdatere kodepraksis, samt sørge for at kodingen, kodepraksis og elementbeskrivelsen samsvarer. Dette er svært viktig for at setteriet skal kunne sette våre kommentarbind korrekt.
Manusredaktørene har ansvar for å oppdatere kodepraksis, samt sørge for at kodingen, kodepraksis og elementbeskrivelsen samsvarer. Dette er svært viktig for at setteriet skal kunne sette våre kommentarbind korrekt.
Manusredaktør og teknisk redaktør har sammen ansvaret for å sende demotekster av eventuelle nye teksttyper til vår formgiver. Formgiverens spesifikasjoner ligger så til grunn for den kode som implementeres. Dersom ny kode opprettes, sørg for at denne ivaretar formgivers spesifikasjoner og tar høyde for samtlige unntak og spesialtilfeller som kan forekomme i den aktuelle teksttypen. Sørg samtidig for at både kodepraksis og elementbeskrivelsen, som setteriet arbeider ut fra, til enhver tid er oppdatert.
kap-15.1.1: STRUKTUR
Den skisserte strukturen er basert på materialet til første dramakommentarbind. Hvert enkelt verks kommentarer grupperes, i <text> og <group>, med id-attributt og nummerering i bindet, eks. <text id="Saht" n="6">. Strukturen i hver gruppe er delt i to deler i body, "Innledning" og "Ord- og sakkommentarer", og en del i back, "introCommAuthors".
kap-15.1.1.1: STRUKTUR FOR DRAMAKOMMENTARBIND
- I <front>
- Smusstittelside: INNLEDNINGER OG KOMMENTARER
- Tittelside
- 1. kolofon
- Innholdsfortegnelse for hele bindet (NB: I dramakommentarbind forekommer i tillegg en innholdfortegnelse forut for hvert enkelt verks innledning og kommentarer. Denne skal inneholde underpunktene for innledning og kommentarer, men ikke for tekstkritisk redegjørelse og manuskriptbeskrivelse.)
- I <body>
- INNLEDNING
- BAKGRUNN
- Dramaform
- Språk
- TILBLIVELSE
- OPPFØRELSE
- Mottagelse av oppførelsen
- UTGIVELSE
- mottagelse av utgaven
NB: Rekkefølgen på OPPFØRELSE og UTGIVELSE skal følge kronologien. Ble dramaet oppført før det ble utgitt, plasseres OPPFØRELSE før UTGIVELSE. Ble det utgitt før det ble oppført, plasseres UTGIVELSE før OPPFØRELSE.
- mottagelse av utgaven
- OVERSETTELSER I IBSENS LEVETID
- PARODIER I SAMTIDEN
- TEKSTKRITISK REDEGJØRELSE
- Valg av grunntekst
- Bibliografiske opplysninger
- Innbinding.
- Format og paginering.
- Typografi.
- Papir og tilstand.
- Øvrige tekstkilder
- Tekstkritiske bemerkninger
- Tidligere tekstkritiske utgaver
- MANUSKRIPTBESKRIVELSE
- (nummererte manuskripttitler)
- innhold og genetisk status.
- datering.
- mengde, struktur og rekkefølge.
- tilstand.
- papir.
- skriveredskap og -stoff.
- hender og skrift.
- stempel og katalogsignatur.
- proveniens.
- (nummererte manuskripttitler)
- TILLEGG TIL NOTER
- BAKGRUNN
- ORD- OG SAKKOMMENTARER
- TITTELSIDE
- ROLLELISTE
- FØRSTE AKT
- ANNEN AKT
- TREDJE AKT
- INNLEDNING
- I <back>
- Litteraturliste
- Forkortelsesliste
- Medarbeideroversikt
- Annenkolofon
kap-15.1.1.1.1: Om ulike div-elementer i dramakommentarbind
Dramakommentarbindene inneholder to overordnede div-elementer:
<div type="introduction" n="I">
OG
<div type="lemmaCommentary" n="II">
Underkapitler i innledningene legges innenfor egne <div>-elementer. Altså: Et nytt <div>-element skal omslutte hvert nye undernivå. Plasseringen av et <div>-element innenfor et annet <div>-element indikerer underkapitlenes nivå, samt avgjør hvilket av de fire overskriftsnivåene vi skal benytte.
Innenfor <div type="lemmaCommentary" n="II"> forekommer i alt maksimalt syv div-elementer, som oftest fem, som omslutter de av ord- og sakkommentarene som tilhører henholdsvis TITTELSIDE, ROLLELISTE, FØRSTE AKT, ANNEN AKT, TREDJE AKT og eventuelt også FJERDE OG FEMTE AKT, dersom det drama som kommenteres består av fem akter
kap-15.1.1.2: STRUKTUR FOR BREVKOMMENTARBIND
- I <front>
- Smusstittelside: INNLEDNING OG KOMMENTARER
- Tittelside
- Førstekolofon
- Innholdsfortegnelse for hele bindet
- I <body>
- INNLEDNING
Herunder foreligger ingen faste underpunkter i likhet med innledningene i dramakommentarbindene da innledningene i de enkelte brevkommentarbind ikke nødvendigvis vil kunne følge et fast oppsett.
- ORD- OG SAKKOMMENTARER
Kommentarene til hvert enkelt brev behandles som en helhet og plasseres i egen div.
- INNLEDNING
- I <back>
- OMTALTE PERSONER
Et register over omtalte personer i Ibsens brev. Hver person biograferes. Biografiene avgrenses til kun å omfatte den perioden som brevbindet dekker, eksempelvis perioden 1844–71 for HIS 12, 1871–79 for HIS 13 osv.
- BREVMOTTAGERE (personer)
Et register over mottagere av Ibsens brev. Hver person biograferes. Biografiene avgrenses til kun å omfatte den perioden som brevbindet dekker, eksempelvis perioden 1844–71 for HIS 12, 1871–79 for HIS 13 osv.
- BREVMOTTAGERE (institusjoner, organisasjoner, bedrifter)
Et register over mottagere av Ibsens brev. Hver institusjon omtales. Omtalene avgrenses til kun å omfatte den perioden som brevbindet dekker, eksempelvis perioden 1844–71 for HIS 12.
- TIDSTAVLE
Oversikt over Ibsens liv: publikasjoner, reiser, bosted, viktige hendelser o.l. i den perioden som brevbindet dekker, eksempelvis perioden 1844–71 for HIS 12.
- Litteraturliste
- Forkortelsesliste
- Personregister
- Medarbeideroversikt
- Annenkolofon
- OMTALTE PERSONER
NB: Tekstkritisk redegjørelse for brevene og manuskriptbeskrivelser av brevene plasseres i brevtekstbindene og ikke i brevkommentarbindene pga. brevkommentarenes omfang, jf. bestemmelser og praksis for HIS 12 og 12k.
kap-15.1.1.3: OM EKSTERNE PRODUKSJONSFILER
Følgende eksterne produksjonsfiler må leveres til setteriet. Gi hver enkelt fil beskrivende filnavn. Her er en oversikt over hva som skal inngå i de aktuelle filene:
Smusstittelside
Tittelside (NB: en tittelside for hvert drama i dramakommentarbind)
Førstekolofon
Innholdsfortegnelse for hele bindet samlet
Innholdsfortegnelser for innledningen og kommentarene til hvert enkelt verk i dramakommentarbind (NB: Brevkommentarbind skal kun ha innholdsfortegnelse for innledningen.)
Litteraturliste
Illustrasjonsliste
Forkortelsesliste
Medarbeideroversikt
Annenkolofon
Smusstittelside
Tittelside (NB: en tittelside for hvert drama i dramakommentarbind)
Førstekolofon
Innholdsfortegnelse for hele bindet samlet
Innholdsfortegnelser for innledningen og kommentarene til hvert enkelt verk i dramakommentarbind (NB: Brevkommentarbind skal kun ha innholdsfortegnelse for innledningen.)
Litteraturliste
Illustrasjonsliste
Forkortelsesliste
Medarbeideroversikt
Annenkolofon
TIL INFORMASJON: For etablering av de eksterne produksjonfilene: Ta utgangspunkt i sist leverte xml-filer og sikre at informasjonen fortsatt er korrekt, samt juster de opplysninger som er unike for hvert kommentarbind.
Dersom den eksterne produksjonsfilen ikke foreligger i xml, må det opprettes. Sikre da at kodingen er i tråd med formgivers spesifikasjoner for den aktuelle teksttypen (se permen). Foreligger ikke spesifikasjoner fra formgiver, må det innhentes (send demo-tekst til formgiver). Dersom ny kode opprettes, f.eks. nye attributtverdier, må dette samtidig oppdateres i den elementbeskrivelsen som setteriet tar utgangspunkt i under settingen. Setteriet må da også informeres om det som ev. er nytt når de mottar de(n) aktuelle filen(e).
Dersom den eksterne produksjonsfilen ikke foreligger i xml, må det opprettes. Sikre da at kodingen er i tråd med formgivers spesifikasjoner for den aktuelle teksttypen (se permen). Foreligger ikke spesifikasjoner fra formgiver, må det innhentes (send demo-tekst til formgiver). Dersom ny kode opprettes, f.eks. nye attributtverdier, må dette samtidig oppdateres i den elementbeskrivelsen som setteriet tar utgangspunkt i under settingen. Setteriet må da også informeres om det som ev. er nytt når de mottar de(n) aktuelle filen(e).
FORKORTELSESLISTEN foreligger i xml. Den må justeres for hvert bind, og den leveres også til setteriet som en ekstern fil.
LITTERATURLISTEN har hittil kun foreligget i wordformat og er unik for hvert bind, med unntak av de kilder som går igjen. Den leveres også til setteriet som en ekstern produksjonsfil. Da denne ikke er kodet, settes den manuelt. Det krever noe mer kontroll fra vår side i og med at settingen da ikke alltid vil være konsekvent, f.eks. kan doble anførselstegn da lett opptre både som vinkler og rette anførselstegn. Det bør vurderes om ikke vi bør legge inn <quote> i stedet for tegnene, samt entiteter apostrofer, enkle vinkelanførselstegn o.l. Kolumnetittel (ev. som kode) kan også kanskje legges inn? Vurder hva som er hensiktsmessig.
kap-15.1.2: ORD- OG SAKKOMMENTARER
TEI Guidelines har ingen forslag til koding av lemmakommentarer. Kommentarkodingen er derfor opprettet og utarbeidet av HIS.
<list type="commentary"> <item n="1"><xptr type="lemma" url="B13ht.xml" from="koB13_1806" id="koB13_1806"/></item> <item n="2">Freia</item> <item n="3"> <p rend="noIndent">norrøn kjærlighets- og fruktbarhetsgudinne, kjent for sin skjønnhet. Andre skrivemåter i 1840-årene er Freya og Freyja, senere Frøya.</p> </item> </list>
Hver enkelt lemmakommentar kodes som en liste i <list type="commentary">. I dramakommentarbind genereres det en blanklinje mellom hver lemmakommentar, mens det i brevkommentarbindene, diktkommentarbindet og sakprosakommentarbindet ikke genereres en blanklinje mellom hver enkelt kommentar (pga. kommentarenes omfang).
Innenfor koden <item n="1"> står lemmaets xptr-element med en unik attributtverdi som lenker lemmaet til tekstbindet. Dette xptr-elementet oversettes til sidetall og linjenummer for lemmaets forekomst i den aktuelle hovedteksten.
Selve lemmaet står innenfor <item n="2">. Denne koden genererer halvfete typer og en skarp, venstrevendt klamme ( ] ) som avlutter lemmaet. Klammen skal ikke være i fet, og det skal ikke genereres mellomrom mellom lemmaet og den avsluttende klammen.
Lemmakommentaren skal ligge innenfor koden: <item n="3">
Elementet <p rend="noIndent"> skal ligge innenfor <item n="3">-koden da det ikke skal genereres avsnittsinnrykk i begynnelsen av lemmakommentaren. Lemmakommentaren skal dessuten helst ikke kodes slik at den deles inn i avsnitt. Alternativt må man vurdere om kommentaren ikke snarere burde deles inn i to kommentarer dersom man skulle ønske avsnittsinndeling.
EKS: <list type="commentary"> <item n="1"><xptr type="lemma" url="B13ht.xml" from="koB13_1806" id="koB13_1806"/></item> <item n="2">Mit Hoved er fortumlet</item> <item n="3"> <p rend="noIndent">TEKST TEKST TEKST</p> </item> </list>
I og med at koden <item n=2> skal generere skarp, venstrevendt klamme, er det ikke nødvendig å legge inn en egen entitet for klammen i parsingen fra word til xml (eller under kodearbeidet).
kap-15.1.3: OVERSKRIFTSKODING
kap-15.1.3.1: Overskriftsnivåene
Alle overskrifter på de to øverste nivåene skal settes som majuskler, og skrives derfor som majuskler i filen. Alle øvrige overskrifter skal settes som kapiteler, og disse må derfor skrives som minuskler i xml-filen (inklusive første bokstav, initialer i personnavn o.l.).
NB: Kapitelfonten mangler tegn som tankestrek og gradstegn. Setteriet er klar over dette, men vi må også sjekke i satskorrekturen at dette ikke er falt ut. Slike tegn kan med fordel kodes som <hi rend="miniscule"> for å sikre seg at de får riktig utseende.
Head-kodene er utformet slik at de angir utseende og formatering på overskriften. Eks:
<head rend="versal14">INNLEDNING</head>
<head rend="versal11,5">BAKGRUNN</head>
<head rend="centre_smallCaps">dramaform</head>
<head rend="inline_smallCaps">ortografi og bøyning.</head>
Eventuelle overskrifter under det laveste nivået settes i kursiv med <head rend="italic"> ...</head>.
Det laveste overskriftsnivået skal settes på linje med det etterfølgende avsnittet, altså ikke linjeskift etter overskriften, og må derfor avsluttes med punktum. Hvis teksten i avsnittet er i listeform, settes overskriften ikke inline, men punktum beholdes i overskriften.
I smallcaps-overskriftene forekommer det manuskriptbetegnelser som består av både store og små bokstaver. I og med at overskriften skal settes i kapiteler, må eventuelle minuskler som skal forbli minuskler i overskriften omrammes av koden <hi rend="miniscule"></hi>. Manuskriptet TarkUiB NT238r kodes derfor slik:
<head rend="centre_smallCaps">t<hi rend="miniscule">ark</hi>u<hi rend="miniscule">i</hi>b nt238<hi rend="miniscule">r</hi></head>.
Overskriften Ms.4° 1111a, bl. 267–349 kodes slik:
<head rend="centre_smallCaps">m<hi rend="miniscule">s</hi>.4° 1111<hi rend="miniscule">a</hi>, bl.&tu20;267<hi rend="miniscule">–</hi>349 </head>
NB: <title>-elementet kan ikke ligge innenfor head-koden; da vil det som er kodet i <title> forbli i minuskler og ikke bli satt i kapiteler som ønsket når teksten settes; se Typografisk koding.
kap-15.1.4: DETALJKODING
kap-15.1.4.1: Text-elementet
I det ytterste <text>-elementet, mellom </teiHeader> og <group>, må det legges inn et id-attributt som er unikt for hvert enkelt kommentarbind. I <text>-elementet i første kommentarbind legger vi eksempelvis inn et id-attributt med attributtverdien bd1k: <text id="bd1k">.
I tillegg må <text>-elementet inneholde et type-attributt: type="commentary".
I tillegg må <text>-elementet inneholde et type-attributt: type="commentary".
For kommentarbind 1 ser det ytterste text-elementet eksempelvis slik ut: <text type="commentary" id="bd1k">.
I DRAMAKOMMENTARBIND: Foruten det ytterste <text>-elementet, ligger innledningen og kommentarene til hvert enkelt verk som kommenteres i et eget <text>-element. Dette elementet inneholder et id-attributt med en unik attributtverdi for hvert enkelt verk. Kommentarene til de ulike verkene er strukturert kronologisk jf. verkenes opprinnelige utgivelsesår. Et n-attributt angir den aktuelle rekkefølgen.
<text>-elementet til Norma ser eksempelvis slik ut: <text id="Nocommentaries" n="5">.
I BREVKOMMENTARBIND holder det med et text-element som omslutter både innledning og kommentarene, jf. HIS 12k: <text type="commentary" id="bd12k">.
kap-15.1.4.2: p-elementet – <p> eller <p rend="noIndent">?
Alle avsnitt i kommentarfilene skal omsluttes av elementet <p>. Dersom avsnittet ikke skal settes med innrykk, skal <p>-elementet inneholde et rend-attributt med attributtverdien "noIndent": <p rend="noIndent">.
Avsnitt skal ikke settes med innrykk (kodes med <p rend="noIndent">):
- etter overskrifter (alle <head>-elementer)
- etter innrykkede dikt- eller prosasitater <quote rend="indent"> og <quote rend="proseIndent">
- i lemmakommentarene (i stien/kombinasjonen: <list type=?commentary?>/<item n="3"><p> )
- etter lister (</list>)
- innenfor <div type="Bb1_to1871"> i totalregisteret (og da også registrene Omtalte personer og Brevmottagere)
- innenfor <div type="regReference"> i totalregisteret (og da også registrene Omtalte personer og Brevmottagere)
UNNTAK: avsnitt som IKKE skal settes med innrykk, men som likevel kodes kun med <p>):
innholdet i <p> i bidragsyterlisten, <div type="introCommAuthors"> (angivelsen av hvem som har skrevet de ulike delene av innledningen). Dette behandles som et unntak fordi teksten i <p> i bidragsyterlisten settes i 8/8 og alle linjer settes med 2 mm innrykk fra satsflatens venstrekant. (Det vil si at teksten i <p> her settes med samme venstremarg som teksten i lemmakommentarene på siden.)
innholdet i <p> i bidragsyterlisten, <div type="introCommAuthors"> (angivelsen av hvem som har skrevet de ulike delene av innledningen). Dette behandles som et unntak fordi teksten i <p> i bidragsyterlisten settes i 8/8 og alle linjer settes med 2 mm innrykk fra satsflatens venstrekant. (Det vil si at teksten i <p> her settes med samme venstremarg som teksten i lemmakommentarene på siden.)
Følgelig kodes kun avsnitt i innledningene med <p>-elementet (uten attributt), så sant det skal genereres avsnittsinnrykk.
kap-15.1.4.3: Kolumnetitler i dramakommentarbind
Kodete kolumnetitler må legges inn i kommentarfilen på rett sted, dvs. rett innenfor den <div> som krever ny kolumnetittel, og før et eventuelt <head>-element. Ny kolumnetittel, ev. kolumnetitler dersom både venstre og høyre kolumnetittel skal endres, må legges inn ved ny teksttype (f.eks. Omtalte personer) i brevkommentarbindet.
Følgende kode omslutter en kolumnetittel (her den som skal stå på oppslagets høyre side): <fw type="header" place="rightPage">Innledning</fw>
EKS. på koding av kolumnetitler for Catilina 1850:
<div type="introduction" n="I"> <fw type="header" place="leftPage">Catilina 1850</fw> <fw type="header" place="rightPage">Innledning</fw> <head rend="versal14">INNLEDNING</head> <div type="lemmaCommentary" n="II"> <fw type="header" place="rightPage">Ord- og sakkommentarer</fw>
<div type="introduction" n="II"> <fw type="header" place="leftPage">Catilina 1850</fw> <fw type="header" place="rightPage">Innledning</fw> <head rend="versal14">INNLEDNING</head>
Kolumnetittelkoden legges kun inn der den skal forekomme første gang, og løper til den erstattes av ny kolumnetittel. Det er derfor ikke nødvendig å legge inn <fw type="header" place="leftPage">Catilina 1850</fw> på nytt når innledningen til Catilina 1850 slutter og Ord- og sakkommentarene begynner da kolumnetittelen på oppslagets venstre side fortsatt skal være Catilina 1850.
Attributtverdiene "leftPage" og "rightPage" viser plassering av kolumnetittel innenfor oppslaget. I dramakommentarbindene er eksempelvis venstre kolumnetittel konstant verktittelen, eksempelvis Catilina 1850, både i innledningen og ord- og sakkommentarene til det aktuelle verket. Høyre kolumnetittel er Innledning gjennom hele innledningen og går så over til å være Ord- og sakkommentarer i kommentardelen.
kap-15.1.4.4: Typografisk koding
kap-15.1.4.4.1: Titler
<title rend="italic"> skal generere kursiv. Titler (både originaltitler og oversatte titler) på verk, samleverk, aviser og tidskrifter kodes med <title rend="italic">.
<title rend="quotes"> skal generere doble anførselstegn. Titler på artikler, dikt, sanger o.l. kodes i <title rend="quotes">
<title rend="normal"> brukes hvis det er behov for å avkursivere verktitler innenfor en kursivert tekst.
NB: <title>-elementet kan ikke ligge innenfor et element som angir at den kodete teksten skal settes som kapiteler (smallCaps). Dette gjelder eksempelvis i de tilfeller hvor et verks tittel inngår i en overskrift som skal settes i kapiteler:
EKS: <hi rend="smallCaps">språket i catilina</hi> 1875
I eksemplet ovenfor kan følgelig ikke tittelen Catilina kodes.
Mellom over- og undertitler skal det være et midtstilt kolon omgitt av et mellomrom på hver side. EKS: Leopold : original Tragedie i 5 Acter. Kolonet skal kodes som entitet: &titleColon;. Det skal da se slik ut:
<title rend="italic">Leopold &titleColon; original Tragedie i 5 Acter</title>
kap-15.1.4.4.2: Formatering
<hi rend="italic"> skal generere kursiv. I lemmakommentarene skal gjentagelser og varianter av lemma, lemmaets etymologiske opprinnelse, latinske ord (f.eks. Myosotis), avsnittsoverskrifter som det henvises til (f.eks. Manuskriptbeskrivelse) og andre ord eller tegn som skal utheves, markeres med kursiv.
<hi rend="smallCaps"> skal generere kapiteler. Ved blanding av kapiteler og minuskler omrammes minusklene av koden <hi rend="miniscule"></hi>. Det gjelder også ved særtegn som tankestrek, skarpe klammer o.l.
kap-15.1.4.5: Bilder
Koding av illustrasjoner beskrives i kapitlet Produksjonskoding i Kodepraksis.
<hi rend="kreditering"> forekommer i bildetekster. Teksten i elementet skal settes i kursiv og omsluttes av rett parentes. Alle titler som normalt markeres med kursiv, må her kodes med <title rend="normal">, jf. 1.4.2.1. ovenfor.
kap-15.1.4.6: Sitater
GENERELT: Korte sitater kodes med <quote> uansett teksttype. Ved lengre sitater (over to el. tre linjer) gir vi ulike rend-attributter til ulike teksttyper, som da genererer innrykk samt luft foran og etter sitatet. Som regel vil det innrykkede sitatet ligge innenfor et lengre avsnitt, og det er derfor ikke nødvendig å avslutte <p> før <quote rend="xxx">. Første <p> etter sitatet må få et rend-attributt som forhindrer at første linje starter med innrykk: <p rend="noIndent">.
Ved innrykkede sitater må eventuelle ht-referanser, bibl-koder og avsluttende punktum ligge innenfor quote, slik at de blir vist og trykt som en del av det innrykkede tekstpartiet. Ved sitater uten innrykk skal <quote> avsluttes før referansen.
Hvis det forekommer titler i kursiv eller anførselstegn inne i et sitat, skal de ikke kodes med <title>-koden, i og med at de ikke skal samkjøres med de øvrige tittelforekomstene. Kursiverte titler kodes med <hi>, mens anførselstegn behandles ulikt ut fra om de er innenfor et innrykket sitat eller ikke: Innenfor <quote> brukes entitetene for enkle vinkler, ‹ og›, mens man innenfor <quote rend="proseIndent"> må bruke &lquo; og &rquo; for doble vinkelanførselstegn.
NB – kontroller i satskorrektur: Alle innrykkede sitater settes 10,5 på 13 (altså i n grad mindre enn øvrig tekst i kommentarbindene).
PROSASITATER: Vil prosasitatet utvilsomt strekke seg over mer enn tre linjer etter at teksten er satt og ombrukket ved setteriet, må sitatet kodes med <quote rend="proseIndent">. Når vi er i tvil om hvor langt et sitat vil være etter setting og ombrekking, koder vi sitatet kun med <quote>. Dersom det viser seg at enkelte sitater (som da ikke er innrykkskodet) strekker seg over mer enn tre linjer etter ombrekking, må sitatene markeres for innrykk av oss under første satskorrektur. Det er ingen fordel med for mange innrykkede sitater, så man kan godta sitater på fire og fem linjer hvis det f.eks. er mange forekomster i nærheten av hverandre eller også dersom sitatet utgjør hele heller tilnærmet hele kommentaren – det vil da, grafisk sett, ikke fungere godt med innrykk i lemmakommentaren.
Noen ganger er det nødvendig med avsnitt i et prosasitat, og da må siste del av sitatet legges i en <hi> som genererer innrykk av første linje:
<quote rend="proseIndent">En erklæring [...] vilde gøre en ende på bagtalelsen.<lb/>
<hi rend="indent_4mm">At jeg ikke kan efterkomme din anmodning om at gribe ind her gør mig oprigtig ondt.</hi></quote>
DIKTSITATER og SITERTE VERSLINJER: Diktsitater og verslinjer som er på to linjer eller mer, kodes med <quote rend="indent"> og <lg>, og med <l> rundt hver verslinje.
EKS:
<quote rend="indent">
<lg>
<l>Der sluttes Fulvia, den unge Qvinde,</l>
<l>Bestemt til Gravens rige Offer, inde;</l>
</lg>
<bibl>(Paludan-Mller 1836–38, b. 2, 205)</bibl>
</quote>
Når siterte verslinjer blir metrisk skandert, kodes de i hver sin <l> innenfor <lg>, skanderingen med attributt: <l rend="scand">. Linjene skal settes på hver sin linje under hverandre, og skanderingen skal midtstilles under verslinjen.
EKS:
<quote rend="indent">
<lg>
<l>Med Perler og Ringe alt som bedst</l>
<l rend="scand"><note type="metKomm">u - u u - u - u -</note></l>
</lg>
</quote>
DRAMASITATER MED ROLLENAVN: Lengre dramasitater som inneholder rollenavn og/eller sceneanvisninger, kodes som i hovedtekstfilen. Man kopierer det aktuelle tekststedet fra hovedtekstfilen og fjerner overflødig metrikk- og ederingskoding, samt who-attributt og ev. faste linjeskift. Ved avvikende typografi (f.eks. ved visualiserte tekster) standardiseres rollenavn og sceneanvisninger som vist i eksempelet under:
EKS:
<quote rend="indent">
<lg>
<sp>
<spOpener>
<speaker rend="smallCaps">catilina</speaker>
<stage>urolig</stage>
</spOpener>
<l part="I">Du kjender ham?</l>
</sp>
<sp>
<spOpener>
<speaker rend="smallCaps">furia</speaker>
</spOpener>
<l part="F">– – Jeg saae ham aldrig der –</l>
<l>jeg vidste Intet, før det var for seent!</l>
<l part="I">Nu kjender jeg hans Navn – –</l>
</sp>
</lg>
</quote>
DRAMASITATER I PROSA: Prosasitater fra et drama kodes i <quote rend="proseplayIndent">, og <lg> og <l> erstattes av <p>, ev. med <lb/> der faste linjeskift er nødvendig:
EKS:
<quote rend="proseplayIndent">
<sp><spOpener><speaker rend="smallCaps">arne</speaker>
<stage>afsides</stage></spOpener>
<p>Dette har været mig en forbandet Dag!</p></sp>
</quote>
BREVSITATER: Hvis et brevsitat inneholder elementer som krever et spesielt oppsett, f.eks. underskrift, kodes det som i brevtekstfilen:
EKS:
<quote rend="proseIndent">Indlagt tager jeg mig den Frihed at sende Dem de første Scener af en Operatext.
<salute rend="closer">ærbødigst</salute>
<signed>Henr: Ibsen</signed>
</quote>
kap-15.1.4.7: Entiteter som særlig brukes i kommentarfilene
Den generelle listen over entiteter som er i bruk, finnes under Entiteter i kodepraksis. I likhet med hovedtekstfilene overlates konvertering av æ, ø, å, Æ, Ø og Å til setteriet. Andre særtegn gjøres om til entiteter underveis i arbeidet; se dokumentet "Fra word til xml" under "kommentararbeid" i kollasjonistmappen.
Entiteten &metDash; brukes for metriske streker i metrikkformlene.
Entiteten &titleColon; brukes for kolonet mellom over- og undertittel. Det legges inn mellomrom foran og bak entiteten.
Skråstrek har entiteten /, og bakovervendt skråstrek har \. Begge skal ha mellomrom før og etter nå de brukes for å markere hhv. (vers)linjeslutt og delte verslinjer i lemma.
Det brukes entiteter for brøker: ½, ¼, ¾ osv.
For tre prikker ved utelatelser brukes entiteten …. Den brukes også innenfor skarpe klammer: […] for ....
For gangetegn i f.eks. målangivelser brukes entiteten ×
Entitetene ‹ og › skal generere enkle vinkelanførselstegn. Disse entitetene er forbeholdt markerering av sitat i sitat og artikkeltitler som forekommer i sitat (hvor kursiv ikke er brukt i det siterte tekststedet).
Entitetene &lapo; og &rapo; skal generere enkle apostrofer ved ordforklaringer på venstre og høyre side av forklaringen.
Entiteten &rapo; brukes også som genitivsapostrof samt for å markere utelatt bokstav.
Vi bruker også entiteter for plusstegn og prosenttegn. De erstattes henholdsvis av + og %. Se for øvrig entitetskapitlet.
Entiteten &foot; skal generere en enkel, rett apostrof (tegnet for fot) og brukes kun i metriske formler. Se også Metrisk koding i kommentarfiler.
Entitetene &lquo; og &rquo; genererer doble anførselstegn av typen dobbel vinkel, høyrevendt og venstrevendt. Brukes bare unntaksvis, først og fremst inne i innrykkede sitater, eller der title-koding ikke lar seg validere, f.eks. godtar <title>-koden ikke <title rend="quotes">.
Tittelen på tidsskriftet "Manden"/Andhrimner kodes slik: &lquo;<title rend="italic">Manden</title>&rquo;/<title rend="italic">Andhrimner</title>.
Entitetene · og &schwa; forekommer i gjengivelse av lydskrift, og genererer hhv. en midtstilt prikk som trykkmarkør og scwharabaktivokalen e.
kap-15.1.4.7.1: Entitet for 20-enheters mellomrom
Entiteten &tu20; genererer et 20-enheters mellomrom i bokutgaven. Denne entiteten skal behandles som én enhet: Det tillates ikke linje- eller sideskift innenfor enheten. Entiteten settes inn I STEDET FOR mellomrom der den brukes. Søk på alle ordenstall (1., 2., 3. osv.), og vurder i hvert tilfelle om enheten skal forsynes med denne entiteten, f.eks.: 1.&tu20;årgang.
FØLGENDE FORKORTELSER (ev. forkortelseskombinasjoner) OG TEGN SKAL SETTES MED ENTITETEN &tu20; MELLOM PUNKTUM OG ETTERFØLGENDE TEGN: (husk å søke både på minuskler og majuskler, men med case sensitive aktivert)
- b. + tall
- bl. + tall
- l. + tall
- Ms. + tall
eks.: Ms.&tu20;230b/45a - Ms.fol. + tall
eks.: Ms.fol.&tu20;3704:2 - nr. + tall
- s. + tall
- sp. + tall
- ordenstall + utg.
- . + [
Mellomrommet mellom et tall og prosenttegnet skal erstattes av &tu20;. Husk entitet også for prosenttegnet, slik at det ser slik ut i xml-en: TALL&tu20;%
Mellomrommet i tall på mer enn fem sifre skal erstattes av &tu20;, EKS.: 300&tu20;000.
Mellomrommet mellom dato og måned skal erstattes av &tu20;, EKS.: 3.&tu20;mai. Erstatt PUNKTUM + MELLOMROM + MÅNED med PUNKTUM + &tu20; + MÅNED. Søk og erstatt deg gjennom alle tolv måneder, så er kodingen av dette komplett. Husk å markere for "case sensitive" under denne søk-erstatt-operasjonen.
Ved skråstrek med mellomrom på begge sider erstattes mellomrommene med &tu20;.
Listen gjelder også for forkortelser med stor forbokstav og for alle tall i skarpe klammer, f.eks.: Bl.&tu20;3. Dessuten bør den brukes ved ordenstall + bibelforkortelser, f.eks.: 1.&tu20;Mos
Forkortelser som o. s. v., o. fl., d. e., f. Ex. forekommer i enkelte av Ibsens tekster, særlig i brevene, ev. også i rollelister. I de tilfeller hvor da Ibsen (eller andre vi siterer) lager mellomrom mellom tegnene i forkortelsen, skal disse mellomrommene kodes og settes som 20-enheters mellomrom, f.eks.: o.&tu20;s.&tu20;v., som er aktuelt for lemmaene i kommentarbindene.
OVERSIKT OVER ØVRIGE TEKSTSTEDER OG FORKORTELSER HVOR DET VIL VÆRE AKTUELT MED 20-ENHETERS MELLOMROM:
20-enheters mellomrom mellom initialer DERSOM det ER mellomrom mellom slike i tekstgrunnlaget.
EKS: S.&tu20;A. Klubien
EKS: S.&tu20;A. Klubien
Dersom det IKKE er mellomrom mellom initialene i XML-filen/tekstgrunnlaget, skal det heller ikke settes inn noe (hverken fullt mellomrom eller 20 enheters mellomrom).
Eks.: S.A. Klubien
Eks.: S.A. Klubien
20-enheters mellomrom mellom dato og måned.
Eks.: 30.&tu20;august
Eks.: 30.&tu20;august
20-enheters mellomrom mellom tall og forkortelser for måleenheter (mm, cm, m, kr etc.).
Eks.: 214&tu20;mm
Eks.: 214&tu20;mm
20-enheters mellomrom mellom tall og x-tegnet når bredde x høyde angis.
Eks.: 134&tu20;x&tu20;187
Eks.: 134&tu20;x&tu20;187&tu20;mm
UNNTAK: Fullt mellomrom rundt tegnet x (som har entiteten ×) må imidlertid bevares når det omsluttes av tekst. I brevtekstbindet (HIS 12) forekom eksempelvis teksten: bredde x høyde. Her må det være fullt mellomrom: bredde x høyde.
FORKORTELSER SOM FOREKOMMER I TEKST PRODUSERT AV HIS, SKAL SETTES UTEN MELLOMROM MELLOM PUNKTUM OG ETTERFØLGENDE TEGN (heller ikke 20 enheters mellomrom). Eks.:
- d.e.
- d.y.
- e.l.
- f.eks.
- h.r.advokat
- m.v.
- o.l.
TIL INFORMASJON: I enkelte tilfeller må koderen avgjøre hva som er mest hensiktsmessig: 20-enheters mellomrom eller fullt mellomrom? Koderen er den som kjenner konteksten og må da vurdere om enheten blir for lang eller ikke siden koding med &tu20; hindrer linjebrekking. Koderen må forsøke å forutse hva det eventuelt fører med seg av satsproblemer som f.eks. for strukne linjer.
VURDER I TVILSTILFELLER: Hva er viktigst: Å unngå linjebrekking eller skåne seg mot for mange strukne linjer i satsen? Samtidig: så lenge ikke enheten er svært lang, noe som da helt klart vil skape for mange problemer for setteren, er det setterens oppgave å løse de problemene, men koderne bør strebe etter å legge best mulig til rette for en god sats. Et godt råd kan være at vi kun legger inn &tu20; mellom forkortelsen og det etterfølgende tegnet/tallet, og ikke mellom både forutgående tegn og etterfølgende forkortelse, som i følgende eksempel:
VURDER I TVILSTILFELLER: Hva er viktigst: Å unngå linjebrekking eller skåne seg mot for mange strukne linjer i satsen? Samtidig: så lenge ikke enheten er svært lang, noe som da helt klart vil skape for mange problemer for setteren, er det setterens oppgave å løse de problemene, men koderne bør strebe etter å legge best mulig til rette for en god sats. Et godt råd kan være at vi kun legger inn &tu20; mellom forkortelsen og det etterfølgende tegnet/tallet, og ikke mellom både forutgående tegn og etterfølgende forkortelse, som i følgende eksempel:
[105] sp.&tu20;[1]
OG IKKE:
[105]&tu20;sp.&tu20;[1]
SOM BLIR MEGET VOND Å LESE.
kap-15.1.4.8: Fotnoter
Fotnoter kodes i <note type="footer">.
Koden må omslutte hele fotnoteteksten, og koden må plasseres direkte etter det ordet fotnoten står til, uten mellomrom; plasseringen av koden har betydning for hvor fotnotetallet plasseres. Fotnotetallet genereres automatisk både under konvertering og ved setteriet.
OBS: Alle fotnoter må kodes allerede i Word, da fotnotefunksjonen forsvinner i overføringen fra word til xml, og fotnoteteksten derfor automatisk innlemmes i den øvrige teksten uten at den markeres på noen måte.
OBS: Alle fotnoter må kodes allerede i Word, da fotnotefunksjonen forsvinner i overføringen fra word til xml, og fotnoteteksten derfor automatisk innlemmes i den øvrige teksten uten at den markeres på noen måte.
EKS:
<p>Papiret i selve heftene er gulaktig konseptpapir. Siden måler ca. 166 x 213 mm.<note type="footer">Ytterkanten er skadet; bredden er målt der mest papir er bevart.</note></p>
kap-15.1.4.9: Romertall
Dersom romertall skal kodes i senere kommentarbind, koder vi dem i hi-elementet med det globale attributtet rend og attributtverdien romNum. NB: Foreløpig koder vi ikke romertall da disse ikke skal settes på noen bestemt måte.
<hi rend="romNum">VI.iii.</hi>. Både små og store romertall samt punktum inkluderes i koden. Unntak: Dersom de store romertallene skal settes som kapiteler, kodes kun store og ikke små romertall. Husk i så fall å skrive de kodete romertallene som minuskler i xml-filen.
kap-15.1.5: Referanser og koblinger
kap-15.1.5.1: Bibliografiske referanser – <bibl>
Det skal oppgis bibliografisk referanse i parentes etter alle sitater i teksten i kommentarbindet. Alle referanser skal kodes med <bibl>, og alle disse skal ha et motsvar i litteraturlisten.
<bibl>-elementet skal kun omslutte det aller nødvendigste, f.eks: <bibl>(Andersen 1998, 54)</bibl>
I enkelte tilfeller er ikke forfatternavnet oppført i parentes sammen med den aktuelle referansen. Der det er tilfelle, kan vi legge inn forfatternavnet slik at det kommer med i <bibl>-kodingen. Dersom forfatternavnet er nevnt rett forut for parentesen, lar vi navnet stå utenfor, men inkluderer det i kodingen, f.eks.:
<bibl>-elementet skal kun omslutte det aller nødvendigste, f.eks: <bibl>(Andersen 1998, 54)</bibl>
I enkelte tilfeller er ikke forfatternavnet oppført i parentes sammen med den aktuelle referansen. Der det er tilfelle, kan vi legge inn forfatternavnet slik at det kommer med i <bibl>-kodingen. Dersom forfatternavnet er nevnt rett forut for parentesen, lar vi navnet stå utenfor, men inkluderer det i kodingen, f.eks.:
"[...] som hos <bibl>Wergeland (1918–1940, b. 2:5, 296)</bibl>
Vær oppmerksom på at <bibl> ikke tillater <quote>-elementet innenfor seg.
Noen henvisninger som ikke er utformet som referanser i parenteser, bør også legges innenfor <bibl> for å kunne sjekke dem ved hjelp av sgrep-søk. Det gjelder særlig bibelhenvisninger i løpende tekst og manuskriptbetegnelser.
For interne henvisninger til illustrasjoner i kommentarbindet, se Produksjonskoding.
VI AVVENTER KODING MED XREF-ELEMENTET DA DET IKKE ER AVKLART HVORDAN DENNE KODEN SKAL BRUKES I UTGAVENS ELEKTRONISKE UTGAVE. I TILLEGG ANBEFALES DET Å BENYTTE ET ANNET ELEMENT TIL DETTE FORMÅLET DA xref-ELEMENTET VISSTNOK BRUKES TIL ANNET I ANDRE TEKSTTYPER.
Elementet <xref> brukes ved referering fra lemmakommentar eller innledning til hovedtekst, til andre lemmakommentarer eller til kommentarenes innledning. Elementet skal kun omslutte den entiteten som skal generere side- og linjetall som angir tekststedet det henvises til. <xref>-elementet skal ikke omslutte den tekst som står i tilknytning til entiteten, da det kun er selve entiteten som skal erstattes av et ikon e.l. som aktiviserer en lenke/en kobling til det tekststedet som entiteten refererer til.
NB: xref-koding forekommer ikke i brevkommentarbindene da vi der henviser til øvrige lemma ved å oppgi selve ordlyden på lemmaet, og ikke side- og linjenummer som i dramakommentarbindene. EKS: jf. kommentar til "amico romano" ovenfor.
Elementet <xref> brukes ved referering fra lemmakommentar eller innledning til hovedtekst, til andre lemmakommentarer eller til kommentarenes innledning. Elementet skal kun omslutte den entiteten som skal generere side- og linjetall som angir tekststedet det henvises til. <xref>-elementet skal ikke omslutte den tekst som står i tilknytning til entiteten, da det kun er selve entiteten som skal erstattes av et ikon e.l. som aktiviserer en lenke/en kobling til det tekststedet som entiteten refererer til.
NB: xref-koding forekommer ikke i brevkommentarbindene da vi der henviser til øvrige lemma ved å oppgi selve ordlyden på lemmaet, og ikke side- og linjenummer som i dramakommentarbindene. EKS: jf. kommentar til "amico romano" ovenfor.
EKS: <p>femfotsjambe, jf. kommentar til <xref>&koK1_15_intern;</xref>.
kap-15.1.5.3: Referanseentiteter
Både lemma-, intern- og ht-elementene genererer side- og linjereferanser til tekstbindet. Side- og linjereferansene genereres automatisk ved setteriet og må kontrolleres av oss under satskorrekturen.
kap-15.1.5.3.1: Lemmaentiteter (&koK1_nr;)
Entiteten &koK1_nr; er en unik ID for hvert enkelt lemma i kommentarfilen, og den må kopieres inn på korrekt plass i hovedtekstfilen idet den utgjør grunnlag for generering av korrekt side- og linjereferanse i kommentarbindet.
Den kobler lemma til den aktuelle hovedteksten (her K1); den unike entiteten angir lemmaets forekomst i hovedteksten og gjør det mulig å generere side- og linjereferanser som angir lemmaets plassering i tekstbindet. I hovedteksten skal lemmaentitetene plasseres umiddelbart foran lemmaet, eller foran første ordet i lemmaet, uten mellomrom.
Den kobler lemma til den aktuelle hovedteksten (her K1); den unike entiteten angir lemmaets forekomst i hovedteksten og gjør det mulig å generere side- og linjereferanser som angir lemmaets plassering i tekstbindet. I hovedteksten skal lemmaentitetene plasseres umiddelbart foran lemmaet, eller foran første ordet i lemmaet, uten mellomrom.
Lemmaentitetene skriptes om til lemmaelementer så snart kommentarmaterialet er overført til XML. Selve lemmaentiteten (eksklusive amp-tegnet og semikolon) gjøres da om til attributtverdi i følgende xptr-element:
<xptr type="lemma" url="F1ht.xml" from="koF1_40" id="koF1_40"/>
Attributtverdien til type-attributtet (her "lemma") angir at dette er et lemmaelement. Attributtverdien til både from-attributtet og id-attributtet er følgelig unikt for hvert element, da F1 i attributtverdien(e) i eksemplet over er koden for dramaet Fru Inger til Østeraad 1857. (Det enkelte verks verkkode er altså det innhold i attributtverdien som gjør elementet unikt.)
<xptr type="lemma" url="F1ht.xml" from="koF1_40" id="koF1_40"/>
Attributtverdien til type-attributtet (her "lemma") angir at dette er et lemmaelement. Attributtverdien til både from-attributtet og id-attributtet er følgelig unikt for hvert element, da F1 i attributtverdien(e) i eksemplet over er koden for dramaet Fru Inger til Østeraad 1857. (Det enkelte verks verkkode er altså det innhold i attributtverdien som gjør elementet unikt.)
kap-15.1.5.3.2: Internentiteter (&koK1_nr_intern;)
Entiteten &koK1_nr_intern; kobler en lemmakommentar til et annet lemma eller til innledningen i samme kommentarfil. En og samme intern-entitet kan følgelig forekomme flere ganger i samme kommentarfil ettersom det ofte finnes flere henvisninger til en og samme lemmakommentar.
De interne lemmaentitetene skriptes om til interne lemmaelementer så snart kommentarmaterialet er overført til XML. Selve entiteten (eksklusive amp-tegnet og semikolon) gjøres da om til attributtverdi i følgende xptr-element:
<xptr type="internal" url="F1ht.xml" from="koF1_85"/>
Attributtverdien til type-attributtet (her "internal") angir at dette er et internt lemmaelement. Attributtverdien til både from-attributtet er følgelig unikt for hvert element, da F1 i attributtverdien(e) i eksemplet over er koden for dramaet Fru Inger til Østeraad 1857. (Det enkelte verks verkkode er altså det innhold i attributtverdien som gjør elementet unikt.)
<xptr type="internal" url="F1ht.xml" from="koF1_85"/>
Attributtverdien til type-attributtet (her "internal") angir at dette er et internt lemmaelement. Attributtverdien til både from-attributtet er følgelig unikt for hvert element, da F1 i attributtverdien(e) i eksemplet over er koden for dramaet Fru Inger til Østeraad 1857. (Det enkelte verks verkkode er altså det innhold i attributtverdien som gjør elementet unikt.)
kap-15.1.5.3.3: HT-entiteter (= ht-referanser) (&koK1_ht_nr;)
Entiteten &koK1_ht_nr; kobler tekst i innledning eller lemmakommentar til hovedtekst.
ht-referansene/ht-elementene skriptes også om til elementer så snart kommentarmaterialet er overført til XML. Selve entiteten (eksklusive amp-tegnet og semikolon) gjøres da om til attributtverdi i følgende xptr-element:
<xptr type="ht" url="F1ht.xml" from="koF1_ht_1"/>
Attributtverdien til type-attributtet (her "ht") angir at dette er en/et ht-referanse/ht-element. Attributtverdien til både from-attributtet er følgelig unikt for hvert element, da F1 i attributtverdien(e) i eksemplet over er koden for dramaet Fru Inger til Østeraad 1857. (Det enkelte verks verkkode er altså det innhold i attributtverdien som gjør elementet unikt.)
<xptr type="ht" url="F1ht.xml" from="koF1_ht_1"/>
Attributtverdien til type-attributtet (her "ht") angir at dette er en/et ht-referanse/ht-element. Attributtverdien til både from-attributtet er følgelig unikt for hvert element, da F1 i attributtverdien(e) i eksemplet over er koden for dramaet Fru Inger til Østeraad 1857. (Det enkelte verks verkkode er altså det innhold i attributtverdien som gjør elementet unikt.)
kap-15.1.5.3.4: Om skripting av lemma-, intern- og HT-entiteter til elementer
Foreløpig legger vi inn lemmaentitetene ved hjelp av en Makro, se instruks for innstallering og kjøring av Makro under Arbeidsprosedyrer.
Deretter skriptes både lemmaentiteter, internentitetene og ht-entitetene om til xptr-elementer når materialet er overført til xml ved hjelp av perl-skriptet endre_lenken_1-1.pl, se mappen skript i kommentarbind-mappen i prosjekt-mappen. Der ligger også en bruksanvisning i wordformat.
Det bør vurderes om ikke Makroen som legger inn entiteter kunne legge inn elementer direkte for å unngå to operasjoner. Men man må da likevel skripte om ht- og intern-entitetene så sant vi ikke selv sørger for å manuelt legge inn disse som elementer med en gang slike koblinger opprettes i wordformat.
Deretter skriptes både lemmaentiteter, internentitetene og ht-entitetene om til xptr-elementer når materialet er overført til xml ved hjelp av perl-skriptet endre_lenken_1-1.pl, se mappen skript i kommentarbind-mappen i prosjekt-mappen. Der ligger også en bruksanvisning i wordformat.
Det bør vurderes om ikke Makroen som legger inn entiteter kunne legge inn elementer direkte for å unngå to operasjoner. Men man må da likevel skripte om ht- og intern-entitetene så sant vi ikke selv sørger for å manuelt legge inn disse som elementer med en gang slike koblinger opprettes i wordformat.
kap-15.1.6: Metrisk koding i kommentarfiler
<note type="metKomm"> skal omslutte enhver metrisk formel i kommentarfilen. Koden genererer ingen form for formatering, men den er nyttig for å kunne søke opp og kontrollere alle metriske formler i ett søk. Metrikkformler skal settes i kursiv og kodes derfor med <hi rend="italic">, men vær obs på at skanderingen (&bue; &metDash;) ikke skal kursiveres og derfor må stå utenfor hi-koden.
EKS: Drikkevisen har strofeformen <note type="metKomm"><hi rend="italic">tri 5 5 5 4 5 5 5 4 A A X x B B X x</hi></note>.
Alle forekomster av apostrofer i de metriske formlene skal kodes som entiteten &foot;
For buer i formlene brukes entiteten &bue;.
NB: Vi koder imidlertid ikke lenger streker i metrikkformlene med entiteten ‐. Metrikkstreken kodes med entiteten &metDash;.
Det skal være et mellomrom mellom buene og strekene. Minus- og plusstegn i bi- og bi+ trenger ikke entiteter, ev. har vi + for +.
NB: Vi koder imidlertid ikke lenger streker i metrikkformlene med entiteten ‐. Metrikkstreken kodes med entiteten &metDash;.
Det skal være et mellomrom mellom buene og strekene. Minus- og plusstegn i bi- og bi+ trenger ikke entiteter, ev. har vi + for +.
Opphøyde tall i metriske formler har entitetene ², ³ osv.
For koding av siterte verslinjer, se også under "Sitater" ovenfor.
kap-15.1.7: Listekoding i kommentarfiler
kap-15.1.7.1: Generelt
Alle listene i kommentarbindene omsluttes av <list type="standardList">. Rend-attributtet innenfor list-elementet angir hvorvidt listen skal ha redusert skrift og/eller settes i blokk:
<list type="standardList" rend="block_reduce">: i blokk og en grad mindre skrift
<list type="standardList" rend="block">: i blokk, men samme gradsstørrelse på skrift som øvrig tekst
<list type="standardList" rend="reduce">: redusert skriftsstørrelse, men ikke i blokk
Hver innførsel legges innenfor <item> som nummereres i et n-attributt ut fra antall innførsler i listen. Rend-attributtet angir avstand til forrige innførsel, standard her er 4 punkt: <item n="1" rend="4pt">. VIKTIG: Siste <item> skal ikke ha rend-attributt, da det ikke skal genereres 4punkts-avstand etter siste listeinnførsel.
Innenfor <item> plasseres <seg>-elementer, to for nummerering og ett for innholdet i innførselen.
Ev. tekst foran nummereringen plasseres mellom <seg type="numbering"> og <seg type="number">.
Dersom listen organiseres etter bokstaver, byttes attributtverdien <number> ut med <text> i det aktuelle <seg>-elementet.
Om den skal organiseres som unummererte punkter, bruk <seg type="number">·</seg>
Ev. tekst foran nummereringen plasseres mellom <seg type="numbering"> og <seg type="number">.
Dersom listen organiseres etter bokstaver, byttes attributtverdien <number> ut med <text> i det aktuelle <seg>-elementet.
Om den skal organiseres som unummererte punkter, bruk <seg type="number">·</seg>
Teksten i listeinnførselen plasseres innenfor <seg type="content">, som genererer 4mm innrykk fra venstre marg, mens nummereringen ikke har innrykk. Hvis man har behov for hengende innrykk av alt etter første linje i tillegg, kan man legge innførselen innenfor en ekstra <hi>: <seg type="content"><hi rend="hangIndent"> (se eksempel under "Oversettelser i Ibsens levetid" nedenfor).
Med tekst foran nummereringen:
<list type="standardList" rend="reduce">
<item n="1" rend="4pt">
<seg type="numbering">Nr. <seg type="number">1:</seg></seg>
<seg type="content"><quote>Bjergekongen red sig</quote> [Margits vise]</seg>
</item>
</list>
Uten tekst foran nummereringen:
<list type="standardList" rend="reduce">
<item n="1" rend="4pt">
<seg type="numbering"><seg type="number">1.</seg></seg>
<seg type="content">Deichmanske biblioteks eksemplar (*Ib8ca 1exp</seg>
</item>
</list>
Uten nummerering:
<list type="standardList" rend="reduce">
<item n="1" rend="4pt">
<seg type="content">tekat tekst tekst</seg>
</item>
</list>
Med unummererte punkter:
<list type="standardList" rend="reduce">
<item n="1" rend="4pt">
<seg type="number">·</seg>
<seg type="content">tekat tekst tekst</seg>
</item>
</list>
kap-15.1.7.2: Lister som forekommer ofte
kap-15.1.7.2.1: Eksemplarliste i Tekstkritisk redegjørelse
<list type="standardList" rend="reduce">
<item n="1" rend="4pt">
<seg type="numbering">
<seg type="number">1.</seg>
</seg>
<seg type="content">Deichmanske biblioteks eksemplar (*Ib8ca 1exp)</seg>
</item>
<item n="2" rend="4pt">
<seg type="numbering">
<seg type="number">2.</seg>
</seg>
<seg type="content">Et eksemplar i privat eie</seg>
</item>
<item n="3">
<seg type="numbering">
<seg type="number">3.</seg>
</seg>
<seg type="content">Et eksemplar i privat eie</seg>
</item>
</list>
Merk at rend="4pt" er fjernet i tredje og siste innførsel i listen over.
kap-15.1.7.2.2: Oversettelser i Ibsens levetid
<p rend="code">
<list type="standardList" rend="reduce">
<item n="1" rend="4pt">
<seg type="content"><hi rend="hangIndent">Ibsen, Henrik. <title rend="italic">Das Fest auf Solhaug</title></hi></seg>
</item>
kap-15.1.7.2.3: Lister i manuskriptbeskrivelser
I manuskriptbeskrivelsene i kommentarbindene forekommer det ofte nummererte avsnitt under overskriftene "Papir" og "Hender og skrift". Disse trenger ikke listekodes, men nummereres innenfor hver <p>. Hvis det bør være linjeskift rett etter overskriften og denne er en inline-overskrift, legges det inn en <lb/>. Nummeret og navnet settes i kursiv.
<head type="inline_smallCaps">hender og skrift.</head><lb/>
<p><hi rend="italic">1. Knud Knudsen</hi>: Se ovenfor.</p>
kap-15.1.7.2.4: Bidragsyterlisten
Bidragsyterlisten i kommentarbindene kodes som følger:
EKS:
<div type="introCommAuthors">
<list type="introCommAuthors">
<item n="1" ><hi rend="smallCaps">thoralf berg</hi></item>
<item n="2" ><hi rend="smallCaps">ståle dingstad</hi></item>
<item n="3" ><hi rend="smallCaps">narve fulsås</hi></item>
<item n="4" ><hi rend="smallCaps">nils grinde</hi></item>
<item n="5" ><hi rend="smallCaps">dag gundersen</hi></item>
<item n="6" ><hi rend="smallCaps">egil kraggerud</hi></item>
<item n="7" ><hi rend="smallCaps">else mundal</hi></item>
<item n="8" ><hi rend="smallCaps">erik mørstad</hi></item>
<item n="9" ><hi rend="smallCaps">tore rem</hi></item>
<item n="10" ><hi rend="smallCaps">olav solberg</hi></item>
<item n="11" ><hi rend="smallCaps">stine brenna taugbøl</hi></item>
<item n="12" ><hi rend="smallCaps">vigdis ystad</hi></item>
</list>
<p>Innledningen er ført i pennen av Vigdis Ystad, Stine Brenna Taugbøl
(<hi rend="italic">metrikk</hi>), Christian Janss (<hi rend="italic">Tekstkritisk redegjørelse</hi>)
og Tone Modalsli (<hi rend="italic">Manuskriptbeskrivelse</hi>).</p>
</div>
Dessuten må vi på grunn av FRIDA føre opp institusjonstilknytninger, jf. eksemplet nedenfor:
<p rend="noIndent"><hi rend="smallCaps">institusjonstilknytninger:</hi></p>
<p rend="noIndent">Christian Janss <hi rend="italic">Universitetet i Oslo, Senter for Ibsen-studier</hi></p>
<p rend="noIndent">Kristoffer Kruken <hi rend="italic">Universitetet i Oslo, Institutt for lingvistiske og nordiske studier</hi></p>
<p rend="noIndent">Else Mundal <hi rend="italic">Universitetet i Bergen, Senter for middelalderstudier</hi></p>
<p rend="noIndent">Erik Mørstad <hi rend="italic">Universitetet i Oslo, Institutt for filosofi, id- og kunsthistorie og klassiske språk</hi></p>
<p rend="noIndent">Henninge Margrethe Solberg <hi rend="italic">Universitetet i Oslo, Senter for Ibsen-studier</hi></p>
<p rend="noIndent">Stine Brenna Taugbøl <hi rend="italic">Universitetet i Oslo, Senter for Ibsen-studier</hi></p>
kap-15.1.8: Tabellkoding i kommentarfiler
kap-15.1.8.1: Tabell for sammenlikning av to eller flere tekstvitner
Ved behov for å sammenlikne flere tekstutdrag fra to ulike tekstvitner kodes eksemplene helst som tabell. Tabeller med denne funksjonen kodes med et rend-attributt med den beskrivende attributtverdien "compareText". Innenfor hvert <cell>-element i tabellen organiseres eksemplene fra ulike tekster ved hjelp av et n-attributt med verdien "compareNR". NR-et i attributtverdien angir hvilket tekstvitne det aktuelle tekstutdraget er hentet fra. I eksemplet nedenfor skiller vi dessuten de to tekstvitnene fra hverandre ved å markere tittelen på det ene tekstvitnet samt utdragene derfra med kursiv (<hi rend="italic">). På trykk vil linjene gis ulik format (kursiv/ikke kursiv) og legges ovenfor hverandre.
EKS:
<table rend="compareText">
<row>
<cell role="label" n="compare1">Catilina 1850</cell>
<cell role="label" n="compare2"><hi rend="italic">NBO Ms.4° 936</hi></cell>
</row>
<row>
<cell n="compare1">
<seg type="poem">det er forbi! mit Liv har intet Maal! – –<xref> (&koC1_ht_37;)</xref></seg>
</cell>
<cell n="compare2">
<seg type="poem"><hi rend="italic">det er fordi mit Liv har intet Maal.</hi> (1v)</seg>
</cell>
</row>
<row>
<cell n="compare1">
<seg type="poem">og haardt og tungt er Romas Herredom;</seg>
<seg type="poem">til Jorden fast dets Kuede det tynger</seg>
<seg type="poem">Thi komme vi som Bud jo fra vort Folk<xref>(&koC1_ht_39;;)</xref></seg>
</cell>
<cell n="compare2">
<seg type="poem"><hi rend="italic">og haardt og tungt er Romas Jernaag,</hi></seg>
<seg type="poem"><hi rend="italic">til Jorden ned den Kuede det tynger;–</hi></seg>
<seg type="poem"><hi rend="italic">thi kom vi hid, afsendte fra vort Folk,</hi> (2r)</seg>
</cell>
</row>
</table>
kap-15.1.9: MER OM INNHOLD I OG KODING AV BREVKOMMENTARBIND
ved Aasta Marie Bjorvand Bjørkøy 2004–2008
Brevkommentrabindene skiller seg fra dramakommentarbindene fordi de har en annen struktur og fordi de inneholder flere teksttyper samt ulike registre. Dette underkapitlet omhandler kun det som er spesifikt for brevkommentarbindene, men alt som vedrører detaljkoding m.m. ovenfor, gjelder også for brevkommentarbindene.
HIS' brevkommentarbind inneholder følgende overordnede <div>-er:
<div type="introduction" n="A"> – omslutter Innledning
<div type="lemmaCommentary" n="B"> – omslutter Ord- og sakkommentarer
<div type="regMentioned" n="C"> – omslutter registeret Omtalte personer
<div type="regRecipientsPers" n="D"> – omslutter registeret Brevmottagere (personer)
<div type="regRecipientsOrg" n="E"> – omslutter registeret Brevmottagere (inst. osv.)
<div type="chronicle" n="F"> – omslutter Tidstavle
<div type="regPersonsCommentaryfile" n="G"> – omslutter Personregister
Detaljkodingen (kodingen av titler, lister, sitater, ulik formatering etc.) er den samme i både drama- og brevkommentarbind. Struktur og innhold i brevkommentarbindene skiller seg imidlertid fra struktur og innhold i dramakommentarbindene. Under følger en oversikt over struktur og prosedyrer for bl.a. generering av personregister, koding og splitting av totalregisteret m.m.
kap-15.1.9.1: Kolumnetitler
Kodete kolumnetitler må legges inn i brevkommentarfilen på rett sted, dvs. rett innenfor den <div> som krever ny kolumnetittel, og før et eventuelt <head>-element. Ny kolumnetittel, ev. kolumnetitler dersom både venstre og høyre kolumnetittel skal endres, må legges inn foran hver nye teksttype (f.eks. Omtalte personer) i brevkommentarbindet.
Følgende kode omslutter en kolumnetittel (her den som skal stå på oppslagets høyre side): <fw type="header" place="rightPage">Brev 1865</fw>
Et noe mer utførlig kodeeksempel:
<div type="introduction" n="A"> <fw type="header" place="leftPage">Brev 1844–71</fw> <fw type="header" place="rightPage">Innledning</fw> <head rend="versal14">INNLEDNING</head>
Attributtverdiene "leftPage" og "rightPage" viser plassering av kolumnetittel innenfor oppslaget. I brevkommentarbindene er eksempelvis venstre kolumnetittel konstant Ord- og sakkommentarer i den delen av bindet som inneholder kommentarer, mens høyre kolumnetittel i denne delen skifter for hver gang et brev stammer fra et nytt årstall.
Siden kolumnetitlene først genereres av setteriet, og vi ikke kan vite om brev fra ulike årstall havner på en og samme side før teksten er satt, må setteriet generere eventuelle årstallspenn i kolumnetitlene av typen Brev 1854–55. Dette må dessuten kontrolleres av oss i satskorrekturen, da det ofte kan forekomme kommentarer til brev fra to ulike år på en og samme side uten at dette er justert av setter i kolumnetittelen.
Siden kolumnetitlene først genereres av setteriet, og vi ikke kan vite om brev fra ulike årstall havner på en og samme side før teksten er satt, må setteriet generere eventuelle årstallspenn i kolumnetitlene av typen Brev 1854–55. Dette må dessuten kontrolleres av oss i satskorrekturen, da det ofte kan forekomme kommentarer til brev fra to ulike år på en og samme side uten at dette er justert av setter i kolumnetittelen.
kap-15.1.9.2: BREVKOMMENTARER
Ord- og sakkommentarene tar for seg brev for brev i kronologisk rekkefølge. I overskriften til hvert enkelt brev blir det gjort rede for bl.a. årstall. Utover dette oppgis kun årstall i bindets kolumnetitler.
Mens alle ord- og sakommentarene som står til et drama i et dramakommentarbind kun omsluttes av et eneste <div>-element, omsluttes hvert enkelt brev av et eget <div>-element som har brevets ID-verdi (f.eks. B18770305FH) som attributtverdi. Dette <div>-elementet omslutter: brevets brevhode (= overskrift), en eventuell innledende kommentar og alle kommentarer til det aktuelle brevet.
EKS:
<div type="letterComm" id="B18440520PL">
Innenfor dette <div>-elementet kan det igjen forekomme i alt tre typer <div>-elementer:
1) brevhodet omsluttes av et eget <div>-element,
2) brevets innledende kommentar omsluttes av et eget <div>-element (dersom brevet har en innledende kommentar)
3) og alle lemmakommentarene omsluttes av et eget <div>-element.
Disse tre <div>-elementene er nummerert B1, B2 og B3 og har dessuten unike attributtverdier som skiller dem fra hverandre.
NB: i HIS 12k omslutter imidlertid <div type="lemmaCommentary" n="B3"> hver enkelt lemmakommentar. Dette er unødig og forenkles derfor i strukturen for annet brevkommentarbind, HIS 13k (jf. xml-mal for den kommende xml-filen til 13k, se dette bindets mappe i Prosjekt-mappen).
Disse tre <div>-elementene er nummerert B1, B2 og B3 og har dessuten unike attributtverdier som skiller dem fra hverandre.
NB: i HIS 12k omslutter imidlertid <div type="lemmaCommentary" n="B3"> hver enkelt lemmakommentar. Dette er unødig og forenkles derfor i strukturen for annet brevkommentarbind, HIS 13k (jf. xml-mal for den kommende xml-filen til 13k, se dette bindets mappe i Prosjekt-mappen).
Utover dette kodes selve lemmakommentarene likt som i dramakommentarbindene.
Kodeeksempel på den enhet som står til ett brev (brevhode, innledende kommentar og ord- og sakkommentarer):
<div type="letterComm" id="B18650120SF"> <div type="letterHead" n="B1"> <label rend="italic"><name>Til Den Skandinaviske Forening i Roma,</name> <placeName>Roma</placeName> <date>20. januar 1865</date></label> </div> <div type="lettersIntroComm" n="B2"> <p rend="noIndent">EVENTUELL INNLEDENDE KOMMENTAR INN HER</p> </div> <div type="lemmaCommentary" n="B3"> <list type="commentary"> <item n="1"><xptr type="lemma" url="B12ht.xml" from="koB12_865" id="koB12_865"/></item> <item n="2">Foreningens Loves</item> <item n="3"><p rend="noIndent">tekst tekst tekst</p> </item></list> <list type="commentary"> <item n="1"><xptr type="lemma" url="B12ht.xml" from="koB12_866" id="koB12_866"/></item> <item n="2">danske Slesvigere</item> <item n="3"><p rend="noIndent">tekst tekst tekst</p> </item></list> <list type="commentary"> <item n="1"><xptr type="lemma" url="B12ht.xml" from="koB12_867" id="koB12_867"/></item> <item n="2">Tydskere kunne ikke indføres</item> <item n="3"><p rend="noIndent">tekst tekst tekst</p> </item></list> </div> </div> <!--B18650120SF slutt-->
kap-15.1.9.2.1: Brevhoder
Hvert brev innledes med et brevhode, dvs. en overskrift som redegjør for mottagers navn, sted og dato. Mottager kodes med elementet <name>, stedsnavn med elementet <placeName> og dato og årstall med elementet <date>.
Husk å legge inn "Til" før og et komma etter mottagers navn, alt plassert innenfor <name>-elementet. Sikre også at eventuelle mellomrom ligger inne mellom elementene da eventuelle mellomrom mellom de ulike leddene i brevhodet ikke genereres automatisk av setteriet:
EKS på kodet brevhode:
<div type="letterHead" n="B1">
<label rend="italic"><name>Til Den Skandinaviske Forening i Roma,</name> <placeName>Roma</placeName> <date>20. januar 1865</date></label>
</div>
kap-15.1.9.3: TOTALREGISTER
ved Aasta Marie Bjorvand Bjørkøy 2004–2008
NB: Etter satskorrektur av brevkommentarbind, må man alltid huske å også oppdatere eventuelle rettelser i XML-filen til totalregisteret, og ikke kun oppdatere de splittede registrene i den aktuelle brevkommentarbind-xml-en.
Biograferte personer i totalregisteret er enten brevmottager eller omtalt i Ibsens brev eller også kanskje begge deler. Hvorvidt en person er kun en av delene eller begge deler kan vi i totalregisteret se ut fra innholdet i <div type="letterlist"> i xml-filen. Dersom både <list type="mentioned_letter"> og <list type="recipient_letter">i denne <div>-en har innhold, vil det si at vedkommende er både omtalt og brevmottager.
Denne brevlisten viser hvilke brev den biograferte er omtalt i og/eller mottager av. Brevreferansen til de brev vedkommende er omtalt i skal bestå av navnet på brevets mottager samt dato, satt opp som følger: F. Hegel 25/3 1865. Brevreferansen til brev som vedkommende er mottager av, får imidlertid den noe enklere referansen som kun består av brevets dato, f.eks.: 25/8 1858
Denne brevlisten viser hvilke brev den biograferte er omtalt i og/eller mottager av. Brevreferansen til de brev vedkommende er omtalt i skal bestå av navnet på brevets mottager samt dato, satt opp som følger: F. Hegel 25/3 1865. Brevreferansen til brev som vedkommende er mottager av, får imidlertid den noe enklere referansen som kun består av brevets dato, f.eks.: 25/8 1858
<div type="letterlist">
<list type="mentioned_letter">
<item>Stortinget 25/10 1859</item>
</list>
<list type="recipient_letter">
<item>10/2 1870</item>
<item>12/5 1870</item>
<item>26/6 1870</item>
</list>
</div>
XML-filen til totalregisteret å finne i mappen Totalregister, under mappen Kommentarbind. Herunder er det, for sikkerhets skyld, og for ryddigheten, opprettet en mappe for 12k-totalregisteret, en for det totalregister som inneholder både 12k og 13k osv. Følg opp dette systemet, se opprettede mapper. Totalregister-filen må oppdateres så snart et nytt brevkommentarbind foreligger i ferdig form, dvs. umiddelbart etter at satskorrekturen er ferdigstilt. Oppdateringen er komplisert pga. totalregisterets struktur, såden ansvarlige manusredaktør må oppdatere, ikke student. Skal student brukes, må denne ha xml-kompetanse, og manusredaktør må først selv oppdatere for alle mottagere og omtalte som allerede foreligger i totalregisteret, da denne oppdateringen krever nøyaktighet fordi div-elementer må kompletteres, man må forstå strukturen osv. Deretter KAN en assistent klippe inn biografiene til alle NYE mottagere og omtalte fra en kopifil av det aktuelle brevkommentarbindfilen og inn i Totalregister.xml, se egen instruk for dette i den ovenfor nevnte totalregister-mappen, samt i dokumentet "Arbeidsprosedyrer for kommentararbeid".
PRAKSIS FOR ARBEIDET MED REGISTRENE I 13k, 14k og 15k. Nye prosedyrer:
I arbeidet med 12k måtte vi samle både omtalte personer og brevmottagere i Totalregisteret, for deretter å splitte i tre registre etter at alle rettelser var lagt inn, rett før sending til setteriet. I arbeidet med 13k, 14k og 15k vil vi derimot gå motsatt vei: Omtalte personer og brevmottagere foreligger i hver sine filer når de parses. Vi må så lime inn de nye innførslene i Totalregisteret, samt lime inn innholdet i <div type="bioText"> og <div type="letterlist"> til de som allerede foreligger som mottager og/eller omtalt inn i Totalregisteret. Dette kan like gjerne gjøres etter at 13k er sendt til setteriet, og VIKTIG: etter at satskorrekturrettelser er lagt inn. Dette letter arbeidet siden vi da slipper å få laget nye, ev. justert, splittingsstilarkene. I tillegg slipper vi å legge inn satskorrekturrettelser to steder (både i de splittede registrene i brevkommentarfilen og i totalregisterfilen). Vi slipper samtidig å samle opp spesielle innførsler av typen "Navn se navn" og legge dem inn i bokutgave-xml-en rett før sending. Da slipper vi problemet vedr. innholdet i ShortDescription, for alt innholdet i ShortDescription må med i Totalregisteret, men bare deler av innholdet gjelder for den enkelte bokutgave. Det alene gjøre det vanskelig å samle alle registrene i Totalregisteret for deretter å splitte. Ergo: Å jobbe med tre filer og deretter samle alt helt til slutt er mer effektivt, selv om vi da må legge inn og oppdatere Totalregisterfilen i henhold til det nye brevkommentarbindet først etter at satskorrekturen er ferdig.
I arbeidet med 12k måtte vi samle både omtalte personer og brevmottagere i Totalregisteret, for deretter å splitte i tre registre etter at alle rettelser var lagt inn, rett før sending til setteriet. I arbeidet med 13k, 14k og 15k vil vi derimot gå motsatt vei: Omtalte personer og brevmottagere foreligger i hver sine filer når de parses. Vi må så lime inn de nye innførslene i Totalregisteret, samt lime inn innholdet i <div type="bioText"> og <div type="letterlist"> til de som allerede foreligger som mottager og/eller omtalt inn i Totalregisteret. Dette kan like gjerne gjøres etter at 13k er sendt til setteriet, og VIKTIG: etter at satskorrekturrettelser er lagt inn. Dette letter arbeidet siden vi da slipper å få laget nye, ev. justert, splittingsstilarkene. I tillegg slipper vi å legge inn satskorrekturrettelser to steder (både i de splittede registrene i brevkommentarfilen og i totalregisterfilen). Vi slipper samtidig å samle opp spesielle innførsler av typen "Navn se navn" og legge dem inn i bokutgave-xml-en rett før sending. Da slipper vi problemet vedr. innholdet i ShortDescription, for alt innholdet i ShortDescription må med i Totalregisteret, men bare deler av innholdet gjelder for den enkelte bokutgave. Det alene gjøre det vanskelig å samle alle registrene i Totalregisteret for deretter å splitte. Ergo: Å jobbe med tre filer og deretter samle alt helt til slutt er mer effektivt, selv om vi da må legge inn og oppdatere Totalregisterfilen i henhold til det nye brevkommentarbindet først etter at satskorrekturen er ferdig.
PRAKSIS FOR ARBEIDET MED REGISTRENE I 12k, 2005:
Totalregisteret inneholder både omtalte personer og brevmottagere (personer, institusjoner m.m.). Totalregisteret er utviklet for HIS' elektroniske utgave. Og det er denne som så danner utgangspunkt for de tre registrene OMTALTE PERSONER, BREVMOTTAGERE (pers.) og BREVMOTTAGERE (inst. m.m.). Av den grunn samles og kodes både omtalte og mottagere i totalregisteret. Når totalregisteret så er komplett og ferdig kodet og alle rettelser er lagt inn, splittes totalregisteret i de tre nevnte registre, slik de skal trykkes i bokutgaven. Splittingen gjøres ved hjelp av egne splittingsstilark (register_o.xml og register_m.xml, se egen stilark-mappe og splitt via Command Prompt). Bruksanvisning for splittingen er å finne i mappen Splitting i 13k-mappen. For å sikre at innholdet i totalregisteret og de tre registrene for bokutgaven er identiske, bør splittingen (eller den siste og da gjeldende splittingen) først skje etter at all korrektur er lagt inn i totalregisteret. Dette for å unngå at man må legge inn rettelser to steder: både i totalregisteret og i de tre registrene, som jo opprinnelig foreligger i totalregisteret. Splitt altså totalregisteret rett før levering til setteriet (men kontroller at operasjonen fungerer i god tid på forhånd). NB: Registeret Brevmottagere (institusjoner, organisasjoner, bedrifter) må imidlertid hentes ut manuelt. Bare kopier, det ligger i eget div-element, og lim inn på rett sted i brevkommentar-filen. Dette er veldig greit å gjøre slik, da dette registeret er både lite og oversiktlig og ikke er blandet, slik som omtalte personer og personlige brevmottagere (som jo er kodet sammen i totalregisteret).
Totalregisteret inneholder både omtalte personer og brevmottagere (personer, institusjoner m.m.). Totalregisteret er utviklet for HIS' elektroniske utgave. Og det er denne som så danner utgangspunkt for de tre registrene OMTALTE PERSONER, BREVMOTTAGERE (pers.) og BREVMOTTAGERE (inst. m.m.). Av den grunn samles og kodes både omtalte og mottagere i totalregisteret. Når totalregisteret så er komplett og ferdig kodet og alle rettelser er lagt inn, splittes totalregisteret i de tre nevnte registre, slik de skal trykkes i bokutgaven. Splittingen gjøres ved hjelp av egne splittingsstilark (register_o.xml og register_m.xml, se egen stilark-mappe og splitt via Command Prompt). Bruksanvisning for splittingen er å finne i mappen Splitting i 13k-mappen. For å sikre at innholdet i totalregisteret og de tre registrene for bokutgaven er identiske, bør splittingen (eller den siste og da gjeldende splittingen) først skje etter at all korrektur er lagt inn i totalregisteret. Dette for å unngå at man må legge inn rettelser to steder: både i totalregisteret og i de tre registrene, som jo opprinnelig foreligger i totalregisteret. Splitt altså totalregisteret rett før levering til setteriet (men kontroller at operasjonen fungerer i god tid på forhånd). NB: Registeret Brevmottagere (institusjoner, organisasjoner, bedrifter) må imidlertid hentes ut manuelt. Bare kopier, det ligger i eget div-element, og lim inn på rett sted i brevkommentar-filen. Dette er veldig greit å gjøre slik, da dette registeret er både lite og oversiktlig og ikke er blandet, slik som omtalte personer og personlige brevmottagere (som jo er kodet sammen i totalregisteret).
kap-15.1.9.3.1: Navnekoding i totalregisteret
Alle navnene omsluttes av elementet <persName>.
Fornavn og eventuelle mellomnavn kodes med elementet <foreName>.
Etternavn kodes med elementet <surname>.
Kongenavn o.l. kodes med elementet <name>.
<name>-elementet brukes til å kode navn, først og fremst kongenavn, da disse navnene gjerne ikke har et etternavn, men likevel består av flere navn som skal settes/vises fortløpende; de skal sorteres etter første fornavn. Enkelte ganger skal det stå kommentar eller forklaring til selve navnet e.l. som også gjør det vanskelig å kode det aktuelle navnet ordinært. Alle slike særtilfeller, som ikke er forenlige med de automatiske genereringer eller de spesifikasjoner som gjelder for de ulike navne-kodene, kodes derfor i <name>. Se ulike eksempler under:
Fornavn og eventuelle mellomnavn kodes med elementet <foreName>.
Etternavn kodes med elementet <surname>.
Kongenavn o.l. kodes med elementet <name>.
<name>-elementet brukes til å kode navn, først og fremst kongenavn, da disse navnene gjerne ikke har et etternavn, men likevel består av flere navn som skal settes/vises fortløpende; de skal sorteres etter første fornavn. Enkelte ganger skal det stå kommentar eller forklaring til selve navnet e.l. som også gjør det vanskelig å kode det aktuelle navnet ordinært. Alle slike særtilfeller, som ikke er forenlige med de automatiske genereringer eller de spesifikasjoner som gjelder for de ulike navne-kodene, kodes derfor i <name>. Se ulike eksempler under:
EKS. 1: <name><hi rend="smallCaps">karl 15.</hi>, i den norske kongerekke senere betegnet <hi rend="smallCaps">karl 4.</hi> (Carl Ludvig Eugne)</name>
EKS. 2: <name>Louise (<hi rend="smallCaps">lovisa</hi>) Vilhelmina Fredrika Alexandra Anna</name>
NB: Koding av initialer: Initialer må plasseres innenfor ett og samme element, ellers vil det genereres mellomrom mellom initialene. Navnet M.A. Stangby kodes følgelig slik:
<foreName n="1">M.A.</foreName>
<surname>Stangby</surname>
I registrene skal ofte mottagers navn eller den omtaltes navn, eventuelt kun deler av navnet utheves; dette for å vise hvilke av navnene, ev. deler av navnene som var de mest frekvente; hvilke (deler) av navnene personen selv brukte i det daglige. De utheves ved at de settes som kapiteler. Dette må kodes med et rend-attributt og attributtverdien "smallCaps", som følger (husk at bokstaver som skal settes som kapiteler må være i minuskler i xml-filen):
<persName>
<foreName n="1">Hans</foreName>
<foreName n="2" rend="smallCaps">jørgen</foreName>
<foreName n="3" rend="smallCaps">christian</foreName>
<surname rend="smallCaps">aall</surname>
</persName>
Som i eksemplet over inneholder <foreName>-elementet i tillegg et n-attributt med henholdsvis attributtverdiene 1, 2, 3 osv. Attributtverdiene angir da rekkefølgen på de ulike fornavnene/mellomnavnene.
Både stilarket (som genererer html-visning) og når registrene settes, sorteres personene etter </surname>-elementet, eventuelt etter <name>-elementet. I tillegg genererer da </surname>-elementet et komma samt ettterfølgende mellomrom før de ulike <foreName>-elementene så blir vist, eller satt, i korrekt rekkefølge. Eventuelle mellomrom mellom de ulike kodene som omsluttes av <persName>-elementet legges følgelig ikke inn av oss manuelt, de genereres automatisk ved setting (eller av stilarket når vi lager visning).
kap-15.1.9.3.2: Koding av fødsels- og dødsår
Dersom elementet <dateRange> er tomt fordi vi ikke kjenner fødsels- eller dødsår for vedkommende, utelater vi elementet <dateRange> samt det <item>-elementet som omslutter <dateRange>.
<item>
<dateRange from="xxxx" to="xxxx">xxxx–xx</dateRange>
</item>
kap-15.1.9.3.3: OMTALTE PERSONER
Omtalte personer er et register over alle personer som er omtalt i Ibsens brev. Dette registeret gjør rede for navn, fødsels- og dødsår, personenes biografi, samt hvilke av Ibsens brev vedkommende er omtalt i. Personer som kun er omtalt i Ibsens brev (og altså ikke også brevmottager) får full oppføring i omtaltregisteret, heretter kalt TYPE-1-oppføring.
EKS på kodestruktur og detaljkoding for TYPE-1-oppføringer i omtaltregisteret:
<div type="person" corresp="peHJCA" rend="aall">
<div type="person_header">
<list>
<item>
<rs type="person" corresp="peHJCA">
<persName>
<foreName n="1">Hans</foreName>
<foreName n="2" rend="smallCaps">jørgen</foreName>
<foreName n="3" rend="smallCaps">christian</foreName>
<surname rend="smallCaps">aall</surname>
</persName>
</rs>
</item>
<item>
<dateRange from="1806" to="1894">1806–94</dateRange>
</item>
</list>
</div>
<div type="1845_1906">
<div type="Bb1_to1871">
<div type="briefDescription">
<p rend="noIndent">norsk embetsmann og politiker.</p>
</div>
</div>
<div type="bioText">
<p rend="noIndent">1829–46 i Bergen, fra 1838 som assessor. Fra 1846 amtmann i Bratsberg. [...]</p>
</div><--SLUTT Bb1_to1871-->
<div type="Bb2_to1879">
<div type="bioText">
<p rend="noIndent">TEKST TEKST TEKST</p>
</div><--SLUTT Bb2_to1879-->
<div type="letterlist">
<list type="mentioned_letter">
<item>Stortinget 25/10 1859</item>
<item>F.Hegel 23/10 1877</item>
</list>
</div>
</div><--SLUTT 1845_1906-->
</div>
Dersom en person er både omtalt i og mottager av Ibsens brev, skal vedkommende kun ha en henvisningsoppføring i omtaltregisteret (heretter kalt TYPE-2-oppføring), mens vedkommende har full oppføring med biografi i mottagerregisteret. De enkle henvisningsoppføringene genereres automatisk av stilarket register_o.xsl som henter ut alle omtalte personer fra totalregisteret.
Denne typen henvisningsoppføringer er kun aktuelle i bokutgavens omtaltregister og ikke i e-utgavens totalregister hvor man kan lese ut fra innholdet i <div type="letterlist"> hvorvidt personen er både omtalt og mottager eller kun en av delene.
Denne typen henvisningsoppføringer er kun aktuelle i bokutgavens omtaltregister og ikke i e-utgavens totalregister hvor man kan lese ut fra innholdet i <div type="letterlist"> hvorvidt personen er både omtalt og mottager eller kun en av delene.
EKS på TYPE-2-oppføring:
<div type="person" corresp="peJPA" rend="andresen">
<div type="person_header">
<list>
<item>
<rs type="person" corresp="peJPA" rend="normal">
<persName>
<foreName n="1" rend="smallCaps">jens</foreName>
<foreName n="2" rend="smallCaps">peter</foreName>
<surname rend="smallCaps">andresen</surname>
</persName>
</rs>
</item>
</list>
</div>
<div type="regReference">
<p>se brevmottagere.</p>
</div>
<div type="Bb1_to1871">
<div type="letterlist">
<list type="mentioned_letter">
<item>J.H. Thoresen 8/3 1870</item>
</list>
</div>
</div>
</div>
kap-15.1.9.3.4: BREVMOTTAGERE (personer)
Brevmottagere (personer) er et register over alle personer som er mottager av Ibsens brev. Dette registeret gjør rede for navn, fødsels- og dødsår, personenes biografi, samt hvilke av Ibsens brev vedkommende er mottager av.
<div type="person" corresp="peJPA" rend="andresen">
<div type="person_header">
<list>
<item>
<rs type="person" corresp="peJPA">
<persName>
<foreName n="1" rend="smallCaps">jens</foreName>
<foreName n="2" rend="smallCaps">peter</foreName>
<surname rend="smallCaps">andresen</surname>
</persName>
</rs>
</item>
<item>
<dateRange from="1818" to="1871">1818–71</dateRange>
</item>
</list>
</div>
<div type="1845_1906">
<div type="Bb1_to1871">
<div type="briefDescription">
<p rend="noIndent">norsk advokat.</p>
</div>
<div type="bioText">
<p rend="noIndent">1840 juridisk embetseksamen. Fra 1858 høyesterettsadvokat. [...]</p>
</div>
</div><--SLUTT Bb1_to1871-->
<div type="letterlist">
<list type="recipient_letter">
<item>10/2 1870</item>
<item>12/5 1870</item>
<item>26/6 1870</item>
</list>
</div>
</div><--SLUTT 1845_1906-->
</div>
I enkelte tilfeller ønsker vi å legge inn enkle navnehenvisninger i registrene Omtalte personer og Brevmottagere (personer). Det er nødvendig og ønskelig dersom en person er kjent under flere navn (eller flere skrivemåter av navnet), samt dersom en kvinne figuerer som omtalt eller mottager både før og etter at hun har giftet seg. I så fall legger vi inn en enkel navnehenvisning, jf. eksemplene under. Denne navnehenvisningen må (i hvert fall foreløpig) legges inn manuelt i både omtalt- og mottagerregisteret da de to splittingsstilarkene hittil ikke henter ut denne typen navnehenvisninger fra totalregisteret under splittingen. (Dette fordi det har vært usikkerthet rundt hvorvidt navnehenvisningene kun skulle inngå i bokutgavens registre eller også foreligge i totalregisteret.)
EKS 1:
<div type="person" corresp="peKongK4">
<div type="person_header">
<list>
<item>
<rs type="person" corresp="peKongK4" rend="normal">
<persName>
<name rend="smallCaps">carl 15.</name>
</persName>
</rs>
</item>
</list>
</div>
<div type="regReference">
<p rend="noIndent">se <hi rend="smallCaps">karl 15.</hi></p>
</div>
</div>
EKS 2:
<div type="person" corresp="peLW">
<div type="person_header">
<list>
<item>
<rs type="person" corresp="peLW" rend="normal">
<persName>
<foreName n="1" rend="smallCaps">lucie</foreName>
<surname rend="smallCaps">johannessen</surname>
</persName>
</rs>
</item>
</list>
</div>
<div type="regReference">
<p rend="noIndent">se <hi rend="smallCaps">wolf</hi>, Karen <hi rend="smallCaps">lucie</hi></p>
</div>
</div>
kap-15.1.9.3.6: BREVMOTTAGERE (institusjoner, organisasjoner, bedrifter)
Brevmottagere (inst. osv.) er et register over alle institusjoner, organisasjoner, bedrifter som er mottager av Ibsens brev. Dette registeret gjør rede for (skrivemåten av) institusjonsnavn, omtale av institusjonen, samt hvilke av Ibsens brev den enkelte institusjon er mottager av.
<div type="organisations" corresp="orgAftb">
<div type="institution_header">
<list>
<item>
<rs type="institution" corresp="orgAftb">
<persName><name rend="smallCaps">aftenbladet</name></persName>
</rs>
</item>
</list>
</div><!--slutt person_header-->
<div type="1845_1906">
<div type="Bb1_to1871">
<div type="briefDescription">
<p rend="noIndent">norsk avis.</p>
</div>
<div type="bioText">
<p rend="noIndent">Utgitt i Kristiania 1855–81 [...]</p>
</div>
</div><--SLUTT Bb1_to1871-->
<div type="letterlist">
<list type="recipient_letter">
<item>5/12 1860</item>
</list>
</div>
</div><--SLUTT 1845_1906-->
</div>
kap-15.1.9.4: TIDSTAVLE
ved Aasta Marie Bjorvand Bjørkøy 2004–2008
Tidstavlen gjør kronologisk rede for viktige hendelser i Ibsens liv, utgivelser, premierer, bosted o.l.
Tidstavlen kodes som en liste: Den skal settes blokkjustert, men skriften skal ikke være redusert (derfor attributtverdien "block", se eksemplet under).
<div type="chronicle" n="F">
<fw type="header" place="rightPage">Tidstavle</fw>
<head rend="versal14">HENRIK IBSEN</head>
<div type="Bb1_to1871">
<head rend="centre_smallCaps">tidstavle mars 1844 – juni 1871</head>
<div type="place">
<head rend="12,5" n="first">STED (ÅRSTALL)</head>
<list type="standardList" rend="block">
<head rend="10,5" n="first"><hi rend="indent_4mm">1871</hi></head>
<item n="1" rend="4pt"><date><hi rend="italic">DATO</hi></date> tekst tekst tekst</item>
<item n="2"><date><hi rend="italic">DATO</hi></date> tekst tekst tekst</item>
</list>
<list type="standardList" rend="block">
<head rend="10,5"><hi rend="indent_4mm">ÅRSTALL</hi></head>
<item n="1"><date><hi rend="italic">DATO</hi></date> tekst tekst tekst</item>
</list>
<list type="standardList" rend="block">
<head rend="10,5"><hi rend="indent_4mm">ÅRSTALL</hi></head>
<item n="1" rend="4pt"><date><hi rend="italic">DATO</hi></date> tekst tekst tekst</item>
<item n="2" rend="4pt"><date><hi rend="italic">DATO</hi></date> tekst tekst tekst</item>
<item n="3" rend="4pt"><date><hi rend="italic">DATO</hi></date> tekst tekst tekst</item>
<item n="4"><date><hi rend="italic">DATO</hi></date> tekst tekst tekst</item>
</list>
</div>
</div>
<!-- slutt Bb1_to1871-->
I tidstavlen opererer vi med et <list>-element for hvert år. Innenfor <list>-elementet omsluttes så hver enkelt oppføring i tidstavlen av et <item>-element. <item>-elementene inneholder et n-attributt som angir nummereringen: <item n="1">, <item n="2">, <item n="3"> osv.
Mellom hver innførsel (= etter hvert <item>-element) i listen skal det genereres et mellomrom på 4pt. <item>-elementet får derfor, i tillegg til et n-attributt som angir listenummereringen, et rend-attributt med attributtverdien "4pt": <item n="1" rend="4pt">
NB: Etter siste <item>-innførsel i listen skal det imidlertid IKKE genereres 4pt etter innførselen. I siste <item>-innførsel i hver liste utelater vi derfor rend="4pt" i <item>-elementet. Se eksemplet over.
NB: Etter siste <item>-innførsel i listen skal det imidlertid IKKE genereres 4pt etter innførselen. I siste <item>-innførsel i hver liste utelater vi derfor rend="4pt" i <item>-elementet. Se eksemplet over.
Dersom innførselen innledes med dato, kodes datoen med et <date>-element. Datoen skal stå i kursiv, og kodes derfor dessuten med et <hi>-element med attributtveriden "italic" som angir at innholdet skal kursiveres: <hi rend="italic">.
NB: DERSOM date-elementet tillater et rend-attributt, kunne man forenkle til: <date rend="italic">
NB: DERSOM date-elementet tillater et rend-attributt, kunne man forenkle til: <date rend="italic">
kap-15.1.9.4.1: Koding av overskrifter i tidstavlen
Jf. kodeeksemplet over kodes de to hovedoverskriftene til tidstavlen med henholdsvis <head rend="versal14"> og <head rend="centre_smallCaps">.
Tidstavlen er organisert etter Ibsens bosted og derunder etter årstall. Både bostedet og årstallene fungerer som overskrifter på ulike nivåer og kodes som følger:
Tidstavlen er organisert etter Ibsens bosted og derunder etter årstall. Både bostedet og årstallene fungerer som overskrifter på ulike nivåer og kodes som følger:
KODING AV STEDSOVERSKRIFTER: Første stedsoverskrift i tidstavlen kodes som følger: <head rend="12,5" n="first">STED (ÅRSTALL)</head> NB: Den første stedsoverskriften settes annerledes enn de etterfølgende stedsoverskriftene (den settes i 12,5/52) og inneholder derfor et n-attributt med attributtverdien "first" (n="first"). De øvrige stedsoverskriftene i tidstavlen kodes som følger (UTEN n="first"), da de settes i 12,5/26: <head rend="12,5">STED (ÅRSTALL)</head>
KODING AV ÅRSTALLSOVERSKRIFTER: Første årstalls-overskrift i tidstavlen kodes som følger: <head rend="10,5"><hi rend="indent_4mm">ÅRSTALL</hi></head> NB: Den første årstallsoverskriften settes annerledes enn de etterfølgende årstallsoverskriftene (den settes i 10,5/17) og inneholder derfor et n-attributt med attributtverdien "first" (n="first") De øvrige årstallsoverskriftene i tidstavlen kodes som følger (UTEN n="first"), da de settes i 10,5/22: <head rend="10,5" n="first"><hi rend="indent_4mm">1871</hi></head>
I tillegg kodes årstallene med et <hi>-element som har attributtverdien "indent_4mm" <hi rend="indent_4mm"> da årstallsoverskriften skal settes med et 4 millimeters innrykk.
kap-15.1.9.5: PERSONREGISTER
ved Aasta Marie Bjorvand Bjørkøy 2004–2008
Personregisteret er et enkelt navneregister som viser på hvilke sider ulike personer omtales i det aktuelle brevkommentarbindet. Personregisteret er sortert alfabetisk etter de omtaltes etternavn. Det inneholder sidehenvisninger til hvor den aktuelle personen omtales i kommentarbindet. Personregisteret genereres automatisk av setteriet v.hj.a. ID-basen og HIS' personkoding i brevkommentarbindet.
Det er lurt å be setteriet om å generere en første utkjøring av personregisteret så snart det er mulig (helst før første satskorrektur). (Dette forutsetter selvfølgelig at alle personer er kodet og at ID-basen er oppdatert). Slik vil manusredaktør og hovedredaktør på et tidlig stadium kunne avsløre eventuelle dubleringer og øvrige feil som man kun tilfeldig vil kunne oppdage i en kontroll av ID-basen.
For kontroll av skrivemåten av personnavn er det dessuten hensiktsmessig å hente ut alle personer som er rs-kodet og få navnene sortert alfabetisk som en liste. Det kan gjøres ved hjelp av stilarket sort_rs.xsl. I denne kontrollen oppdager man lett inkonsekvens og feil i skrivemåten av navn da feil og ulikheter blir lett synlige når alle forekomstene av ett navn ramses opp under hverandre.
kap-15.1.9.5.1: Forarbeid for personkoding og oppretting av personregisteret
1. Gul ut alle personer (på papir) som er omtalt i innledningen, i lemmakommentarene, i tidstavlen og i biografiene i totalregisteret. (NB: Kun første forekomst i hver kommentar og i hver biografi.)
- Ikke gul ut fiktive personer, eller f.eks. "Neros villa", "bysten av Titus" osv.
- Ikke gul ut Ibsen selv eller pseudonymet Brynjolf Bjarme
- Ikke gul ut/kode personene når de står nevnt i en henvisning av typen: "jf. kommentar til ...", "jf. brev til XX", "av brev til XX". Det er overflødig å trekke ut dette i personregisteret; det skal ikke gjøre rede for henvisninger til henvisninger.
- Referansepersoner, f.eks. Molbech, skal ikke kodes.
2. Søk opp personene i ID-basen.
- Dersom du finner rett person: notér ID-verdi, f.eks.: peBB for Bjørnstjerne Bjørnson, i margen ved siden av den omtalte, utgulede personen.
3. Dersom personen ikke er registrert i ID-basen: Registrer vedkommende, MEN vær sikker på at vedkommende ikke allerede er lagt inn.
VIKTIG tips for søk: Søk på etternavn alene (eller deler av etternavnet), deretter ev. fornavn, og ikke både etternavn og fornavn samtidig da personen kan være registrert med initialer og ikke fornavn. Sikre også at søket ikke er for unikt, slik at du ikke vil få treff på personen dersom noen allerede har registrert vedkommende, men har skrevet navnet feil.
VIKTIG tips for søk: Søk på etternavn alene (eller deler av etternavnet), deretter ev. fornavn, og ikke både etternavn og fornavn samtidig da personen kan være registrert med initialer og ikke fornavn. Sikre også at søket ikke er for unikt, slik at du ikke vil få treff på personen dersom noen allerede har registrert vedkommende, men har skrevet navnet feil.
4. De utgulede personene kodes i brevkommentarfilen og totalregisterfilen (se under, kap 1.9.4.2)
kap-15.1.9.5.2: Personkoding i innledning, kommentarer og tidstavlen
I innledningen, i kommentarene og i tidstavlen i brevkommentarbindene kodes alle omtalte personer med følgende kode: <rs type="person_Comm" corresp="peXX">.
EKS: <rs type="person_Comm" corresp="peLD">Lorentz Dietrichson</rs>
Dersom en og samme person omtales flere ganger i en kommentar, kodes kun første forekomst av personens navn. I innledningen kodes imidlertid ALLE forekomster selv om samme person kanskje omtales fem ganger i samme avsnitt. Dette fordi vi ikke vet hvor sideskift vil inntreffe før teksten er satt. Det er så opp til setteriet å sikre at det i personregisteret kun henvises til ett og samme sidetall for hvor en person omtales.
I totalregisteret kodes alle personer med følgende kode: <rs type="person_Reg" corresp="peXX">.
EKS: <rs type="person_Reg" corresp="peBB">Bjørnson</rs>
Dersom en og samme person omtales flere ganger i en og samme biografi, kodes kun første forekomst av personens navn.
Det er viktig at personkodingen finner sted i totalregisteret før siste splitting i tre registre for bokutgaven. Dette for å unngå dobbeltarbeid.
kap-15.1.9.5.4: Hvordan generere personregisteret
<rs>-kodens corresp-attributt har personenes unike ID-verdi som attributtverdi. Ut fra ID-verdien finner så setteriet frem til korrekt navn i ID-basen. Det er derfor viktig at navnet er skrevet invertert i navnefeltet STANDARD i ID-basen. I tillegg er det viktig at navnefeltet i ID-basen KUN inneholder personenes navn, og ikke andre opplysninger, da det er hva som står i dette feltet som kommer på trykk i bokutgaven av brevkommentarene. ID-basen må oppdateres jevnlig ettersom nye personer legges til i basen, be Ellen om hjelp/instruks. Er ikke basen oppdatert, vil man få feilmeldinger på personkode selv om disse tilsynelatende er lagt inn i ID-basen.
Når brevkommentarbindet skal sendes til setteriet, må ID-basen først være oppdatert. Be deretter en av våre medarbeidere ved AKSIS om å generere en liste over alle innførslene i ID-basen i HTML-format som sendes setteriet, og som de tar utgangspunkt i under genereringen av personregisteret. NB: ID-basen må derfor være fullstendig oppdatert idet brevkommentarfilen sendes til setteriet. Ingen endringer som foretas i ID-basen ETTER at denne listen er generert og sendt til setteriet, kommer med i personregisteret.
Dersom man oppdager ekstremt mange feil i personregisteret under 1. satkorrektur: Rett i ID-basen, oppdater den på nytt og generer ny HTML-liste som sendes til setteriet på nytt. Setteriet genererer så personregisteret på nytt også. Det er mindre tidkrevende for både setteriet og for oss, siden det tar mye tid å markere mange feil i personregisteret, og vi må uansett samtidig oppdatere feilene i ID-basen. For setteriet er det dessuten lettere å generere på nytt enn å måtte rette mye manuelt. Sikrere er det også (med tanke på feilretting osv.).
Selv om personregisteret genereres av setteriet, legger vi inn et eget <div>-element for personregisteret i hoved-xml-filen. Dette inneholder en forklarende innledning. I tillegg koder vi inn personregisterets kolumnetittel i selve brevkommentarfilen. Følgende er hva filen skal inneholde. (I kommende brevkommentarbind kan følgende kopieres inn herfra eller fra xml-en til HIS 12k eller HIS 13k, men sikre at det ikke er nødvendig med noen justeringer:
<div type="regPersonsCommentaryfile" n="G">
<fw type="header" place="rightPage">Personregister</fw>
<head rend="versal14">PERSONREGISTER</head>
<p rend="noIndent">I de tilfeller hvor sidetallene refererer til omtale i bindets ord- og sakkommentarer eller biografier, viser sidereferansene kun til første forekomst av navnet i kommentaren eller biografien. Dersom kommentaren strekker seg over mer enn n side, og personen er nevnt flere ganger i samme kommentar eller biografi, kan vedkommende av den grunn være omtalt på følgende side(r) uten at det fremkommer av registeret. For omtalte personer og brevmottagere viser kursiverte tall til den aktuelle biografi.</p>
</div>
Dersom den innledende teksten til personregisteret endres, sikre at setteriet faktisk genererer ut fra den tekst som er lagt inn i den aktuelle xml-filen. Under settingen av HIS 13k, opplevde vi at setter kun kopierte tekst fra det personregisteret han genererte til 12k, selv om den ikke var identisk med teksten i 13k, som var noe endret.
ved Aasta Marie Bjorvand Bjørkøy 2004–2008
Den tekstkritiske redegjørelsen for brevene, opplysningene om tekstgrunnlag og manuskriptbeskrivelsene av brev plasseres i brevtekstbindet pga. kommentarenes omfang. Den tekstkritiske redegjørelsen for brev kodes identisk med tilsvarende redegjørelser i dramakommentarbindene. Oppsettet og formgivers spesifikasjoner for manuskriptbeskrivelser av brev er imidlertid annerledes for brev enn for drama. Under følger struktur- og kodeeksempler fra HIS 12 med forklaringer.
kap-15.1.9.6.1: Brevenes tekstkritiske redegjørelse
Brevenes tekstkritiske redegjørelse omsluttes av følgende overordnede div:
<div type="introduction">
<div type="editorialStatement">
<head type="versal11,5">TEKSTKRITISK REDEGJØRELSE</head>
<p rend="noIndent">tekst tekst tekst</p>
</div>
</div>
<!-- slutt introduction -->
Utover dette kodes brevenes tekstkritiske redegjørelse likt som de tekstkritiske redegjørelsene i dramakommentarbindene (med under-div-er osv).
kap-15.1.9.6.2: Innledningen til brevenes manuskriptbeskrivelser
Innledningen til brevenes manuskriptbeskrivelser omsluttes av følgende overordnede div:
<div type="introMsDescr">
<head type="versal11,5">OM MANUSKRIPTBESKRIVELSENE</head>
<p rend="noIndent"></p>
</div>
<!-- slutt introMsDescr -->
Utover dette kodes denne innledningen som øvrige innledninger i kommentarbindene.
kap-15.1.9.6.3: Brevenes manuskriptbeskrivelser og opplysninger om tekstgrunnlag
Brevenes manuskriptbeskrivelser omsluttes av følgende overordnede div:
<div type="filRedMsDescription">
<head type="versal11,5">TEKSTGRUNNLAG OG MANUSKRIPTBESKRIVELSER</head>
<div type="letterHead" n="A1">
<label rend="italic"><name>Til Frederik Hegel,</name> <placeName>Roma</placeName> <date>17. april 1868</date></label>
<div type="filRed" n="A2">
<head type="inline_smallCaps">tekstgrunnlag.</head>
<p>Brevet gjengis etter original, [SIGNATUR].</p>
</div>
<div type="msDescription" n="A3">
<head type="inline_smallCaps">manuskriptbeskrivelse.</head>
<p>Brevet består av BLA BLA BLA</p>
</div>
<div type="print" n="A4">
<p rend="noIndent">Trykt i HU 16.</p>
</div>
</div>
<!--A1 slutt -->
</div>
<!--filRedMsDescription slutt-->
Innenfor den overordnede <div type="filRedMsDescription"> gjentas strukturen A1 + A2 + A3 + A4 for hvert brev som beskrives. <div type="letterHead" n="A1"> omslutter henholdsvis A2, A3 og A4.
NB:
Innenfor <div type="filRed" n="A2"> og <div type="msDescription" n="A3"> må det kun ligge <p>, uten attributtverdien "noIndent", da teksten (med unntak av overskriftene) her skal settes med 4 millimeters innrykk, og dette kan ikke spesifiseres på det aktuelle <div>-elementet da dette kun gjelder teksten og ikke overskriftene (altså ikke alt innholdet i <div>-elementet).
Innenfor <div type="filRed" n="A2"> og <div type="msDescription" n="A3"> må det kun ligge <p>, uten attributtverdien "noIndent", da teksten (med unntak av overskriftene) her skal settes med 4 millimeters innrykk, og dette kan ikke spesifiseres på det aktuelle <div>-elementet da dette kun gjelder teksten og ikke overskriftene (altså ikke alt innholdet i <div>-elementet).
Overskriftene TEKSTGRUNNLAG OG MANUSKRIPTBESKRIVELSE skal settes som kapiteler, og det skal ikke genereres linjeskift etter overskriften. Vi koder derfor disse overskriftene med koden for det fjerde og laveste overskriftsnivået: <head type="inline_smallCaps">. Husk å sette selve overskriftsteksten som minuskler pga. kapitelkodingen. Husk også å legge inn punktum etter overskriften:
EKS:
<head type="inline_smallCaps">tekstgrunnlag.</head>
OG
<head type="inline_smallCaps">manuskriptbeskrivelse.</head>
Teksten for øvrig detaljkodes i tråd med øvrig tekst i kommentarbindene.
Brevhodene som innleder manuskriptbeskrivelsene er identiske med, og likt kodet som, brevhodene i brevkommentarbindene. Det er derfor hensiktsmessig å kopiere de ferdig kodete brevhodene fra brevmanuskriptbeskrivelsene og legge dem inn i brevkommentarfilen, så unngår man å kode det samme på nytt. (Enkelte brev blir imidlertid ikke beskrevet, dette gjelder særlig de brev som trykkes på grunnlag av avistrykk. Det vil derfor forekomme at brev som kommenteres ikke er beskrevet, eller også omvendt dersom man ikke har funnet det nødvendig å kommentere et brev.)
På grunn av brevkommentarenes omfang plasseres brevenes tekstkritiske redegjørelse og manuskriptbeskrivelser i det aktuelle tekstbindet. Den tekstkritiske redegjørelsen plasseres før Ibsens brev. Manuskriptbeskrivelsene plasseres til slutt i bindet, etter Ibsens brev. Når den tekstkritiske redegjørelsen og manuskriptbeskrivelsene er kodet ferdig, sendes xml-filen til den edisjonsfilolog som har ansvaret for det aktuelle tekstbindet. Tekstbind-ansvarlig sikrer så at tekstene plasseres på korrekt sted i tekstbind-xml-en, samt legger inn kolumnetitler.
kap-15.2: DIKT- og SAKPROSAKOMMENTARBIND
Dikt- og sakprosakommentarbindene har samme struktur for ord- og sakkommentarene som brevkommentarbindene, med overskrift og innledning til det kommentarsett som tilhører hver enkelt tekst, samt ev. en oversettelse dersom grunnteksten er på annet språk enn norsk. For å markere enheten, brukes det heller ikke her blanklinje mellom hver kommentar, som i dramakommentarbindene. For øvrig gjelder samme detaljkoding som for drama- og brevkommentarbindene.
kap-16: Koding for bokproduksjon
kap-16.1: Lemma- og hovedtekstreferanser
For å kunne koble kommentarmateriale til riktig sted i hovedteksten koder vi inn lemma- og hovedtekstreferanser.
I kommentarfilen kodes referansene som <xptr/>-elementer. Disse peker enten til hovedteksten eller til et annet sted i kommentarfilen:
<xptr type="lemma" doc="C1ht.xml" from="koC1_1" id="koC1_1"/> (lemmareferanse) <xptr type="internal" from="koC1_ht_1"/> (intern referanse) <xptr type="ht" doc="C1ht.xml" from="koC1_ht_1"/> (ht-referanse)
I hovedtekstfilen kodes referansene i <anchor/>-elementer:
<anchor type="lemma" id="koC1_1"/> (lemmareferanse) <anchor type="ht" id="koC1_ht_1"/> (ht-referanse)
kap-16.2: Bilderessurser
kap-16.2.1: Grunnleggende koding
Bilderessurser som skal inn i filene kodes med <figure>-elementer. Filnavnet er attributtverdi i entity="". Legg merke til at filendelsen ikke skal være en del av attributtverdien i entity="". Merk også at entiteten ikke kan starte med et tall, men må starte med en bokstav, så det anbefales at man legger inn verksforkortelsen først i filnavnet, f.eks. slik: Sa_tittelside.
I XML-filen:
<figure type="getFile" id="illus-siffer" entity="filnavn"/>
Hvis det skal refereres til bilderessursene, legges attributtet id="" inn, slik som vist i eksemplet.
I HIS_figures.ent (http://www.edd.uio.no:8088/his/DTD/figures/) legges definisjoner av bilderessurs-entitetene:
<!ENTITY filnavn SYSTEM "filnavn.jpg" NDATA jpeg>
Når filen inneholder bilderessurser er dette tillegget nødvendig i dokumentheader i XML-filen:
<!ENTITY % HIS_figures SYSTEM 'http://www.edd.uio.no:8088/his/DTD/figures/HIS_figures.ent'> %HIS_figures;
Foreløpig har vi definert jpg-, ps- og eps-formatene slik at filer av disse bildene kan inkluderes. Skulle det dukke opp nye formater, må disse defineres i HIS_figures.ent. Ta kontakt med DTD-ansvarlig for å få gjort dette.
For å få validert lenker til illustrasjoner må man legge inn bildeentiteten i dtd-en via Z:\DTD\figures\HIS_figures.ent. Man får også validert hvis man utkommenterer illustrasjonslenkene.
Faksimiler:
Et kodeeksempel på faksimiler av tittelside og eksempelside som skal plasseres foran verksinnledningen, fra kommentarbindfil:
<text id="C1commentaries" n="1">
<body>
.
.
.
<div type="illusTexts">
<p>Motstående side: <hi rend="italic">Tittelside i Ibsens
debutverk <title rend="italic">Catilina</title> 1850. Boken ble
utgitt under pseudonymet Brynjolf Bjarme. Den forelå ferdig
trykt 12. april og ble utlagt for salg 15. april 1850.</hi>
<hi rend="kreditering">Deichmanske bibliotek</hi></p>
<p>Følgende side: <hi rend="italic">Rolleliste i
<title rend="italic">Catilina</title> 1850.</hi>
<hi rend="kreditering">Deichmanske bibliotek</hi></p>
</div>
<div type="illustrations">
<figure type="getFile" id="illus-1" entity="c1_tittelside"/>
<p><!-- tom p satt inn av valideringshensyn--></p>
</div>
<div type="illustrations">
<figure type="getFile" id="illus-2" entity="c1_rolleliste"/>
<p><!-- tom p satt inn av valideringshensyn--></p>
</div>
<div type="introduction" n="I">...</div>
...
</body>
</text>
Faksimiler kodes altså i en egen <div type="illustrations">, jf. eks. ovenfor. Disse plasseres inn så godt som mulig i den eksisterende kodestrukturen i kommentarbindfila, jf. veiledende retningslinjer:
- faksimiler (<figure type="getFile">) som skal inn foran eller etter et spesielt avsnitt kodes som egen <div> og legges rett foran eller bak starten på vedkommende <div>, jf. eks. ovenfor hvor faksimilene skal trykkes i forkant av verksinnledningen
- faksimiler som skal inn et eller annet sted i løpet av et avsnitt (<figure type="getFile" rend="free">) plasseres bakerst i vedkommende <div> og kodes ikke i egen <div>, jf. eks. nedenfor hvor faksimilen skal plasseres innenfor bakgrunnsavsnittet
<div type="background">
<head>BAKGRUNN</head>
...
<p>...
omsluttende rim, parrim og kryssrim, mens hennes 14 avsluttende
parrimede femfotsjamber er beholdt nesten uendret.</p>
<figure type="getFile" rend="free" id="illus-13" entity="gmlTeaterBergen_bygn"><p>Det norske Theater i Bergen,
slik bygningen stod under Henrik Ibsens tid ved teateret. Ødelagt under annen verdenskrig
på grunn av et bombenedslag i 1944.
<hi rend="kreditering">Universitetet i Bergen, Teaterarkivet</hi></p></figure>
</div>
Noteillustrasjoner:
Et kodeeksempel på noteillustrasjon som skal ligge mellom prosaavsnitt i løpende tekst, fra kommentarbindfil:
<p>... bedre å utelate alle eller noen av de andre repetisjonene.
Akkompagnementet bygger på Crusells harmonisering.</p>
<figure type="getFile" id="illus-1eps" entity="K1_106001"/>
<p>To sanger av Gandalf (<title rend="quotes">Maalet er vundet!</title>
og <title rend="quotes">Naar udi Barmen</title>) i 1850-utgaven er
trukket frem som egne dikt i Hundreårsutgaven <bibl>(HU ...</bibl>...</p>
Her kodes <figure> fritt i <div> som omslutter prosaavsnittene.
Et kodeeksempel på noteillustrasjon som skal ligge etter prosaavsnitt i kommentarene, fra kommentarbindfil:
<list type="commentary">
<item n="1">&koSa_116;</item>
<item n="2">Stille, stille; Natten kommer</item>
<item n="3">
<p>Firfotstrok: bi (8 7)² (8 7)²
(A b)² (C d)²<xref>, jf. kommentar til
&koSa_2_intern;</xref> (prolog). Til sangen er det
bevart en melodi med første tekststrofe skrevet
inn, merket med <hi rend="italic">soprano</hi>.</p>
<figure type="getFile" id="illus-4eps" entity="Sa_eks3001"/>
</item></list>
Her kodes <figure> fritt i <item> som omslutter prosaavsnittene.
Logo:
Et kodeeksempel på inkludering av logo i 2. kolofon, fra innledende fil:
<text><body><div type="2colophon">
<figure type="getFile" entity="HIS-logo_innh"/>
<head>Henrik Ibsens skrifter</head>
Her kodes <figure> fritt i <div>.
kap-16.2.3: Bildetekst
Bildetekst kodes på en av to måter:
- i <p> inne i <figure>, jf. første eks. nedenfor
- i <p> i egen <div> i forbindelse med innledende faksimiler til en innledning og kommentarer til et verk, jf. andre eks. nedenfor
<figure type="getFile" rend="free" id="illus-13" entity="gmlTeaterBergen_bygn">
<p>Det norske Theater i Bergen,
slik bygningen stod under Henrik Ibsens tid ved teateret. Ødelagt under annen verdenskrig
på grunn av et bombenedslag i 1944.
<hi rend="kreditering">Universitetet i Bergen, Teaterarkivet</hi></p>
</figure>
<text id="C1commentaries" n="1">
<body>
.
.
.
<div type="illusTexts">
<p>Motstående side: <hi rend="italic">Tittelside i Ibsens
debutverk <title rend="italic">Catilina</title> 1850. Boken ble
utgitt under pseudonymet Brynjolf Bjarme. Den forelå ferdig
trykt 12. april og ble utlagt for salg 15. april 1850.</hi>
<hi rend="kreditering">Deichmanske bibliotek</hi></p>
<p>Følgende side: <hi rend="italic">Rolleliste i
<title rend="italic">Catilina</title> 1850.</hi>
<hi rend="kreditering">Deichmanske bibliotek</hi></p>
</div>
<div type="illustrations">
<figure type="getFile" id="illus-1" entity="c1_tittelside"/>
<p><!-- tom p satt inn av valideringshensyn--></p>
</div>
<div type="illustrations">
<figure type="getFile" id="illus-2" entity="c1_rolleliste"/>
<p><!-- tom p satt inn av valideringshensyn--></p>
</div>
<div type="introduction" n="I">
For å få validert illustrasjoner inne i ord- og sakkommentarene, er det nødvendig å avslutte <div>, selv om det egentlig bryter med den logiske kodestrukturen. Det kommer av at det er strenge regler for rekkefølgen av de ulike elementene inne i <div>.
Behandling av diverse fenomener:
- særtegn gjøres om til entiteter
- mellom årstall etc. skal det være tankestreksentitet
- anførselstegn erstattes med entiteter
kap-16.2.4: Krediteringstekst
Krediteringstekst kodes i <hi rend="kreditering"> i <p> inne i <figure>.
<figure type="getFile" id="illus-1" entity="c1_tittelside"><p>Tittelside i Ibsens
debutverk <title rend="italic">Catilina</title> 1850. Boken ble utgitt under
pseudonymet Brynjolf Bjarme. Den forelå ferdig trykt 12. april og ble utlagt for salg
15. april 1850. <hi rend="kreditering">Deichmanske bibliotek</hi></p></figure>
kap-16.2.5: Sidetallsreferanser til illustrasjoner
Når vi vil ha generert et sidetall i kommentarbindet ut fra en illustrasjon plassert et annet sted i bindet, bruker vi <ref>-elementer:
<p>Teksten i <title rend="italic">Catilina</title> 1850 er satt i fraktur. En faksimile av tittelbladet gjengis på s.&tu20;<ref targType="figure" target="illus-1"></ref>.</p>
target="" viser til attributtverdien i id="" i <figure type="getFile" id="" entity="">. Den illustrasjonen det vises til, kan ikke være utkommentert; kodingen blir ikke validert hvis det ikke finnes noen tilsvarende attributtverdi et annet sted i fila.
kap-16.3: Innhenting av XML-filer
I kommentarbindfilen (o.a. komplette bindfiler, f.eks. brevbind) legges det inn referanser til eksterne filer (dvs. innledende filer til verket HIS; tittelsider, kolofonsider, innholdsfortegnelser, forkortelseslister etc.), som setteriet skal inkludere i filen i produksjonen.
Filer som skal hentes inn kodes inn vha. <xptr type="getFile" doc=""/>. Filene defineres som entiteter i HIS_files.ent. Filnavnet er attributtverdi i entity="". Legg merke til at filendelsen skal være en del av attributtverdien i doc="".
I XML-filen:
<xptr type="getFile" doc="filnavn.xml"/>
I HIS_files.ent (http://www.edd.uio.no:8088/his/DTD/eksterneFiler/):
<!ENTITY filnavn.xml SYSTEM 'filnavn.xml' NDATA XML>
Legg merke til at filendelsen (filformatbetegnelsen) skal være en del av attributtverdien i doc-attributtet.
Når det skal hentes inn eksterne filer er dette tillegget nødvendig i dokumentheader i XML-filen:
<!ENTITY % HIS_files SYSTEM 'http://www.edd.uio.no:8088/his/DTD/eksterneFiler/HIS_files.ent'> %HIS_files;
kap-16.4: Litteraturliste
Det finnes en fullstendig litteraturliste som dekker all kildelitteratur brukt av prosjektet. Denne listen finnes i XML-filen HIS_litteraturliste.xml. Fra denne skal det genereres lister til de enkelte kommentarbind.
kap-16.4.1: Manuskriptinnførsler
Struktur på <bibl>-elementet med gjeldende og valid koding:
<bibl n="1">
<note type="korr"/>
<seg type="msInnførsel">BOB (Bergen Offentlige Bibliotek)</seg>
<seg type="msInfo">hBI. Ibsen, Henrik. «Gildet paa Solhoug». Sufflørbok</seg>
</bibl>
<bibl n="1">
<note type="korr"/>
<seg type="msInnførsel">TarkUiB (Teaterarkivet, Institutt for
kulturstudier og kunsthistorie, Universitetet i Bergen)</seg>
<seg type="msInfo">NT264r. Dumas, Alexandre. «Regentens Datter». Rollehefter</seg>
<seg type="msInfo">NT280. Ibsen, Henrik. «Fru Inger til Østeraad». Sufflørbok</seg>
<seg type="msInfo">NT344r. Ibsen, Henrik. «Fru Kirsten Liljekrans
i ‘Olaf Liljekrans’». Rollehefte</seg>
<seg type="msInfo">NT348. Ibsen, Henrik. «Gildet paa Solhoug». Sufflørbok</seg>
<seg type="msInfo">NT348r. Ibsen, Henrik. «Gildet paa Solhoug». Rollehefter</seg>
</bibl>
kap-16.4.2: Trykte kilder
kap-16.4.2.1: Monografier
Struktur på <bibl>-elementet med gjeldende og valid koding:
<bibl n="1">
<note type="korr"/>
<monogr>
<author>Goethe, Johann Wolfgang</author>
<title level="m">Faust</title>
<edition><!--Angir hvilken utgave, dersom dette er oppgitt--></edition>
<editor></editor>
<imprint>
<date>1999</date>
<pubPlace>Frankfurt am Main</pubPlace>
<publisher>Deutscher Klassiker Verlag</publisher>
<biblScope type="totalPage">856 s</biblScope>
</imprint>
</monogr>
</bibl>
kap-16.4.2.2: Samlede verk
Struktur på <bibl>-elementet med gjeldende og valid koding:
<bibl n="1">
<note type="korr"/>
<author>FU = Ibsen, Henrik</author>
<series>
<title level="s">Samlede værker</title>
<editor></editor>
</series>
<edition><!--Angir hvilken utgave, dersom dette er oppgitt--></edition>
<imprint>
<date>1898–1902</date>
<pubPlace>København</pubPlace>
<publisher>Gyldendalske Boghandel</publisher>
<biblScope type="volume">10 b. B. 1–9 uten bindtitler;
titlene er tatt fra innholdsfortegnelsen</biblScope>
<biblScope type="totalPage"><!--antall sider dersom dette er oppgitt--></biblScope>
</imprint>
<monogr n="1">
<title level="m">Catilina. Gildet på Solhaug. Fru Inger til Østråt</title>
<imprint>
<date>1898</date>
<biblScope type="volume"></biblScope>
<biblScope type="totalPage"><hi rend="romNum">VII</hi>, 378 s</biblScope>
</imprint>
</monogr>
ØVRIGE BIND
.
.
.
</bibl>
kap-16.4.2.3: Artikler
Struktur på <bibl>-elementet med gjeldende og valid koding:
<bibl n="1">
<note type="korr"/>
<analytic>
<author>Anonym</author>
<title level="a">&lquo;[Anmeldelse av
<hi rend="italics">Kjæmpehøien</hi>]&rquo;</title>
</analytic>
<imprint>
<biblScope type="pageRange"><!--sidespennet artikkelen strekker seg over--></biblScope>
</imprint>
<series><!-- i -->
<editor><!--ev. redaktør--></editor>
<title level="j">Christiania-Posten</title>
<title type="subordinate">28/9</title>
</series>
<imprint>
<date>1850b</date>
</imprint>
</bibl>
kap-16.4.3: Annen koding i litteraturlisten
kap-16.4.3.1: Markering av bindtilhørighet
Bindtilhørighet markeres ved at bindnummer legges inn i attributtet n="" i de <bibl>-innførslene som er aktuelle for et bind.
<bibl n="1">
.
.
.
</bibl>
kap-16.4.3.2: Markering av korrekturlesning
- <note type="korr"/> brukes for å markere innførsler som er ferdig korrekturlest
- <note type="ukorr"/> markerer innførsler som ikke er korrekturlest
kap-17.1: Innledning
Dette kodepraksiskapitlet omhandler koding som utføres for den elektroniske utgaven og er UNDER ARBEID.
kap-17.2: Hovedtekster
HIS' hovedtekster skal foreligge i to versjoner, en versjon for den elektroniske utgaven og en versjon for bokutgaven. Versjonene skilles fra hverandre i filnavnene; for Gengangere navnes filene slik: Geht.xml og Geht_noter.xml (elektronisk utgave) og Geht_bok.xml og Geht_noter_bok.xml (bokutgave). Her beskrives hvordan fila for HISe utvikles fra fila for HISb.
kap-17.2.1: <teiHeader>
kap-17.2.1.1: Den elektroniske tekstens tittel – <titleStmt>
Tekst i <titleStmt> skal følge dette mønsteret. Forskjeller fra Geht_bok.xml er markert med fet:
<titleStmt> <title level="s" type="main">Henrik Ibsens skrifter</title> <title level="s" type="sub">Historisk-kritisk utgave, elektronisk versjon</title> <title level="a" type="main">Gengangere</title> <title level="a" type="sub">Hovedtekst, 1. utg.</title> <title level="a" type="origYear">1881</title> <author>Henrik Ibsen</author> <funder>&funder;</funder> <editor>&editor;</editor> <respStmt> <resp>Edering</resp> <name>Christian Janss</name> <name>Hilde Bøe</name> <name>Stine Brenna Taugbøl</name> <resp>Innlemming i elektronisk utgave</resp> <name>EDD: Eining for digital dokumentasjon</name> <resp>Kodeteknisk støtte og utvikling</resp> <name>AKSIS: Avdeling for kultur, språk og informasjonsteknologi, Universitetsforskning i Bergen (Unifob AS)</name> <resp>HISe-koding</resp> <name>Stine Brenna Taugbøl</name> <resp>Ederingskoding</resp> <name>Hilde Bøe</name> <name>Stine Brenna Taugbøl</name> <resp>Kodekontroll</resp> <name>Ellen Nessheim Wiger</name> <resp>Konvertering, kollasjonering og koding</resp> <name>Ingvald Aarstein</name> <resp>Kollasjonering</resp> <name>Sigrid Larsson</name> <resp>Kodekontroll</resp> <name>Mette Witting</name> </respStmt> </titleStmt>
kap-17.2.1.2: Tekstens utgave – <editionStmt>
Her føres versjonsspesifikk dato. Se forøvrig «<teiHeader>».
<editionStmt><edition id="Geht-0310"/></editionStmt>
kap-17.2.1.3: Publiseringsinfo – <publicationStmt>
Her føres forlag/utgiver samt årstall for når den aktuelle teksten publiseres elektronisk.
<publicationStmt> <publisher>Universitetet i Oslo ved Henrik Ibsens skrifter</publisher> <distributor id="HISe">Universitetet i Oslo</distributor> <date value="2010" id="HISe-date">2010</date> <pubPlace>Oslo</pubPlace> </publicationStmt>
kap-17.2.1.4: Bibliografiske opplysninger om kildene – <sourceDesc>
Hovedtekstfilen for den elektroniske utgaven bygger på hovedtekstfilen for bokutgaven, og dette opplyses det om i et innledende <p>-element.
<sourceDesc> <p>Denne filen bygger på Geht_bok.xml (Geht_bok-0310).</p> ... </sourceDesc>
De bibliografiske opplysningene over grunntekst og øvrige tekstkilder kan beholdes fra hovedtekstfilen for bokutgaven.
kap-17.2.1.5: Kodedokumentasjon – <tagsDecl>
I <tagUsage gi="id-who"> i <tagsDecl> ligger en oversikt over id-ene til de ulike rollenavnene i dramaene og hvilke navn de opptrer under i henholdsvis <castList>, <speaker> og <stageRole>. I hovedtekstfilene kan <stageRole> med tilhørende navn fjernes fra oversikten, siden <stageRole>-kodingen er fjernet fra hovedtekstene.
kap-17.2.2: Fjerning av typografisk koding (bokproduksjon)
Deler av typografien til bokutgaven skal ikke overføres til den elektroniske utgaven. Dette gjelder:
- kapitler på tittelsider, rolleliste og replikkåpner, samt majuskler i overskrifter, erstattes med majuskler og minuskler
- attributtene i følgende elementer fjernes: <head rend="majuscule">, <p rend="set">, <role rend="smallCaps>, <speaker rend="smallCaps">, <stage rend="2lines">, <stage rend="next">, <stage rend="previous">
- attributtene i følgende elementer beholdes: <p rend="noIndent">, <pb rend="noprint">, <text rend="proseDrama|verseDrama|visualized|poem|letter">
- attributtene i følgende elementer endres: fra <titlePage type="main_flyleaf"> til <titlePage type="flyleaf">
- kolumnetitler (<fw>) fra bokutgaven fjernes
- mellomromsentiteten (som skulle hindre uheldige linjedelinger i satsen) fjernes
kap-17.2.3: Innlegging av sidereferanser til HISb
Hovedtekstene i HISe skal ha med sidereferanser til HISb. Disse kodes på samme måte som sidereferansene til HU: <pb ed="HIS">. Bare første sidetall legges inn i n="", resten genereres automatisk av stilarket.
kap-17.3: Hovedtekstens notefil
Notefila deles også i HISe- og en HISb-fil: Geht_noter.xml (elektronisk versjon) og Geht_noter_bok.xml (trykt versjon). Bare <teiHeader> skiller de to filene fra hverandre.
kap-17.3.1: <teiHeader>
Notefilas <teiHeader> ser slik ut:
<teiHeader> <fileDesc> <titleStmt> <title>Henrik Ibsens skrifter</title> <title id="Ge">Gengangere</title> <title>Tekstkritiske noter, elektronisk versjon</title> <funder>&funder;</funder> <editor>&editor;</editor> <respStmt><resp>Omgjøring til elektronisk versjon</resp> <name id="HIS_SBT">Stine Brenna Taugbøl</name></respStmt> <respStmt><resp>Oppretting</resp> <name id="HIS_HB">Hilde Bøe</name></respStmt> </titleStmt> <publicationStmt><p/></publicationStmt> <sourceDesc><p>Filen er opprettet internt.</p></sourceDesc> </fileDesc> <encodingDesc> <projectDesc><p/></projectDesc> <tagsDecl><tagUsage gi="tei.2">Kodingen her er gjort så enkel som mulig.</tagUsage></tagsDecl> </encodingDesc> <profileDesc><langUsage><language id="nob"/></langUsage></profileDesc> <revisionDesc> <change><date>17.03.2010</date><respStmt><name>SBT</name><resp>Splittet fila i en bokfil og en HIS-fil.</resp></respStmt><item/></change> </revisionDesc> </teiHeader>
kap-17.4: Tekstarkiv
De diplomatariske tekstene i tekstarkivet inngår bare i HISe, ikke i HISb. I dette kapitlet omtales endringer som gjøres i de eksisterende filene for å klargjøre og tilpasse dem for elektronisk publisering.
kap-17.5: Lenking til faksimiler
I HISe skal det lenkes til faksimiler fra hovedtekst, grunntekst og alle manuskripter. Lenken legges i doc="" i <pb/>:
<head><pb n="[7]" doc="Ge_s7.jpg"/><pb ed="HIS"/><pb ed="HU"/>Første akt</head> <sp who="ENGSTRAND"><spOpener><speaker><pb n="8" doc="Ge_s8.jpg"/>Engstrand</speaker></spOpener>
Lenker til faksimiler av perm og forsatsblader legges i henholdsvis <front> og <back>. Disse <pb/>-ene skal ikke ha n="". Kodeeksempel fra Gengangere:
<text rend="proseDrama" lang="Dano-Norwegian"> <front> <pb doc="Ge_forperm.jpg"/><pb doc="Ge_fremreForsatsI.jpg"/><pb doc="Ge_fremreForsatsII.jpg"/><pb doc="Ge_fremreForsatsIII.jpg"/> <titlePage type="flyleaf"><docTitle><titlePart type="main"><pb n="1" doc="Ge_s1.jpg"/><pb ed="HIS" n="383"/><anchor type="lemma" id="koGe_1"/>Gengangere</titlePart></docTitle></titlePage> ... <sp who="OSVALD"><spOpener><speaker>Osvald</speaker> <stage>sidder ubevægelig som før og siger</stage></spOpener> <p rend="noIndent">Solen. – Solen.</p></sp> </div> </body> <back> <pb doc="Ge_bakreForsatsIV.jpg"/><pb doc="Ge_bakreForsatsV.jpg"/><pb doc="Ge_bakreForsatsVI.jpg"/><pb doc="Ge_bakperm.jpg"/> </back> </text>
kap-17.6: Kommentarmateriale
Kommentarbindfilene splittes opp i mindre deler til bruk for HISe. For hvert enkelt verk deles det opp i:
- innledning
- tekstkritisk redegjørelse
- manuskriptbeskrivelse
- ord- og sakkommentarer
kap-17.6.1: Innledning
NB: Foreløpig er ikke forfatterne av innledningene inkludert i fila. Dette er metaopplysninger som det ikke er bestemt ennå hvor skal stå i HISe.
kap-17.6.1.1: <teiHeader>
Slik ser <teiHeader> for ei innledningsfil ut, med særtrekk markert med fet:
<teiHeader>
<fileDesc>
<titleStmt>
<title>Henrik Ibsens skrifter, elektronisk versjon</title>
<title>Innledning til Gengangere</title>
<funder>&funder;</funder>
<editor>&editor;</editor>
<respStmt>
<resp>Innlemming i elektronisk utgave</resp>
<name>EDD: Eining for digital dokumentasjon</name>
<resp>Kodeteknisk støtte og utvikling</resp>
<name>AKSIS: Avdeling for kultur, språk og informasjonsteknologi, Universitetsforskning i Bergen (Unifob AS)</name>
<resp>HISe-koding</resp>
<name id="SBT">Stine Brenna Taugbøl</name>
<resp>Koding</resp>
<name id="AMB">Aasta Marie Bjorvand Bjørkøy</name>
<name id="MA">Maria Alnæs</name>
<name>Nina Marie Evensen</name>
<resp>Tekstarbeid</resp>
<name>Aasta Marie Bjorvand Bjørkøy</name>
<name>Maria Alnæs</name>
<name>Nina Marie Evensen</name>
<resp>Kontroll av sitater og ordbøker</resp>
<name id="IK">Ingrid Korvald</name>
<name id="GB">Gry Berg</name>
<resp>Kontroll av littlist og referanser</resp>
<name id="HS">Hege Stensrud</name>
<name>Aasta Marie Bjorvand Bjørkøy</name>
<name>Maria Alnæs</name>
<resp>Kommentar-, intern- og ht-entiteter</resp>
<name>Aasta Marie Bjorvand Bjørkøy</name>
<resp>Kodekontroll</resp>
<name>Aasta Marie Bjorvand Bjørkøy</name>
</respStmt>
</titleStmt>
<publicationStmt>
<publisher>Universitetet i Oslo ved Henrik Ibsens skrifter</publisher>
<distributor id="HISe">Universitetet i Oslo</distributor>
<date value="2010" id="HISe-date"/>
<pubPlace>Oslo</pubPlace>
</publicationStmt>
<sourceDesc>
<p>Dette dokumentet har ingen kilde.</p>
</sourceDesc>
</fileDesc>
<encodingDesc>
<tagsDecl>
<tagUsage gi="id-base">&Ibsen-keys;</tagUsage>
</tagsDecl>
</encodingDesc>
<profileDesc>
<langUsage>
<language id="nob"/>
<language id="dut"/>
<language id="cze"/>
<language id="ger"/>
<language id="fre"/>
<language id="ice"/>
<language id="eng"/>
<language id="ita"/>
<language id="spa"/>
<language id="swe"/>
<language id="scc"/>
<language id="rus"/>
<language id="por"/>
<language id="hun"/>
<language id="pol"/>
<language id="fin"/>
<language id="jpn"/>
<language id="ukr"/>
<language id="bul"/>
<language id="rum"/>
</langUsage>
</profileDesc>
<revisionDesc>
<change>
<date>15.04.2010</date>
<respStmt><name>SBT</name><resp>Opprettet xml-fil</resp></respStmt>
<item>Skilte ut innledningen til Ge i en egen fil til HISe. Har lagt inn opplysninger vedr HISe i teiHeader. Fjernet typografisk koding, jf. KP.</item>
</change>
</revisionDesc>
</teiHeader>
kap-17.6.1.2: Overordnet struktur
Strukturen i innledningsfila ser slik ut:
<text type="introduction" id="Ge_intro"> <body> <div type="introduction"> <head>Innledning</head> <div type="background"> <head>Bakgrunn</head> <p rend="noIndent">...</p> <p>...</p> ... </div> <div> <head>Dramaform</head> <p rend="noIndent">...</p> <p>...</p> ... </div> </div> <div type="creation"> <head>Tilblivelse</head> <p rend="noIndent">...</p> <p>...</p> ... </div> <div type="publication"> <head>Utgivelse</head> <p rend="noIndent">...</p> <p>...</p> ... <div> <head>Mottagelse av utgaven</head> <p rend="noIndent">...</p> <p>...</p> ... </div> </div> <div type="translatedPublication"> <head>Oversettelser i Ibsens levetid</head> <p rend="noIndent">...</p> <p>...</p> ... </div> <div type="performance"> <head>Oppførelser</head> <p rend="noIndent">...</p> <p>...</p> ... <div> <head>Mottagelse av oppførelsene</head> <p rend="noIndent">...</p> <p>...</p> ... </div> </div> </div>
De ulike avdelingene i innledningene kan variere noe fra verk til verk.
kap-17.6.1.3: Omgjøring av bokutgavens typografi
Følgende endringer gjøres:
- <head>: overskrifter (på 3 nivåer) er foreløpig kodet med attributtverdiene "level1" (øverste nivå), "level2" og "level3" i rend=""
- majuskler i <head> endres til majuskler og minuskler
- HVA GJØR VI MED ILLUSTRASJONENE HER?
kap-17.6.1.4: Liste med oversettelser
Listekodingen over oversettelser er forenklet i forhold til HISb. Kodingen ser slik ut for HISe:
<list type="standardList" rend="reduce"> <item n="1" rend="hangIndent"> <seg type="content" lang="swe"><date value="1882-xx-xx">1882</date>. <title rend="quotes">Gengångare : familjedrama i tre akter</title>. fverstting från norskan. <title rend="italic"><rs type="place" corresp="plHel">Helsingfors</rs></title> nr.&tu20;20–41, 25/1–31/1; 1/2–18/2</seg> </item> ... </list>
kap-17.6.2: Tekstkritisk redegjørelse
kap-17.6.3: Manuskriptbeskrivelse
kap-17.6.4: Ord- og sakkommentarer
NB: Foreløpig er ikke oversikt over kommentatorer eller generelle opplysninger om kommenteringen (bruk av NRO) inkludert i kommentarfila. Dette er metaopplysninger som foreløpig tenkes plassert andre steder i HISe, f.eks. i kommentarregulativet og i egne medarbeideroversikter.
kap-17.6.4.1: <teiHeader>
Slik ser <teiHeader> for ei kommentarfil ut, med særtrekk markert med fet:
<teiHeader>
<fileDesc>
<titleStmt>
<title>Henrik Ibsens skrifter, elektronisk versjon</title>
<title>Kommentarer til Gengangere</title>
<funder>&funder;</funder>
<editor>&editor;</editor>
<respStmt>
<resp>Innlemming i elektronisk utgave</resp>
<name>EDD: Eining for digital dokumentasjon</name>
<resp>Kodeteknisk støtte og utvikling</resp>
<name>AKSIS: Avdeling for kultur, språk og informasjonsteknologi, Universitetsforskning i Bergen (Unifob AS)</name>
<resp>HISe-koding</resp>
<name id="SBT">Stine Brenna Taugbøl</name>
<resp>Koding</resp>
<name id="AMB">Aasta Marie Bjorvand Bjørkøy</name>
<name id="MA">Maria Alnæs</name>
<name>Nina Marie Evensen</name>
<resp>Tekstarbeid</resp>
<name>Aasta Marie Bjorvand Bjørkøy</name>
<name>Maria Alnæs</name>
<name>Nina Marie Evensen</name>
<resp>Kontroll av sitater og ordbøker</resp>
<name id="IK">Ingrid Korvald</name>
<name id="GB">Gry Berg</name>
<resp>Kontroll av littlist og referanser</resp>
<name id="HS">Hege Stensrud</name>
<name>Aasta Marie Bjorvand Bjørkøy</name>
<name>Maria Alnæs</name>
<resp>Kommentar-, intern- og ht-entiteter</resp>
<name>Aasta Marie Bjorvand Bjørkøy</name>
<resp>Kodekontroll</resp>
<name>Aasta Marie Bjorvand Bjørkøy</name>
</respStmt>
</titleStmt>
<publicationStmt>
<publisher>Universitetet i Oslo ved Henrik Ibsens skrifter</publisher>
<distributor id="HISe">Universitetet i Oslo</distributor>
<date value="2010" id="HISe-date"/>
<pubPlace>Oslo</pubPlace>
</publicationStmt>
<sourceDesc>
<p>Dette dokumentet har ingen kilde.</p>
</sourceDesc>
</fileDesc>
<encodingDesc>
<tagsDecl>
<tagUsage gi="id-base">&Ibsen-keys;</tagUsage>
</tagsDecl>
</encodingDesc>
<profileDesc>
<langUsage>
<language id="nob"/>
<language id="dut"/>
<language id="cze"/>
<language id="ger"/>
<language id="fre"/>
<language id="ice"/>
<language id="eng"/>
<language id="ita"/>
<language id="spa"/>
<language id="swe"/>
<language id="scc"/>
<language id="rus"/>
<language id="por"/>
<language id="hun"/>
<language id="pol"/>
<language id="fin"/>
<language id="jpn"/>
<language id="ukr"/>
<language id="bul"/>
<language id="rum"/>
</langUsage>
</profileDesc>
<revisionDesc>
<change>
<change>
<date>17.03.2010</date>
<respStmt><name>SBT</name><resp>Opprettet xml-fil</resp></respStmt>
<item>Skilte ut kommentarene til Ge i en egen fil til HISe. Har lagt inn opplysninger vedr HISe i teiHeader. Fjernet typografisk koding.</item>
</change>
</revisionDesc>
</teiHeader>
kap-17.6.4.2: Overordnet struktur
Strukturen i kommentarfila ser slik ut:
<text type="commentary" id="Ge_komm"> <body> <div type="lemmaCommentary"> <div> <head>Tittelside</head> <list type="commentary"> <item>...</item> </list> </div> <div> <head>Rolleliste</head> <list type="commentary"> <item>...</item> </list> </div> <div> <head>Akt 1</head> <list type="commentary"> <item>...</item> </list> </div> <div> <head>Akt 2</head> <list type="commentary"> <item>...</item> </list> </div> <div> <head>Akt 3</head> <list type="commentary"> <item>...</item> </list> </div> </div> </body> </text>
kap-17.6.4.3: Omgjøring av bokutgavens typografi
Følgende endringer gjøres:
- n="" fjernes fra <div type="lemmaCommentary" n="II">
- bokutgavens foliering (<fw>) fjernes
- rend="" fjernes fra <head rend="versal11,5">
- majuskler i <head> endres til majuskler og minuskler
- <figure type="getFile">, <div type="illusTexts">, <div type="illustrations">, <hi rend="kreditering">, <hi rend="red">: angår illustrasjoner i boka – disse må gås gjennom. Om de tilhører kommentarene bør de få stå her (koding?). Hvis ikke, tas de bort og plasseres ev. andre steder i HISe.
kap-17.6.4.4: Omkoding av kommentarene
De enkelte kommentarene kodes som innførsler (<item>) i en liste (<list type="commentary">), jf. Overordnet struktur.
Lemma i kommentaren kodes i <term> og kommentaren i <gloss>:
<item> <p rend="noIndent"> <xptr type="lemma" url="Geht.xml" from="koGe_16" id="koGe_16"/> <term>sybord</term> <gloss>bord til sysaker og sytøy (NRO), ofte forsynt med skuffer eller med en oppfellbar bordplate over et rom hvor sysakene oppbevares</gloss> </p> </item>
Ved lange sitater inne i kommentaren, blir kodingen slik:
<item> <p rend="noIndent"> <xptr type="lemma" url="Geht.xml" from="koGe_1" id="koGe_1"/> <term>Gengangere</term> <gloss>Tittelens betydning ...</gloss> <quote rend="proseIndent">The subject falls prey to ... memory is extended enormously <bibl>(Tjønneland 2005, 198–99)</bibl>.</quote></p> <p rend="noIndent"><gloss>Den samtidige tyske forfatterinnen og feministen Hedwig Dohms bruk av ordet ... Alfred Fournier hevdet at</gloss> <quote rend="proseIndent">freldrarnas syfilis kan gå i arf ... ett slags «gengångare» af den luetiska diatesen hos frldrarne <bibl>(1882, 55–56)</bibl>.</quote> </p> </item>
kap-18: Tekniske tema
kap-18.1.1: Kodesettet TEI
Ved koding av tekstene i prosjektet Henrik Ibsens Skrifter brukes kodesettet TEI – Text Encoding Initiative – som er dokumentert i C.M. Sperberg-McQueen and Lou Burnard (eds), Guidelines for Text Encoding and Interchange. Published for the TEI Consortium by the Humanities Computing Unit, University of Oxford, 2002. ISBN 0-952-33013-X, nettversjonen er tilgjengelig fra TEI Guidelines. TEIs taggsett består av et sekstitalls DTD-fragmenter (*.dtd) og entitetsfiler (*.ent). I disse filene defineres de forskjellige delene av kodesettet. TEI er delt inn i «core tag sets», «base tag sets» og «additional tag sets». I tillegg kommer en del tilleggssett som f.eks. «Auxiliary Document Types». Vi bruker ett slik tilleggstaggsett i prosjektet, men det brukes for DTD vi har lagt for dokumentasjonen av kodepraksis, og ikke for materialet etter Henrik Ibsen. Det som som følger her dokumenterer tilpasningene som er gjort for HIS i TEIs elementer. For en innføring i TEI generelt, se kapittel 1 i TEI P4: About these guidelines. Det følgende forutsetter dessuten god kjennskap til XML - Extended Markup Language, se A Gentle Introduction to XML i TEI P4.
kap-18.1.2: En oversikt over de viktigste DTD-fragmentene
Nedenfor følger en oversikt over de viktigste DTD-fragmentene og entitetsfilene i TEI, dvs. de filene som inneholder definisjoner av elementer og attributter som vi bruker.
- teicore2.dtd – kjerneelementer (bla. de enkleste tekstkritiske taggene)
- teidram2.dtd – dramaelementer
- teipros2.dtd – prosaelementer
- teivers2.dtd – verselementer
- teitc2.dtd – apparatkoder/tekstkritiske elementer
- teitran2.dtd – transkripsjonstagger
- teilink2.dtd – lenke- og referanseelementer
- teifig2.dtd – her defineres <figure>
- teihdr2.dtd – <teiHeader>-elementene
- teitsd2.dtd – elementer (fra «[the] auxiliary DTD which may be used for the documentation of new elements, element classes and entities») brukt i Kodepraksis.dtd til dokumentasjonen av våre endringer i TEI (se selve kodingen av kapitlet «Dokumentasjon av nye elementer» i dette dokumentet)
- teiclas2.ent – her defineres de fleste attributtene og attributtgruppene, f.eks. %a.global; (de globale attributtene)
kap-18.1.3: Forskjellige element-typer
I TEI P4-DTDene er nesten alle elementer medlem av en klasse. Klassessystemet er omfattende, og her skal vi bare se kort på den overordnede inndelingen, siden den kan hjelpe oss i arbeidet med DTD-endringer samt til å forstå logikken i hvordan og hvorfor elementer er definert som de er. I TEI P4 snakker man om disse nivåene:
-
«top-level element»
- <TEI.2> og <teiCorpus.2> er de to eneste «top-level»-elementene i TEI P4, og disse to inngår ikke i noen elementklasse (for øvrig sammen med noen spesial-elementer som bare kan brukes i ett element) «component-level element»/«components»
- «text components» er en samlegruppe for «chunks» og «inter-level»-elementer, som begge er elementer , som kan forekomme direkte på tekstnivå (altså i <text>) eller innenfor tekstens deler (dvs. i <div>-elementer) «chunk-level element»/«chunks»
- elementer som f.eks. avsnitt (<p>) og andre elementer på avsnittsnivå (f.eks. <head>), som kan forekomme direkte på tekstnivå eller innenfor tekstens deler (dvs. i <div>-elementer), men ikke i andre «chunks» (<head> kan ikke inneholde <p> og heller ikke seg selv, <head>) «inter-level element»
- disse elementene kan forekomme både i og utenfor «chunks» (<list> kan f.eks. brukes både inne i <p> og direkte i <div> eller <text>) «phrase-level element»
- elementer på frasenivå kan ikke brukes direkte på tekst- eller <div>-nivå, de kan bare forekomme der ren tekst kan finnes, dvs. i «chunks (paragraphs or paragraph-level elements)», som TEI formulerer det i «3.7.3 The TEICLAS2.ENT File », se Element classes i kapittel 3 «Structure of the TEI Document Type Definition»
kap-18.1.4: Elementdefinisjon
Et element defineres i to deler; først elementets navn og innhold, og deretter dets attributter. Her er et eksempel på en elementdefinisjon hentet fra en av TEI-DTDene (teicore2.dtd).
<!ELEMENT foreign %om.RR; %paraContent;>
<!ATTLIST foreign
%a.global;>
I TEI-DTDene er parameterentiteter i utstrakt bruk, her er %om.RR; %paraContent; og %a.global; parameterentiteter. Parameterentiteter definerer visse felles egenskaper for et sett av elementer. F.eks. definerer %a.global; de fire vanlige, globale attributtene som er tillatt i alle elementer.
«%om.RR;» inneholder en oversikt over hvilken status start- og sluttaggene har (obligatorisk eller valgfri). Dette har kun betydning for SGML, i XML blir denne ignorert. Deretter følger innholdsmodellen, i dette tilfelle er det en såkalt «mixed contents», dvs. elementet <foreign> kan både innholde #PCDATA og andre elementer som er angitt i det DTD-fragmentet hvor parameterentiteten er definert.
«!ATTLIST» inneholder en oversikt over hvilke attributter elementet kan inneholde enten i form av en referanse til en attributtgruppe eller som en liste over tillatte attributter. I begge tilfeller inneholder «!ATTLIST» en oversikt over hvilke attributter som er tillatt, hvilken status de har (obligatoriske eller valgfrie) og hva slags innhold attributtverdiene kan ha (bokstaver, siffer, spesialtegn). I blant er verdiene spesifisert i attributtlista, og en default-verdi er oppgitt (gjelder f.eks. part="" i <l> som har verdiene «I», «M» og «F»). TEIform er et globalt attributt som definerer hvilket XML-navn elementet har Vha. dette attributtet kan man derfor bytte navn på elementet (f.eks. fornorske taggene), og via attributtverdien som er angitt i TEIform, angir man hvilket element det nye svarer til i de opprinnelige TEI-DTDene..
Hvis man ekspanderte disse parametrene ville deklarasjonen blitt slik i XML:
<!ELEMENT foreign
(#PCDATA | dimensions | locus | origDate | origPlace | msIdentifier
| material | signatures | catchwords | secFol | heraldry
| abbr | address | date | dateRange | dateStruct | expan
| geogName | measure | name | num | orgName | persName |
placeName | rs | time | timeRange | timeStruct | clarification
| add | app | corr | damage | del | orig | reg | restore
| sic | space | supplied | unclear | formula | fw | handShift
| distinct | emph | foreign | gloss | hi | mentioned | soCalled
| term | title | ptr | ref | xptr | xref | caesura | seg
| bibl | biblFull | biblStruct | castList | figure | cit
| q | quote | label | list | listBibl | note | witDetail
| stage | stageRole | camera | caption | move | sound |
tech | view | table | text | anchor | addSpan | delSpan
| gap | alt | altGrp | index | join | joinGrp | link | linkGrp
| timeline | cb | lb | milestone | pb)* >
<!ATTLIST foreign
corresp IDREFS #IMPLIED
synch IDREFS #IMPLIED
sameAs IDREF #IMPLIED
copyOf IDREF #IMPLIED
next IDREF #IMPLIED
prev IDREF #IMPLIED
exclude IDREFS #IMPLIED
select IDREFS #IMPLIED
id ID #IMPLIED
n CDATA #IMPLIED
lang IDREF #IMPLIED
rend CDATA #IMPLIED
TEIform CDATA "foreign" >
Det er slik det ser ut i den ferdige DTDen vår (ibsen-xml.dtd). Hvis man raskt vil se om et spesifikt element er tillatt i det elementet man ønsker å plassere det, er det derfor raskest og enklest å ta en kikk i ibsen-xml.dtd.
kap-18.1.5: Videre om elementdefinisjoner
Nedenfor følger en oversikt over hva tegnene man støter på i elementdefinisjonene betyr samt en gjennomgang av reglene for bruken av dem.
- «!ELEMENT»:
- «Minimization Rules» (markeres med - og 0) – regler for om sluttaggen er valgfri eller obligatorisk Bemerk at dette er fjernet i XML, hvor sluttagg alltid er påbudt, og at det derfor bare gjelder for SGML.. Bindestrek betyr at taggen er obligatorisk (starttagger er f.eks. alltid obligatoriske), en 0 betyr at den er valgfri. Hvis elementet er tomt («EMPTY»), kan det likevel ikke ha sluttagg selv om tegnkombinasjonen da alltid er «- 0». At elementet er tomt, og derfor ikke har noen sluttagg, defineres av ordet «EMPTY»
- «Content Model» – innholdsmodell (omsluttet av parenteser), dvs. en definisjon av hva elementet kan inneholde. Innholdsmodellen er rammet inn av parenteser og inneholder enten navnet på tillatte elementer eller på reserverte begreper (jf. om parameterentiteter ovenfor), som enten definerer et sett elementer (elementklasser) eller en spesiell type innhold (f.eks. tekst og elementer som <emph>, <hi> etc.)
- «Occurrence Indicators» markeres med *, + og ?, og er tegn som begrenser innholdet i elementet. I større innholdsmodeller kan det forekomme mange grupper av elementer og elementklasser, alle rammet inn av parenteser, og etterfulgt av enten *, + eller ?. * betyr at elementet kan inneholde n, flere eller ingen forekomster av elementet tegnet er knyttet til. + betyr n eller flere. ? betyr n eller ingen forekomster
- «Group Connectors» er tegnene |, & og ,. Dette er tegn som regulerer forholdet mellom de innholdselementene elementet kan inneholde. | betyr eksklusivt eller, altså enten dette innholdet eller dette, men ikke begge. & betyr eksklusivt og, dvs. alltid begge to & er ikke tillatt brukt i XML, og de innholdsdefinisjonene i TEI SGML som inneholder & er skrevet om for å være kompatible med XML i TEI XML.. Komma betyr at rekkefølgen på innholdselementene er obligatorisk slik den er angitt i innholdsmodellen.
I en og samme innholdsmodell kan disse tegnene kombineres til komplekse regulære uttrykk, se f.eks. definisjonen av <div>
- «!ATTLIST»:
Hva kan brukes som attributtverdier?- CDATA – Hvis DTD-en sier at attributtverdier skal være av typen CDATA betyr det at verdiene kan bestå av nesten hva som helst; verdiene kan inneholde entiteter, men ikke tagger. Dette er den mest brukte typen
- IDREF/IDREFS – Når DTD-en krever at attributtverdien for et bestemt attributt skal være av typen IDREF, betyr det at attributtverdien må være brukt som verdi for et id=""-attributt et annet sted i XML-filen. Attributtverdier av typen IDREF kan bestå av bokstaver og tall samt av enkelte andre tegn (bla. bindestrek). Dette er også en type vi har en del med å gjøre. Jf. for øvrig kap-18.2.4.1 «IDREF & IDREFS»
- NMTOKEN – Hvis DTD-en sier at attributtverdier skal være av typen NMTOKEN betyr det at verdiene kan bestå av alfanumeriske tegn. Denne typen ser vi sjeldent
- NUMBER – Hvis DTD-en sier at attributtverdier skal være av typen NUMBER betyr det at verdiene bare kan bestå av tall. Denne typen ser vi sjeldent
kap-18.2: Guide til DTD-endringer
kap-18.2.1: Grunnleggende
Endringene i TEI gjøres slik som det er angitt i kapittel 29 i TEI Guidelines: 29 Modifying and Customizing the TEI DTD. Se denne for en grundig innføring i modifisering av TEI.
Endringer i DTD-en gjøres i to ekstensjonsfiler og ikke i selve DTD-en. DTD-en lages på nytt vha. «pizzabakeren» etter at man har endret ekstensjonsfilene. Ekstensjonsfilene kan f.eks. hete ibsen.extensions_XX.ent og ibsen.extensions_XX.dtd, der XX angir hovedversjonsnummeret.
I ibsen.extensions_XX.dtd endrer man innholdsmodeller, tilføyer og utelukker attributter, endrer attributtdefinisjoner samt føyer til definisjoner av nye elementer. Hvis man trenger elementer fra et nytt subsett inkluderes dette når DTDen lages til vha. PizzaChef.
kap-18.2.2: Legge til nye elementer
Når man skal legge til et nytt element i DTD-en, gjør man bare endringer i ibsen.extensions_XX.dtd. Der føyer man til en nyskreven elementdefinisjon («content model») i avsnittet som er merket med <!-- The following elements are new -->. Elementene er sortert alfabetisk. Her er et eksempel på en elementdefinisjon prosjektet har laget.
<!ELEMENT printer %om.RO; (%phrase; | note)*>
<!ATTLIST printer %a.global;>
Å lage elementdefinisjoner krever en god del kunnskaper om DTDer, men som alt annet kan det læres. Først må man tenke nøye gjennom hva slags type element man skal lage og hva slags oppgaver det skal dekke. Deretter er det beste tipset nok å bruke eksisterende, gjerne liknende elementdefinisjoner som mal, og så klippe og lime sammen en ny innholdsmodell og en ny attributtliste på grunnlag (eller etter modell) av eksisterende materiale.
kap-18.2.3: Endre eksisterende elementer
Når man skal endre på eksisterende elementer, må man gjøre bruke av både ibsen.extensions_XX.ent og ibsen.extensions_XX.dtd. I ibsen.extensions_XX.ent ekskluderer man TEIs versjon av elementet med å føye til et eksklusjonsutsagn:
<!ENTITY % add 'IGNORE'>
Dette fjerner TEIs definisjon av elementet ved å negere den inklusjonen som gjøres i TEI-DTD-en, jfr. Elementdefinisjon, og derfor må hele elementdefinisjonen til elementet legges inn i ibsen.extensions_XX.dtd. Elementdefinisjonen henter man fra den TEI-DTD-en elementet hører til i originalt. Man kopierer med seg de to kodeparentesene som begynner med «!ELEMENT» og «!ATTLIST». Elementdefinisjonen plasseres deretter i ibsen.extensions_XX.dtd i det avsnittet som endringen hører hjemme i (endring av elementdefinisjon og attributtdefinisjon=avsnittet <!-- The following elements are revised -->; tilføye/utelukke attributter=avsnittet <!-- The following elements are extended -->). Deretter foretar man de ønskede endringene av elementet.
Det kan kreve en del leting å finne fram til akkurat den elementdefinisjonen man trenger. Et orienteringspunkt å gå ut fra, er hvilken del av dokumentet elementet brukes i eller hvilket taggsett elementet inngår i. Begge disse spørsmålene kan man finne svar på i TEI Guidelines.
Den enkleste måten å finne fram til elementdefinisjonen til det elementet man er ute etter, er ved å hente elementdefinisjonen fra TEI Guidelines, elementindeksen i kap. 35
kap-18.2.4.1: IDREF & IDREFS
Når man skal tillate flere attributtverdier for attributter som er definert som IDREF; definerer man attributtet som IDREFS i stedet for IDREF. Med andre ord, IDREF betyr at n id=""-attributtverdi er tillatt, IDREFS betyr at flere slike verdier er tillatt brukt.
kap-18.2.4.2: Attributter med forhåndsdefinerte verdier
En del av attributtene i TEI har forhåndsdefinerte verdier, dvs. at attributtverdiene er gitt i DTD-definisjonen av attributtet, slik som her:
an (Y | N | var) "var"
Når man skal lage nye slike attributter, må man huske på å definere en standardverdi (de tillatte attributtverdiene listes i parentesen, standardverdien angis i anførselstegn etter parentesen) for attributtet. Hvis ikke det blir gjort, er ikke DTD gyldig, og man får feilmeldinger av typen vist nedenfor (her er nsgmls brukt som valitator):
C:\Sp\bin\nsgmls.exe:C:\SGML\tei\ibsen-xml.dtd:304:1:W:
attribute value not a literal
C:\Sp\bin\nsgmls.exe:C:\SGML\tei\ibsen-xml.dtd:304:1:E:
value of attribute "an" cannot be "realMet"; must be one of "Y", "N", "var"
C:\Sp\bin\nsgmls.exe:C:\SGML\tei\ibsen-xml.dtd:304:15:E:
delimiter "#" invalid: only "CDATA", "ENTITIES", "ENTITY", "ID", "IDREF",
"IDREFS", "NAME", "NAMES", "NMTOKEN", "NMTOKENS", "NOTATION",
"NUMBER", "NUMBERS", "NUTOKEN", "NUTOKENS" and parameter separators
are allowed
Av feilmeldingene kan man lese at nsgmls oppfatter starten av neste attributtdefinisjon som del av den foregående (attributtet realMet="" er definert etter an="" i ATTLIST for <l>, <lg> og <lgSpan/> som har disse attributtene, jfr. nedenfor) og slik fortsetter den, jfr. tredje feilmelding.
an (Y | N | var) "var"
realMet CDATA #IMPLIED
Dette er for øvrig et godt eksempel på at en enkelt feil kan forårsake mange feilmeldinger.
kap-18.3: DTD-baking
kap-18.3.1: The Pizza Chef
I og med at TEI er et sett av DTD-fragmenter, så må man velge hvilke fragmenter man vil bruke for et gitt tekstmateriale. For å gjøre disse valgene og å få generert en DTD på bakgrunn av disse, bruker vi programmet TEI Pizza Chef - a TEI Tag Set Selector. TEI Pizza Chef er en programvare som er tilgjengelig på nettet. Selve «bakingen» går ut på å fylle inn et skjema, og å kopiere DTD-en som blir generert. Nedenfor finnes en oversikt over hvordan TEI Pizza Chef skal fylles ut for å generere DTD-en som brukes i HIS for koding av Ibsen-tekstene.
Gå først til TEI Pizza Chef, følg deretter instruksjonene gitt nedenfor:
- Step 1:
- kryss av for: mixed, og deretter for:
- drama
- prose
- verse
- kryss av for: mixed, og deretter for:
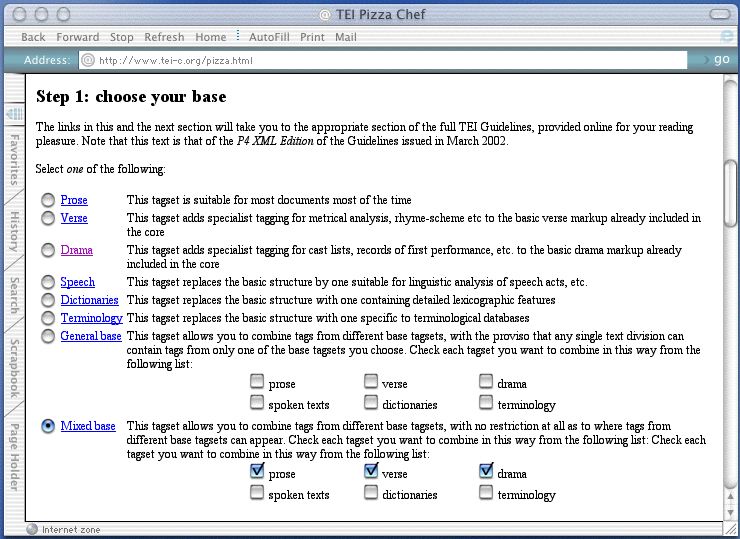
- Step 2: subsett:
- kryss av for:
- linking
- figures
- transcr
- textcrit
- names.dates
- corpora
- kryss av for:
- Step 3: tegnsett:
- velg:
- ISOlat1 – ISO Latin 1 (Western European languages)
- ISOnum – ISO Numeric and Special Graphic Characters (fractions, some superscript numerals, arithmetic operators, arrows, quotation marks)
- ISOdia – ISO Diacritics (acute, breve, caron, cedil, circ, tilde, uml, etc.)
- velg:
- Step 4 : hopp over dette punktet, går rett til neste!
- Step 5 : ekstensjonsfiler:
- velg alternativet hvor du supplerer filene selv, let deg fram til ibsen.extensions_XX.ent og ibsen.extensions_XX.dtd (velg åpne slik at filnavnene kommer opp i hver sin tekstboks)
- Klikk på knappen merket «Generate full DTD», kopier den ferdige DTD-en fra nettsida og erstatt den gamle DTD-teksten med den nye eller lagre til disk hvis nettleseren tilbyr det
kap-18.3.2: Testing og feilretting
Etter at du har laget ny DTD, må DTD-en testes. Prøv å validere en fil som i utgangspunktet var valid med den gamle DTD-en, men som nå inneholder koding som skal være tillatt i den nye DTD-en. Går det greitt, er det bare å annonsere at en ny versjon av DTD-en er klar. Går det derimot ikke greitt, må du begynne å lete etter feil.
Se først på hva slags feilmeldinger du får: Hvilken fil stammer feilmeldingene fra, XML-filen eller DTD-en? I begge tilfeller betyr feilmeldingene sannsynligvis at det er noe galt med DTD-en, men du bør for sikkerhets skyld sjekke feilmeldingene som kommer på XML-filen på vanlig måte; er det noe galt i kodingen? Hvis du ikke kan finne noe galt i kodingen, må du begynne å lete etter feil i DTD-en.
Noen ganger vil feilmeldingene være knyttet til feil som har oppstått i DTD-en da den ble laget i TEI Pizza Chef NB: Også pizzabakeren kan forårsake feil!. Slike feilmeldinger ser gjerne slik ut:
L2 pizza17069.ent <-- parse error, expecting `STRING' --> <!--* carthage found fatal error, aborting ... *--> <!--* Are you sure the URL you gave is correct? *-->
Sjekk følgende:
- Er det brukt tegn, f.eks. æøå, i ekstensjonsfilene som ikke finnes i ASCII? Det er lovlig i kommentarer i XML, men det går ikke igjennom The Pizza Chef siden programmet Cartago som brukes i genereringen av DTD-en ikke håndterer det
- Ikke bruk serier av bindestreker inne i kommentarer, det er ikke lovlig i XML. En bindestrek er greit, men altså ikke "--" inne i en kommentar
Finner du denne typen feilmeldinger i DTD-en, kan du først forsøke å fjerne dem, og så prøve å validere en fil med den rettede DTD-en. Hvis du ikke får feilmeldinger i validatoren nå, bør du først forsøke å lage en ny DTD med pizzabakeren og deretter, hvis feilmeldingene i DTD-en dukker opp på nytt, kontakte Tone Merete Bruvik eller Vemund Olstad på HIT-senteret for å forsøke å finne ut av hva som er galt. Man kan også sende en melding til den ansvarlige for Pizza Chefen, Lou Burnard.
Får du andre typer feilmeldinger om DTD-en, enten i selve DTD-en (som feilmeldingen som er sitert ovenfor) eller når du forsøker å validere XML-filer, må du rette opp i ibsen.extensions_XX.dtd eller ibsen.extensions_XX.ent og deretter lage ny DTD med pizzabakeren. Vi retter ikke direkte i den genererte DTD-en! Feilmeldinger som kan dukke opp, avhenger av hva slags type endringer du har gjort. Nedenfor følger en beskrivelse av feiltyper vi har hatt erfaring med.
Har du endret i et elements innholdsmodell og glemt å utelukke TEIs originale elementdefinisjon, vil du få feilmelding om dobbel elementdefinisjon («element already defined...»). Da mangler ibsen.extensions_XX.ent et <!ELEMENT ... "IGNORE">-utsagn for det aktuelle elementet.
Hvis du har endret i en innholdsmodell og får feilmelding av typen «ambigous content model» eller beskjed om at et eller flere elementer kommer i konflikt med hverandre, må du se nøye på hva slags endring du gjorde:
- Har du brukt riktig antall parenteser?
- Har du brukt riktige tegn til å skille elementene i innholdsmodellen fra hverandre (|, & eller ,)?
- Har du brukt riktig begrensningstegn (*, + eller ?)?
- Har du satt inn den nye delen av innholdsmodellen på den logisk riktige plassen?
- Sjekk hva elementklassene/innholdstypene som finnes i elementdefinisjonen kan inneholde; kanskje er det elementet du vil gjøre tillatt, allerede tillatt indirekte gjennom å være medlem av en elementklasse eller inngå i en av innholdstypene, jfr. nedenfor
Å finne feilen kan være vanskelig, spør Tone Merete Bruvik eller Vemund Olstad hvis du ikke kommer videre på egen hånd.
Noen feilmeldinger skyldes at elementet du er ute etter å inkludere i en innholdsmodell, allerede finnes der gjennom inklusjonen av en spesiell elementklasse. Dette kan skape kollisjoner i innholdsmodellen og dermed feilmeldinger når du bruker DTD-en. Sjekk posisjonen til det du inkluderer i forhold til det som finnes der fra før. Husk på at innholdsmodellen er et regulært uttrykk (slik som dem vi bruker i søk-erstatt-rutiner), og at når noe er galt med rekkefølgen eller skilletegnene, fungerer uttrykket rett og slett ikke slik det var ment.
Å finne ut av hvilke elementklasse et enkelt element tilhører, direkte eller indirekte, er en plundrete jobb; bruk kapitlene 33 til 35 i TEI Guidelines – før eller seinere klarer du å spore opp det du er ute etter!
kap-18.4: Dokument-headere
kap-18.4.1: XML
Alle XML-filer vi lager innledes med en dokument-header. Dokument-headeren inneholder opplysninger om hvilken versjon av TEI vi forholder oss til samt opplysning om hvilken DTD filen bruker.
Etter overgangen til XML er følgende header i bruk:
<!DOCTYPE TEI.2 PUBLIC "-//TEI P4 Ibsen-xml//DTD TEI P4 Unified for HIS//EN"
http://www.edd.uio.no:8088/his/DTD/ibsen-xml.dtd" >
Detaljer om tillegg som trengs i forbindelse med bilder, <rs>-koding, notefiler i hovedtekster osv. finnes i de respektive kapitlene om koding av dette.
kap-18.4.2: SGML
Filene kodes nå i XML, men siden det finnes SGML-arkiv over eldre stadier, er dokument-header slik den er brukt i SGML-filene dokumentert her. Dette er de to standard-headerne som vi benyttet til SGML-filene. I tillegg til dokument-headerne er DTDene listet opp.
<!DOCTYPE TEI.2 PUBLIC "-//TEI P3 Ibsen//DTD TEI P3 Unified for HIS//EN" [ tei\ibsen.dtd <!DOCTYPE TEI.2 PUBLIC "-//TEI P3 Ibsen-multitext//DTD TEI P3 Unified for HIS//EN" [ tei\ibsen-flertekst.dtd
Her er dokument-headerne som peker til DTDene som ble brukt til å sjekke sluttagger i sgml-filene.
<!DOCTYPE TEI.2 PUBLIC "-//TEI P3 Ibsen-endtag//DTD TEI P3 Unified for HIS//EN" [ tei\ibsen-sluttagg.dtd <!DOCTYPE TEI.2 PUBLIC "-//TEI P3 Ibsen-multitext-endtag//DTD TEI P3 Unified for HIS//EN" [ tei\ibsen-flertekst-sluttagg.dtd
kap-18.4.3: catalog-filen
Her er innførslene i catalog som knyttet dokumentheaderne til DTDene:
-- *********************************************************** --
-- Document Type Definitions --
-- *********************************************************** --
-- *********************************************************** --
-- Henrik Ibsen's Writings --
-- *********************************************************** --
PUBLIC "-//TEI P4 Ibsen-xml//DTD TEI P4 Unified for HIS//EN"
"tei\ibsen-xml.dtd"
-- *********************************************************** --
-- Henrik Ibsen's Writings' guidelines for encoding --
-- *********************************************************** --
<!DOCTYPE TEI.2 PUBLIC "-//TEI P4 Codebook//DTD TEI P4 Unified for HIW//EN"
"http://www.edd.uio.no:8088/his/DTD/Kodepraksis.dtd"
-- *********************************************************** --
-- Not in use anymore --
-- *********************************************************** --
PUBLIC "-//TEI P3 Ibsen//DTD TEI P3 Unified for HIS//EN"
"tei\ibsen.dtd"
PUBLIC "-//TEI P3 Ibsen-multitext//DTD TEI P3 Unified for HIS//EN"
"tei\ibsen-flertekst.dtd"
PUBLIC "-//TEI P3 Ibsen-endtag//DTD TEI P3 Unified for HIS//EN"
"tei\ibsen-sluttagg.dtd"
PUBLIC "-//TEI P3 Ibsen-multitext-endtag//DTD TEI P3 Unified for HIS//EN"
"tei\ibsen-flertekst-sluttagg.dtd"
PUBLIC "-//TEI//DTD TEI Lite XML ver. 1.1 Modified by HIW//EN"
"tei\derived\Kodepraksis.dtd"
PUBLIC "-//TEI P3 Codebook//DTD TEI P3 Unified for HIS//EN"
"tei\kodepraksis.dtd"
PUBLIC "-//TEI P3 Codebook-endtag//DTD TEI P3 Unified for HIS//EN"
"tei\kodepraksis-sluttagg.dtd"
Endringer gjort etter overgangen til XML dokumenteres her og i selve DTD-en. Den som ønsker å se nærmere på endringene kan ta en titt på DTDer og ekstensjonsfiler i Ibsen-DTDene på prosjektets hjemmesider. Her finnes det også et arkiv med ekstensjonsfiler og DTDer for SGML.
kap-18.5.1: Elementer med attributt-tillegg
Elementer der det er lagt til attributter, men der det ikke er andre endringer:
Vi har lagt til, og noen ganger også samtidig omdefinert, attributter. Dette er hovedsaklig gjort av to årsaker: enten fordi filologiske grunner har gjort at vi har ønsket å kode inn opplysningen, og/eller fordi det kodeteknisk forenkler kodingen å ha attributtet der. Det kan f.eks. være snakk om å validere attributtverdier og dermed unngå feilskrevne verdier, eller å kunne legge opplysning om hvilken hånd som har skrevet et avsnitt direkte i <p>, fordi det ikke er snakk om en tilføyelse (hvor man ville brukt <add>), men et håndskifte, og fordi det er enklere å prosessere hand-attributtet="" i <p> enn det tomme <handShift/>-elementet.
-
<app>
-
- attributtet alt="" (alteration) er lagt til (CDATA); til typologisering av endringer
- attributtet hand="" er lagt til (IDREF)
- attributtet subtype="" er lagt til (CDATA)
- attributtet type="" er endret til REQUIRED og gitt attributtverdiene 'alteration', 'external' og 'internal'
<cb>
- attributtet place="" er lagt til (CDATA) <date>
- attributtet hand="" er lagt til (IDREFS) <div>
- attributtet hand="" er lagt til (IDREFS) <emph>
- attributtet hand="" er lagt til (IDREFS) <figure>
- attributtet type="" er lagt til (CDATA) <hi>
- attributtet hand="" er lagt til (IDREFS) <l>
- attributtet type="" er lagt til (CDATA) <note>
- attributtet hand="" er lagt til (IDREFS) <p>
-
- attributtet type="" er lagt til (CDATA)
- attributtet hand="" er lagt til (IDREFS)
<rdg>
-
- nytt attributt var="" er lagt til (IMPLIED) for koding av variasjon (Y | N)
- attributtet wit="" er endret (fra CDATA til IDREFS) for å kunne validere attributtverdiene i det eksterne variantapparatet
<ref>
- attributtet hand="" er lagt til (IDREFS) <seg>
- attributtet hand="" er lagt til (IDREFS) <signed>
- attributtet hand="" er lagt til (IDREFS) <text>
- attributtet type="" er lagt til (CDATA) <variantEncoding>
- attributtet type="" er lagt til (REQUIRED) og gitt attributtverdiene 'alteration', 'external' og 'internal' <xptr/>
- nytt attributt url="" er lagt til for koding av nettadresser (CDATA) <xref>
- nytt attributt url="" er lagt til for koding av nettadresser (CDATA)
kap-18.5.2: Endringer i elementklasser
Dette omfatter endringer i elementklasser, dvs. endringer som får konsekvenser for alle elementer som bruker denne klassen.
-
a.metrical
- HIS har utvidet og standardisert kodingen for metrisk analyse. Lagt til attributtene realMet="", realRhyme="", an="", realAn="", first="". Dette gjør disse attributtene tilgjengelig i alle elementer som bruker a.metrical, dvs. <div> og <lg> a.readings
- wit="" er endret fra CDATA til IDREFS slik at attributtverdiene i det eksterne variantapparatet kan valideres x.data
- lagt <dateline> inn i x.data, hvilket gjør elementet tilgjengelig alle steder hvor m.data («groups phrase-level elements containing names, dates, numbers, measures, and similar data») er tilgjengelig. Dette er nødvendig av hensyn til Ibsen-brevenes struktur x.divtop
- lagt til det nye elementet <tune> i innholdsmodellen. Det gjør elementet tilgjengelig i alle elementer som bruker m.divtop, f.eks. i starten av <div> og <lg> x.edit
- lagt til elementet <clarification> i innholdsmodellen til m.edit, klassen for håndskriftselementer. Dette gjør elementet tilgjengelig i alle elementer som inneholder m.edit (som igjen inneholder <add> <app> <corr> <damage> <del> <orig> <reg> <restore> <sic> <space> <supplied> <unclear>) x.hqphrase
- lagt til det nye elementet <print> i innholdsmodellen. Dette gjør elementet tilgjengelig på samme sted som elementene i m.hqphrase (som inneholder <distinct> <emph> <foreign> <gloss> <hi> <mentioned> <soCalled> <term> <title>) x.Incl
- lagt til det nye elementet <diacrit/> i innholdsmodellen. Dette gjør dette elementet tilgjengelig i alle elementer som bruker m.Incl, f.eks. i <supplied> og <unclear>. Elementet brukes i hovedtekstkoding og forenkler <unclear>-kodingen
'x' foran navnet på klassen står (sannsynligvis) for «extension». og det er altså vha. slike utvidelsesklasser at man legger til elementer i en gitt elementklasse.
kap-18.5.3: Reviderte elementer
Revisjon av elementer betyr at innholdsmodellen («content model») er endret, og at eventuelt en (eller flere) attributtdefinisjon(er) er skrevet om. Det er angitt hvilket TEI-DTD-fragment hvert element tilhører.
De fleste av våre endringer skyldes at vi mener at noen for oss sentrale elementer burde være tillatt tilnærmet overalt. Det gjelder spesielt <add>, <app> (med følger for <lem> og <rdg>), <del> og <note>. Å tillate disse elementene på «inter level»-nivå har medført at vi må tillate mange elementer inne i dem også, jf. f.eks. nedenfor listen over de elementene som er lagt til i <add>. Noen av endringene skyldes også vårt krav til detaljnivå (diplomatarisk transkripsjon, dokumenterende koding) i koding av typografiske detaljer, se f.eks. <dateline> hvor bla. <emph>, <hi> og <print> er gjort tillatt. Vi har også ofte hatt en løsere kodestruktur som mål, siden vi ønsker å kode de historiske Ibsen-tekstene så nær original struktur som mulig, se f.eks. <castList>.
-
<actor>– teidrama2.dtd
- <note> er lagt til i innholdsmodellen <add> – teicore2.dtd
- <actor>, <castItem>, <cell>, <div>, <docImprint>, <head>, <item>, <row>, <salute>, <set>, <signed>, <speaker>, <spOpener> er inkludert <app>– teitc2.dtd
- <note> er lagt til sist i innholdsmodellen, alle Incl er fjernet siden vi aldri bruker elementene herfra direkte i <app> <author> – teicore2.dtd
- Vi har undertrykket TEIs definisjon i forbindelse med inklusjonen av MASTER (MASTERs er identisk med TEIs) <bibl> – teicore2.dtd
- vårt nye element <letterinfo> er lagt inn i innholdsmodellen <body> – teicore2.dtd
- Lagt til elementene <add>, <del>, <set> og <titlePage>. Elementet <note> er gjort tillatt mellom <div>-elementer <byline> – teistr2.dtd
- vårt nye element <composer> er lagt inn i innholdsmodellen <castGroup> – teidram2.dtd
- Innholdsmodellen er endret til mixed content, siden PCDATA er inkludert. I tillegg er <add>, <app>, <del> og <roleDesc> inkludert. Elementet kan nå inneholde <add>, <app>, <castGroup>, <castItem>, <del>, <fw>, <head>, <hi>, <lb>, <note>, <pb>, <roleDesc>, <trailer> og PCDATA <castItem> – teidram2.dtd
- <note> er lagt til i innholdsmodellen <castList> – teidram2.dtd
- <add>, <app> og <del> er lagt til i innholdsmodellen. Innholdsmodellen er gjort løsere slik at f.eks. <figure> kan komme mellom <castItem> <closer> – teistr2.dtd
- <dateline> fjernet siden det er lagt til i x.data <corr> – teicore2s.dtd
- Innholdsmodellen er løst opp. <docEdition>, <salute>, <signed>, <speaker> og <spOpener> er lagt til i innholdsmodellen. Nytt attributt: wit="". Endringene er gjort av hensyn til kodingen av trykte tekster med håndskrevne rettelser <date> – teicore2.dtd
- <note> er lagt til i innholdsmodellen <dateline> – teistr2.dtd
- <app>, <del>, <emph>, <hi>, <print>, <rs>, <sic> og <xref> er lagt til i innholdsmodellen. Endringene er gjort for å gjøre brevkodingen mer diplomatarisk <del> – teicore2.dtd
- m.Incl, <blockSeg>, <byline>, <castItem>, <div>, <docAuthor>, <head>, <l>, <lg>, <note>, <p>, <stage>, <sp>, <speaker>, <spOpener> og <stageRole> er lagt til i innholdsmodellen <div> – teicore2.dtd
- inkludert ny elementklasse kalt n.divElementsAdded (inneholder <add>, <app>, <blockSeg>, <corr>, <del>, <note>, <ref>, <space>) hvor alle elementer kan være første element i <div>. <lg> og <sp> lagt til på samme nivå som <div> og <divpart>, dvs. at <lg> og <div> blir likestilt. Dette er gjort av hensyn til koding av metrisk struktur. <envelope> lagt til <docImprint> – teifron2.dtd
- <printer> og <note> er tilføyd <docTitle> – teifron2.dtd
- <add> er lagt til i innholdsmodellen <editorialDecl> – teihdr2.dtd
- det nye elementet <typography> er tilføyd <front> – teifron2.dtd
- <add>, <app>, <del>, <envelope> og <note> er lagt til i innholdsmodellen <fw> – teitran2.dtd
- m.fragmentary er fjernet fra innholdsmodellen, <note> er lagt til i innholdsmodellen <group> – teistr2.dtd
- <note> er lagt til i innholdsmodellen <hand> – teitran2.dtd
- innholdsmodellen er skrevet om slik at elementet ikke lenger er tomt og slik at det kan inneholde <p>. Vi kan dermed føre inn mer detaljerte opplysninger om hvor og hvordan etc. hender finnes <headItem>– teicore2.dtd
- <note> er lagt til i innholdsmodellen <hi> – teicore2.dtd
- <speaker>, <stageRole> er lagt til i innholdsmodellen <imprint> – teicore2.dtd
- det nye elementet <printer> er tilføyd <lem> – teitc2.dtd
- m.Incl, <actor>, <castItem>, <speaker> er lagt til i innholdsmodellen <lg> – teicore2.dtd
- <add>, <app>, <del>, <note>, <opener> og <stage> er inkludert, i tillegg til <div> og <sp> som kan være eneste underelementer <list>– teicore2.dtd
- <add>, <app>, <del> og <note> er lagt til i innholdsmodellen. <add> er dessuten gjort tillatt mellom <item>-tagger <listBibl>– teicore2.dtd
- <msDescription> fra MASTER er lagt til i innholdsmodellen. <opener>– teistr2.dtd
- <note> er lagt til i innholdsmodellen, <dateline> er fjernet, siden det er lagt inn i x.data, noe som gjør elementet tilgjengelig i m.phrase og dermed i <opener> <performance> – teidram2.dtd
- <add>, <app> og <del> er lagt til i innholdsmodellen <publisher> – teicore2.dtd
- <note> er lagt til i innholdsmodellen <q> – teicore2.dtd
- who="" er endret fra CDATA til IDREFS slik at attributtverdiene kan valideres <quote> – teicore2.dtd
- løst opp specialPara og lagt til <head> i innholdsmodellen <rdg> – teitc2.dtd
- <castItem>, <docImprint>, <docAuthor>, <l>, <p>, <role>, <roleDesc>, <sp>, <speaker>, <spOpener>, <stageRole>, <titlePage> er inkludert <role> – teidram2.dtd
- <note> er lagt til i innholdsmodellen <roleDesc> – teidram2.dtd
- <note> er lagt til i innholdsmodellen <row>
- <add>, <del> lagt til i innholdsmodellen <salute> – teistr2.dtd
- <note> er lagt til i innholdsmodellen <sp> – teicore2.dtd
- m.Incl er lagt til og elementer som hører til i dette er fjernet. <ref>, <restore> og <spOpener> er lagt til i innholdsmodellen <speaker> – teicore2.dtd
- <note> er lagt til i innholdsmodellen <stage> – teicore2.dtd
- <stageRole> er lagt til i innholdsmodellen, specialPara ble løst opp for å få det til <table> – teifig2.dtd
- <add> er lagt til i innholdsmodellen <text> – teistr2.dtd
- <note> er lagt til i innholdsmodellen <titlePage> – teifron2.dtd
- <add>, <app>, <corr>, <del> og <note> er lagt til i innholdsmodellen <xref> – teilink2.dtd
- løste opp paracontent og la til <role> i innholdsmodellen
kap-18.5.4: Fjernede elementer
Disse elementene er fjernet.
-
<div0> – <div7>
- HIS bruker bare <div>. Istedenfor et nummerert hierarki av <div>-elementer, foretrekker vi å definere innholdet vha. type="". Det forenkler transformering vha. stilark, siden type="" forteller hva <div> inneholder uavhengig av plassering i kodestrukturen <lg1> – <lg5>
- HIS bruker bare <lg>. Bak denne endringen ligger samme argumentasjon som ovenfor for <div> <addSpan>/<delSpan>
- HIS har utelukket <addSpan> og <delSpan>, siden vi betrakter <add> og <del> som «inter level»-elementer, og har gjort det vi må for å tillate <add> og <del> der vi trenger dem
Nye elementer: Vi lager nye elementer når vi ikke finner det vi trenger i TEI P4. I hovedsak lager vi bare elementer basert på manglende detaljnivå i kodinga av en spesifikk teksttype, f.eks. er det laget en del til brevkoding.
Nye elementklasser: Vi har laget en ny elementklasse, n.divElementsAdded. Den har parallell funksjon med TEIs Incl-klasse, som inneholder elementer som skal være tilgjengelig mange steder. Tilsvarende har vi hatt behov for å tillate noen elementer flere steder enn de originalt er tillatt. Vi har utvidet bruksområdet til disse elementene fordi vi mener at de burde være tillatt mange flere steder. Spesielt gjelder det <add>, <app> og <del>, som vi mener skulle vært definert som såkalte «inter level»-elementer, dvs. elementer som både kan brukes inne i tekst og utenfor, der tekst ikke er tillatt.
kap-18.6.1: Nye elementer
Legg inn litt om når og hvorfor nye elementer er lagt til.
blockSeg
element som har samme funksjon som <seg>, men som er et block-element. Blir brukt i manuskriptkoding til koding av omrokkeringer av linjer. Opprettet 16.05 2006
- Attributter
- hand
angir hånden som har flyttet om på linjene
- Datatype: IDREFS
- Default-verdi: %INHERITED
- type
for verdier, se attributtverdilista
- Datatype: CDATA
- Default-verdi: #IMPLIED
- Elementdefinisjon
- <!ELEMENT blockSeg %om.RR; (%m.refsys; | add | app | blockSeg | del | castItem | join | l | note | sp | stage)* >
- Attributtdefinisjon
- <!list blockSeg hand IDREFS #IMPLIED type CDATA #IMPLIED %a.global;
clarification
element som skal inneholde tilfeller av tydeliggjøring i håndskriftsmateriale. Vedtatt på Sisyfosmøte 14.12 1999
- hand
angir hånden som har tydeliggjort der hvor denne er en annen enn hovedhånden
- Datatype: IDREF
- Default-verdi: %INHERITED
- place
lagt til 2001; vi fant ut at tydeliggjøringer noen ganger er gjort utenfor linja og vi ønsket å ta vare på informasjon om dette
- Datatype: CDATA
- Default-verdi: #IMPLIED
- Elementdefinisjon
- <!ELEMENT clarification %om.RR; (#PCDATA | %m.Incl; | add | corr | del | hi | speaker)* >
- Attributtdefinisjon
- <!list clarification %a.global; resp IDREF %INHERITED; cert CDATA #IMPLIED hand IDREF %INHERITED; place CDATA #IMPLIED
composer
element til koding av informasjon om komponist. Inneholder bare globale attributter. Inkludert 18.12 2002
- Elementdefinisjon
- <!ELEMENT composer %om.RR; (#PCDATA | note)* >
- Attributtdefinisjon
- <!list composer %a.global;>
diacrit
(diacritical brackets) element til typopgrafisk hardkoding av klammeparenteser for markering av uklar tekst i hovedtekster. Inneholder globale attributter og type=""-attributt med faste verdier. Inkludert 23.08 2004
- type
Attributtverdiene angir start- («left») eller sluttklamme («right»)
- Datatype: left | right
- Default-verdi: #IMPLIED
- Elementdefinisjon
- <!ELEMENT diacrit %om.RO; EMPTY>
- Attributtdefinisjon
- <!list diacrit %a.global; type (left | right) #IMPLIED>
envelope
element til koding av konvolutter. Har bare globale attributter. Inkludert 15.05 2003
- Elementdefinisjon
- <!ELEMENT envelope %om.RR; (postmark | minAddress | div | head | p | lb | note | pb )* >
- Attributtdefinisjon
- <!list envelope type CDATA #IMPLIED %a.global;>
letterinfo
(letter information) element til bruk i <bibl> og <msDescription>, for å beskrive brev. Inkludert 18.12 2002
- type
- Datatype: letter | visitingCard | telegram | poem | postcard
- Default-verdi: #IMPLIED
- Elementdefinisjon
- <!ELEMENT letterinfo %om.RR; (sender | recipient | origPlace | origDate | lettertype | translation | matDesc | note | %m.Incl;)* >
- Attributtdefinisjon
- <!list letterinfo %a.global; type (letter | visitingCard | telegram | poem) #IMPLIED>
lettertype
(type of letter) element til bruk i <letterinfo> i hovedtekstkoding, inneholder opplysning om brevtypen «telegram». Har bare globale attributter. Inkludert 08.06.2007
- Elementdefinisjon
- <!ELEMENT lettertype %om.RR; (#PCDATA) >
- Attributtdefinisjon
- <!list lettertype %a.global; >
matDesc
(material description) element til bruk i <msHeading>, for kort å beskrive håndskriftsmateriale. Har bare globale attributter. Inkludert 14.02 2002
- Elementdefinisjon
- <!ELEMENT matDesc %om.RR; (#PCDATA | note | xref)* >
- Attributtdefinisjon
- <!list matDesc %a.global;>
minAddress
(minimal address) element til bruk i <envelope>, for koding av minimale adresseopplysninger. Elementet kommer i tillegg til TEI-elementet <address>, som har et mye mer komplekst innhold. Har bare globale attributter. Inkludert 15.05 2003
- Elementdefinisjon
- <!ELEMENT minAddress %om.RR; (#PCDATA | %m.Incl; | %m.edit; | hi | note | addrLine)* >
- Attributtdefinisjon
- <!list minAddress %a.global;>
postmark
element til koding av frimerker og poststempler på konvolutter. Inneholder <postmarkDesc>. Har bare globale attributter. Inkludert 15.05 2003
- Elementdefinisjon
- <!ELEMENT postmark %om.RR; (postmarkDesc)* >
- Attributtdefinisjon
- <!list postmark %a.global;>
postmarkDesc
(postmark description) element til beskrivelse av frimerker og poststempler på konvolutter. Har bare globale attributter. Inkludert 15.05 2003
- Elementdefinisjon
- <!ELEMENT postmarkDesc %om.RR; (#PCDATA | note | xref)* >
- Attributtdefinisjon
- <!list postmarkDesc %a.global;>
print
(printed matter) element til koding av trykt tekst i brev (navn på visittkort, brevhoder etc.). Har bare globale attributter. Inkludert 27.05 2003
- Elementdefinisjon
- <!ELEMENT print %om.RR; (#PCDATA | hi | note | lb | rs | clarification | anchor | pb | del )* >
- Attributtdefinisjon
- <!list print %a.global;>
printer
element til koding av opplysning om trykker på tittelblad og trykker i <sourceDesc> i <teiHeader>. Har bare globale attributter. Inkludert 05.04 2003
- Elementdefinisjon
- <!ELEMENT printer %om.RO; (%phrase; | note)*>
- Attributtdefinisjon
- <!list printer %a.global;>
recipient
element til bruk i <letterinfo>, for å oppgi mottaker. Har bare globale attributter. Inkludert 18.12 2002
- Elementdefinisjon
- <!ELEMENT recipient %om.RR; (#PCDATA | note | rs | %m.Incl;)* >
- Attributtdefinisjon
- <!list recipient %a.global;>
sender
element til bruk i <letterinfo>, for å oppgi avsender. Har bare globale attributter. Inkludert 18.12 2002
- Elementdefinisjon
- <!ELEMENT sender %om.RR; (#PCDATA | note | rs | %m.Incl;)* >
- Attributtdefinisjon
- <!list sender %a.global;>
spOpener
(speech opener) samler tekstelementene som åpner replikken, vanligvis rollenavn og sceneanvisning. Har bare globale attributter. Vedtatt på Sisyfosmøte 26.10 1999
- Elementdefinisjon
- <!ELEMENT spOpener %om.RR; (#PCDATA | lb | pb | fw | note | speaker | stage | hi | corr | unclear | xptr | addSpan | delSpan | add | app | del)* >
- Attributtdefinisjon
- <!list spOpener %a.global;>
stageRole
er et element for koding av typografisk markerte handlingselementer (rollenavn/-betegnelser) i sceneanvisninger (og bare der), kan inneholde attributtet who="". Vedtatt på Sisyfosmøte 26.10 1999
- who
attributtverdien i who="" peker til en id=""-verdi et annet sted i samme XML-fil, vanligvis i innførslene i rollelista. Brukes når rollen er identifiserbar.
- Datatype: IDREFS
- Default-verdi: #IMPLIED
- Elementdefinisjon
- <!ELEMENT stageRole %om.RR; (#PCDATA | %m.phrase; | %m.inter; | %m.Incl;)* >
- Attributtdefinisjon
- <!list stageRole %a.global; who IDREFS #IMPLIED >
translation
element til bruk i <letterinfo>, for å angi at oversettelse finnes i kommentarbind, brukes i hovedtekstkoding av brev. Har bare globale attributter. Inkludert 08.06.2007
- Elementdefinisjon
- <!ELEMENT translation %om.RR; (#PCDATA) >
- Attributtdefinisjon
- <!list lettertype %a.global; >
tune
til melodiangivelse i f.eks. <div> og <lg>, innholdsmodell som for <salute>. Har bare globale attributter. Inkludert 12.07 2002
- Elementdefinisjon
- <!ELEMENT tune %om.RR; (%phrase; | note | composer)* >
- Attributtdefinisjon
- <!list tune %a.global;>
typography
til beskrivelsen av en tekstkildes typografi (trykt tekst) eller grafiske oppsett (manuskript) i <teiHeader>, kan inneholde <list>, <p> og <note>. Vi bruker <list> og evt. <note>. Har bare globale attributter. Vedtatt på kodemøte 25.11 1999
- Elementdefinisjon
- <!ELEMENT typography %om.RR; (note | list | p)* >
- Attributtdefinisjon
- <!list typography %a.global;>
kap-18.6.2: Nye elementklasser
n.divElementsAdded (elements added to div)
samleklasse (type: model class) for elementer tilføyd i <div>, foreløpig inneholder den disse elementene: <add>, <app>, <corr>, <del>, <note>, <ref>, <space>. Inkludert 26.04 2004
kap-18.7: Entiteter definert i Ibsen-DTD-en
Vi definerer entiteter på pragmatisk grunnlag: Hvis et tegn ikke lar seg skrive på tastaturet, eller hvis det ikke blir vist riktig i visningene våre eller vi er redd det kan bli problemer i HISb eller HISe, lager vi en entitet for det. Vi forsøker å holde oss til standard-entiteter der de finnes.
acuteCentre
(acute accent)
Acute aksent brukt typografisk som skilletegn. Inkludert 20.09 2005
Tegnstreng: '´'
Entitetstype: general entity
Entitetstype: general entity
alphaacute
(greek small letter alpha with dasia)
Entitet for gresk tegn. Inkludert 04.09 2007
Tegnstreng: 'ἁ'
Entitetstype: general entity
an
(modified letter vertical line)
Settes inn foran stavelsestall i den metriske formelen ved opptakt. Brukes i «vasking» av metrikkfiler, for å gi korrekt visning av metrisk notasjon. Inkludert 09.01 2004
Tegnstreng: 'ˈ'
Entitetstype: general entity
bue
(union)
Brukes for trykksvak stavelse. Brukes i «vasking» av metrikkfiler, for å gi korrekt visning av metrisk notasjon. Inkludert 09.01 2004
Tegnstreng: '∪'
Entitetstype: general entity
bull
(bullet)
Brukes til å skille mellom deler av tekstkritisk note (hører til ISO-pub.ent). Inkludert 19.05 2005
Tegnstreng: '•'
Entitetstype: general entity
ccaron
('c' med caron)
Satt til UNICODE-verdien 010D (hører til i ISO-lat2.ent). Inkludert 21.10 2004
Tegnstreng: 'č'
Entitetstype: general entity
corrMark
(Ibsens korrekturtegn i PG85-teaterms-pe (trykt tekst med egenhendige rettelser))
Satt til UNICODE-verdien 2625 ('ankh'). Inkludert 16.06 2006
Tegnstreng: '☥'
Entitetstype: general entity
cyrilE
(cyrillic capital letter E)
Satt til UNICODE-verdien 042D. Inkludert 01.12.2008
Tegnstreng: 'Э'
Entitetstype: general entity
cyrilel
(cyrillic small letter el)
Satt til UNICODE-verdien 043B. Inkludert 01.12.2008
Tegnstreng: 'л'
Entitetstype: general entity
cyrilem
(cyrillic small letter em)
Satt til UNICODE-verdien 043C. Inkludert 01.12.2008
Tegnstreng: 'м'
Entitetstype: general entity
cyrilen
(cyrillic small letter en)
Satt til UNICODE-verdien 043D. Inkludert 01.12.2008
Tegnstreng: 'н'
Entitetstype: general entity
cyrilhard
(cyrillic small letter hard sign)
Satt til UNICODE-verdien 044A. Inkludert 01.12.2008
Tegnstreng: 'ъ'
Entitetstype: general entity
cyrilsoft
(cyrillic small letter hard sign)
Satt til UNICODE-verdien 044C. Inkludert 01.12.2008
Tegnstreng: 'ь'
Entitetstype: general entity
cyrilGHE
(cyrillic captial letter GHE)
Satt til UNICODE-verdien 0413. Inkludert 01.12.2008
Tegnstreng: 'Г'
Entitetstype: general entity
cyrilPE
(cyrillic captial letter PE)
Satt til UNICODE-verdien 041F. Inkludert 01.12.2008
Tegnstreng: 'П'
Entitetstype: general entity
cyrilya
(cyrillic small letter ya)
Satt til UNICODE-verdien 044F. Inkludert 01.12.2008
Tegnstreng: 'я'
Entitetstype: general entity
cyrilzhe
(cyrillic small letter zhe)
Satt til UNICODE-verdien 0436. Inkludert 01.12.2008
Tegnstreng: 'ж'
Entitetstype: general entity
cyrilka
(cyrillic small letter ka)
Satt til UNICODE-verdien 043A. Inkludert 01.12.2008
Tegnstreng: 'к'
Entitetstype: general entity
cyrilve
(cyrillic small letter ve)
Satt til UNICODE-verdien 0432. Inkludert 01.12.2008
Tegnstreng: 'в'
Entitetstype: general entity
cyrilNo
(numero sign)
Satt til UNICODE-verdien 2116. Inkludert 03.12.2008
Tegnstreng: '№'
Entitetstype: general entity
dash
(tankestrek)
Satt til UNICODE-verdien 2013, også kalt EN DASH. Inkludert 11.07 2002
Tegnstreng: '–'
Entitetstype: general entity
edot
(e med prikk over)
Satt til UNICODE-verdien 0117. Inkludert 06.12 2006
Tegnstreng: 'ė'
Entitetstype: general entity
ergo
(latin small letter open o)
Satt til UNICODE-verdien 0254. Inkludert 03.12 2008
Tegnstreng: 'ɔ'
Entitetstype: general entity
finalsigma
(greek small letter final sigma)
Entitet for gresk tegn. Inkludert 04.09 2007
Tegnstreng: 'ς'
Entitetstype: general entity
foot
(metrisk apostrof)
Satt til UNICODE-verdien 0027. Inkludert 29.08 2005
Tegnstreng: '''
Entitetstype: general entity
frac45
(vulgar fraction four fifths)
Satt til UNICODE-verdien 2158. Inkludert 19.09 2005
Tegnstreng: '⅘'
Entitetstype: general entity
hellip
(lakunetegn)
Satt til UNICODE-verdien 2026 (...=horizontal ellipsis). Inkludert 29.08 2005
Tegnstreng: '…'
Entitetstype: general entity
iota
(greek small letter iota)
Entitet for gresk tegn. Inkludert 04.09 2007
Tegnstreng: 'ι'
Entitetstype: general entity
ksi
(greek small letter xi)
Entitet for gresk tegn. Inkludert 04.09 2007
Tegnstreng: 'ξ'
Entitetstype: general entity
lapo
(left single quotation mark)
Satt til UNICODE-verdien 2018 (=lsquo). Inkludert 29.08 2005
Tegnstreng: '‘'
Entitetstype: general entity
lquo
(left pointing double angle quotation mark)
Satt til UNICODE-verdien 00AB. Inkludert 11.07 2002
Tegnstreng: '«'
Entitetstype: general entity
lsaquo
(left pointing single angle quotation mark)
Satt til UNICODE-verdien 2039. Inkludert 29.08 2005
Tegnstreng: '‹'
Entitetstype: general entity
mark
(–)
Historisk valutategn for mark. Inkludert 03.05 2004
Tegnstreng: 'Ֆ'
Entitetstype: general entity
mbar
('m' med nasalstrek)
'm' med nasalstrek (combination of 'm' and unicode combining overline), dvs. forkortet dobbelkonsonant. Inkludert 18.12 2002
Tegnstreng: 'm̅'
Entitetstype: general entity
metDash
(metrisk tankestrek)
metrisk tankestrek (ndash used as metrical dash). Inkludert 07.03 2007
Tegnstreng: 'n–'
Entitetstype: general entity
My
(greek capital letter mu)
Entitet for gresk tegn. Inkludert 04.09 2007
Tegnstreng: 'Μ'
Entitetstype: general entity
my
(greek small letter mu)
Entitet for gresk tegn. Inkludert 04.09 2007
Tegnstreng: 'μ'
Entitetstype: general entity
nbar
('n' med nasalstrek)
'n' med nasalstrek (combination of 'n' and unicode combining overline), dvs. forkortet dobbelkonsonant. Inkludert 17.04 2006
Tegnstreng: 'n̅'
Entitetstype: general entity
okvist
(latin small letter o with ogoneke)
'o' med kvist. Inkludert 15.10 2004
Tegnstreng: 'ǫ'
Entitetstype: general entity
Okvist
(latin capital letter o with ogoneke)
'O' med kvist. Inkludert 06.02 2006
Tegnstreng: 'Ǫ'
Entitetstype: general entity
omacr
(latin small letter o with macron)
Satt til UNICODE-verdien 014D (fra iso-lat2.ent). Inkludert 29.08 2005
Tegnstreng: 'ō'
Entitetstype: general entity
omikron
(greek small letter omicron)
Entitet for gresk tegn. Inkludert 04.09 2007
Tegnstreng: 'ο'
Entitetstype: general entity
rapo
(right single quotation mark)
Satt til UNICODE-verdien 2019 (=rsquo). Inkludert 29.08 2005
Tegnstreng: '’'
Entitetstype: general entity
rcaron
(latin small letter r with caron)
Satt til UNICODE-verdien 0159 (fra iso-lat2.ent). Inkludert 11.09 2007
Tegnstreng: 'ř'
Entitetstype: general entity
referenceMark
(reference mark)
Satt til UNICODE-verdien 203B. Inkludert 25.04 2007
Tegnstreng: '※'
Entitetstype: general entity
rep
(repetisjonstegn)
Repetisjonstegn (quotation mark). Inkludert 09.01 2004
Tegnstreng: '"'
Entitetstype: general entity
rquo
(right pointing double angle quotation mark)
Satt til UNICODE-verdien 00BB. Inkludert 11.07 2002
Tegnstreng: '»'
Entitetstype: general entity
rsaquo
(right pointing single angle quotation mark)
Satt til UNICODE-verdien 203A. Inkludert 29.08 2005
Tegnstreng: '›'
Entitetstype: general entity
skilling
(–)
Historisk valutategn for skilling. Inkludert 03.05 2004
Tegnstreng: 'ʄ'
Entitetstype: general entity
supn
(–)
sup-entitetene brukes for opphøyde tegn i formler. Brukes i «vasking» av metrikkfiler, for å gi korrekt visning av metrisk notasjon. Inkludert 09.01 2004
Tegnstreng: 'ⁿ'
Entitetstype: general entity
titleColon
(–)
titleColon (standard UNICODE-kolon) brukes for å skille fra hverandre deler i titler i kommentarbindene. Inkludert 14.04 2005
Tegnstreng: ':'
Entitetstype: general entity
tu20
(20 typographical units)
Brukes til å kode mellomrom som skal være smalere enn vanlige ord-mellomrom og som ikke skal brekkes. Inkludert 10.01 2006
Tegnstreng: ' '
Entitetstype: general entity
typHyp
(typographical hyphen)
typHyp-entiteten erstatter HIS' opprinnelige shy-entitet og er definert som UNICODEs vanlige bindestrek. Inkludert 17.12 2004
Tegnstreng: '‐'
Entitetstype: general entity
vcaron
(combination of latin small letter v and caron)
Satt til v + UNICODE-verdien 02C7. Inkludert 11.09 2007
Tegnstreng: 'vˇ'
Entitetstype: general entity
z/Zcaron
('z/Z' med caron)
Satt til UNICODE-verdien x017E/x017D (hører til i ISO-lat2.ent). Inkludert 19.04.2005
Tegnstreng: 'ž/x017D;'
Entitetstype: general entity
kap-18.8: Endringer fra MASTER
Deler av MASTERs (Manuscript Access through Standards for Electronic Records) DTD er tatt inn i Ibsen-DTD-en. Se Reference Manual for the MASTER Document Type Definition for en fyldestgjørende dokumentasjon av MASTER. Her gis bare et resym av hvilke elementer som er endret og lagt til, og hvilke entitetsklasser som er endret pga. at MASTER er inkludert i Ibsen-DTD-en. Vi har ønsket å inkludere kodingen fordi den ga oss bedre mulighet til å legge inn bibliografiske opplysninger for manuskripter enn TEI P4 gjør. I TEI P5 er MASTERs koding tatt inn og gjort offisiell.
kap-18.8.1: Elementer i MASTER tatt inn i HIS
Disse elementene fra MASTER har vi lagt til i Ibsen-DTD-en.
-
<msDescription>
- Brukes i <sourceDesc> i <teiHeader>. Har underelementene <msIdentifier>, <msHeading>, <msContents>, <physDesc>, <history>, <additional>, <msPart>, <letterinfo>, <dateRange>
kap-18.8.2: Elementer lagt til av HIS i MASTER
Disse elementene har vi lagt til i de delene av MASTER som vi har inkludert i Ibsen-DTD-en.
-
<letterinfo>
- inkluderer elementene <sender>, <recipient>, <origDate>, <origPlace>, <matDesc> og <note>. Brukes i <msDescription> <matDesc>
- nytt element til bruk direkte i <msHeading>, for å beskrive håndskriftsmateriale. Elementet er også inkludert i <letterinfo>, jf. over
kap-18.8.3: Elementer endret i MASTER
Disse elementene er endret i MASTER, og blir derfor også endret i Ibsen-DTD-en.
-
<birth>
<form>
<name>
<occupation>
<person>
<personGrp>
<residence>
<sourceDesc>
kap-18.8.4: Entitetsklasser som er endret i MASTER
Entitetsklasser som er endret i MASTER, og derfor også i Ibsen-DTD-en.
-
<n.particDesc>
<x.chunk>
<x.phrase>
<x.names>
<a.datable>
<a.measured>
kap-18.9: DTD for dokumentasjon av kodepraksis
Dokumentasjonen av kodepraksis er også skrevet i XML og i TEI, men det er brukt en noe enklere DTD. DTD-en for kodepraksis er også laget ved hjelp av TEI Pizza Chef, men med følgende settinger:
- Step 1:
- Bruk standardvalget, Prose.
- Step 2: subsett:
- Bruk standardvalgene:
- Linking
- Figures
- Analysis
- Bruk standardvalgene:
- Step 3: tegnsett:
- Velg:
- ISOlat1 – ISO Latin 1 (Western European languages)
- ISOnum – ISO Numeric and Special Graphic Characters (fractions, some superscript numerals, arithmetic operators, arrows, quotation marks)
- Velg:
- Step 4 : hopp over dette punktet, går rett til neste
- Step 5 : ekstensjonsfiler:
- velg alternativet hvor du supplerer filene selv, let deg fram til kodepraksis.extensions_XX.ent og kodepraksis.extensions_XX.dtd
Det er gjort to viktige endringer i ekstensjonsfilene, nytt attributt url er lagt til i <xptr> og <xref>, for å tillate HTML-lenker, og elementer definert i taggsettet Auxiliary DTD for tag set documentation, se Tag Set Documentation, er tatt inn (<tagDoc>, <entDoc> og <classDoc> brukes i <div>).
Her er dokumentheaderen til kodepraksisdokumentene:
<?xml version="1.0" encoding="iso-8859-1"?>
<?xml-stylesheet type="text/xsl" href="http://www.edd.uio.no/cocoon/ibsen01_03/his/DTD/Kodepraksis/praksis.xsl"?>
<!DOCTYPE TEI.2 PUBLIC "-//TEI P4 Codebook//DTD TEI P4 Unified for HIW//EN"
"http://www.edd.uio.no:8088/his/DTD/Kodepraksis.dtd" [
<!ENTITY % HIScodebook_figures SYSTEM
'http://www.edd.uio.no:8088/his/Kodepraksis/HIScodebook_figures.ent'>
%HIScodebook_figures;
]>
kap-19: Attributtverdier
Dette kapitlet inneholder en oversikt over hvilke attributtverdier som er i bruk.
kap-19.1: Innledende bemerkninger
Dette dokumentet inneholder såkalte gyldige attributtverdier, det vil si de attributtverdiene som er i bruk.
Se kodebøkene for riktig bruk av elementer, attributter og attributtverdier.
(Vi kodet tidligere flere tekstvitner inn i samme fil (flertekstfiler). Attributtverdier knyttet til denne kodingen finnes ikke lenger i dette dokumentet, men de er dokumentert i en arkivert utgave (05.10.00).)
kap-19.1.1: Utarbeidelse av nye verdier
Nye attributtverdier utarbeides på engelsk og sendes kodelisten for diskusjon og godkjenning.
kap-19.1.2: Prinsipper for rekkefølge
Verdier som er sammensatt av flere verdier skal ordnes alfabetisk (eks. "erased overwritten").
kap-19.2: Attributter og attributtverdier i bruk
Attributtene og attributtverdiene er gruppert i to hovedlister: en felles liste for grunnkoding, hovedtekstkoding, kommentarkoding og produksjonskoding og en egen liste for den metriske kodingen. I tillegg finnes det en egen liste med verdier som brukes i det globale attributtet rend. Rend-verdier som er spesifikke for et element (f. eks. rend="numbered" i <app>, rend="indent" i <l> og rend="desc" i <castGroup>) er også ført i hovedlisten(e).
kap-19.2.1: Generell koding
Se kodebøkene for riktig bruk av elementer, attributter og attributtverdier.
Listen er ordnet alfabetisk etter elementer.
| A | B | C | D | E |
| F | G | H | I | J |
| L | M | N | O | P |
| Q | R | S | T | U |
| V | X |
| Element | Attributt og attributtverdi | Kommentar | |
| A | <add> | hand="" | Samme verdi som hand-attributtet i <hand> |
| <add> | place="inline" | På linjen (også hvis deler ligger utover linjen i margen) | |
| <add> | place="offline" | Over linjen og (mindre tilføyelser) i margen | |
| <add> | place="infralinear" | Under linjen | |
| <add> | place="margin" | Store tilføyelser i margen | |
| <add> | place="inBetweenLines" | Tilføyd ny linje mellom to eksisterende linjer | |
| <anchor/> | type="lemma" | Brukes til koding av lemmareferanser i hovedtekstfilen | |
| <anchor/> | type="ht" | Brukes til koding av ht-referanser i hovedtekstfilen | |
| <anchor/> | id="" | Referense/lenke-koding. verdien skal være unik | |
| <app> | type="alteration" | Brukes i apparater som inneholder manuskriptendringer | |
| <app> | alt="corr" | Brukes i apparater i trykt utg. med egenh. rettelser | |
| <app> | type="internal" | Brukes i apparater som inneholder intern variasjon | |
| <app> | type="external" | Brukes i apparater som inneholder ekstern variasjon | |
| <app> | id="var[verk]-[siffer]" | Brukes til nummerering av eksterne varianter | |
| <app> | subtype="word" | Typifiserer ekstern variasjon: substantialer | |
| <app> | subtype="interpunction" | Typifiserer ekstern variasjon: aksidentalier | |
| <app> | hand="" | Samme verdi som hand-attributtet i <hand> | |
| B | <bibl> | id="" | Entydig verdi for hvert tekstvitne = vitnenummer |
| <bibl> | n="" | Litteraturlistekoding: markerer bindtilhørighet | |
| <biblScope> | type="volume" | Brukes for samlede verker (HU, FU) | |
| <biblScope> | type="issue" | Brukes for føljetonger | |
| <biblScope> | type="part" | Brukes for del av bok eller samling | |
| <biblScope> | type="pageRange" | Litteraturlistekoding: sidespenn | |
| <biblScope> | type="totalPage" | Litteraturlistekoding: antall sider en bok eller artikkel inneholder | |
| <blockSeg> | type="transposition_lines" | Brukes til koding av omrokkering | |
| <blockSeg> | type="transposition_lines_braced" | Brukes til koding av omrokkering | |
| <blockSeg> | id="" | Brukes til koding av omrokkering | |
| <blockSeg> | corresp="" | Brukes til koding av omrokkering | |
| C | <castGroup> | rend="braced" | Markert med klamme |
| <castGroup> | rend="desc" | Markert med felles beskrivelse (uten klamme) | |
| <castGroup> | rend="header" | Markert med felles overskrift | |
| <castGroup> | rend="paragraph" | Markert med felles avsnitt | |
| <castItem> | id="" | Entydig verdi for hver rolle | |
| <castItem> | type="list" | Liste av roller som ikke skal ha id-attributt | |
| <cb/> | n="" | Fortløpende nummerering (skal bare brukes hvis første spalte er noen annet enn 1) | |
| <cb/> | place="left" [*] | Venstre spalte | |
| <cb/> | place="right" [*] | Høyre spalte | |
| <cb/> | place="middle" [*] | Midtre spalte | |
| <cb/> | place="bottom" [*] | Nedre del av siden | |
| <cb/> | place="top" [*] | Øvre del av siden | |
| <cell> | role="label" | Overskriftscelle i tabell | |
| <cell> | role="data" | (Tekst)celle i tabell | |
| <cell> | role="filler" | Fylltegn mellom celler | |
| <cell> | n="compare1" | Brukt i produksjonskodingen | |
| <cell> | n="compare2" | Brukt i produksjonskodingen | |
| <cell> | rend="abbr" | Brukt i kommentarkodingen | |
| <cell> | rend="abbrExpl" | Brukt i kommentarkodingen | |
| <clarification> | hand="" | Samme verdi som hand- attributtet i <hand> | |
| <clarification> | place="inline" | Tydeligjøringen er gjort ved overskriving | |
| <clarification> | place="offline" | Tydeliggjøringen er gjort over, i margen etc | |
| <corr> | resp="" | Brukes til koding av rettelsene i rettede trykte utgaver. Samme verdi som i hand-attributtet i <hand> | |
| <correction> | status="high" | Indikerer at teksten er «thoroughly checked and prrofread» | |
| D | <date> | hand="" | Brukes i brevkoding. Samme verdi som i hand-attributtet i <hand> |
| <date> | value="" | Datering i TEI-header | |
| <date> | id="HISb-date" | Brukes i <publicationStmt> | |
| <date> | id="HISe-date" | Brukes i <publicationStmt> | |
| <dateRange> | from="[yyyy-mm-dd]" | Brukes i brevkoding når brevet er skrevet over flere dager | |
| <dateRange> | from="[yyyy-mm-dd]" | Brukes i brevkoding når brevet er skrevet over flere dager | |
| <dateRange> | to="[yyyy-mm-dd]" | Brukes i brevkoding når brevet er skrevet over flere dager | |
| <del> | hand="" | Samme verdi som hand-attributtet i <hand> | |
| <del> | rend="erased" | Ord/tegn som er visket ut | |
| <del> | rend="overstrike" | Ord/tegn som er strøket ut | |
| <del> | rend="overwritten" | Ord/tegn som er overskrevet | |
| <del> | rend="diagonalOverstrike" | Diagional overstrykningsstrek ved lengre strykninger | |
| <del> | type="checkList" | Brukes til strykninger i Ibsens huskelister i KG41111 | |
| <diacrit/> | type="left" | Brukes i hovedtekster: venstre vinkelparentes | |
| <diacrit/> | type="right" | Brukes i hovedtekster: høyre vinkelparentes | |
| <div> | id="" | Brukes i kommentarkodingen | |
| <div> | n="" | Fortløpende nummerering | |
| <div> | type="relatedToWork" | MS: verksrelatert materiale | |
| <div> | type="paratext" | MS: ikke-verksrelatert materiale | |
| <div> | type="castList" | MS: brukes i <div> rundt <list>, som inneholder forstadium til rollelister | |
| <div> | type="act" | Aktnivå | |
| <div> | type="scene" | Scenenivå | |
| <div> | type="epilogue" | Etterord | |
| <div> | type="preface" | Brukes både ved forord og fortaler | |
| <div> | type="book" | Diktsamling | |
| <div> | type="collectionPart" | Del av samling | |
| <div> | type="poem" | Enkeltdikt | |
| <div> | type="letter poem" | Rimbrev/dikt som også kan defineres som brev | |
| <div> | type="section" | Større ikke-metriske enheter innenfor enkeltdikt | |
| <div> | type="letter" | Brev | |
| <div> | type="letterpart" | Brukes når et brev består av flere deler | |
| <div> | type="postscript" | Etterskrift i brev | |
| <div> | type="attachment" | Vedlegg til brev | |
| <div> | type="contents" | Innholdsfortegnelser | |
| <div> | type="ref" | For frittstående referanser (som ikke kan legges i eksisterende strukturkoding) | |
| <div> | type="telegram" | Telegram | |
| <div> | type="visitingCard" | Visittkort | |
| <div> | type="postcard" | Postkort | |
| <div> | type="appendix" | appendiks i hovedtekster | |
| <div> | type="1colophon" | Brukes i produksjons-/kommentarkoding: 1. kolofonside | |
| <div> | type="flyleaf" | Brukes i produksjons-/kommentarkoding: smusstittelblad | |
| <div> | type="main" | Brukes i produksjons-/kommentarkoding: Hovedtittelside | |
| <div> | type="part" | Brukes i produksjons-/kommentarkoding: Deltittelside | |
| <div> | type="2colophon" | Brukes i produksjons-/kommentarkoding: 2. kolofonside | |
| <div> | type="abbrList" | Brukes i produksjons-/kommentarkoding: liste over forkortelser | |
| <div> | type="illusList" | Brukes i produksjons-/kommentarkoding: liste over illustrasjoner | |
| <div> | type="illustrations" | Brukes i produksjons-/kommentarkoding: illustrasjoner | |
| <div> | type="illusTexts" | Brukes i produksjons-/kommentarkoding: illustrasjonstekst | |
| <div> | type="litList" | Brukes i produksjons-/kommentarkoding: litteraturliste | |
| <div> | type="background" | Brukes i kommentarkoding, i innledningen, rundt avsnittet om verkets bakgrunn | |
| <div> | type="creation" | Brukes i kommentarkoding, i innledningen, rundt avsnittet om verkets tilblivelse | |
| <div> | type="editorialStatement" | Brukes i kommentarkoding, i innledningen, rundt den tekstkritiske redegjørelsen | |
| <div> | type="introCommAuthors" | Brukes i kommentarkoding, rundt bidragsyterlisten | |
| <div> | type="introduction" | Brukes i kommentarkoding, rundt innledningen til hvert verks kommentarer | |
| <div> | type="lemmaCommentary" | Brukes i kommentarkoding, rundt ord- og sakkommentarene | |
| <div> | type="msDescription" | Brukes i kommentarkoding, rundt hver enkelt manuskriptbeskrivelse | |
| <div> | type="performance" | Brukes i kommentarkoding, i innledningen, rundt avsnittet om oppførelse | |
| <div> | type="publication" | Brukes i kommentarkoding, i innledningen, rundt avsnittet om utgivelse | |
| <div> | type="receptionPublication" | Brukes i kommentarkoding, i innledningen, rundt avsnittet om mottagelse av utgaven | |
| <div> | type="translatedPublication" | Brukes i kommentarkoding, i innledningen, rundt avsnittet om oversettelser publisert i Ibsens levetid | |
| <div> | type="CommIntroCont" | Brukes i produksjonskodingen | |
| <div> | type="philosWit" | Brukes i produksjonskodingen | |
| <div> | type="abbrAdded" | Brukes i produksjonskodingen | |
| <div> | type="tcNote" | Brukes i hovedtekstkodingen, inneholder liste over noter | |
| <div> | part="" | Brukes sammen med type="letterpart" når et brev består av flere deler. Gyldige verdier er "I" (initial), "M" (medial) og "F" (final) | |
| <docAuthor> | type="composer" | Komponist | |
| E | <edition> | id="[tekstvitnenr-mnd+år]" | Identifisering av elektronisk utgave - eks. "Br-0900" |
| <editor> | role="chiefEditor" | TEI-header-koding, brukes sammen med id="HIS-[initialer]". Filologisk leder | |
| <editor> | role="assistantEditor" | TEI-header-koding, brukes sammen med id="HIS-[initialer]". Assisterende filolog | |
| <editor> | role="manuscriptController" | TEI-header-koding, brukes sammen med id="HIS-[initialer]". Manuskriptansvarlig | |
| <editor> | role="technicalController" | TEI-header-koding, brukes sammen med id="HIS-[initialer]". Dataledelse | |
| <editor> | role="verseController" | TEI-header-koding, brukes sammen med id="HIS-[initialer]". Metrikkansvarlig | |
| <emph> | hand="" | Samme verdi som hand-attributtet i <hand> | |
| <emph> | rend=""[**] | Se egen liste under for verdier i bruk i rend | |
| <envelope> | type="envelope" | Adressetekst på løs konvolutt | |
| <envelope> | type="sheet" | Adressetekst på baksiden av brevarket | |
| <expan> | abbr="m" | 'm' med nasalstrek | |
| F | <figure/> | type="bar" | Skille- og pyntestreker |
| <figure/> | type="num" | Skigard/strofeskille | |
| <figure/> | type="facsimile" | HUs faksimiler | |
| <figure/> | type="illustration" | Alle typer illustrasjoner | |
| <figure/> | type="logo" | Forlagsstempler, logoer | |
| <figure/> | type="getFile" | For innhenting av bilderessurser i kommentar - og produksjonsfiler | |
| <figure/> | id="illus-[siffer]" | For innhenting av bilderessurser i kommentar - og produksjonsfiler | |
| <figure/> | entity="filnavn" | For innhenting av bilderessurser i kommentar - og produksjonsfiler | |
| <figure/> | rend="free" | Brukes når illustrasjoner skal plasseres et eller annet sted innenfor det <div>-elementet det ligger i | |
| <foreign> | lang="lat" | jf. <language> | |
| <foreign> | lang="ger" | jf. <language> | |
| <foreign> | lang="eng" | jf. <language> | |
| <foreign> | lang="ita" | jf. <language> | |
| <foreign> | lang="fre" | jf. <language> | |
| <foreign> | lang="dan" | jf. <language> | |
| <foreign> | rend="quote" | I anførselstegn | |
| <fw> | hand="" | Samme verdi som hand-attributtet i <hand> | |
| <fw> | type="column" | Kolonnefoliering | |
| <fw> | type="page" | Sidefoliering, sidetall | |
| <fw> | type="leaf" | Bladfoliering | |
| <fw> | type="gathering" | Leggfoliering i manuskripter | |
| <fw> | type="sheet" | Arkfoliering i trykte tekster | |
| <fw> | type="footer" | Bunntekst | |
| <fw> | type="header" | Topptekst | |
| <fw> | place="bottom" | Midtstilt nederst på siden | |
| <fw> | place="bottom-left" | Nederst til venstre på siden | |
| <fw> | place="bottom-right" | Nederst til høyre på siden | |
| <fw> | place="top" | Midtstilt øverst på siden | |
| <fw> | place="top-left" | Øverst til venstre på siden | |
| <fw> | place="top-right" | Øverst til høyre på siden | |
| <fw> | place="leftPage" | Produksjonskoding: brukes sammen med type="header" til koding av venstre kolumnetitler | |
| <fw> | place="rightPage" | Produksjonskoding: brukes sammen med type="header" til koding av høyre kolumnetitler | |
| G | <gap/> | reason="irrelevant" | Brukes ved utelatt, irrelevant tekst eller figur |
| <gap/> | reason="binding" | Tekst uleselig pga stram innbinding eller beskjæring i forb. med innbinding | |
| <gap/> | reason="damage" | Tekst uleselig pga skader (rifter etc.) | |
| <gap/> | reason="endline" | Tekst uleselig fordi skriveren har kommet til slutten av linjen | |
| <gap/> | reason="glue" | Tekst uleselig pga overliming eller tape | |
| <gap/> | reason="ink" | Tekst uleselig pga blekkflekk | |
| <gap/> | reason="omission" | Utelatt tekst | |
| <gap/> | reason="overstrike" | Tekst uleselig pga overstrykning | |
| <gap/> | reason="overwritten" | Tekst uleselig pga overskrivning | |
| <gap/> | reason="erased" | Tekst uleselig pga utvisking/avskraping | |
| <gap/> | reason="smudge" | Tekst uleselig pga avsverting, utflytende blekk etc | |
| <gap/> | reason="writing" | Tekst uleselig pga av vanskelig håndskrift | |
| <gap/> | reason="stamp" | Tekst uleselig pga frimerke | |
| <gap/> | extent="leaf" | Brukes når et blad (med tekst) mangler | |
| <gap/> | extent="2leaves" | Brukes når to blad (med tekst) mangler | |
| <gap/> | extent="sheet" | Brukes når et helt legg/ark (med tekst) mangler | |
| H | <hand> | hand="" | Verdien skal være unik for hver enkelt hånd (samme verdi som i id-attributtet.). Hvis skriveren er identifisert brukes skriverens intialer (eks. HI), hvis skriveren er uidentifisert brukes "h[+siffer]" (eks. h1, h2, h3 osv.). Hvis samme skriver bruker flere skriveredskaper nummereres hendene, eks, "HI-1", "HI-2", "h1-1", "h1-2" (NB! I brevfiler brukes [brev-id]-HI) |
| <hand> | id="" | Verdien skal være unik for hver enkelt hånd (samme verdi som i hand-attributtet.). Hvis skriveren er identifisert brukes skriverens intialer (eks. HI), hvis skriveren er uidentifisert brukes "h[+siffer]" (eks. h1, h2, h3 osv.). Hvis samme skriver bruker flere skriveredskaper nummereres hendene, eks, "HI-1", "HI-2", "h1-1", "h1-2" (NB! I brevfiler brukes [brev-id]-HI) | |
| <hand> | ink="pen-black" | Brunsort blekk | |
| <hand> | ink="pen-brown" | Mørkt brunt blekk | |
| <hand> | ink="pen-blue" | Blåsort blekk | |
| <hand> | ink="pen-red" | Rødt blekk | |
| <hand> | ink="pen-violet" | Fiolett blekk | |
| <hand> | ink="pencil" | Gråblyant | |
| <hand> | ink="pencil-red" | Rød blyant | |
| <hand> | ink="pencil-blue" | Blå blyant | |
| <hand> | character="careful" | Renskriftsstil (skrevet med omhu) | |
| <hand> | character="careless" | Kladdestil (skrevet med større eller mindre grad av skjødesløshet) | |
| <hand> | first="yes" | Hovedhånd | |
| <handShift/> | old="" | Skriverhånden før <handShift> - samme verdi som i hand-attributtet i <hand> | |
| <handShift/> | new="" | Skriverhånden etter <handShift> - samme verdi som i hand-attributtet i <hand> | |
| <handShift/> | ink="pen-black" | Brunsort blekk | |
| <handShift/> | ink="pen-brown" | Mørkt brunt blekk | |
| <handShift/> | ink="pen-blue" | Blåsort blekk | |
| <handShift/> | ink="pen-red" | Rødt blekk | |
| <handShift/> | ink="pen-violet" | Fiolett blekk | |
| <handShift/> | ink="pencil" | Gråblyant | |
| <handShift/> | ink="pencil-red" | Rød blyant | |
| <handShift/> | ink="pencil-blue" | Blå blyant | |
| <handShift/> | character="careful" | Renskriftsstil (skrevet med omhu) | |
| <handShift/> | character="careless" | Kladdestil (skrevet med større eller mindre grad av skjødesløshet) | |
| <head> | n="[siffer]" | Brukes i produksjonskoding | |
| <head> | type="contents_commVol" | Brukes i kommentarkoding | |
| <head> | rend="versal14" | Brukes i kommentarkoding | |
| <head> | rend="versal12" | Brukes i kommentarkoding | |
| <head> | rend="centre_smallCaps" | Brukes i kommentarkoding | |
| <head> | rend="centre_italic" | Brukes i kommentarkoding | |
| <head> | rend="centre_Ms" | Brukes i kommentarkoding | |
| <head> | rend="inline_smallCaps" | Brukes i kommentarkoding | |
| <hi> | hand="" | Samme verdi som hand-attributtet i <hand> | |
| <hi> | rend=""[**] | Se egen liste under for verdier i bruk i rend | |
| <hyphenation> | eol="hard" | Brukes i hovedtekstfiler: indikerer at grunntekstens myke bindestreker er fjernet og at eventuelle gjenværende bindestreker skal betraktes som harde/meningsbærende | |
| <hyphenation> | eol="soft" | Brukes i filer for grunntekst og øvrige tekstvitner (ikke hovedtekster): indikerer at alle grunntekstens myke bindestreker er beholdt | |
| I | <idno> | id="[eksemplarnr]" | Dokumenterer hvilket eksemplar som er brukt i kollasjoneringen |
| <item> | n="1" | Brukes i kommentarkoding, rundt lemmaets unike entitet | |
| <item> | n="2" | Brukes i kommentarkoding, rundt selve lemma | |
| <item> | n="3" | Brukes i kommentarkoding, rundt lemmakommentaren | |
| <item> | rend="" | Brukes i kommentarkoding | |
| J | <join/> | targets="" | Lenkekoding: att.verdi fra id="" (f.eks. i <text> (føljetonger) eller <xref> (lemma i hovedtekster)) |
| <join/> | targOrder="Y" | Føljetongkoding: samme rekkefølge som i targets="" | |
| L | <l> | part="I" | "initial" (oblig. TEI) |
| <l> | part="M" | "medial" (oblig. TEI) | |
| <l> | part="F" | "final" (oblig. TEI) | |
| <l> | part="Y" | Uavsluttet verslinje | |
| <l> | n="[1/2]" | Brukes sammen med part="M" for de to miderste delene i den firdelt verslinje | |
| <l> | rend="indent" | Innrykket verslinje. Ved innrykk av ulik lengde (innefor en fil) brukes "indent1", "indent2" osv | |
| <l> | rend="line" | Brukes når det er en blank linje før verslinjen | |
| <l> | rend="indent line" | Brukes når det er blank linje før innrykket verslinje | |
| <l> | rend="centre" | Midtstilt verslinje | |
| <l> | type="dashes" | Linje med tankestreker | |
| <label> | id="" | Brukes når id ikke kan plasseres i <castItem> i rollelisten | |
| <label> | rend="" | Brukes i kommentarkoding | |
| <language> | id="Dano-Norwegian" | Dansk-norsk | |
| <language> | id="nob" | Norsk bokmål | |
| <language> | id="ger" | Tysk | |
| <language> | id="lat" | Latin | |
| <language> | id="eng" | Engelsk | |
| <language> | id="ita" | Italiensk | |
| <language> | id="fre" | Fransk | |
| <language> | id="swe" | Svensk | |
| <language> | id="dan" | Dansk | |
| <language> | id="hun" | Ungarsk | |
| <lem> | hand="" | Samme verdi som hand-attributtet i <hand> | |
| <letterinfo> | type="letter" | Brev | |
| <letterinfo> | type="visitingCard" | Visittkort | |
| <letterinfo> | type="telegram" | Telegram | |
| <letterinfo> | type="poem" | Diktbrev | |
| <letterinfo> | type="postcard" | Postkort | |
| <lg> | rend="poem" | Produksjonskoding: omslutter dikt (inkl. sanger og drikkeviser) som skal ha diktoppsett | |
| <lg> | rend="opAlign" | Produksjonskoding: omslutter tekst som skal optisk sentreres | |
| <list> | type="commentary" | Brukes i kommentarkoding, rundt hver enkelt lemmakommentar | |
| <list> | type="standardList" | Brukes i kommentarkoding, omslutter listeoppsett | |
| <list> | type="nobreakList" | Brukes i kommentarkoding, omslutter listeoppsett | |
| <list> | type="simple" | Brukes i kommentarkoding, omslutter unummerert listeoppsett | |
| <list> | type="bulletedList" | Brukes i kommentarkoding | |
| <list> | type="sources" | Brukes i kommentarkoding | |
| M | <milestone/> | n="" | Nummerering av hefter |
| <milestone/> | unit="instalment" | Hefte. Brukt i Catilina-manuskriptet | |
| <msDescription> | id="" | Entydig verdi for hvert tekstvitne = vitnenummer | |
| <msDescription> | type="notes" | Notater | |
| <msDescription> | type="workingManuscript" | Arbeidsmanuskript | |
| <msDescription> | type="finalManuscript" | Endelig manuskript | |
| <msDescription> | type="finalFairCopy" | Endelig renskrift | |
| <msDescription> | type="printersCopy" | Trykkmanuskript | |
| <msDescription> | type="stageProductionCopy" | Scenemanuskript | |
| <msDescription> | type="promptCopy" | Sufflørbok | |
| <msDescription> | type="parts" | Rollehefter | |
| <msDescription> | type="letter" | Brev | |
| N | <name> | type="place" | Stedsangivelse i forord, etterord, brev og dikt |
| <name> | id="[Kollasjonistens initialer]" | I <respStmt> (i <titleStmt> og <revisionDesc>): identifisering av hvem som har gjort hva med filen når | |
| <note> | resp="author" | Forfatter er ansvarlig for noten | |
| <note> | resp="editor" | HIS (filologene) er ansvarlig for noten | |
| <note> | resp="[kollasjonistens initialer]" | Brukes i arbeidsnoter | |
| <note> | resp="[verdi fra <handList>]" | Brukes til koding av transkriberte noter i manuskripter og margnotater i rettede trykte utgaver. Samme verdi som i hand-attributtet i <hand> | |
| <note> | id="note[verk]_[siffer]" | Hovedtekstkoding (notelistekoding) | |
| <note> | id="n[+siffer]" | Tilsvarer verdien i <ref target=""> | |
| <note> | target="nb[+siffer]" | Tilsvarer verdien i <ref id=""> | |
| <note> | place="top" | Sentrert øverst | |
| <note> | place="top-left" | Øverst til venstre | |
| <note> | place="top-right" | Øverst til høyre | |
| <note> | place="bottom" | Sentrert nederst | |
| <note> | place="bottom-left" | Nederst til venstre | |
| <note> | place="bottom-right" | Nederst til høyre | |
| <note> | place="margin-left" | I venstre marg | |
| <note> | place="margin-right" | I høyre marg | |
| <note> | place="inline" | Del av løpende tekst | |
| <note> | place="offline" | Brukes i PG85 (teaterms.) | |
| <note> | type="reading" | Hvor flere lesemåter er mulig | |
| <note> | type="scribble" | Skribleri som ikke hører med til teksten | |
| <note> | type="typo" | Markerer at noe er galt med teksten f. eks. gal/manglende tegnsetting | |
| <note> | type="workingNote" | Arbeidsnote | |
| <note> | type="met" | Metrikknote | |
| <note> | type="varThrough" | Brukes til koding av gjennomgående ekstern variasjon | |
| <note> | type="appExt" | Brukes til koding av eksterne varianter | |
| <note> | type="metKomm" | Brukes i kommentarkoding, omslutter alle metrikkformler | |
| <note> | type="footer" | Brukes i kommentarkoding for å angi hvor det skal genereres fotnoter. Koden omslutter all fotnotetekst | |
| <note> | type="korr" | Litteraturlistekoding: innførselen er korrekturlest | |
| <note> | type="ukorr" | Litteraturlistekoding: innførselen er ikke korrekturlest | |
| <note> | type="transposition_lines" | Manuskriptkoding: omrokkering av linjer | |
| <note> | type="transposition_lines_braced" | Manuskriptkoding: omrokkering av linjer | |
| O | <orgName> | type="owner" | Eier av eksemplaret brukt i kollasjoneringen |
| <origDate> | value="[yyyy-mm-dd]" | Brukes til datering av manuskripter | |
| <origDate> | notBefore="[yyyy-mm-dd]" | Brukes til å kode spenn ved datering | |
| <origDate> | notAfter="[yyyy-mm-dd]" | Brukes til å kode spenn ved datering | |
| P | <p> | type="dashes" | Linje med tankestreker |
| <p> | rend="noIndent" | Produksjonskoding. Prosaavsnitt som ikke skal ha innrykket førstelinje | |
| <p> | rend="set" | Produksjonskoding. Prosaavsnitt i <set> | |
| <pb/> | ed="HU" | Brukes til synkronisering av tekstvitner | |
| <pb/> | n="" | Fortløpende nummerering (skal bare brukes hvis første side er noen annet enn 1) | |
| <pb/> | rend="noprint" | Brukes når siden skal telles men ikke vises | |
| <principal> | id="HIS-VY" | TEI-headerkoding. Hovedredaktør for HIS = Vigdis Ystad | |
| <ptr/> | type="external" | Brukes til koding av ekterne varianter | |
| <ptr/> | target="ext[siffer]" | Brukes til koding av eksterne varianter. Verdien er den samme som i tilhørende <anchor/>-element | |
| Q | <quotation> | marks="all" | Alle anførselstegn er beholdt |
| <quotation> | form="std" | Anførselstegn er standardisert | |
| <quote> | rend="indent" | Brukes i kommentarkoding, rundt diktsitat og verslinjer på mer enn to linjer (hvor innrykk skal genereres) | |
| <quote> | rend="quoteIndent" | Brukes i kommentarkoding, rundt prosasitater som utvilsomt vil være på mer enn trelinjer etter setting og hvor innrykk da skal genereres | |
| R | <rdg> | wit="HIS" | Markerer en foretrukken variant ved internvariasjon |
| <rdg> | wit="[tekstkildenr.]" | Markerer hvilken tekstkilde lesemåten tilhører | |
| <rdg> | var="Y" | Brukes i eksternvariantkodingen. Markerer at lesemåten varierer i forhold til grunnteksten | |
| <rdg> | var="N" | Brukes i eksternvariantkodingen. Markerer at lesemåten ikke varierer i forhold til grunnteksten | |
| <recipient> | id="" | Brevmottagers initialer | |
| <ref> | type="refMark" | Notereferanse til alle slags to-veis referanser (mellom note og notetegn og mellom tilføyelse og tilføyelsestegn) | |
| <ref> | type="serialRef" | Referanse mellom "Forts" og "Slutning" i føljetonger | |
| <ref> | id="fnb[+siffer]" | Tilsvarer verdien i <note target=""> | |
| <ref> | target="fn[+siffer]" | Tilsvarer verdien i <note id=""> | |
| <ref> | hand="" | Brukes hvis annen hånd enn hovedhånden har laget referansen/referanstegnet, samme verdi som hand-attributtet i <hand> | |
| <restore> | type="del" | Kansellert/opphevet strykning | |
| <restore> | type="hi" | Kansellert/opphevet markering/understreking | |
| <restore> | type="emph" | Kansellert/opphevet retorisk utheving | |
| <restore> | type="corr" | Kansellert/opphevet rettelse i trykt tekst med håndskrevne rettelser | |
| <restore> | desc="" | Prosabeskrivelse av hvordan opphevingen er signalisert/utført | |
| <role> | rend="smallCaps" | Brukes i hovedtekstkoding | |
| <rs> | corresp="[id]" | Til koding av navn, brukes sammen med type="". Id-verdi hentes fra id-basen | |
| <rs> | type="person" | Til koding av personnavn, brukes sammen med corresp="" | |
| <rs> | type="org" | Til koding av organisasjonsnavn, brukes sammen med corresp="" | |
| <rs> | type="place" | Til koding av stedsnavn, brukes sammen med corresp="" | |
| <rs> | type="work" | Til koding av verk, brukes sammen med corresp="" | |
| S | <seg> | type="numbering" | Kommentarkoding |
| <seg> | type="number" | Kommentarkoding | |
| <seg> | type="description" | Kommentarkoding | |
| <seg> | type="poem" | Kommentarkoding | |
| <seg> | type="text" | Kommentarkoding | |
| <seg> | type="content" | Kommentarkoding | |
| <seg> | type="listContent" | Kommentarkoding | |
| <seg> | type="bullet" | Kommentarkoding | |
| <seg> | type="pageNumber" | Kommentarkoding | |
| <seg> | type="rhyme" | Kommentarkoding | |
| <seg> | type="msInnførsel" | Litteraturlistekoding: manuskriptinnførsler | |
| <seg> | type="msInfo" | Litteraturlistekoding: manuskriptinnførsler | |
| <seg> | n="" | Kommentarkoding | |
| <seg> | type="transposition" | Brukes til koding av omrokkering | |
| <seg> | rend="" | Brukes til koding av omrokkering | |
| <seg> | subtype="no" | Brukes til koding av omrokkering | |
| <seg> | subtype="words_numbered" | Brukes til koding av omrokkering | |
| <seg> | subtype="phrase" | Brukes til koding av omrokkering | |
| <seg> | subtype="word" | Brukes til koding av omrokkering | |
| <seg> | rend=""[**] | Brukes til koding av omrokkering | |
| <sender> | id="" | Brevsenders initialer | |
| <signed> | hand="" | Samme verdi som hand-attributtet i <hand> | |
| <signed> | rend="capSmallCap" | Brukes i hovedtekstkoding | |
| <sp> | who="" | Samme verdi som id-attributtene i rollelisten | |
| <space/> | extent="line" | Brukes ved umotiverte tomrom i teksten: en eller flere tomme linjer (se kodepraksis: Rom i teksten) | |
| <space/> | extent="indent" | Brukes ved umotiverte tomrom i teksten: innrykk (uavhengig av hvor stort innrykket er) (se kodepraksis: Rom i teksten) | |
| <speaker> | rend="smallCaps" | Brukes i hovedtekstkoding | |
| <spOpener> | rend="braced" | Brukt i OL-rolleheftene til koding av felles replikktekst | |
| <stage> | rend="braced" | Brukt i Fj ved "omsluttende" sceneanvisning | |
| <stage> | rend="bracedLeft" | Brukt i Fj ved "omsluttende" sceneanvisning | |
| <stage> | rend="previous" | Brukes i hovedtekstkoding | |
| <stage> | rend="next" | Brukes i hovedtekstkoding | |
| <stage> | type="dashes" | Linje med tankestreker | |
| <stageRole> | who="" | Samme verdi som id-attributtene i rollelisten | |
| T | <table> | rend="compareText" | Brukes i kommentarkoding |
| <tagUsage> | gi="id-who" | Brukes til å føre oversikt over id- og who-attributtene (i <castItem> (evnt. annet element hvis tekstvitnet ikke har rolleliste), <sp> og <stageRole>) i filen | |
| <tagUsage> | gi="pb-ed-HU"/gi="pb-ed-HU-n" | Brukes til å dokumentere hvordan sideskift fra HU (skal brukes til synkronisering av tekstvitner senere) er kodet | |
| <tagUsage> | gi="tei.2" | Brukes til dokumentasjon av kodepraksis i TEI-headeren | |
| <tagUsage> | gi="body" | Brukes til dokumentasjon av strukturkoding i BE-materialet | |
| <tagUsage> | gi="app-external" | Brukes ved koding av eksterne varianter | |
| <teiHeader> | lang="nob" | Angir språket i teiHeader, norsk bokmål. Attributtverdien er hentet fra ISO-standarden for språkkoder | |
| <term> | type="music" | Brukt i kodingen av notebilaget i KE | |
| <text> | corresp="[id-verdi]" | Brevhovedtekstkoding: hvert brev kodes i et eget <text corresp="">-element. Verdien i corresp hentes fra id-verdien i <msDescription>/<bibl> | |
| <text> | id="" | Identifisering av et <text>-element. Eks. på verdi: "C1ht", "K2ht", "bd1k", "KG1", "KG2" | |
| <text> | lang="Dano-Norwegian" | Angir (hoved)språket i teksten. Brukes i tekster skrevet på dansk-norsk (Ibsens språk). Attributtverdien er egendefinert | |
| <text> | lang="eng" | Angir (hoved)språket i teksten. Brukes i tekster skrevet på engelsk. Attributtverdien er hentet fra ISO-standarden for språkkoder | |
| <text> | lang="ger" | Angir (hoved)språket i teksten. Brukes i tekster skrevet på tysk. Attributtverdien er hentet fra ISO-standarden for språkkoder | |
| <text> | lang="swe" | Angir (hoved)språket i teksten. Brukes i tekster skrevet på svensk. Attributtverdien er hentet fra ISO-standarden for språkkoder | |
| <text> | lang="dan" | Angir (hoved)språket i teksten. Brukes i tekster skrevet på svensk. Attributtverdien er hentet fra ISO-standarden for språkkoder | |
| <text> | n="" | Føljetongkoding: fortløpende nummerering av føljetongdelene | |
| <text> | type="workingManuscript"> | Brukes i KG41111 | |
| <text> | rend="commentary"> | Kommentarkoding: omslutter all tekst til et kommentarbind | |
| <text> | rend="verseDrama"> | Kommentarkoding: omslutter all tekst til et versdrama | |
| <text> | rend="proseDrama"> | Kommentarkoding: omslutter all tekst til et prosadrama | |
| <text> | rend="letter"> | Kommentarkoding: omslutter all tekst til et brev | |
| <text> | rend="visualized"> | Omslutter all tekst i en visualisert ms-fil | |
| <text> | type="bdTK_singleWorks_standardTitle"> | Produksjonskoding: omslutter teksten til enkel standardtittelside foran de enkelte verk | |
| <text> | type="HIS_titlePage"> | Produksjonskoding: omslutter teksten til tittelside | |
| <text> | type="HIS_smusstittel"> | Produksjonskoding: omslutter teksten til smusstittelside | |
| <text> | type="abbrList"> | Produksjonskoding: omslutter teksten til forkortelsesliste | |
| <title> | type="main" | Hovedtittel | |
| <title> | type="sub" | Undertittel | |
| <title> | type="origYear" | Dato | |
| <title> | level="s" | Indikerer tittelnivå innenfor utgaven: (series) omfatter flere bind | |
| <title> | level="m" | Indikerer tittelnivå innenfor utgaven: (monographic) enkeltbind | |
| <title> | level="a" | Indikerer tittelnivå innenfor utgaven: (analytic) del av et bind | |
| <title> | rend="italic" | Brukes i kommentarkoding, rundt titler på verk som skal stå i kursiv | |
| <title> | rend="quotes" | Brukes i kommentarkoding, rundt titler (på artikler, dikt o.l.) som skal markeres med doble anførselstegn | |
| <titlePage> | type="main" | Hovedtittelblad/-side | |
| <titlePage> | type="flyleaf" | Smusstittelblad/-side | |
| <titlePage> | type="main_flyleaf" | Produksjonskoding: smusstittelside som skal settes på samme side som hovedtittelside. | |
| <titlePage> | type="part" | Deltittelblad/-side | |
| <titlePage> | type="main_part" | Produksjonskoding: deltittelside som skal settes på samme side som hovedtittelside. | |
| <titlePage> | type="colophon" | Kolofonblad/-side | |
| <titlePage> | type="appendix_main" | Brukt i kodingen av notebilaget til KE (tittelbladet) | |
| <titlePage> | type="appendix_colophon" | Brukt i kodingen av notebilaget til KE (kolfonblad sist i bilaget) | |
| <titlePage> | type="serial" | Føljetongtittelblad/-side | |
| <titlePage> | n="" | Til nummerering av tittelsider | |
| <titlePart> | type="main" | Hovedtittel | |
| <titlePart> | type="sub" | Undertittel | |
| <titlePart> | type="vol" | Produksjonskoding: bindnummer på tittelsider | |
| <titlePart> | id="" | Brukes kun i rollehefter uten rollelister | |
| <titlePart> | rend="" | Produksjonskoding | |
| U | <unclear> | reason="binding" | Utydelig tekst pga stram innbinding eller beskjæring i forbindelse med innbinding |
| <unclear> | reason="damage" | Utydelig tekst pga skade (rifter etc.) | |
| <unclear> | reason="endline" | Utydelig tekst fordi skriveren har kommet til slutten av linjen | |
| <unclear> | reason="glue" | Teksten er utydelig fordi den er helt eller delvis overlimt eller skjult av tape | |
| <unclear> | reason="ink" | Utydelig tekst pga blekkflekk | |
| <unclear> | reason="overstrike" | Utydelig pga overstrykning | |
| <unclear> | reason="overwritten" | Utydelig pga overskrivning | |
| <unclear> | reason="erased" | Utydelig pga utvisking/avskraping | |
| <unclear> | reason="fadedWriting" | Utydelig pga falmet/bleknet skrift | |
| <unclear> | reason="smudge" | Utydelig pga avsverting eller utflytende blekk etc | |
| <unclear> | reason="writing" | Utydelig skrift | |
| V | <variantEncoding/> | method="parallel-segmentation" | Brukes i TEI-headeren i filer med apparatkoding |
| <variantEncoding/> | location="internal" | Brukes i TEI-headeren i filer med apparatkoding | |
| <variantEncoding/> | type="alteration" | Brukes i TEI-headeren i filer med manuskriptkoding | |
| <variantEncoding/> | type="external" | Brukes i TEI-headeren i filer med ekstern variantkoding | |
| <variantEncoding/> | type="internal" | Brukes i TEI-headeren i filer med intern variantkoding | |
| X | <xptr/> | n="" | Fortløpende nummerering av pekere |
| <xptr/> | id="" | Unik verdi for hver peker - skal brukes til krysslenking | |
| <xptr/> | from="" | Angir hvilket id-attributt pekeren går til | |
| <xptr/> | doc="" | Inneholder referansen til dokumentet det pekes til - eks. "F2", "ms1939" | |
| <xptr/> | type="getFile" | For innhenting av eksterne filer i kommentar - og produksjonsfiler | |
| <xptr/> | type="lemma" | For koding av lemmareferanser i kommentarfiler | |
| <xptr/> | type="internal" | For koding av interne referanser i kommentarfiler | |
| <xptr/> | type="ht" | For koding av ht-referanser i kommentarfiler | |
| <xref> | type="tcNote" | Til koding av lemma i hovedtekst og noteliste | |
| <xref> | type="tcNote-part" | Til koding av fragmentert lemma i hovedtekst | |
| <xref> | id="note[verk]_[siffer]" | Til koding av lemma og noter i hovedtekst og noteliste | |
| <xref> | from="note[verk]_[siffer]" | Til koding av lemma og noter i hovedtekst og noteliste | |
| <xref> | url="[filnavn]" | Til koding av lemma og noter i hovedtekst og noteliste |
kap-19.2.2: Globale attributter
De globale attributtene kan brukes i alle elementer. Nedenfor følger en beskrivelse av attributtene bygd på TEIs forklaring av dem (kapittel 3.5 i «Introduction»), ikke en definisjon av vår bruk av dem:
- id (identifier) angir en unik verdi
- n (number) angir et siffer/nummer
- lang (language) inneholder en attributtverdi som viser hvilket språk den kodede teksten er skrevet på
- rend (render) beskrivelse av hvordan noe skal gjengis typografisk.
Vår bruk av attributtene er knyttet til det elementet de skal brukes i, så kodepraksis for elementet skal konsulteres før attributtene brukes.
kap-19.2.2.1: Verdier i bruk i det globale attributtet rend
Listen er ordnet alfabetisk etter verdier.
| rend="abbr" | Brukes i <cell> (kommentarkoding) |
| rend="abbrExpl" | Brukes i <cell> (kommentarkoding) |
| rend="alignRight" | Brukes i visualiserte ms |
| rend="blue" | Blå skrift |
| rend="bold"[**] | Fet skrift |
| rend="braced" | Brukes i <castGroup>, <spOpener> og <stage> |
| rend="bracedLeft" | Brukes i <stage> i Fj |
| rend="capSmallcap"[**] | Kombinasjon av majuskler og kapitéler |
| rend="centre" | Brukes i <l> |
| rend="centre_smallCaps" | Brukes i <head> |
| rend="centre_italic" | Brukes i <head> |
| rend="centre_Ms" | Brukes i <head> |
| rend="colour" | Brukes i produksjonskodingen |
| rend="compareText" | Brukes i produksjonskodingen: i <table> |
| rend="cross"[**] | Kryss under bokstav/tegn |
| rend="desc" | Brukes i <castGroup> |
| rend="deviation"[**] | Brukes ved avvikende typografi (skal ikke brukes i <hi>) |
| rend="deviation raised"[**] | Avvikende + hevet tekst. Brukes i Fru Inger til Østråt (1874) |
| rend="erased" | Brukes i <del> og <delSpan/> |
| rend="erased overwritten" | Brukes i <del> og <delSpan/> |
| rend="fontsize"[**] | Typestørrelse. Brukes i Gildet paa Solhoug (1856) og Brand |
| rend="free" | Brukes i kommentar- og produksjonsfiler for illustrasjoner som ikke skal stå et bestemt sted. Brukes i <figure/> |
| rend="header" | Brukes i <castGroup> |
| rend="indent" | Brukes i <l> |
| rend="indent1" | Brukes i <l> |
| rend="indent2" | Brukes i <l> |
| rend="indent3" | Brukes i <l> |
| rend="indent4" | Brukes i <l> |
| rend="infralinear" | Under linjen. Brukes i <seg> |
| rend="initial"[**] | Forstørret initial (f. eks. først i scene) |
| rend="inline_smallCaps" | Brukes i <head> |
| rend="italic"[**] | Kursivert skrift |
| rend="kreditering" | Brukes i kommentar- og produksjonsfiler for krediteringstekst (v/illustrasjoner) |
| rend="left" | Brukes i <seg> i visualiserte ms |
| rend="line" | Brukes i <l> |
| rend="majuscule"[**] | Majuskler (tidligere "cap") |
| rend="miniscule"[**] | Minuskler |
| rend="next" | Brukes i <stage> (produksjonskoding) |
| rend="nocolour" | Brukes i produksjonskodingen |
| rend="noIndent" | Brukes i produksjonskodingen til oppheving av førstelinjeinnrykk i prosaavsnitt |
| rend="noprint" | Brukes i produksjonskodingen til undertrykking av elementer (f. eks. <head>, <dateline> og <pb/>) |
| rend="normal" | Brukes rundt tekst som skal avkursiveres i kursiverte bildetekster i kommentarbindene |
| rend="overstrike" | Brukes i <del> og <delSpan/> |
| rend="overstrike overwritten" | Brukes i <del> og <delSpan/> |
| rend="overwritten" | Brukes i <del> og <delSpan/> |
| rend="petit"[**] | Petit skrift |
| rend="paragraph" | Brukes i <castGroup> |
| rend="poem" | Brukes i <lg> |
| rend="previous" | Brukes i <stage> (produksjonskoding) |
| rend="quote" | Brukes i <foreign> |
| rend="quotes" | Brukes i kommentarkoding; rundt titler som skal ha doble anførselstegn. Brukes i <title> |
| rend="quoteIndent" | Brukes i <quote> |
| rend="raised"[**] | Hevet skrift |
| rend="romNum" | Brukes i kommentarkoding; koden omslutter alle romertall, men kun store romertall dersom disse skal genereres som smallCaps |
| rend="sepia" | Sepia-farget skrift |
| rend="set" | Brukes i produksjonskoding for å skille <p> i <set> fra ander prosaavsnitt |
| rend="simple" | Brukes i produksjonskodingen: i <label> |
| rend="smallCaps"[**] | Kapitéler (tidligere "scap") |
| rend="sources" | Brukes i produksjonskodingen: i <label> |
| rend="spaced"[**] | Sperret skrift |
| rend="supralinear" | Over linjen. Brukes i <seg> |
| rend="underlined"[**] | Enkel understreking |
| rend="underlined2"[**] | Dobbel understreking |
| rend="underlined3"[**] | Trippel understreking |
| rend="num" | Brukes i <figure/> i visualiserte ms |
kap-19.2.3: Metrisk koding
Se «Retningslinjer for verskoding» for riktig bruk og sammensetning av attributtverdier.
Listen er ordnet alfabetisk etter elementer.
| A | D | L |
| N | R | T |
| Element | Attributt og attributtverdi | Kommentar | |
| D | <div> | id="c[+nummer]/po[+nummer]" | Løpende nummerering. 'c' står for 'collection' (diktsamling) og 'po' står for 'poem' (enkeltdikt). (Brukt i DHU.) |
| <div> | type="book" | Diktsamling | |
| <div> | type="poem" | Enkeltdikt (i diktsamling) | |
| <div> | type="ref" | For referanser til tekster andre steder i dokumentet. (Brukt i DHU.) | |
| L | <l> | first="yes" | Førstelinjer i dikt |
| <l> | rend="indent" | Innrykket verslinje. Ved innrykk av ulik lengde (innefor en fil) brukes "indent1", "indent2" osv | |
| <l> | rend="centre" | Midtstilt verslinje (ikke i bruk i hovedtekstfiler) | |
| <l> | rend="line" | Brukes når det er en blank linje før verslinjen (ikke i bruk i hovedtekstfiler) | |
| <l>, <lg> | an="single" | Markerer opptaktsforhold: enkel opptakt | |
| <l>, <lg> | an="double" | Markerer opptaktsforhold: dobbel opptakt | |
| <l>, <lg> | an="no" | Markerer opptaktsforhold: ingen opptakt | |
| <l>, <lg> | realAn="single" | Markerer avvikende opptaktsforhold: enkel opptakt | |
| <l>, <lg> | realAn="double" | Markerer avvikende opptaktsforhold: dobbel opptakt | |
| <l>, <lg> | realAn="no" | Markerer avvikende opptaktsforhold: ingen opptakt | |
| <l>, <lg> | met="mono" [***] | Enstavet taktledd (-) | |
| <l>, <lg> | met="bi" [***] | Tostavet taktledd (-v) | |
| <l>, <lg> | met="tri" [***] | Trestavet taktledd (-vv) | |
| <l>, <lg> | met="tetra" [***] | Firestavet taktledd (-vvv) | |
| <l>, <lg> | met="bi+" [***] | Markerer substitusjon (innsetting av trisyllabler (-vv) i ellers bisyllabisk (-v) versgang) | |
| <l>, <lg> | met="bi++" [***] | Markerer hypersubstitusjon (innsetting av større taktledd enn trisyllabler i ellers bisyllabisk versgang) | |
| <l>, <lg> | met="bi-" [***] | Markerer reduksjon (bisyllabisk versgang med enkelte monosyllabler (--)) | |
| <l>, <lg> | met="bi+-" [***] | Markerer versgang med både substitusjon og reduksjon | |
| <l>, <lg> | met="10|11" [***] | Angir antall stavelser i en verslinje. | betyr 'eller' | |
| <l>, <lg> | met="reg" [***] | Fast/regulært blandet versgang | |
| <l>, <lg> | met="-" (bindestrek) [***] | Trykksterk stavelse | |
| <l>, <lg> | met="v" [***] | Trykksvak stavelse | |
| <l>, <lg> | realMet="" | Markerer faktisk realisasjon av (dvs. avvik fra) det metriske mønsteret. Kan inneholde samme attributtverdier som met | |
| <l>, <lg> | part="I" | "initial" (oblig. TEI) | |
| <l>, <lg> | part="M" | "medial" (oblig. TEI). En oppdelt verslinje kan ha flere M-parter. I hovedtekstene nummereres slike med n-attributter (<l part="M" n="1">, <l part="M" n="2">) | |
| <l>, <lg> | part="F" | "final" (oblig. TEI) | |
| <l>, <lg> | part="Y" | Markerer at en verslinje eller en verslinjegruppe er inkomplett | |
| <l>, <lg> | rhyme="(a B)2" | Liten bokstav markerer monosyllabisk (mannlig) rim. Stor bokstav markerer bisyllabisk (kvinnelig) rim. Hver rimsekvens begynner på a|A. Parentesen med opphøyd totall bak markerer fordobling, slik at rimskjemaet her blir a B a B | |
| <l>, <lg> | rhyme="x|X" | Nullrim | |
| <l>, <lg> | rhyme="Aa" | Trisyllabisk rim (-vv) | |
| <l>, <lg> | rhyme="r|R|Rr" | Varierende rimforhold (veksler mellom mono-, bi- og trisyllabiske rim | |
| <l>, <lg> | rhyme="var a b b a" | Angir at rimskjemaet ligger fast, men at det veksler mellom mono- og bisyllabiske rim | |
| <l>, <lg> | realRhyme="" | Markerer faktisk realisasjon av (dvs. avvik fra) rimskjemaet. Kan inneholde samme attributtverdier som rhyme | |
| <lg> | id="l[løpende nummerering]" | Brukes til lenking fra f.eks. ufullstendig til fullstendig strofe. Tilsvarende id-verdi skal ligge i en tilhørende <note type="met" target="l[løpende nummerering]"> | |
| <lg> | type="strofe" | Strofe | |
| <lg> | type="strofegruppe" | Samling av strofer som til sammen utgjør en strofegruppe | |
| <lg> | type="stikisk" | Stikisk formdannelse; ensartede verslinjer som følger på hverandre i rekke, uten noen inndeling i strofer. Typisk i versdramaer | |
| <lg> | type="rapsodisk" | Rapsodisk formdannelse; verslinjer av ulik lengde som følger på hverandre i rekke, uten noen inndeling i strofer, f.eks. Wergelandstroken | |
| <lg> | type="refreng" | Refreng | |
| N | <note> | type="met" | Metrikknote |
| <note> | type="met" target="l[løpende nummerering]" | Lenkes til en <lg id=""> med tilsvarende verdi | |
| R | <ref> | target="" | Angir id-verdien til teksten det lenkes til (brukt i DHU) |
| T | <text> | id="c[+nummer]/po[+nummer]" | Løpende nummerering. 'c' står for 'collection' (diktsamling) og 'po' står for 'poem' (enkeltdikt) (brukt i DHU) |
kap-20: Entiteter
Dette kapitlet inneholder en oversikt over hvilke entiteter som er i bruk.
Tegn som ikke fins i det vanlige norske alfabetet (a-å) skal byttes ut med entiteter.
Konvertering av æ, ø, å, Æ, Ø og Å overlates for alle filtyper til setteriet. Andre særtegn gjøres om til entiteter underveis i arbeidet.
Det skal brukes entiteter for anførselstegn (&lquo;/&rquo;) i løpende tekst. Unntak: i kommentarmaterialet genereres anførselstegn på grunnlag av koding, se kapitlet om kommentarkoding.
Det skal alltid brukes entiteter for kodeklammer (< og >), ampersand (&) og skråstrek (/ = /) når disse forekommer utenfor tagger/i tekst.
Bindestreker kodes med entitet (&typHyp;) ved linjeslutt, men transkriberes som vanlig bindestrek når de står midt i en linje. I hovedtekster blir entitet for myk bindestrek i noen tilfeller gjort om til entitet for hard bindestrek. I hovedtekster blir også vanlige bindestrekstegn gjort om til bindestreksentiteter.
Nedenfor fins en oversikt over alle de entitetene som er i bruk. Unntak: entiteter som brukes som lenker til standardtekster etc. i <teiHeader> står oppført under sine respektive punkter i kapitlet om <teiHeader>. Kommentarentiteter er definert i et eget dokument (HIS_kommentarentiteter.xml), se kapitlet om kommentarkoding.
Entitetene nedenfor fins alle i DTD-en. Ikke alle er tatt i bruk. Noen skal ikke brukes enten fordi det fins flere entiteter for enkelte tegn (f.eks. half), vi har da valgt en av dem, eller fordi vi har laget vår egen versjon av et tegn (f.eks. typHyp). Entitetene er ordnet alfabetisk. De blir ikke alltid vist riktig, og tegn som ser ut som en åpen firkant kan derfor dessverre ikke vises (dette kan skyldes nettleseren, maskinen etc. og er vanskelig å få gjort noe med).
| A | B | C | D | E |
| F | G | H | I | K |
| L | M | N | O | P |
| Q | R | S | T | U |
| V | Y | Z |
| NAVN | VISNING | UNICODE-NR. | UNICODE-DEFINISJON | ENTITETSSETT | BEMERKNINGER | ||
| A | aacute | á | LATIN SMALL LETTER A WITH ACUTE | iso-lat1.ent | i bruk | ||
| Aacute | Á | LATIN CAPITAL LETTER A WITH ACUTE | iso-lat1.ent | ||||
| abreve | ă | ă | LATIN SMALL LETTER A WITH BREVE | iso-lat2.ent | i bruk | ||
| acirc | â | LATIN SMALL LETTER A WITH CIRCUMFLEX | iso-lat1.ent | ||||
| Acirc | Â | LATIN CAPITAL LETTER A WITH CIRCUMFLEX | iso-lat1.ent | ||||
| acute | ´ | ´ | ACUTE ACCENT | iso-dia.ent | i bruk | ||
| acuteCentre | ´ | ´ | ACUTE ACCENT | HIS-definert entitet, tegn fra iso-dia.ent | i bruk; acute aksent brukt typografisk som skilletegn i 2. kolofon | ||
| aelig | æ | æ | LATIN SMALL LETTER AE | iso-lat1.ent | |||
| AElig | Æ | Æ | LATIN CAPITAL LETTER AE | iso-lat1.ent | |||
| agrave | à | LATIN SMALL LETTER A WITH GRAVE | iso-lat1.ent | i bruk | |||
| Agrave | À | LATIN CAPITAL LETTER A WITH GRAVE | iso-lat1.ent | ||||
| alphaacute | ἁ | ἁ | GREEK SMALL LETTER ALPHA WITH DASIA | Fra Unicode-settet Greek Extended | i bruk | ||
| amacr | ā | ā | LATIN SMALL LETTER A WITH MACRON | Fra ISO Lat-2.ent | i bruk | ||
| amp | & | & | AMPERSAND | predefinert i XML | i bruk | ||
| an | ˈ | ˈ | MODIFIED LETTER VERTICAL LINE | HIS-definert, tegn fra Spacing Modifier Letters | i bruk; entitet til visningsvasking av metrikkoding[****] | ||
| apos | ' | ' | APOSTROPHE | iso-num.ent | ikke i bruk; HIS' apostrof er rapo | ||
| aring | å | å | LATIN SMALL LETTER A WITH RING ABOVE | iso-lat1.ent | |||
| Aring | Å | Å | LATIN CAPITAL LETTER A WITH RING ABOVE | iso-lat1.ent | |||
| ast | ∗ | ∗ | ASTERISK OPERATOR | iso-num.ent | |||
| atilde | ã | LATIN SMALL LETTER A WITH TILDE | iso-lat1.ent | ||||
| Atilde | Ã | LATIN CAPITAL LETTER A WITH TILDE | iso-lat1.ent | ||||
| auml | ä | LATIN SMALL LETTER A WITH DIAERESIS | iso-lat1.ent | i bruk | |||
| Auml | Ä | LATIN CAPITAL LETTER A WITH DIAERESIS | iso-lat1.ent | i bruk | |||
| B | breve | ˘ | ˘ | BREVE | iso-dia.ent | ||
| brvbar | ¦ | ¦ | BROKEN BAR | iso-num.ent | |||
| bsol | \ | \ | REVERSE SOLIDUS | iso-num.ent | i bruk; markerer delte verslinjer i lemma i kommentarene | ||
| bue | ∪ | ∪ | UNION | HIS-definert, tegn fra Mathematical Operators | i bruk; bue i metrikknotasjon i kommentarene[****] | ||
| bull | • | • | BULLET | iso-pub.ent | i bruk | ||
| C | cacute | ć | ć | LATIN SMALL LETTER C WITH ACUTE | ISO Lat-2.ent | i bruk | |
| caron | ˇ | ˇ | CARON | iso-dia.ent | |||
| ccaron | č | č | LATIN SMALL LETTER C WITH CARON | iso-lat2.ent | i bruk | ||
| Ccaron | Č | Č | LATIN CAPITAL LETTER C WITH CARON | iso-lat2.ent | i bruk | ||
| ccedil | ç | LATIN SMALL LETTER C WITH CEDILLA | iso-lat1.ent | i bruk | |||
| Ccedil | Ç | LATIN CAPITAL LETTER C WITH CEDILLA | iso-lat1.ent | i bruk | |||
| cedil | ¸ | ¸ | CEDILLA | iso-dia.ent | |||
| cent | ¢ | CENT SIGN | iso-num.ent | ||||
| circ | ∘ | ∘ | RING OPERATOR | iso-dia.ent | |||
| colon | : | : | COLON | iso-num.ent | |||
| comma | , | , | COMMA | iso-num.ent | |||
| commat | @ | @ | COMMERCIAL AT | iso-num.ent | |||
| copy | © | © | COPYRIGHT SIGN | iso-num.ent | i bruk | ||
| corrMark | ☥ | ☥ | ANKH | HIS-definert, tegn fra Miscellaneous Symbols | i bruk; Ibsens korrekturtegn i PG85-teaterms-pe (trykt tekst med egenhendige rettelser) | ||
| curren | ¤ | ¤ | CURRENCY SIGN | iso-num.ent | |||
| cyrilE | Э | Э | CYRILLIC CAPITAL LETTER E | Fra Unicode-settet Cyrillic 0400-04FF | i bruk | ||
| cyrilel | л | л | CYRILLIC CAPITAL LETTER EL | Fra Unicode-settet Cyrillic 0400-04FF | i bruk | ||
| cyrilem | м | м | CYRILLIC SMALL LETTER EM | Fra Unicode-settet Cyrillic 0400-04FF | i bruk | ||
| cyrilen | н | н | CYRILLIC SMALL LETTER EN | Fra Unicode-settet Cyrillic 0400-04FF | i bruk | ||
| cyrilhard | ъ | ъ | CYRILLIC SMALL LETTER HARD SIGN | Fra Unicode-settet Cyrillic 0400-04FF | i bruk | ||
| cyrilsoft | ь | ь | CYRILLIC SMALL LETTER SOFT SIGN | Fra Unicode-settet Cyrillic 0400-04FF | i bruk | ||
| cyrilGHE | Г | Г | CYRILLIC CAPITAL LETTER GHE | Fra Unicode-settet Cyrillic 0400-04FF | i bruk | ||
| cyrilPE | П | П | CYRILLIC CAPITAL LETTER PE | Fra Unicode-settet Cyrillic 0400-04FF | i bruk | ||
| cyrilya | я | я | CYRILLIC SMALL LETTER YA | Fra Unicode-settet Cyrillic 0400-04FF | i bruk | ||
| cyrilzhe | ж | ж | CYRILLIC SMALL LETTER ZHE | Fra Unicode-settet Cyrillic 0400-04FF | i bruk | ||
| cyrilka | к | к | CYRILLIC SMALL LETTER KA | Fra Unicode-settet Cyrillic 0400-04FF | i bruk | ||
| cyrilve | в | в | CYRILLIC SMALL LETTER VE | Fra Unicode-settet Cyrillic 0400-04FF | i bruk | ||
| cyrilNo | № | № | NUMERO SIGN | Fra Unicode-settet Letterlike Symbols 2100-214F | i bruk | ||
| D | darr | ↓ | ↓ | DOWNWARDS ARROW | iso-num.ent | ||
| dash | – | – | EN DASH | HIS-definert, tegn fra General Punctuation | i bruk; HIS' tankestrek | ||
| dblac | ˝ | ˝ | DOUBLE ACUTE ACCENT | iso-dia.ent | i bruk? | ||
| deg | ° | ° | DEGREE SIGN | iso-num.ent | i bruk | ||
| die | ¨ | ¨ | DIAERESIS | iso-dia.ent | |||
| divide | ÷ | ÷ | DIVISION SIGN | iso-num.ent | |||
| dollar | $ | $ | DOLLAR SIGN | iso-num.ent | |||
| dot | ˙ | ˙ | DOT ABOVE | iso-dia.ent | |||
| E | eacute | é | LATIN SMALL LETTER E WITH ACUTE | iso-lat1.ent | i bruk | ||
| Eacute | É | LATIN CAPITAL LETTER E WITH ACUTE | iso-lat1.ent | i bruk | |||
| ecaron | ě | ě | LATIN SMALL LETTER E WITH CARON | iso-lat2.ent | i bruk | ||
| ecirc | ê | LATIN SMALL LETTER E WITH CIRCUMFLEX | iso-lat1.ent | i bruk | |||
| Ecirc | Ê | LATIN CAPITAL LETTER E WITH CIRCUMFLEX | iso-lat1.ent | ||||
| edot | ė | ė | LATIN SMALL LETTER E WITH DOT ABOVE | iso-lat2.ent | i bruk | ||
| Edot | Ė | Ė | LATIN CAPITAL LETTER E WITH DOT ABOVE | iso-lat2.ent | i bruk | ||
| egrave | è | LATIN SMALL LETTER E WITH GRAVE | iso-lat1.ent | i bruk | |||
| Egrave | È | LATIN CAPITAL LETTER E WITH GRAVE | iso-lat1.ent | ||||
| eogon | ę | ę | LATIN SMALL LETTER E WITH OGONEK | iso-lat2.ent | i bruk | ||
| equals | = | = | EQUALS SIGN | iso-num.ent | i bruk | ||
| ergo | ɔ | ɔ | LATIN SMALL LETTER OPEN O | Fra Unicode-settet IPA Extensions 0250-02AF | i bruk | ||
| eth | ð | LATIN SMALL LETTER ETH | iso-lat1.ent | i bruk | |||
| ETH | Ð | LATIN CAPITAL LETTER ETH | iso-lat1.ent | ||||
| euml | ë | LATIN SMALL LETTER E WITH DIAERESIS | iso-lat1.ent | i bruk | |||
| Euml | Ë | LATIN CAPITAL LETTER E WITH DIAERESIS | iso-lat1.ent | ||||
| excl | ! | ! | EXCLAMATION MARK | iso-num.ent | |||
| F | finalsigma | ς | ς | GREEK SMALL LETTER FINAL SIGMA | Fra Unicode-settet Greek and Coptic | i bruk | |
| foot | ' | ' | APOSTROPHE FOR METRICAL USE IN COMMENTARY ENCODING | HIS-definert, tegn fra C0 Controls and Basic Latin | i bruk; kommentarkoding: metrisk apostrof | ||
| frac12 | ½ | ½ | VULGAR FRACTION ONE HALF | iso-num.ent | ikke i bruk; HIS bruker half | ||
| frac13 | ⅓ | ⅓ | VULGAR FRACTION ONE THIRD | iso-num.ent | i bruk | ||
| frac14 | ¼ | ¼ | VULGAR FRACTION ONE QUARTER | iso-num.ent | i bruk | ||
| frac15 | ⅕ | ⅕ | VULGAR FRACTION ONE FIFTH | iso-num.ent | i bruk | ||
| frac16 | ⅙ | ⅙ | VULGAR FRACTION ONE SIXTH | iso-num.ent | i bruk | ||
| frac17 | ⅟₇ | ⅟₇ | VULGAR FRACTION ONE SEVENTHS | iso-num.ent | i bruk | ||
| frac18 | ⅛ | ⅛ | VULGAR FRACTION ONE EIGHTH | iso-num.ent | i bruk | ||
| frac23 | ⅔ | ⅔ | VULGAR FRACTION TWO THIRDS | iso-num.ent | i bruk | ||
| frac24 | ²⁄₄ | ²⁄₄ | VULGAR FRACTION TWO QUARTERS | HIS-definert, tegn fra C1 Controls and Latin-1 Supplement | i bruk | ||
| frac25 | ⅖ | ⅖ | VULGAR FRACTION TWO FIFTHS | iso-pub.ent | i bruk | ||
| frac34 | ¾ | ¾ | VULGAR FRACTION THREE QUARTERS | iso-num.ent | i bruk | ||
| frac38 | ⅜ | ⅜ | iso-num.ent | ||||
| frac44 | ⁴⁄₄ | ⁴⁄₄ | VULGAR FRACTION FOUR QUARTERS | HIS-definert: fra Unicode-settene Superscripts and subscripts og General punctuation | i bruk | ||
| frac45 | ⅘ | ⅘ | VULGAR FRACTION FOUR FIFTHS | iso-pub.ent | i bruk | ||
| frac27 | ²⁄₇ | ²⁄₇ | VULGAR FRACTION TWO SEVENTHS | egendefinert | i bruk | ||
| frac37 | ³⁄₇ | ³⁄₇ | VULGAR FRACTION THREE SEVENTHS | egendefinert | i bruk | ||
| frac57 | ⁵⁄₇ | ⁵⁄₇ | VULGAR FRACTION FIVE SEVENTHS | egendefinert | i bruk | ||
| frac58 | ⅝ | ⅝ | VULGAR FRACTION FIVE EIGHTHS | iso-num.ent | |||
| frac68 | ⁶⁄₈ | ⁶⁄₈ | VULGAR FRACTION SIX EIGHTHS | HIS-definert: fra Unicode-settene Superscripts and subscripts og General punctuation | i bruk | ||
| frac78 | ⅞ | ⅞ | VULGAR FRACTION SEVEN EIGHTHS | iso-num.ent | |||
| G | grave | ` | ` | GRAVE ACCENT | iso-dia.ent | i bruk | |
| gt | > | > | GREATER-THAN SIGN | iso-num.ent | i bruk i kodepraksis-XML-filene | ||
| H | half | ½ | ½ | VULGAR FRACTION ONE HALF | iso-num.ent | i bruk | |
| hellip | … | … | HORIZONTAL ELLIPSIS | iso-pub.ent | i bruk; markerer utelatelser, også innenfor skarpe klammer | ||
| horbar | ― | ― | HORIZONTAL BAR | iso-num.ent | |||
| hyphen | ‐ | ‐ | HYPHEN | iso-num.ent | i bruk; i hovedtekster: bindestrek; strek i metrikknotasjon i kommentarene | ||
| I | iacute | í | LATIN SMALL LETTER I WITH ACUTE | iso-lat1.ent | i bruk | ||
| Iacute | Í | LATIN CAPITAL LETTER I WITH ACUTE | iso-lat1.ent | ||||
| icirc | î | LATIN SMALL LETTER I WITH CIRCUMFLEX | iso-lat1.ent | ||||
| Icirc | Î | LATIN CAPITAL LETTER I WITH CIRCUMFLEX | iso-lat1.ent | ||||
| iexcl | ¡ | ¡ | INVERTED EXCLAMATION MARK | iso-num.ent | |||
| igrave | ì | LATIN SMALL LETTER I WITH GRAVE | iso-lat1.ent | i bruk | |||
| Igrave | Ì | LATIN CAPITAL LETTER I WITH GRAVE | iso-lat1.ent | ||||
| iota | ι | ι | GREEK SMALL LETTER IOTA | Fra Unicode-settet Greek and Coptic | i bruk | ||
| iquest | ¿ | ¿ | INVERTED QUESTION MARK | iso-num.ent | |||
| iuml | ï | LATIN SMALL LETTER I WITH DIAERESIS | iso-lat1.ent | i bruk | |||
| Iuml | Ï | LATIN CAPITAL LETTER I WITH DIAERESIS | iso-lat1.ent | ||||
| K | ksi | ξ | ξ | GREEK SMALL LETTER XI | Fra Unicode-settet Greek and Coptic | i bruk | |
| L | lapo | ‘ | ‘ | LEFT SINGLE QUOTATION MARK =lsquo | HIS-definert, tegn fra General Punctuation | i bruk; kommentarkoding | |
| laquo | « | « | LEFT-POINTING DOUBLE ANGLE QUOTATION MARK | iso-num.ent | ikke i bruk; i HIS brukes lquo | ||
| larr | ← | ← | LEFTWARDS DOUBLE ARROW | iso-num.ent | |||
| lcub | { | { | LEFT CURLY BRACKET | iso-num.ent | |||
| ldquo | “ | “ | LEFT DOUBLE QUOTATION MARK | iso-num.ent | |||
| lowbar | _ | _ | LOW LINE | iso-num.ent | |||
| lpar | ( | ( | LEFT PARENTHESIS | iso-num.ent | |||
| lquo | « | « | LEFT-POINTING DOUBLE ANGLE QUOTATION MARK | HIS-definert, tegn fra C0 Controls and Basic Latin | i bruk; HIS' standard anførselstegn | ||
| lsaquo | ‹ | ‹ | SINGLE LEFT-POINTING ANGLE QUOTATION MARK | HIS-definert, tegn fra General Punctuation | i bruk; anførselstegn til sitat i sitat i kommentarene | ||
| lstrok | ł | ł | LATIN SMALL LETTER L WITH STROKE | iso-lat2.ent | i bruk | ||
| lsqb | [ | [ | LEFT SQUARE BRACKET | iso-num.ent | i bruk | ||
| lsquo | ‘ | ‘ | LEFT SINGLE QUOTATION MARK | iso-num.ent | ikke i bruk; i HIS brukes lapo | ||
| lt | < | < | LESS-THAN SIGN | predefinert i XML | i bruk i kodepraksis-XML-filene | ||
| M | macr | ¯ | ¯ | MACRON | iso-dia.ent | i bruk | |
| mark | Ֆ | Ֆ | ARMENIAN CAPITAL LETTER FEH. | HIS-definert, tegn fra Armenian | i bruk; valutategn for mark | ||
| mbar | m̅ | m̅ | COMBINATION OF 'm' AND UNICODE COMBINING OVERLINE | HIS-definert, tegn fra Combining Diacritical Marks | i bruk; 'm' med nasalstrek; markering (som attributtverdi) av forkortet dobbel 'm' i håndskrifter (kommentarkoding har egen praksis, se denne) | ||
| metDash | – | – | NDASH USED AS METRICAL DASH | HIS-definert | i bruk | ||
| micro | µ | µ | MICRO SIGN | iso-num.ent | |||
| middot | · | · | MIDDLE DOT | iso-num.ent | i bruk | ||
| my | μ | μ | GREEK SMALL LETTER MU | Fra Unicode-settet Greek and Coptic | i bruk | ||
| My | Μ | Μ | GREEK CAPITAL LETTER MU | Fra Unicode-settet Greek and Coptic | i bruk | ||
| N | nacute | ń | ń | LATIN SMALL LETTER N WITH ACUTE | iso-lat2.ent | i bruk | |
| nbar | n̅ | n̅ | COMBINATION OF 'n' AND UNICODE COMBINING OVERLINE | HIS-definert, tegn fra Combining Diacritical Marks | i bruk; 'n' med nasalstrek; markering (som attributtverdi) av forkortet dobbel 'n' i håndskrifter (kommentarkoding har egen praksis, se denne) | ||
| nbsp |   | NO-BREAK SPACE | iso-num.ent | ||||
| not | ¬ | ¬ | NOT SIGN | iso-num.ent | |||
| ntilde | ñ | LATIN SMALL LETTER N WITH TILDE | iso-lat1.ent | ||||
| Ntilde | Ñ | LATIN CAPITAL LETTER N WITH TILDE | iso-lat1.ent | ||||
| num | # | # | NUMBER SIGN | iso-num.ent | |||
| O | oacute | ó | LATIN SMALL LETTER O WITH ACUTE | iso-lat1.ent | i bruk | ||
| Oacute | Ó | LATIN CAPITAL LETTER O WITH ACUTE | iso-lat1.ent | ||||
| ocaron | ǒ | ǒ | LATIN SMALL LETTER O WITH CARON | Fra Unicode-settet Latin Extended-B | i bruk | ||
| ocirc | ô | LATIN SMALL LETTER O WITH CIRCUMFLEX | iso-lat1.ent | i bruk | |||
| Ocirc | Ô | LATIN CAPITAL LETTER O WITH CIRCUMFLEX | iso-lat1.ent | ||||
| odblac | ő | ő | LATIN SMALL LETTER O WITH DOUBLE ACUTE | ISO-lat2.ent | i bruk | ||
| oelig | œ | œ | LATIN SMALL LIGATURE OE | ISO-lat2.ent | i bruk | ||
| OElig | Π| Π| LATIN CAPITAL LIGATURE OE | ISO-lat2.ent | i bruk | ||
| ogon | ˛ | ˛ | OGONEK | iso-dia.ent | |||
| ograve | ò | LATIN SMALL LETTER O WITH GRAVE | iso-lat1.ent | ||||
| Ograve | Ò | LATIN CAPITAL LETTER O WITH GRAVE | iso-lat1.ent | ||||
| ohm | Ω | Ω | OHM SIGN | iso-num.ent | |||
| okvist | ǫ | ǫ | LATIN SMALL LETTER O WITH OGONEK | HIS-definert, tegn fra Latin Extended-B | i bruk; 'o' med kvist | ||
| Okvist | Ǫ | Ǫ | LATIN CAPITAL LETTER O WITH OGONEK | HIS-definert, tegn fra Latin Extended-B | i bruk; 'O' med kvist | ||
| omacr | ō | ō | LATIN SMALL LETTER O WITH MACRON | ISO-lat2.ent | i bruk | ||
| omikron | ο | ο | GREEK SMALL LETTER OMICRON | Fra Unicode-settet Greek and Coptic | i bruk | ||
| ordf | ª | ª | FEMININE ORDINAL INDICATOR | iso-num.ent | |||
| ordm | º | º | MASCULINE ORDINAL INDICATOR | iso-num.ent | |||
| oslash | ø | ø | LATIN SMALL LETTER O WITH SLASH | iso-lat1.ent | |||
| Oslash | Ø | Ø | LATIN CAPITAL LETTER O WITH STROKE | iso-lat1.ent | |||
| otilde | õ | LATIN SMALL LETTER O WITH TILDE | iso-lat1.ent | ||||
| Otilde | Õ | LATIN CAPITAL LETTER O WITH TILDE | iso-lat1.ent | ||||
| ouml | ö | LATIN SMALL LETTER O WITH DIAERESIS | iso-lat1.ent | i bruk | |||
| Ouml | Ö | LATIN CAPITAL LETTER O WITH DIAERESIS | iso-lat1.ent | ||||
| P | para | ¶ | ¶ | PILCROW SIGN | iso-num.ent | ||
| percnt | % | % | PERCENT SIGN | iso-num.ent | i bruk | ||
| period | . | . | FULL STOP | iso-num.ent | |||
| plus | + | + | PLUS SIGN | iso-num.ent | |||
| plusmn | ± | ± | PLUS-MINUS SIGN | iso-num.ent | |||
| pound | £ | POUND SIGN | iso-num.ent | ||||
| Q | quest | ? | ? | QUESTION MARK | iso-num.ent | i bruk | |
| quot | " | " | QUOTATION MARK | iso-num.ent | |||
| R | rapo | ’ | ’ | RIGHT SINGLE QUOTATION MARK =rsquo =HIW'S APOSTROPHE | HIS-definert, tegn fra General Punctuation | i bruk; HIS' tegn for genitivsapostrof og utelatt tegn | |
| raquo | » | » | RIGHT-POINTING DOUBLE ANGLE QUOTATION MARK | iso-num.ent | ikke i bruk; i HIS brukes rquo | ||
| rarr | → | → | RIGHTWARDS DOUBLE ARROW | iso-num.ent | |||
| rcaron | ř | ř | LATIN SMALL LETTER R WITH CARON | iso-lat2.ent | i bruk | ||
| rcub | } | } | RIGHT CURLY BRACKET | iso-num.ent | |||
| rdquo | ” | ” | RIGHT DOUBLE QUOTATION MARK | iso-num.ent | |||
| referenceMark | ※ | ※ | REFERENCE MARK | HIS-definert, tegn fra General Punctuation | i bruk; normaliseringstegn for ikke-transkriberbare innføyningstegn | ||
| reg | ® | ¯ | MACRON | iso-num.ent | |||
| rep | " | " | QUOTATION MARK | HIS-definert, tegn fra C0 Controls and Basic Latin | i bruk; repetisjonstegn | ||
| ring | ˚ | ˚ | RING ABOVE | iso-dia.ent | |||
| rpar | ) | ) | RIGHT PARENTHESIS | iso-num.ent | |||
| rquo | » | » | RIGHT-POINTING DOUBLE ANGLE QUOTATION MARK | HIS-definert, tegn fra C1 Controls and Latin-1 Supplement | i bruk; HIS' standard anførselstegn | ||
| rsaquo | › | › | SINGLE RIGHT-POINTING ANGLE QUOTATION MARK | HIS-definert, tegn fra General Punctuation | i bruk; anførselstegn til sitat i sitat i kommentarene | ||
| rsqb | ] | ] | RIGHT SQUARE BRACKET | iso-num.ent | i bruk | ||
| rsquo | ’ | ’ | RIGHT SINGLE QUOTATION MARK | iso-num.ent | ikke i bruk; i HIS brukes rapo | ||
| S | sacute; | ś | ś | LATIN SMALL LETTER S WITH ACUTE | iso-lat2.ent | i bruk | |
| scaron | š | š | LATIN SMALL LETTER S WITH CARON | iso-lat2.ent | i bruk | ||
| Scaron | Š | Š | LATIN CAPITAL LETTER S WITH CARON | iso-lat2.ent | i bruk | ||
| scedil | ş | ş | LATIN SMALL LETTER S WITH CEDILLA | iso-lat2.ent | i bruk | ||
| schwa | ə | ə | LATIN SMALL LETTER SCHWA | IPA Extensions | i bruk | ||
| sect | § | § | SECTION SIGN | iso-num.ent | i bruk | ||
| semi | ; | ; | SEMICOLON | iso-num.ent | |||
| shy | | ­ | SOFT HYPHEN | iso-num.ent | ikke i bruk; i HIS brukes typHyp | ||
| skilling | ʄ | ʄ | LATIN SMALL LETTER DOTLESS J WITH STROKE AND HOOK | HIS-definert, tegn fra IPA Extensions | i bruk; valutategn for skilling | ||
| sol | / | / | SOLIDUS | iso-num.ent | i bruk | ||
| sung | ♩ | ♩ | QUARTER NOTE | iso-num.ent | |||
| sup1 | ¹ | ¹ | SUPERSCRIPT ONE | iso-num.ent | |||
| sup2 | ² | ² | SUPERSCRIPT TWO | iso-num.ent | i bruk; gir opphøyd totall[****] | ||
| sup3 | ³ | ³ | SUPERSCRIPT THREE | iso-num.ent | i bruk; gir opphøyd tretall[****] | ||
| supn | ⁿ | ⁿ | SUPERSCRIPT LATIN SMALL LETTER N | HIS-definert, tegn fra Superscripts and Subscripts | i bruk; gir opphøyd 'n'[****] | ||
| szlig | ß | LATIN SMALL LETTER SHARP S | iso-lat1.ent | i bruk | |||
| T | tcedil | ţ | ţ | LATIN SMALL LETTER T WITH CEDILLA | iso-lat2.ent | i bruk | |
| tilde | ~ | ~ | TILDE | iso-dia.ent | |||
| times | × | × | MULTIPLICATION SIGN | iso-num.ent | i bruk | ||
| titleColon | : | : | COLON | HIS-definert, tegn fra C0 Controls and Basic Latin | i bruk; kommentarkoding: kolon som skiller deler av tittel/overskrift fra hverandre | ||
| thorn | þ | LATIN SMALL LETTER THORN | iso-lat1.ent | i bruk | |||
| THORN | Þ | LATIN CAPITAL LETTER THORN | iso-lat1.ent | i bruk | |||
| trade | ™ | ™ | TRADE MARK SIGN | iso-num.ent | |||
| tu20 |   | '20 typographical units' EXPANDS AS UNICODE CHARACTER 2009 THIN SPACE | HIS-definert, tegn fra General Punctuation | i bruk; kommentarkoding | |||
| typHyp | ‐ | ‐ | HYPHEN | HIS-definert, tegn fra General Punctuation | typografisk (myk) bindestrek | ||
| U | uacute | ú | LATIN SMALL LETTER U WITH ACUTE | iso-lat1.ent | i bruk | ||
| Uacute | Ú | LATIN CAPITAL LETTER U WITH ACUTE | iso-lat1.ent | ||||
| uarr | ↑ | ↑ | UPWARDS ARROW | iso-num.ent | i bruk | ||
| ucaron | uˇ | &uˇ | COMBINATION OF 'u' AND CARON | HIS-definert, tegn fra Combining Diacritical Marks | i bruk | ||
| ucirc | û | LATIN SMALL LETTER U WITH CIRCUMFLEX | iso-lat1.ent | i bruk | |||
| Ucirc | Û | LATIN CAPITAL LETTER U WITH CIRCUMFLEX | iso-lat1.ent | ||||
| udblac | ű | ű | LATIN SMALL LETTER U WITH DOUBLE ACUTE | iso-lat2.ent | i bruk | ||
| ugrave | ù | LATIN SMALL LETTER U WITH GRAVE | iso-lat1.ent | ||||
| Ugrave | Ù | LATIN CAPITAL LETTER U WITH GRAVE | iso-lat1.ent | ||||
| umacr | ū | ū | LATIN SMALL LETTER U WITH MACRON | Fra ISO Lat-2.ent | i bruk | ||
| uml | ¨ | ¨ | DIAERESIS | iso-dia.ent | |||
| utilde | ũ | ũ | LATIN SMALL LETTER U WITH TILDE | iso-lat2.ent | i bruk | ||
| uuml | ü | LATIN SMALL LETTER U WITH DIAERESIS | iso-lat1.ent | i bruk | |||
| Uuml | Ü | LATIN CAPITAL LETTER U WITH DIAERESIS | iso-lat1.ent | ||||
| V | vcaron | vˇ | vˇ | COMBINATION OF 'v' AND CARON | HIS-definert, tegn fra Combining Diacritical Marks | i bruk | |
| verbar | | | | | VERTICAL LINE | iso-num.ent | |||
| Y | yacute | ý | LATIN SMALL LETTER Y WITH ACUTE | iso-lat1.ent | i bruk | ||
| Yacute | Ý | LATIN CAPITAL LETTER Y WITH ACUTE | iso-lat1.ent | ||||
| yen | ¥ | YEN SIGN | iso-num.ent | ||||
| yuml | ÿ | LATIN SMALL LETTER Y WITH DIAERESIS | iso-lat1.ent | ||||
| Z | zacute | ź | ź | LATIN SMALL LETTER Z WITH ACUTE | iso-lat2.ent | i bruk | |
| zcaron | ž | ž | LATIN SMALL LETTER Z WITH CARON | iso-lat2.ent | i bruk; 'z' med caron | ||
| Zcaron | Ž | Ž | LATIN CAPITAL LETTER Z WITH CARON | iso-lat2.ent | i bruk; 'Z' med caron | ||
| zdot | ż | ż | LATIN SMALL LETTER Z WITH DOT ABOVE | iso-lat2.ent | i bruk; 'z' med dot |